MLflow跟踪
MLflow Tracking组件是一个API和UI,用于在运行机器学习代码时记录参数,代码版本,度量和输出文件,以及以后可视化结果。MLflow Tracking允许您使用Python,REST,R API和Java API API 记录和查询实验。
目录
- 概念
- 在哪里运行记录
- 将数据记录到运行中
- 记录功能
- 在一个程序中启动多个运行
- 绩效跟踪与指标
- 可视化度量标准
- 从TensorFlow和Keras自动记录(实验)
- 在实验中组织运行
- 使用Tracking Service API管理实验和运行
- 跟踪UI
- 以编程方式查询运行
- 引用工件
- MLflow跟踪服务器
- 存储
- 联网
- 登录到跟踪服务器
- 系统标签
概念
MLflow跟踪围绕运行的概念进行组织,运行是一些数据科学代码的执行。每次运行都记录以下信息:
代码版本
用于运行的Git提交哈希,如果它是从MLflow项目运行的。
开始和结束时间
运行的开始和结束时间
资源
如果从MLflow项目运行,则启动运行的文件的名称,或运行的项目名称和入口点。
参数
您选择的键值输入参数。键和值都是字符串。
度量
键值指标,其中值为数字。每个指标都可以在整个运行过程中更新(例如,跟踪模型的损失函数如何收敛),以及MLflow记录,并让您可视化指标的完整历史记录。
文物
以任何格式输出文件。例如,您可以将图像(例如,PNG),模型(例如,酸洗的scikit-learn模型)和数据文件(例如,Parquet文件)记录为工件。
您可以从运行代码的任何位置使用MLflow Python,R,Java和REST API记录运行。例如,您可以将它们记录在独立程序,远程云计算机或交互式笔记本中。如果您在MLflow项目中记录运行,MLflow会记住项目URI和源版本。
您可以选择将运行组织到实验中,这些组一起运行以执行特定任务。您可以使用CLI,使用 或使用相应的REST参数创建实验。MLflow API和UI允许您创建和搜索实验。mlflow experimentsmlflow.create_experiment()
记录完运行后,您可以使用Tracking UI或MLflow API 查询它们。
在哪里运行记录
MLflow运行可以记录到本地文件,SQLAlchemy兼容数据库或远程跟踪服务器。默认情况下,MLflow Python API日志在本地运行到mlruns您运行程序的目录中的文件。然后,您可以运行以查看已记录的运行。mlflow ui
要远程记录运行,请将MLFLOW_TRACKING_URI环境变量设置为跟踪服务器的URI或调用mlflow.set_tracking_uri()。
有不同种类的远程跟踪URI:
- 本地文件路径(指定为
file:/my/local/dir),其中数据直接存储在本地。 - 数据库编码为
+ :// : @ : / mysql,mssql,sqlite,和postgresql。有关更多详细信息,请参阅SQLAlchemy数据库uri。 - HTTP服务器(指定为
https://my-server:5000),它是托管MLFlow跟踪服务器的服务器。 - Databricks工作区(指定为
databricks或如databricks://,一个Databricks CLI轮廓。
将数据记录到运行中
您可以使用MLflow Python,R,Java或REST API将数据记录到运行中。本节介绍Python API。
在这个部分:
- 记录功能
- 在一个程序中启动多个运行
- 绩效跟踪与指标
- 可视化度量标准
记录功能
mlflow.set_tracking_uri()连接到跟踪URI。您还可以设置 MLFLOW_TRACKING_URI环境变量,让MLflow从那里查找URI。在这两种情况下,URI都可以是远程服务器的HTTP / HTTPS URI,数据库连接字符串或将数据记录到目录的本地路径。URI默认为mlruns。
mlflow.tracking.get_tracking_uri() 返回当前跟踪URI。
mlflow.create_experiment()创建一个新实验并返回其ID。可以通过将实验ID传递给实验来启动运行mlflow.start_run。
mlflow.set_experiment()将实验设置为活动状态。如果实验不存在,请创建一个新实验。如果您未指定实验mlflow.start_run(),则会在此实验下启动新运行。
mlflow.start_run()返回当前活动的运行(如果存在),或者启动新运行并返回mlflow.ActiveRun可用作当前运行的上下文管理器的对象。您不需要start_run显式调用:调用其中一个没有活动运行的日志记录功能会自动启动一个新的日志功能。
mlflow.end_run() 结束当前活动的运行(如果有),采用可选的运行状态。
mlflow.active_run()返回mlflow.entities.Run与当前活动的运行相对应的对象(如果有)。
mlflow.log_param()在当前活动的运行中记录单个键值参数。键和值都是字符串。用于mlflow.log_params()一次记录多个参数。
mlflow.log_metric()记录单个键值指标。该值必须始终为数字。MLflow会记住每个指标的值历史记录。用于mlflow.log_metrics()一次记录多个指标。
mlflow.set_tag()在当前活动的运行中设置单个键值标记。键和值都是字符串。用于mlflow.set_tags()一次设置多个标签。
mlflow.log_artifact()将本地文件记录为工件,可选择 artifact_path将其放入运行的工件URI中。运行工件可以组织到目录中,因此您可以通过这种方式将工件放在目录中。
mlflow.log_artifacts()将给定目录中的所有文件记录为工件,再次选择可选项artifact_path。
mlflow.get_artifact_uri() 返回应记录当前运行的工件的URI。
在一个程序中启动多个运行
有时您希望在同一程序中启动多个MLflow运行:例如,您可能在本地执行超参数搜索,或者您的实验运行速度非常快。这很容易做到,因为ActiveRun返回的对象mlflow.start_run()是Python 上下文管理器。您可以将每个运行“范围”到一个代码块,如下所示:
with mlflow.start_run():
mlflow.log_param("x", 1)
mlflow.log_metric("y", 2)
...
