第一天 hadoop概述
hadoop 概述
- 一、hadoop大数据 概述
-
-
- <1>概念
- <2>特点
- <3>作用
- <4>大数据就业方向和部门的组成
-
- 二、Hadoop概述( hdfs + yarn + mapreduce )
-
-
- <1>概念
- <2>发展史
- <3>特点
- <4>组成
- <5>数据业务流程图
-
- 三、Hadoop的搭建
-
-
- <1> 步骤
- <2>步骤一:安装虚拟机
- <3>步骤二:配置虚拟机
- <4>步骤三:安装软件
- <5>步骤四:虚拟机克隆
-
- 四、Hadoop的运行模式
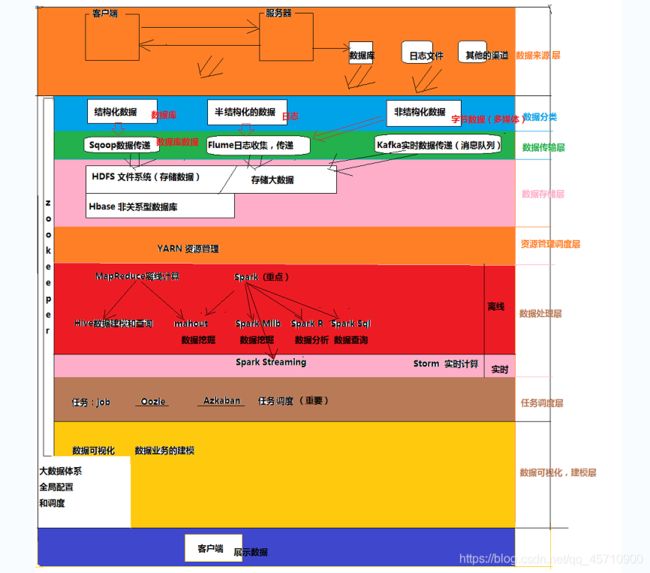
体系架构
一、hadoop大数据 概述
<1>概念
1. 概念:
大数据(big data),指无法在一定时间范围内用 常规软件工具 进行捕捉、管理和处理的数据集合。
解决的问题的是:海量数据的存储和处理问题
2. 单位
1 Byte =8 bit
1 KB = 1,024 B
1 MB = 1,024 KB
1 GB = 1,024 MB
1 TB = 1,024 GB
1 PB = 1,024 TB (数据量在PB级别)
1 EB = 1,024 PB
1 ZB = 1,024 EB (全年全球数据总量)
1 YB = 1,024 ZB
1 BB = 1,024 YB
1 NB = 1,024 BB
1 DB = 1,024 NB
淘宝一天的数据量:50TB左右
<2>特点
大数据的4V特点:
Volume(大量): 数量级别、增长级别
2000年全球的总数量:4G光盘存储(光盘叠加到月球来回的距离)
2000年2020年:全球数据的增加倍数 TB / ZB
Velocity(高速): 数据的增长速度快
Variety(多样): 物理设备、人为... ...
Value(低价值密度):数据量和数据价值成反比
<3>作用
1. 零售业(消费习惯),提高商品的销量
2. 政府(竞选),预测竞选结果,有效的投放广告、金额
3. 预防病毒( 疾控中心 )
4. 电商网站(广告的推荐,分析用户行为:日志文件)
大量的数据(某些商品的销量:用户,年纪,地域,... ...)
5. 人工智能、机器学习、深度学习、物联网、无人驾驶、自动化生产
个人、企业、政府(金融行业、销售行业、地产行业... ...)
