Apache Druid
Apache Druid
-
- Apache Druid 介绍
- tutorials 教程
- designs 设计
-
- 进程和服务器 Processes and Servers
- 体系结构图 Architecture diagram
- 存储设计 Storage Design
-
- 数据源和片段 Datasources and segments
- 索引和切换 Indexing and handoff
- 片段标识符 Segment Identifiers
- 片段版本控制 Segment versioning
- 片段生命周期 Segment lifecycle
- 可用性和一致性 Availability and consistency
- 查询处理 Query processing
Apache Druid
官方文档:https://druid.apache.org/docs/latest/design/index.html
Apache Druid 介绍
Apache Druid 是一个实时分析数据库 real-time analytics database,用于对大型数据集进行快速切片分析(OLAP 查询)。在实时摄入(数据)、快查询表现、长时间正常运行(high uptime)等方面要求很高的场景,Druid 发挥作用。
Druid 通常作为分析系统的 GUI、需要快速聚合的高并发 apis 的后端数据库。Druid 最适合处理面向事件的数据。
Druid 的
常见应用领域;
- 包括 web、手机在内的点击流分析
- 包括网络性能监控在内的网络遥测分析
- 服务器指标存储
- 包括生产指标在内的供应链分析
- 应用程序表现指标
- 数字化营销/广告分析
- 商业智能 BI /联机分析处理 OLAP
Druid 的
主要特点 key features
- 列式存储。并且 Druid 会根据列的数据类型优化列存储,以支持快速扫描和聚合
- 可扩展的分布式系统。Druid 的经典集群配置是几十到几百个服务器。Druid 可以以每秒数百万条记录的速度摄入数据,同时保存几万亿条记录,并保持次秒(<1秒)到几秒的查询延迟。
- 大规模并行处理 Massively parallel processing。可以在集群中并行处理每个查询。
- 实时/批量摄入数据,摄取的数据可以立即用于查询
- 自愈合 self-healing,自平衡,操作方便。您可以随意地通过增加/减少服务器来扩展/缩小集群规模。Druid 集群会在后台自动重新平衡集群,不需要任何停机时间。如果某个 Druid 服务器无法正常工作,系统会自动分发数据到其他正常节点,直到损坏节点被替换。德鲁伊被设计成可以连续运行,而不会因为任何原因而计划停机。这对于配置更改和软件更新来说很重要。
- 保证了不会丢失数据的本地云和容错体系结构。摄入数据后,德鲁伊将数据的副本安全地存储在深度存储 deep storage。深度存储通常是云存储、 HDFS 或共享文件系统。你可以从深度存储中恢复你的数据,即使在所有的 Druid 服务器都损坏的情况下。对于只影响少数几个 Druid 服务器的有限故障,副本可以确保在系统恢复期间仍然可以进行查询。
- 索引,快速过滤。Druid 使用 Roaring 或 CONSISE 的压缩位图索引,以支持快速筛选和跨多列搜索。
- 基于时间的分区 Time-based partition。Druid 首先按照时间来划分分区。您可以选择性地基于其他字段实现额外的分区。因此,基于时间的查询将只访问与查询的时间范围相匹配的分区,带来显著的性能提升。
- 近似算法 Approximate algorithms。Druid 包括近似的去重计数算法,近似排名算法,并计算近似直方图和分位数。这些算法使用有限的内存,通常比精确计算快得多。对于精确比速度更重要的情况,Druid 也提供了精确的统计、排序算法。
- 在摄入数据时,自动做数据汇总。这个汇总提前聚合了数据,可能导致成本节约和性能提升。
何时使用 Druid ?