运行在整个with语句中保持打开状态,并在语句退出时自动关闭,即使它由于异常而退出。
绩效跟踪与指标
您可以使用logTracking API中的方法记录MLflow指标。这些log方法支持两种在x轴上区分度量值的替代方法:timestamp和step。
timestamp是一个可选的long值,表示记录度量标准的时间。timestamp默认为当前时间。step是一个可选的整数,表示任何训练进度的测量值(训练迭代次数,时期数等)。step默认为0并具有以下要求和属性:
- 必须是有效的64位整数值。
- 可以是消极的。
- 在连续写入调用中可能出现故障。例如,(1,3,2)是有效序列。
- 在连续写入调用中指定的值序列中可以有“间隙”。例如,(1,5,75,-20)是有效序列。
如果同时指定时间戳和步骤,则会针对两个轴单独记录度量标准。
例子
蟒蛇
with mlflow.start_run():
for epoch in range(0, 3):
mlflow.log_metric(key="quality", value=2*epoch, step=epoch)
Java和Scala
MlflowClient client = new MlflowClient();
RunInfo run = client.createRun();
for (int epoch = 0; epoch < 3; epoch ++) {
client.logMetric(run.getRunId(), "quality", 2 * epoch, System.currentTimeMillis(), epoch);
}
可视化度量标准
以下是带有步长x轴和两个时间戳轴的快速入门教程的示例图:

X轴步骤

X轴墙时间 - 绘制每个度量标准的绝对时间
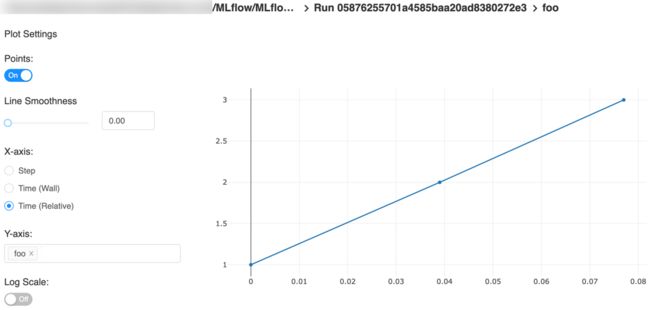
X轴相对时间 - 为每次运行绘制相对于记录的第一个度量标准的时间
从TensorFlow和Keras自动记录(实验)
调用mlflow.tensorflow.autolog()或mlflow.keras.autolog()在您的培训代码之前启用指标和参数的自动记录,而无需显式日志语句。请参阅使用Keras和 TensorFlow的示例用法。
自动记录功能可捕获以下信息:
| 骨架 | 度量 | 参数 | 标签 | 文物 |
| 硬 | 训练损失; 验证损失; 用户指定的指标 | 层数; 优化器名称; 学习率; 小量 | 模型摘要 | MLflow模型(Keras模型),TensorBoard日志; 在训练结束 |
tf.keras |
训练损失; 验证损失; 用户指定的指标 | 层数; 优化器名称; 学习率; 小量 | 模型摘要 | MLflow模型(Keras模型),TensorBoard日志; 在训练结束 |
tf.estimator |
TensorBoard指标 | - | - | MLflow模型(TF保存模型); 随叫随到tf.estimator.export_saved_model |
| TensorFlow核心 | 所有tf.summary.scalar电话 |
- | - | - |
请注意,自动记录tf.keras是由mlflow.tensorflow.autolog(),而不是mlflow.keras.autolog()。
注意:此功能是实验性的 - 记录数据的API和格式可能会发生变化。
在实验中组织运行
MLflow允许您在实验下对运行进行分组,这对于比较旨在处理特定任务的运行非常有用。您可以使用命令行界面()或Python API 创建实验。您可以使用CLI(例如,)或 环境变量传递单个运行的实验名称。或者,您可以通过CLI标志或环境变量来使用实验ID。mlflow experimentsmlflow.create_experiment()mlflow run ... --experiment-name [name]MLFLOW_EXPERIMENT_NAME--experiment-idMLFLOW_EXPERIMENT_ID
# Set the experiment via environment variables
export MLFLOW_EXPERIMENT_NAME=fraud-detection
mlflow experiments create --experiment-name fraud-detection
# Launch a run. The experiment is inferred from the MLFLOW_EXPERIMENT_NAME environment
# variable, or from the --experiment-name parameter passed to the MLflow CLI (the latter
# taking precedence)
with mlflow.start_run():
