python灰色关联度分析代码_GRA灰色关联度分析学习 附python代码
主要学习了这位大佬的文章,讲的也很通俗易懂了
以下的示例以及一些图片也是从大佬那边抄过来的,主要记录一下自己的学习感受.
灰色关联度分析,听名字很高大上,实际上就是算关联度的一个方法.就是想看看某几个因素中,哪个因素对事情的影响更大.比如
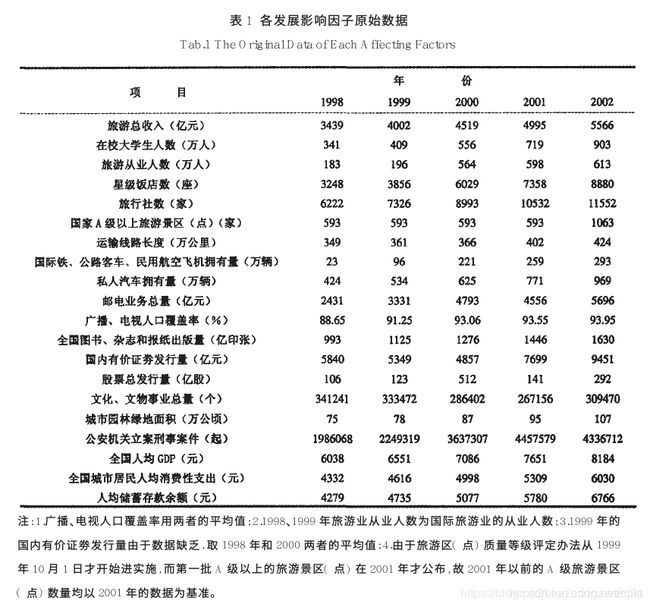
这个例子就算想看,其他这么一堆因子中,对旅游总收入的影响,哪个更大一些.个人从结果上看,还挺像熵权法的…
现在知道了就是想算影响关系,那就完成了第一步,确定子母序列,母是结果,子是影响因子.
然后第二步,就要对数据进行预处理了.就想熵权法要归一化,这个也要…看大神的说法,一般在这里是用均值化和初值化
初值化 就是每个因素都除以因素中,第一个因子的值就好了.比如在校大学生人数就是每个都除以341
均值化就是每个因素都除以因素的平均值
都挺好理解的,实际上,如果用标准化,或者归一化,会有不同的排序情况…至于为啥选初值化和均值化,不懂…
数据与处理完后,ok,对着公式操作就好.

先看rho等于0的情况
分子(就是min min那个)就是每一列(列指上面的数据图的列)第一行的数字(代表了结果)分别减下面每行(代表了影响因子)的绝对值得到一个值,然后再遍历每一列,得到这么多个值中的最小值.所以对于固定的数据来说,这个值是固定的.
大神博客中提到,初值化的话,这个分子一定是0,也很好理解,初值化都是除以第一列的值,那第一列都是1,所以1-1=0,0肯定是最小值了
分母就是第i行k列的值的具体值,结果减去影响因子的绝对值.几何意义上说,就是影响因子和结果的距离,距离越远,相关度就越低.
再考虑rho,这里就直接不想多了,rho一般取0.5然后加上去以后可以防止分子为0的情况.别的就不多研究了…max max 跟min min那个算式,前面求的是最大值,这里求的是最小值.
这样就能得到一个关联度矩阵,每个因子关联矩阵里对应位置的平均值,就是这个因子的关联度.
下附代码
这是可以直接复制使用的代码
import numpy as np
mom_ = [3439,4002,4519,4995,5566]
son_ = [[341,409,556,719,903],[183,196,564,598,613],[3248,3856,6029,7358,8880]]
mom_ = np.array(mom_)
son_ = np.array(son_)
son_ = son_.T / son_.mean(axis=1)
mom_ = mom_/mom_.mean()
for i in range(son_.shape[1]):
son_[:,i] = abs(son_[:,i]-mom_.T)
Mmin = son_.min()
Mmax = son_.max()
cors = (Mmin + 0.5*Mmax)/(son_+0.5*Mmax)
Mmean = cors.mean(axis = 0)
print(Mmean)
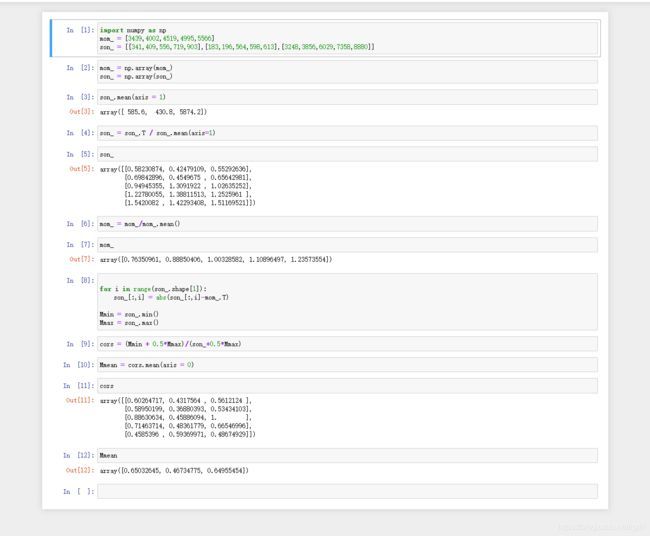
jupyter的运行过程展示,方便理解