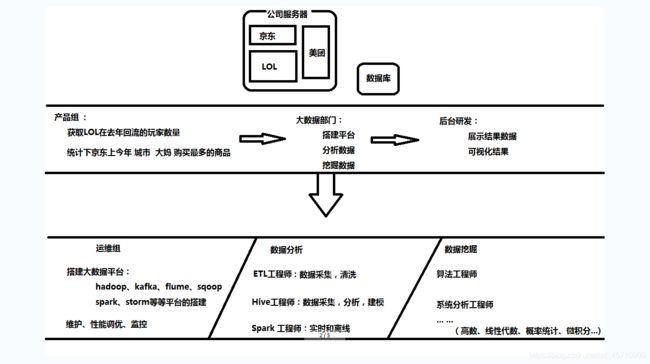
<4>大数据就业方向和部门的组成
二、Hadoop概述( hdfs + yarn + mapreduce )
开发人员:
大数据怎么存储
大数据怎么计算
Hadoop:
解决 大数据存储问题
解决 大数据计算问题
分布式:由发布在不同的主机上的进程协同在一起构成的整个应用
例如:B/S架构
集群:将相同的功能模块部署到不同的主机上
云计算和大数据:
云计算是一系列服务:阿里云,百度云(租用云产品,量范式,随意修改配置)
虚拟化技术:类似于虚拟机,伸缩性强,可以定制
大数据:是一种技术
<1>概念
Hadoop是一个 分布式 系统 架构, 解决海量数据的存储和分析计算问题。
在应用层面被设置成可高用,可扩展,容灾容错
响应数据包的分析:https://toolbar.netcraft.com/site_report?url=http://www.taobao.com
1. 去IOE思想(hadoop的每台节点的配置不要太高)
阿里提出的不使用国外的IBM公司提供的服务器,Oracle提供的数据库,其他公司提供的EMC存储设备
以开源软件进行替代: 硬件(廉价的普通的计算机) + linux + MySQL + 廉价的存储设备
2. 容错和容灾(在系统应用层面,实现高可用)
fault over 容错(软件故障)
failure over 容灾(硬件故障)
<2>发展史
开发者:Doug Cutting( hadoop 之父 )
logo:大象
Hadoop:大数据的生态( hdfs + yarn + mapreduce) 包含:其上的所有的其他的技术
1. Lucene项目:Doug Cutting开发者,实现搜索引擎功能
2. Nutch项目: 搜索引擎项目,在对数据进行抓取(爬虫),遇到存储瓶颈!
3. GFS论文: google file system , google发布此论文
4. NDFS项目: Nutch解决存储瓶颈 , 计算和分析大数据时遇到分析计算瓶颈 (大数据存储)
5. MapReduce论文:google发布论文,怎么在大数据存储环境下,计算分析数据 (大数据计算)
6. NDFS+MapReduce ---> Hadoop : HDFS + MapReduce
google在大数据的三篇论文: GFS ,MapReduce , BigTable(分布式存储数据库,存储PB级别的数据,方便的部署到上千台机器上)
<3>特点
阿里:3000+台
腾讯:5000+
百度:单集群 2800+
yahoo: 4500+
Facebook: 1400+
reliable: 高可靠,维护了多个数据的副本,对错误节点重新分布处理
scalable: 高扩展,集群间分配任务数据,可以方便的扩展数以万计的节点
高效的:在mapreduce的思想下,才是并行处理的方式
容灾容错:数据备份,节点备份等等
<4>组成
1. common 公共模块
2. HDFS 文件系统,存储海量数据模块 (重点)
高可靠、高效的、容灾容错的 分布式 文件系统
3. Yarn 资源分配和调度模块
Hadoop2.0之后出现Yarn ( 符合模块化开发 )
4. MapReduce 海量数据处理模块 (重点)
分布式 离线 并行 计算框架

5. 节点类型
5.1HDFS:
NameNode 名称节点: (一本书的目录)
存储文件的目录信息,文件属性信息,文件的配置信息等等
存储数据和数据节点的信息
DataNode 数据节点( 多个 ):
存储具体的数据
SecondaryNameNode 辅助名称节点
获取数据节点数据,辅助名称节点对数据的维护
5.2 yarn:
ResourceManager: 管理所有的资源
NameNodeManager: 负责一个节点上的资源的分配和调度
守护进程:五个 ,是一类在后台运行的特殊的进程,执行特定的系统任务。
NameNode
DataNode
SecondaryNameNode
ResourceManager
NameNodeManager
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-afyGcUsn-1599704982221)(4.png)]
5.3mapreduce:
将计算和分析过程分为:map和reduce阶段
map:并行处理源数据(拆数据)
reduce:对map的结果进行汇总(合数据)
<5>数据业务流程图

三、Hadoop的搭建
<1> 步骤
1. 安装虚拟机 : Centos7_mini_64_1611
2. 配置虚拟机
静态ip地址、网络模式( 推荐:NAT )
3. 安装软件
JDK / Hadoop
4. 克隆虚拟机
( 完全克隆 )
Master: 控制,主节点
Slave: 服从,从节点
Cluster:集群
<2>步骤一:安装虚拟机
选择 网路模式:Nat(在生产环境下推荐使用桥接)
Nat模式的网络配置信息:
GETWAY=192.168.***.2
NETMASK=255.255.255.0
<3>步骤二:配置虚拟机
配置静态ip地址:
1. 编辑网卡配置文件:vi /etc/sysconfig/network-scripts/ifcfg-ensxx
2. 修改参数
onboot=yes
static/none
IPADDR=192.168.175.200 # Master
GETWAY=192.168.175.2
NETMASK=255.255.255.0
DNS1=8.8.8.8
4. 测试网络连通性( NAT 能上网 )