如果您的情况和下面的一些匹配,Druid 可能是一个不错的选择
- 插入频率很高,更新频率很低。
- 大多数查询是聚合和报告查询 reporting query。例如“group by”查询。可能还有搜索和扫描查询。
- 查询延迟希望在100毫秒到几秒之间。
- 数据有一个时间列。Druid 对时间有特别的优化和设计选择。
- 查询只涉及一个大的分布式表,或多个小的表。
- 高基数数据列 high cardinality data columns。例如 urls、用户 id,并需要对它们进行快速计数和排序。
- 需要从 Kafka、HDFS、平面文件 flat files 或者像 Amazon S3 这样的对象存储 object storage 中加载数据。
您可能不想使用 Druid 的情况有
- 需要通过主键对现有数据进行低延迟的更新。Druid 支持流式插入,但不支持流式更新。您可以通过后台批处理作业进行更新。
- 您正在构建的是一个离线报告系统,不要求低的查询延迟。
- 您希望执行“大”连接 “big” join,即一个大的事实表 join 另一个大的事实表,并可以接受该查询需要很长时间。
tutorials 教程
- Druid 可以从本地(通过摄入任务规范 ingestion task spec)、Kafka、Hadoop 加载文件。类 sql 查询数据。
- roll-up。可以对记录进行一些合并 combine。比如设置了分钟级的对某些列的合并,就会把这一分钟内的多条秒级的记录合并为一条分钟级的记录。(original rows -> rolled-up rows)
- 可配置数据保留 rentation(ttl)。即记录的生存时间。
- 更新现有数据。包括覆盖 overwrite 和追加 append。覆盖可以设置为普通覆盖或 roll-up 型覆盖。追加就是普通的插入。
- 压缩片段 compacting segments。将现有的 segments 压缩为更少但是更大的 segment。由于维护每个段都需要一些内存和处理的开销,所以有时候减少 segment 的数量是有益的。通过提交压缩任务规范 compaction task spec,在规范中定义压缩的要求。
- 删除数据。Druid 的 segment 的永久删除有两个步骤。1标记 segment 为未使用 “unused”。2一个 kill task 将从 Druid 的元数据存储 metadata store 和深度存储 deep storage 中删除任何 “unused” segment。
- 编写摄入规范 ingestion spec
- 转换 transforming 输入数据:在摄入期间 during ingesting 使用转换规格 transform specs 来过滤 filter 和转换 transform 输入数据。转换操作有增加列、修改列等等。
- 配置 Druid 使用 Kerberized Apache Hadoop 作为深度存储 deep storage。
designs 设计
Druid 有一个多进程的、分布式的体系结构。这个体系结构云有好 cloud-friendly、易操作。每种进程类型都可以独立配置和扩展,十分灵活。这种设计还有很强的容错能力:一个组件的中断不会立即影响其他组件。
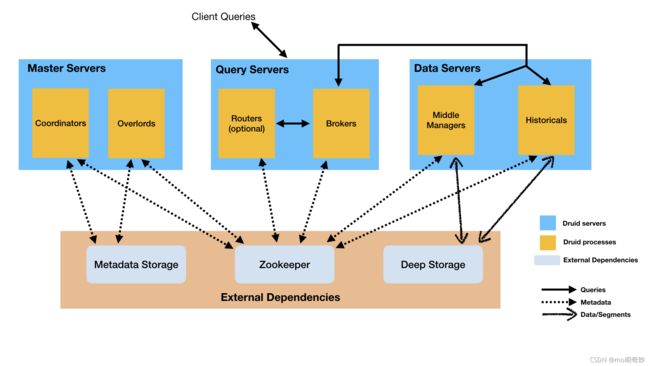
进程和服务器 Processes and Servers
Druid 的进程类型 process type 有以下几种:
- Coordinator:管理集群上的数据可用性
- Overlord:控制数据摄入负载的分配
- Broker:处理外部客户端的查询
- Router(可选):请求路由到 Coordinators,Overloads 和 Brokers
- Historical:存储可查询数据
- MiddleManager:处理摄入的数据
为了方便部署,建议将 Druid 进程组织成3种服务器类型:
- Master:运行 Coordinators 和 Overloads 进程。管理数据可用性和数据摄入。
- Query:运行 Brokers 和可选的 Routers 进程。处理来自外部客户端的查询。
- Data:运行 Historical 和 MiddleManager 进程。执行摄入工作负载 executes ingestion workloads 并存储所有可查询数据。
除了内置的进程类型,Druid 还有3个外部依赖 external dependencies。这些都是为了能利用现有的基础设施 leverage existing infrastructure。
- 深度存储 Deep Storage
深度存储会存储任何被摄入到系统中的数据。深度存储是每个 Druid 服务器都可以访问的共享文件存储。在集群部署中,深度存储往往是 S3 或 HDFS 这样的分布式对象存储,或者网络安装的文件系统 network mounted filesystem。在单服务器部署中,深度存储通常是本地磁盘。
深度存储只用作数据的备份,以及作为在 Druid 进程之间传输后台数据的一种方式。Druid 将数据存储在 segment 文件中。Historical 进程将 segment 缓存 cache 在本地磁盘上,并从该缓存提供查询服务,就像从内存中那样。这意味着查询过程中,Druid 永远不需要访问深度存储,查询延迟更低。这还意味着,你的深度存储和 Historical 服务器都得有足够的磁盘空间,用于计划加载的数据。
深度储存是 Druid 弹性、容错设计的重要组成部分。即使每个数据服务器(指 Historical)都丢失并重新配置,Druid 也可以从深层存储启动。- 元数据存储 Metadata Storage
元数据存储包含各种共享的系统元数据,如分段使用信息和任务信息。在集群部署中,这通常是传统的 RDBMS,如 PostgreSQL 或 MySQL。在单服务器部署中,它通常是本地存储的 apachederby 数据库- ZooKeeper
用于内部服务发现、协调和领导选举。Used for internal service discovery, coordination, and leader election.