mlflow.log_param("a", 1)
mlflow.log_metric("b", 2)
使用Tracking Service API管理实验和运行
MLflow提供了更详细的跟踪服务API,用于管理实验并直接运行,可通过mlflow.tracking模块中的客户端SDK获得。这样就可以查询有关过去运行的数据,记录有关它们的其他信息,创建实验,为运行添加标记等。
例
from mlflow.tracking import MlflowClient
client = MlflowClient()
experiments = client.list_experiments() # returns a list of mlflow.entities.Experiment
run = client.create_run(experiments[0].experiment_id) # returns mlflow.entities.Run
client.log_param(run.info.run_id, "hello", "world")
client.set_terminated(run.info.run_id)
添加标签到运行
该mlflow.tracking.MlflowClient.set_tag()功能允许您为运行添加自定义标签。标记一次只能映射一个唯一值。例如:
client.set_tag(run.info.run_id, "tag_key", "tag_value")
重要
不要mlflow为标记使用前缀。此前缀保留供MLflow使用。
跟踪UI
跟踪UI允许您可视化,搜索和比较运行,以及下载运行工件或元数据以便在其他工具中进行分析。如果您将运行记录到本地mlruns目录,请在其上方的目录中运行,并加载相应的运行。或者,MLflow跟踪服务器提供相同的UI并启用运行工件的远程存储。mlflow ui
UI包含以下主要功能:
- 基于实验的运行列表和比较
- 按参数或度量标准值搜索运行
- 可视化运行指标
- 下载运行结果
以编程方式查询运行
您可以以编程方式访问Tracking UI中的所有功能。这样可以轻松完成几项常见任务:
- 使用您选择的任何数据分析工具(例如pandas)查询和比较运行。
- 确定运行的工件URI,以便在执行工作流时将其某些工件提供给新运行。有关查询运行和构建多步骤工作流的示例,请参阅MLflow多步骤工作流示例项目。
- 从过去的运行中加载工件作为MLflow模型。有关训练,导出和加载模型以及使用模型进行预测的示例,请参阅MLFlow TensorFlow示例。
- 运行自动参数搜索算法,您可以在其中查询各种运行中的指标以提交新指标。有关运行自动参数搜索算法的示例,请参阅MLflow Hyperparameter Tuning Example项目。
引用工件
在MLflow API中指定工件的位置时,语法取决于您是否正在调用Tracking,Models或Projects API。对于Tracking API,您可以使用(运行ID,相对路径)元组指定工件位置。对于Models和Projects API,您可以通过以下方式指定工件位置:
/Users/me/path/to/local/modelrelative/path/to/local/model/ s3://my_bucket/path/to/modelhdfs://: / runs://run-relative/path/to/model
例如:
跟踪API
mlflow.log_artifacts("" , "/path/to/artifact")
模型API
mlflow.pytorch.load_model("runs://run-relative/path/to/model" )
MLflow跟踪服务器
在这个部分:
- 存储
- 神器商店
- 联网
- 登录到跟踪服务器
您使用运行MLflow跟踪服务器。服务器的示例配置是:mlflow server
mlflow server \
--backend-store-uri /mnt/persistent-disk \
--default-artifact-root s3://my-mlflow-bucket/ \
--host 0.0.0.0
存储
MLflow跟踪服务器有两个用于存储的组件:后端存储和工件存储。
后端存储是MLflow Tracking Server存储实验和运行元数据以及运行的参数,指标和标记的位置。MLflow支持两种类型的后端存储:文件存储和 数据库支持的存储。
