【YOLOv5】训练自己的数据集
引言
官网连接:https://github.com/ultralytics/yolov5/tree/v6.1
笔者YOLOv5专栏链接导航:
- 【YOLOv5】6.0环境搭建(不定时更新)
- 【YOLOv5】训练自己的数据集
笔者更新日期 : 2022.3.2
截至2022年3月份,YOLOv5已经更新到6.1.版本
1 数据集准备
数据集的树形框架如下图所示:
-----------------------------------------------------------------------------------------------------------
# 1.准备数据集(树形框架)
|-Customdata(数据库:包含不同场景下的多种数据集)
|-datasets(objects1) # 针对某一目标或者某一场景下的多目标
|-xml # 标签xml文件
|-images # 原始图像
|-ImageSets # 自动生成无需创建
|-train.txt
|-test.txt
|-txt # xml转换后的txt文件
|-datasets(objects2) # 第2类数据集……第n类数据集(不同场景下可能需要构建多个数据集)
……
|-divide_xml.py # 训练时划分训练集和验证集
|-fruit.yaml # 配置训练的数据读取
|-xml2txt.py # 脚本xml文件转换成txt文件,自动生成无需创建
-----------------------------------------------------------------------------------------------------------
上述Customdata数据库放在yolov5的项目文件中:
1.1 新建脚本divide_xml.py:生成ImageSets文件夹下的train.txt和test.txt
进入该脚本的文件夹,若按照笔者上述的文件部署,只需修改数据集的名称即可
"""
2022.3.2
author:alian
因为训练时没有用到测试集,为了充分利用数据,将其数划分为训练集、验证集
注:没有测试集
"""
import os
import random
import shutil
# 针对某一目标或者某一场景下的多目标数据集
object = 'datasets' # 根据自定义的数据集名称修改
# 1.自动生成数据集划分文件夹ImageSets
if os.path.exists("./%s/ImageSets/"%object): # 如果文件存在
shutil.rmtree("./%s/ImageSets/"%object) # 清空原始数据
os.makedirs('./%s/ImageSets/'%object) # 重新创建
else:
os.makedirs('./%s/ImageSets/'%object) # 自动新建文件夹
# 设置训练和验证的比例
train_percent = 0.8
val_percent = 0.2
xmlfilepath = './%s/xml'%object
total_xml = os.listdir(xmlfilepath) # 遍历标签文件
num = len(total_xml) # 统计标签文件的数量
list = list(range(num)) # 标签文件的索引
num_val = int(num * val_percent) # 验证集的数量
num_train = num-num_val # 训练集的数量
train_list = random.sample(list, num_train) # 随机挑选标签文件的索引(要达到训练集的数量)
for i in train_list:
list.remove(i) # 将已挑选为训练集的索引删除,剩下的便是验证集的索引(训练集与验证集不可存在交集)
val_list = list
ftrain = open('./%s/ImageSets/train.txt'%object, 'w') # 写入文件
fval = open('./%s/ImageSets/val.txt'%object, 'w')
# 进行标签文件路径的写入,用于后续数据集的转换
for i in range(num):
name = total_xml[i][:-4] + '\n'
if i in train_list:
ftrain.write(name)
else:
fval.write(name)
ftrain.close()
fval.close()
1.2 新建脚本xml2txt.py :xml文件转换成txt文件,放在data数据库文件夹里
特别注意图片的后缀名,是.jpg还是.png
"""
2022.03.02
author:alian
function: xml to txt
多种数据集并存放入data数据库中
-data
-datasets(object1)
-xml
-images
-datasets(object2)
-xml
-images
-datasets(object3)
-...
"""
import xml.etree.ElementTree as ET
import shutil
import os
# 定义识别目标或类集合
object = 'datasets' # 根据自定义的数据集名称
if os.path.exists("./%s/txt/"%object): # 如果文件存在
shutil.rmtree("./%s/txt/"%object)
os.makedirs("./%s/txt/"%object)
else:
os.makedirs("./%s/txt/"%object)
sets = ['train', 'val']
# 修改类别(自定义)
classes =['Wallfitting','Distributionpanel','Advertisingboard','Balise','Sign','Abutment']
def convert(size, box): # 坐标信息归一化至0-1
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open('./%s/xml/%s.xml' % (object,image_id)) # xml文件
out_file = open('./%s/txt/%s.txt' % (object,image_id), 'w') # txt文件
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls) # 类别序号
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b) # 归一化
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
for image_set in sets:
if not os.path.exists('./%s/txt/'%object):
os.makedirs('./%s/txt/'%object)
image_ids = open('./%s/ImageSets/%s.txt' % (object,image_set)).read().strip().split()
list_file = open('./%s/%s.txt' % (object,image_set), 'w')
for image_id in image_ids:
list_file.write('./images/%s.jpg\n' % (image_id)) # 要注意图片的后缀名是什么
convert_annotation(image_id)
list_file.close()
1.3 fruit.yaml :新建文件,配置训练的数据
path: /data3/205b/Alian/yolov5/Customdata/subway
train:
- train.txt
val:
- val.txt
# number of classes
nc: 6 # 训练的类别
# class namesdata
names: ['Wallfitting','Distributionpanel','Advertisingboard','Balise','Sign','Bracket']
1.4 xml文件的修改
构建好YOLOv5使用的训练库之后,可能训练过程会遇到数据读取的问题,原因可能是xml标签文件里存在中文,或者标签出错等问题,xml文件几种修改如下:
"""
2022.03.02
author:alian
对xml文件内容的修改
"""
import xml.etree.ElementTree as ET
import glob
from pathlib import Path
# 0.检查目标标签
def check_label(xml_dir,label_list):
xmls_path = glob.glob('%s/*.xml' % (xml_dir))
error_info={}
for xml in xmls_path:
tree = ET.ElementTree(file=xml) # 打开xml文件,送到tree解析
root = tree.getroot() # 得到文档元素对象
for label in root.iter("name"):
if label.text not in label_list:
error_info[xml]=label.text
tree = ET.ElementTree(root)
tree.write(xml)
if len(error_info)==0:
print('检查完毕,标签全部正确!')