ping www.baidu.com
5. 修改yum源
curl -o 本地的yum源地址 阿里的yum源地址
curl -o /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
yum list |more
yum search ifconfig
# net-tools
yum -y install net-tools ( ifconfig )
6. yum安装ifconfig
使用 : ifconfig
7. 关闭防火墙(开发阶段)
systemctl status firewalld
systemctl stop firewalld
systemctl disable firewalld
8. 修改主机名称(ip和主机名称相比,操作主机名称更方便)
1) /etc/hostname
master
2)vi /etc/sysconfig/network
HOSTNAME=master
9. 修改ip地址和主机名称的映射关系(通过主机名称访问节点)
/etc/hosts
192.168.175.200 master
192.168.175.201 s1
192.168.175.202 s2
192.168.175.203 s3
192.168.175.204 s4
10. 创建文件夹(统一存储安装包和软件)
/usr : 系统级别 类似于 C://program file
/opt : 用户级别 类似于 D://program file
mkdir - p /opt/software 存放软件包
mkdir - p /opt/programfile 存放安装的软件
注意:/opt 普通用户无法直接操作
解决:给普通用户临时添加超级管理员权限
vi /etc/sudoers
root ALL=(ALL) ALL
zhangsan ALL=(ALL) ALL # 添加权限
<4>步骤三:安装软件
4.1 jdk安装
设置环境变量: /etc/profile
4.2 hadoop安装
设置环境变量的: /etc/profile
#java
export JAVA_HOME=/opt/java/jdk
export PATH=$PATH:$JAVA_HOME/bin
#hadoop
export HADOOP_HOME=/opt/programfile/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
<5>步骤四:虚拟机克隆
四、Hadoop的运行模式
1. 本地模式,nothing什么事都不用做
2. 伪分布模式:修改四个配置文件
3. 完全分布式模式:修改四个配置文件
必须的配置的属性:
配置文件名称 配置的属性 本地模式 伪分布模式 完全分布模式
core-site fs.defaultFS file:/// hdfs://localhost hdfs://主节点
hdfs-site.xml dfs.replication N/A 1 3(默认)
mapred-site.xml mapreduce.framework.name N/A yarn yarn
yarn-site.xml yarn.resourecemanager.hostname N/A localhost 主节点
yarn.nodemanager.aux.services N/A mapreduce_shuffle mapreduce_shuffle
SSH的无秘登陆:
四个配置文件:
hadoop-env.xml 配置JDK的路径 (一定要在启动文件系统之前配置)
export JAVA_HOME=/opt/programfile/jdk
core-site.xml 配置文件系统的访问方式
hdfs-site.xml 配置副本的个数
mapred-site.xml 配置MR的框架:yarn
yarn-site.xml 配置资源管理和调度: NodeManager/resourceManager
4. 格式化文件系统
hadoop namenode -format
5. 启动hadoop
start-all.sh
stop-all.sh
6. 查看当前文件系统中的java进程
jps
10882 NameNode
12026 Jps
11179 SecondaryNameNode
11611 NodeManager
11020 DataNode
11324 ResourceManager
7. 报错:
1. 检查主机名称
2. 检查主机名称和ip的是否映射正确
3. 配置文件参数是否正确
4. 去/opt/programfile/hadoop/logs/
hadoop-zhangsan-datanode-master.log
hadoop-zhangsan-namenode-master.log
hadoop-zhangsan-secondarynamenode-master.log
yarn-zhangsan-resourcemanager-master.log
yarn-zhangsan-nodemanager-master.log
使用常用名:
hdfs dfs -mkdir -p /zhangsan/asd
hdfs dfs -lsr
使用webUI查看hadoop文件系统:
http://master的ip地址:50070
补充:SSH
SSH:安全的远程连接
xshell/putty工具连接linux系统时,使用的方式就是ssh
语法: ssh ip地址
密码
伪分布模式:主节点 master 管理 多个 从节点 slave