使用--backend-store-uri配置后台存储的类型。您将文件存储 后端指定为./path_to_store或file:/path_to_store将数据库支持的存储指定为 SQLAlchemy数据库URI。数据库URI通常采用该格式mysql,mssql,sqlite,和postgresql。司机是可选的。如果未指定驱动程序,SQLAlchemy将使用方言的默认驱动程序。例如,将使用本地SQLite数据库。--backend-store-uri sqlite:///mlflow.db
重要
mlflow server将使用过时的数据库架构对数据库支持的存储失败。要防止这种情况,请使用将数据库架构升级到最新支持的版本 。架构迁移可能导致数据库停机,在较大的数据库上可能需要更长时间,并且不能保证是事务性的。在运行之前,应始终备份数据库- 有关备份的说明,请参阅数据库的文档。mlflow db upgrade [db_uri]mlflow db upgrade
默认--backend-store-uri设置为本地./mlruns目录(与本地运行时相同),但在运行服务器时,请确保指向持久(即非短暂)文件系统位置。mlflow run
工件存储是适合大型数据(例如S3存储桶或共享NFS文件系统)的位置,并且是客户端记录其工件输出的位置(例如,模型)。artifact_location是mlflow.entities.Experiment在此实验中为所有运行存储工件的默认位置记录的属性。另外,artifact_uri 是一个属性,mlflow.entities.RunInfo用于指示存储此运行的所有工件的位置。
使用--default-artifact-root(默认为本地./mlruns目录)配置服务器工件存储的默认位置。这将用作新创建的未指定实验的实验的工件位置。创建实验后,--default-artifact-root 与该实验不再相关。
要允许服务器和客户端访问工件位置,您应该正常配置云提供程序凭据。例如,对于S3,您可以设置AWS_ACCESS_KEY_ID和AWS_SECRET_ACCESS_KEY环境变量,使用IAM角色或配置默认配置文件~/.aws/credentials。有关详细信息,请参阅设置AWS凭据和开发区域。
重要
如果--default-artifact-root在创建实验时未指定工件URI或工件URI(例如,),工件根目录是文件存储中的路径。通常,这不是一个合适的位置,因为客户端和服务器可能引用不同的物理位置(即不同磁盘上的相同路径)。mlflow experiments create --artifact-location s3://
神器商店
在这个部分:
- 亚马逊S3
- Azure Blob存储
- Google云端存储
- FTP服务器
- SFTP服务器
- NFS
- HDFS
除了本地文件路径之外,MLflow还支持以下存储系统作为工件存储:Amazon S3,Azure Blob存储,Google云存储,SFTP服务器和NFS。
亚马逊S3
要在S3中存储工件,请指定表单的URI s3://。MLflow从您的计算机的IAM角色,配置文件~/.aws/credentials或环境变量中获取凭据以访问S3 AWS_ACCESS_KEY_ID,AWS_SECRET_ACCESS_KEY具体取决于哪些可用。有关如何设置凭据的更多信息,请参阅 设置AWS凭据和要开发的区域。
要将工件存储在自定义端点中,请将端口设置为MLFLOW_S3_ENDPOINT_URLURL。例如,如果端口9000上有一个位于1.2.3.4的Minio服务器:
export MLFLOW_S3_ENDPOINT_URL=http://1.2.3.4:9000
Azure Blob存储
要在Azure Blob存储中存储工件,请指定表单的URIwasbs://。MLflow预计将在Azure存储访问凭据AZURE_STORAGE_CONNECTION_STRING或AZURE_STORAGE_ACCESS_KEY环境变量(宁愿一个连接字符串,如果已设置),所以你必须设置两个客户端应用程序和MLflow跟踪服务器这些变量之一。最后,您必须 单独运行(在客户端和服务器上)以访问Azure Blob存储; 默认情况下,MLflow不会声明对此包的依赖性。pip install azure-storage
Google云端存储
要在Google云端存储中存储工件,请指定表单的URI gs://。您应该按照GCS文档中的说明配置用于访问客户端和服务器上的GCS容器的凭据。最后,您必须(在客户端和服务器上)运行以访问Google云端存储; 默认情况下,MLflow不会声明对此包的依赖性。pip install google-cloud-storage
FTP服务器
要在FTP服务器中存储工件,请指定格式为ftp:// user @ host / path / to / directory的URI 。URI可以可选地包括用于登录服务器的密码,例如ftp://user:pass@host/path/to/directory
SFTP服务器