else:
print('存在以下错误标签:')
print(error_info)
# 1.修改路径
def change_path(xml_dir): # ------------------------------------------------------------------------
xmls_path = glob.glob('%s/*.xml' % (xml_dir))
for xml in xmls_path:
tree = ET.ElementTree(file=xml) # 打开xml文件,送到tree解析
root = tree.getroot() # 得到文档元素对象
old_path = Path(root.find('path').text).as_posix()
ele = old_path.split('/')[-1]
if ele.endswith('.jpg'):
root.find('path').text = xml.replace('Annotations','images').replace('.xml','.jpg')
else:
root.find('path').text = xml.replace('Annotations', 'images').replace('.xml', '.JPG')
tree=ET.ElementTree(root)
tree.write(xml)
# 2.修改目标标签,若修改多个标签,则列表中的标签名要一一对应----------------------------------
def change_label(xml_dir,oldname_list,newname_list):
xmls_path = glob.glob('%s/*.xml'%(xml_dir))
for xml in xmls_path:
tree = ET.ElementTree(file=xml) # 打开xml文件,送到tree解析
root = tree.getroot() # 得到文档元素对象
for label in root.iter("name"):
for i in range(len(oldname_list)):
if label.text == oldname_list[i]:
print('%s --> %s'%(label.text,newname_list[i]))
label.text = newname_list[i]
tree = ET.ElementTree(root)
tree.write(xml)
# 3.删除指定目标---------------------------------------------------------------------
def del_xmlobj(xml_path,del_classes): # 删除xml文件中的指定元素
# tree = ET.ElementTree(file=xml_path)
tree = ET.parse(xml_path) # 获得树
root = tree.getroot() # 获得其根
for object in root.findall('object'):
obj_name = object.find("name").text
if obj_name in del_classes:
root.remove(object)
tree.write(xml_path) # 修改后重新保存
def func_del(dir_path,del_classes):
for path in glob.glob('%s/*.xml'%dir_path):
del_xmlobj(path,del_classes)
# 4.将两个或多个同名的xml文件进行目标合并--------------------------------------------------------
def merge_xmlobj(xml_path1,xml_path2):
tree1 = ET.parse(xml_path1) # 获得树
root1 = tree1.getroot() # 获得其根
tree2 = ET.parse(xml_path2)
root2 = tree2.getroot()
ele_list = []
# 重复性判断(避免重复增加同一个目标)
for ele2 in root2.iter('object'):
dis = 0
num = 0
for ele1 in root1.iter('object'):
num+=1
if not iter_equal(ele1.find('bndbox'),ele2.find('bndbox')):
dis+=1
else:
break
if dis == num:
ele_list.append(ele2)
root1.extend(ele_list)
tree1.write(xml_path1)
def iter_equal(items1, items2): # 判断两个迭代器的内容是否相同
'''`True` if iterators `items1` and `items2` contain equal items.'''
