算法工程师15——数据结构与算法加强版
数据结构+算法=程序
- 1 计算复杂性
-
- 1.1 算法评价指标
-
- 1.1.1 大O计法就用来实现算法的评判
- 1.1.2 程序可读性的重要性
- 2 python数据类型
-
- 2.1 列表
- 2.2 字典
- 2.3 python官网公开的算法复杂度
- 3 线性结构(一对一,必须是一个连一个,4种基本的线性结构)
-
- 3.1 栈
-
- 3.1.1 python实现栈
- 3.1.2 栈的应用
- 3.2 队列
-
- 3.2.1 python实现队列
- 3.2.2 热土豆问题
- 3.3 双端队列
- 3.4 无序表(不安数据内容的大小排序)
-
- 3.4.1 列表实现无序表
- 3.4.2 链表实现无序表
- 3.4.2.1 链表的实现
- 3.5 有序表
- 4 几种解决问题的策略
-
- 4.1 递归Recursion
-
- 4.1.1 数列求和
- 4.1.2 海归作图分形树(具有自相似的物体)
- 4.1.3 递归解决最少找零钱数量问题
- 4.1.4 总结
- 4.2 分治策略
- 4.3 贪心策略
- 4.4 动态规划
- 5 查找
-
- 5.1 顺序查找
- 5.2 二分查找
- 6 排序
-
- 6.1 冒泡排序
- 6.2 选择排序
- 6.3 插入排序
- 6.4 希尔排序
- 6.5 归并排序
- 6.6 快速排序
- 6.7
- 6.8
- 7 散列(哈希表)
-
- 7.1 散列函数
- 7.2 区块链
- 7.3 散列函数;
- 7.4 冲突解决方案
- 7.5 映射
- 8 树
-
- 8.1 树的三大特性
- 8.2 树的术语
- 8.3 实现树
-
- 8.3.1 嵌套列表法实现树
- 8.3.2 节点链接法实现树(单向链表)
- 8.4 树的应用
- 8.5 树的遍历
- 9 二叉树
-
- 9.1 完全二叉树实现二叉堆
- 9.2 二叉查找树
- 9.3 平衡二叉查找树(AVL树)
- 10 图
-
- 10.1 基本概念
- 10.2 图的实现
- 10.2.1 用邻接举证实现(耗费空间)
-
- 10.2.2 邻接列表
- 10.3 有向图的实现
- 10.4 几种搜索方式
-
- 10.4.1 广度优先
- 10.4.2 深度优先
- 10.5 图的应用
-
- 10.5.1 词梯问题
- 10.5.2 骑士周游问题
- 10.5.3 拓扑排序
- 10.5.4 强连通分支
- 10.5.5 最短路径问题
- 10.5.6 最小生成树
- 11需要会的代码
-
- 11.1 数据结构的实现,主要是结构和基本方法(增删改查,len)
- 11.2 算法
- 11.3 查找
- 11.4 排序
- 11.5 树
- 11.6 图
- 12 总结
- 参考资料
1 计算复杂性
算法必须符合有穷能运行,有一些人类可以解决但是计算机无法解决的问题




分工不同,做底层的给你提供算法结构,函数结构,普通程序员可以调用实现功能,但是底层程序员可以不断优化函数内部实现,你外部只管调用就行了,不用关注里面是怎么实现的。

算法是逻辑层面上的,程序运行时物理层面上的。
1.1 算法评价指标



接下来大O计发横空出世
1.1.1 大O计法就用来实现算法的评判





关注主流的,大多数情况下的复杂度,而不的只看一些特殊的。


1.1.2 程序可读性的重要性
两个不同程序员实现的从1到n累加



2 python数据类型

2.1 列表

不同的方法耗时差距太大,最慢和最快相差2000倍的时间。


2.2 字典

2.3 python官网公开的算法复杂度

3 线性结构(一对一,必须是一个连一个,4种基本的线性结构)


