Python-openpyxl之二次封装
1.excel结合测试用例的使用
测试自己写的函数是否可以正常使用,一般来说就简单的使用如下方法进行就可以:
# 使用 if __name__ == '__main__'和直接调用的区别就是其他模块中导入该模块时不会执行下面的代码
if __name__ == '__main__':
result = read_excel('cases.xlsx','Sheet1')
print(result)
excel.py文件中内容如下,读取excel数据:
from openpyxl import load_workbook
def read_excel(file,sheet_name):
# 通过文件得到一个工作薄,参数是文件名,如果有路径要写绝对路径
wb = load_workbook(file)
# 获取sheet表格
sheet = wb[sheet_name]
# 获取sheet中所有的数据
data = list(sheet.values)
# 将列表还转化为字典
dict_list = []
for i in range(1, len(data)):
dict_list.append(dict(zip(data[0], data[i])))
return dict_list
# 使用 if __name__ == '__main__'和直接调用的区别就是其他模块中导入该模块时不会执行下面的代码
if __name__ == '__main__':
result = read_excel('cases.xlsx','Sheet1')
print(result)
运行结果:

也可以编写测试用例进行调用,但一般不会使用这种方法去验证函数是否正确。
# unittest 测试函数,类下面的方法是否可以正常使用
# 也可以测试自定义的函数
# 1.准备测试数据 ,其实就是函数的实际参数 file='',sheet_name=''
# 2.准备预期结果
# 3.测试,调用read_excel函数,得到实际结果
# 实际工作当中,
from excel import read_excel
import unittest
class TestExcel(unittest.TestCase):
def test_excel(self):
file = 'cases.xlsx'
sheet_name = 'Sheet1'
excepted = [{'case_id': 1, 'data': 'kunkun', 'expected': 'ok', 'title': '测试用例1'},
{'case_id': 2, 'data': '困困', 'expected': 'not ok', 'title': '测试用例2'}]
actual = read_excel(file, sheet_name)
self.assertEqual(excepted, actual)
运行结果:
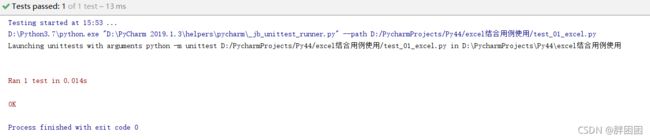
下面有个例子,调用登录函数,编写测试用例:
login函数所在funcs.py文件内容如下:
def login(username=None, pwd=None):
if username is None or pwd is None:
return {'code': '400', 'msg': '用户名或密码为空'}
if username == 'kunkun' and pwd == '123':
return {'code': '200', 'msg': '登录成功'}
return {'code': '300', 'msg': '用户名或密码错误'}test_02_login.py文件内编写测试用例:
# 准备测试数据(根据被测函数的参数)
# 调用login函数,得到实际结果
# 断言
import unittest
from funcs import login
class TestLogin(unittest.TestCase):
# 测试用例方法名以test开头
def test_login_1(self):
username = 'kunkun'
pwd = '123'
actual = login(username, pwd)
expected = {'code': '200', 'msg': '登录成功'}
self.assertEqual(expected, actual)
def test_login_2(self):
username = 'pang'
pwd = '1234'
actual = login(username, pwd)
expected = {'code': '300', 'msg': '用户名或密码错误'}
self.assertEqual(expected, actual)
def test_login_3(self):
username = None
pwd = None
actual = login(username, pwd)
expected = {'code': '400', 'msg': '用户名或密码为空'}
self.assertEqual(expected, actual)这样写测试用例,我们发现会存在大量的代码,且代码重复性高,缺点:
- 1.一个用例要单独编写一个函数,存在重复性代码(可通过数据驱动解决)
- 2.测试数据维护不方便,增加/修改,需要查找很多代码(可通过测试数据单独管理进行优化,比如放在excel当中)
缺点2,我们可以通过excel中存放测试用例数据,cases.xlsx文件存放测试用例的数据,如下:

此时我们使用for循环,实现从excel结合测试用例的使用,test_03_login_excel.py文件如下:
import unittest
from funcs import login
from excel import read_excel
data = read_excel('cases.xlsx', 'Sheet1')
class TestLogin(unittest.TestCase):
# 测试用例方法名以test开头
def test_login(self):
for row in data:
params_str = row['data']
params = eval(params_str)
username = params['username']
pwd = params['pwd']
expected = eval(row['expected'])
actual = login(username, pwd)
self.assertEqual(expected, actual)运行结果:
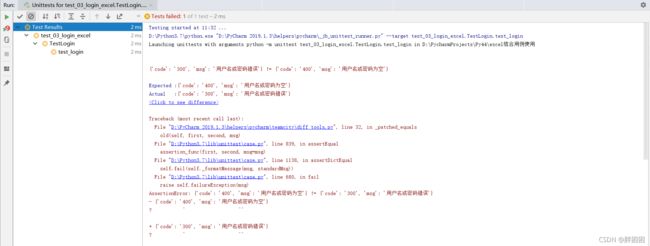
从上面例子发现,使用for循环实现测试用例方法的实现时,把所有的用例数据都当成了一个,不会自动生成单独的测试用例,这就导致了测试用例的缺失,这就引入了数据驱动(ddt)。
2.数据驱动(ddt)
针对上面的for循环可以优化:每组测试数据单独一个用例。使用数据驱动的方式:另一种叫法就是参数化 。
参数化:对于一个统一的逻辑,使用不同的参数(数据)去执行。
使用第三方库实现:ddt , unittestreport,使用前请先安装,切换到terminal,输入命令点击回车即可完成安装:pip install ddt;pip install unittestreport
2.1 unittestreport
import unittest
from funcs import login
from excel import read_excel
from unittestreport import ddt, list_data
data = read_excel('cases.xlsx', 'Sheet1')
@ddt
class TestLogin(unittest.TestCase):
@list_data(data)
def test_login(self, row):
# row表示每次从data这个list当住取出一个数据
# 代表一组测试数据,相当于for row in data
# 但不同点在于:会自动生成一个新的测试用例方法test_login_01()
params_str = row['data']
params = eval(params_str)
username = params['username']
pwd = params['pwd']
expected = eval(row['expected'])
actual = login(username, pwd)
self.assertEqual(expected, actual)运行结果:

ddt的高级之处在于,前面失败的测试用例不会影响后续的测试用例方法的生成,即ddt会根据每个不同的测试数据,自动生成新的测试用例方法。
参数化的具体使用过程:
1. 导入相应模块:form unittestreport import ddt,list_data;
2.在测试函数当中,加入参数row,row参数名称是可自定义的。
2.2 ddt
import unittest
from funcs import login
from excel import read_excel
from ddt import ddt, data
excel = read_excel('cases.xlsx', 'Sheet1')
@ddt
class TestLogin(unittest.TestCase):
@data(*excel)
def test_login(self, row):
# row表示每次从data这个list当住取出一个数据
# 代表一组测试数据,相当于for row in data
# 但不同点在于:会自动生成一个新的测试用例方法test_login_1()
params_str = row['data']
params = eval(params_str)
username = params['username']
pwd = params['pwd']
expected = eval(row['expected'])
actual = login(username, pwd)
self.assertEqual(expected, actual)运行结果:
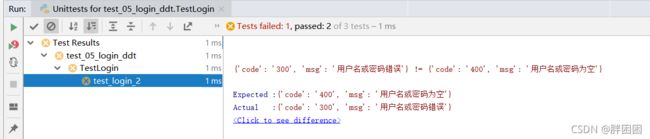
3.excel结合测试用例的用法:
-为什么要用excel单独管理用例?便于维护。
-具体用法:
1.通过read_excel方法读取excel当中的数据;
2.通过参数化完成数据到用例的结合;
3.此时用例函数只需要写一个,而用例数据可以有成千上万个,节省了很多的测试用例函数;
4.什么数据可以整合到一个用例函数?一定要是测试逻辑一致,只有数据不一致。
-注意事项:
1.excel当中不存在字典,如果单元格当中有文本,读取出来是字符串。字典是python当中的概念;
2.参数化不要用for循环,因为for循环虽然一个函数可以执行多个数据,但是所有的数据被当成一个用例,for循环不会自动生成新的测试用例方法;
3.如果测试过程当中出现了异常,一定要养成打断点的习惯。
-参数化 VS 数据驱动
1.参数化:函数参数,一个测试函数当中会带参数,该参数往往就是测试数据
2.数据驱动(data driven testing,ddt),数据驱动是一种思想。具体实现方式是参数化的方式。