if (items1.find('xmin').text == items2.find('xmin').text) \
and (items1.find('xmax').text == items2.find('xmax').text) \
and (items1.find('ymin').text == items2.find('ymin').text) \
and (items1.find('ymax').text == items2.find('ymax').text):
return True
else:
return False
def func_merge(dir_path1,dir_path2):
for path in glob.glob('%s/*.xml'%dir_path1):
path2 = path.replace(dir_path1,dir_path2)
if path2 in glob.glob('%s/*.xml'%dir_path2):
merge_xmlobj(path,path2)
if __name__ == '__main__':
# xml_dir = '/data3/205b/Alian/yolov5/Customdata/subway/xml'
xml_dir = '/data3/205b/Alian/yolov5/Customdata/Bracket/xml'
# 0.标签检查
# label_list = ['Wallfitting','Distributionpanel','Advertisingboard','Balise','Sign','Bracket']
label_list = ['Bracket']
check_label(xml_dir, label_list)
# 1.训练库修改中文路径
# change_path(xml_dir)
# 2.修改目标标签
# oldname_list = ['Abutment'] # 旧标签
# newname_list = ['Bracket'] # 新标签
# change_label(xml_dir, oldname_list, newname_list)
# 3.删除xml目标
# del_classes = ['Bracket'] #['Wallfitting', 'Distributionpanel', 'Advertisingboard', 'Balise', 'Sign'] # 要删除的目标
# func_del(xml_dir,del_classes)
# 4.合并xml目标
# func_merge(r'E:\Alian\yolov5\yolov5-alian\datasets\Facilities1981\22',
# r'E:\Alian\yolov5\yolov5-alian\datasets\Facilities1981\11')
确认xml文件准确无误之后,再重复上述1.1-1.3步骤,构建训练集
2 开始训练
2.1 models文件
选择什么预训练模型.pt就修改哪个.yaml文件,例如采用yolov5s.yaml:
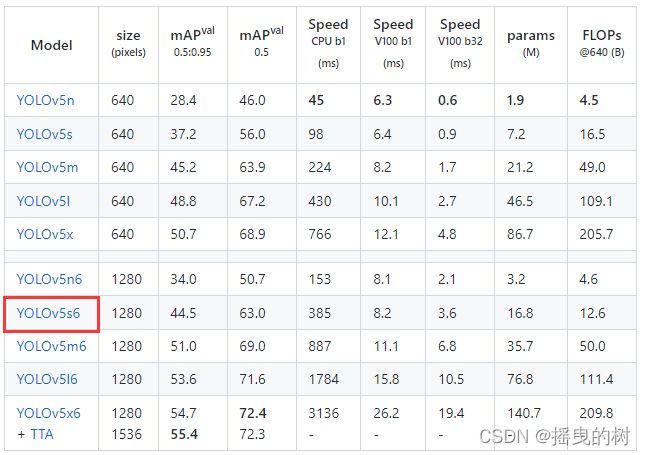
模型下载链接:https://github.com/ultralytics/yolov5/releases
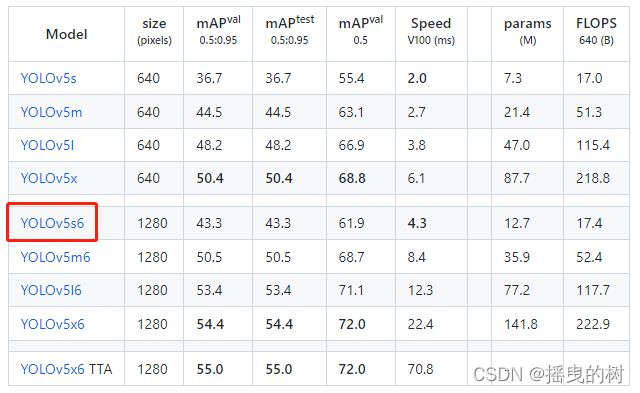
只要修改类别即可:
# YOLOv5 by Ultralytics, GPL-3.0 license
# Parameters
nc: 6 # number of classes
depth_multiple: 0.67 # model depth multiple
width_multiple: 0.75 # layer channel multiple
anchors:
- [19,27, 44,40, 38,94] # P3/8
- [96,68, 86,152, 180,137] # P4/16
- [140,301, 303,264, 238,542] # P5/32
- [436,615, 739,380, 925,792] # P6/64
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [768, 3, 2]], # 7-P5/32
[-1, 3, C3, [768]],
[-1, 1, Conv, [1024, 3, 2]], # 9-P6/64
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 11
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [768, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 8], 1, Concat, [1]], # cat backbone P5
[-1, 3, C3, [768, False]], # 15
[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 19
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 23 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 20], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 26 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 16], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [768, False]], # 29 (P5/32-large)
[-1, 1, Conv, [768, 3, 2]],
[[-1, 12], 1, Concat, [1]], # cat head P6
[-1, 3, C3, [1024, False]], # 32 (P6/64-xlarge)
[[23, 26, 29, 32], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5, P6)
2.2 修改./utils/datasets.py 374行
因为笔者将标签文件xml转换后保存再txt文件夹内,而不是源码默认的labels文件夹内

修改如下:

2.2 开始训练
进入train.py文件所在的YOLOv5项目文件夹,输入指令:
cd /data3/205b/Alian/yolov5
python train.py --data Customdata/fruit.yaml --cfg models/hub/yolov5s6.yaml --weights models/yolov5s6.pt --project logs/ --batch-size 16 --epochs 400 --img-size 1280 --device 6,7
1 --data :指定fruit.yaml的路径
2 --cfg: 指定配置文件yolov5m6.yaml的路径
3 --weights: 指定预训练权重文件的路径
4 --project:指定模型的保存路径
5 --batch-size
6 --epochs
7 --img-size # 根据预训练模型提示
8 --device: 指定GPU
3 测试
进入yolov5项目文件,运行如下命令:
python detect.py --source test --weights logs/exp/weights/best.pt --project results
1 --source:测试文件夹路径
2 --weights:模型的保存路径
3 --project:测试结果图的保存路径