要在SFTP服务器中存储工件,请指定表单的URI sftp://user@host/path/to/directory。您应该将客户端配置为能够在没有SSH密码的情况下登录SFTP服务器(例如,公钥,ssh_config中的身份文件等)。
sftp://user:pass@host/登录时支持该格式。但是,出于安全原因,不建议这样做。
使用此存储时,pysftp必须同时安装在服务器和客户端上。运行以安装所需的包。pip install pysftp
NFS
要将工件存储在NFS安装中,请将URI指定为普通文件系统路径,例如/mnt/nfs。服务器和客户端上的此路径必须相同 - 您可能需要使用符号链接或重新安装客户端以强制执行此属性。
HDFS
要在HDFS中存储工件,请指定hdfs:URI。它可以包含主机和端口:hdfs://或只包含路径:hdfs://。
还有两种方法可以对HDFS进行身份验证:
- 使用当前的UNIX帐户授权
- 使用以下环境变量的Kerberos凭据:
export MLFLOW_KERBEROS_TICKET_CACHE=/tmp/krb5cc_22222222
export MLFLOW_KERBEROS_USER=user_name_to_use
大多数群集竞赛设置都是hdfs-site.xml使用CLASSPATH环境变量从HDFS本机驱动程序访问的。
您可以选择使用以下方法选择不同版本的HDFS驱动程序库:
export MLFLOW_HDFS_DRIVER=libhdfs3
默认驱动程序是libhdfs。
联网
该--host选项在所有接口上公开服务。如果在生产中运行服务器,我们建议不要广泛地公开内置服务器(因为它是未经身份验证和未加密的),而是将其置于反向代理(如NGINX或Apache httpd)之后,或通过VPN连接。然后,您可以使用这些环境变量将身份验证标头传递给MLflow 。
此外,您应确保--backend-store-uri(默认为 ./mlruns目录)指向持久(非短暂)磁盘或数据库连接。
登录到跟踪服务器
要登录到跟踪服务器,请将MLFLOW_TRACKING_URI环境变量及其方案和端口(例如http://10.0.0.1:5000)或调用设置为服务器的URI mlflow.set_tracking_uri()。
然后mlflow.start_run(),mlflow.log_param()和mlflow.log_metric()调用会向远程跟踪服务器发出API请求。
import mlflow
with mlflow.start_run():
mlflow.log_param("a", 1)
mlflow.log_metric("b", 2)
除了MLFLOW_TRACKING_URI环境变量之外,以下环境变量还允许将HTTP身份验证传递给跟踪服务器:
MLFLOW_TRACKING_USERNAME和MLFLOW_TRACKING_PASSWORD- 用于HTTP基本身份验证的用户名和密码。要使用基本身份验证,必须设置两个环境变量。MLFLOW_TRACKING_TOKEN- 用于HTTP承载认证的令牌。如果设置,则基本身份验证优先。MLFLOW_TRACKING_INSECURE_TLS- 如果设置为文字true,MLflow不会验证TLS连接,这意味着它不会验证用于https://跟踪URI的证书或主机名。建议不要在生产环境中使用此标志。
系统标签
您可以使用任意标记注释运行。开头的标记键mlflow.保留供内部使用。适当时,MLflow会自动设置以下标记:
| 键 | 描述 |
|---|---|
mlflow.runName |
标识此运行的人类可读名称。 |
mlflow.parentRunId |
父运行的ID(如果这是嵌套运行)。 |
mlflow.user |
创建运行的用户的标识符。 |
mlflow.source.type |
来源类型。可能的值:"NOTEBOOK","JOB","PROJECT", "LOCAL",和"UNKNOWN" |
mlflow.source.name |
源标识符(例如,GitHub URL,本地Python文件名,笔记本名称) |
mlflow.source.git.commit |
如果在git存储库中,则提交已执行代码的哈希值。 |
mlflow.source.git.branch |
如果在git存储库中,则执行代码的分支的名称。 |
mlflow.source.git.repoURL |
从中克隆执行代码的URL。 |
mlflow.project.env |
MLflow项目使用的运行时上下文。可能的值:"docker"和"conda"。 |
mlflow.project.entryPoint |
与当前运行关联的项目入口点的名称(如果有)。 |
mlflow.docker.image.name |
用于执行此运行的Docker镜像的名称。 |