体系结构图 Architecture diagram
下图显示了查询 query 和数据 data 如何在 Master/Query/Data 服务器架构中流动:
存储设计 Storage Design
数据源和片段 Datasources and segments
Druid 的数据存在数据源中,类似于 RDBMS 中的表。每个数据源都按时间进行分区 partition,还可以进一步按其他属性分区。每个时间范围成为一个块 chunk。(例如,如果您的数据源按天分区,则一个块就是一天的数据)在一个块中,数据被分为多个片段 segment。每个片段是一个单独的文件,通常包含多达数百万行数据。由于片段被组织成时间块,可以把片段想象成分布在一个时间轴上。
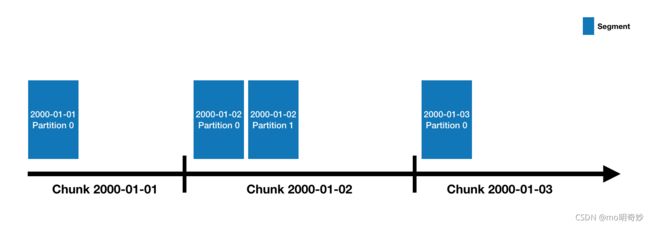
一个数据源可能有几个片段,也可能有几十万甚至几百万个片段。每个片段都是由 MiddleManager 创建的,创建时是可变的 mutable 和未提交 uncommited 的。一旦数据被添加到一个未提交的片段,数据就是可查询的 queryable。片段生成过程中会生成一个压缩的 compact 索引的 indexed 数据文件,以加速后续的查询。
- 转换为列的格式 Conversion to columnar format
- 使用位图索引进行索引 Indexing with bitmap indexes
- 压缩 Compression
– 字符串列的最小化存储id的字典编码 Dictionary encoding with id storage minimization for String columns
– 位图索引的位图压缩 Bitmap compression for bitmap indexes
– 所有列的类型识别压缩 Type-aware compression for all columns
片段会定期地被提交 commit 和发布 publish 到深度存储,成为不可变的 immutable,并从 MiddleManager 移到 Historical 线程。关于片段的条目 entry 也被记录到元数据存储中。这个条目 entry 是关于片段的元数据的自我描述位 self-describing bit,包括段的 schema、它的大小和它在深度存储上的位置。这些条目 entries 告诉 Coordinator 集群有哪些数据可用。
索引和切换 Indexing and handoff
索引 indexing 是片段创建 create 的机制 mechanism,切换 handoff 是片段发布 publish 并开始由 Historical 进程提供(查询)服务的机制。
在索引 indexing 侧:
- 一个索引任务 indexing task 开始运行并开始创建一个新的片段。索引任务会在开始创建新片段之前,确定 determine 片段的标识符 identifier。对于附加 appending 的任务(比如 Kafka 任务或附加模式下的索引任务) ,可以通过调用 Overlord 上的“ allocate”API 在现有片段的集合(这里应该指的是已经创建的该时间范围的chunk)中添加新分区。对于覆盖写 overwriting 的任务(比如 Kafka 任务或不处于附加模式的索引任务),通过锁定一个时间间隔 interval,创建一个新版本号(这里应该指该 chunk 的标识符),创建一个新的片段的集合(这里应该是每个时间范围 time range/每个时间间隔 interval,一个集合,集合中是多个片段),来实现。
- 如果索引任务是一个实时 realtime 任务(像 Kafka 任务一样) ,那么该片段此时立即可查询。它是可用的,但是还没有发布。
- 当索引任务 indexing task 完成了片段的读取后,它(指索引任务)将片段推送 push 到深度存储,并通过向元数据存储中写入一条记录来发布它(指片段)
- 如果索引任务是一个实时任务,那么为了确保数据持续可用于查询,它将等待 Historical 进程加载该片段。如果索引任务不是实时任务,它将立即退出
在 Coordinator / Historical 侧:
- Coordinator 定期轮询元数据存储(默认每分钟轮询1次),为了新发布的片段
- 当 Coordinator 发现一个发布了的、但是不可用的片段时,它(指 Coordinator)会选择并指导一个 Historical 线程加载这个片段。
- Historical 线程加载该片段并为它服务
- 此时,如果索引任务正在等待 handoff,索引任务将退出(结束等待)
片段标识符 Segment Identifiers
所有片段都有一个4部分组成的标识符,包含以下组件 components:
- 数据源名称 Datasource name
- 时间间隔(这个片段属于的 time chunk),与摄入数据时指定的 segmentGranularity 一致。
- 版本号 Version number。(通常是片段集合首次启动的时间的 iso8601 时间戳)ps:从后面例子来看,似乎是该记录的写入时间戳
- 分区号 Partition number。(一个整数 int,在(数据源, 间隔, 版本)中唯一,不一定是连续的)
例如,这是一个数据源为 clarity-cloud0,time chunk 为 2018-05-21T16:00:00.000Z/2018-05-21T17:00:00.000Z,版本号为 2018-05-21T15:56:09.909Z,分区号为 1 的片段的标识符:
clarity-cloud0_2018-05-21T16:00:00.000Z_2018-05-21T17:00:00.000Z_2018-05-21T15:56:09.909Z_1
分区号为 0 (即该 chunk 中的第一个分区)的片段,省略了分区号,例如,下面是只有分区号与上面的片段不同的一个片段的标识符,分区号为0而不是1
clarity-cloud0_2018-05-21T16:00:00.000Z_2018-05-21T17:00:00.000Z_2018-05-21T15:56:09.909Z
片段版本控制 Segment versioning
片段的版本号的作用:提供“多版本并发控制”(MVCC)。
如果只对 chunk 中的数据做附加 append 操作,那么 chunk 只会有1个版本号。但是当你覆写 overwrite 数据时,Druid 处理查询时会无缝的去查询最新的版本(而不是旧版本)。
其实在覆写时,Druid 会创建一个新的 segment。这时 chunk 中既有新的 segment,又有旧的 segment。Druid 会加载新的 segment,期间的查询还是查旧的 segment。当完成了新的 segment 的加载,Druid 将查询切换到新的 segment 上,并在几分钟后删除旧的 segment。
片段生命周期 Segment lifecycle
片段的三个主要的生命周期:
- 元数据存储 Meta Store。当一个片段构建完成,会将它发布 publish,即把片段的记录插入到元数据存储中。
- 一旦一个片段被构造完毕,片段的数据文件就会被推送到深存储器中。这发生在将元数据发布到元数据存储之前。
- 查询可用性。片段可用于在一些 Druid 服务器上进行查询。比如实时任务或 Historical 进程。
可以查询 druidsqlsys.segments 表来检查当前活动段的状态。
可用性和一致性 Availability and consistency
查询处理 Query processing
查询分布在整个 Druid 集群,由 Broker 管理。查询首先进入 Broker 进程,Broker 知道哪些数据片段是与该查询有关的。片段的列表总是随着时间(分区方式)而被修剪 pruned,也可能被其他属性修剪,取决于数据源的分区方式。Broker 知道哪些 Historicals 和 MiddleManagers 是为这些片段服务的,并向每个进程分配一个重写 rewritten 的子查询 subquery,Historic/MiddleManager 进程执行每个子查询并将结果返回给 Broker。Broker 合并部分结果以获得最终答案,并将其返回给原始调用方。
时间和其他属性的剪纸是 Druid 减少查询所需扫描的数据量的一种重要方法,但不是唯一方法。对于比 Broker 可用于剪枝的更细粒度级别的过滤器(比如不进行分区的 where 中的属性),每个片段内的索引结构允许 Historicals 在查看任何数据行之前确定哪些(如果有的话)行匹配过滤器集。一旦 Historical 知道哪些行匹配特定查询,它就只访问该查询所需的特定行和列。
因此,Druid 使用三种不同的技术来最大化查询性能:
- 修剪查询访问的片段集
- 在每个段中,使用索引标识必须访问哪些行
- 在每个段中,只读取与特定查询相关的特定行和列
暂完