栈:堆盘子
队列:排队

3.1 栈
比如堆盘子,先取上面的才能取下面的,撤销功能,就是栈的实现

3.1.1 python实现栈

3.1.2 栈的应用
(1)简单括号的匹配
(2)复杂括号匹配

(3)十进制二进制转换
二进制转为十进制,就是看位数,2**(n-1),对每个位置上的树相加
十进制转二进制,就是每次都除以2求余数

十进制转二进制

3.2 队列
排队买东西,计算机里的打印机,cpu任务等待

3.2.1 python实现队列
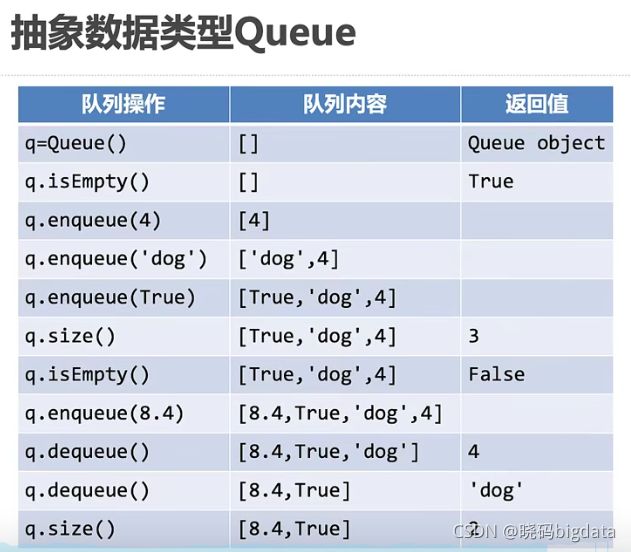
下面以list的右边作为队首,如果以左边的话用append等函数即可

3.2.2 热土豆问题

3.3 双端队列
首尾都可以进出



3.4 无序表(不安数据内容的大小排序)

顺序存储和链式存储有不一样的实现



3.4.1 列表实现无序表
列表实现的话存储位置是连续的
3.4.2 链表实现无序表
这样存储位置不连续,可以实现插入复杂度为O(n)
(1)节点的实现
(2)链表的实现,主要是注意头节点和尾节点





3.4.2.1 链表的实现



3.5 有序表

4 几种解决问题的策略
4.1 递归Recursion
将复杂问题可以分为一个个相同步骤的时候用递归

4.1.1 数列求和


三个重要的注意项


4.1.2 海归作图分形树(具有自相似的物体)



4.1.3 递归解决最少找零钱数量问题





4.1.4 总结

4.2 分治策略
比如各个省由省长管理,分成各个县,县长管理
递归算法是一种典型的分治策略算法

4.3 贪心策略
找零钱时候,给的硬币数量最少

4.4 动态规划

动态规划表格,行好i代表宝物id号,列号代表限制的重量,单元格表示价值,是前i个里面选一个的最大值

使用动态规划

使用递归解法

5 查找
5.1 顺序查找
用for更简单,while是另外一种思路

5.2 二分查找
二分查找前必须先排好序




6 排序
6.1 冒泡排序
每一趟排序一次,需要n-1躺
同时每趟要执行n-已跑趟数
所有需要两个for循环

6.2 选择排序


6.3 插入排序
先拿出第一个作为子列,然后看第二个应该放到第一个前面还是后面
总之先外层循环一轮,拿出第k个值,然后内层循环,把拿出的这个值和前面拍好序的值比较,看看该放到哪里。
和我们打牌时整理牌的过程几乎一样
类似于拿到扑克牌时候的排序




6.4 希尔排序
因为插入排序的话,如果是已经排序好的,那执行速度就快。
希尔排序把整个列表先分成几个小部分,小部分排序好之后,再进行整体排序




6.5 归并排序



储存的空间增加了1倍

6.6 快速排序






6.7
堆排序就是用后面的二叉堆进行排序
6.8


7 散列(哈希表)
我们最重要的是找到数据储存的位置,这样知道位置直接查找就很简单了。
哈希表就是需要将数据和位置对应,知道数据了就能推出它的位置。
(1)散列
(2)散列函数
(3)负载因子








7.1 散列函数



直接对比得到了唯一值,看文件是否相同


7.2 区块链
分布式数据库




散列值生成很快,但是你需要在在全网同步,所以需要控制区块生成的速度。


相当于抢资源
7.3 散列函数;




7.4 冲突解决方案
(1)线性探测
(2)数据项链





7.5 映射
在python中就是字典



key是用哈希表存储的,data和key位置对应,找到key就能找到data
8 树

8.1 树的三大特性



8.2 树的术语





8.3 实现树
8.3.1 嵌套列表法实现树





实现树的嵌套


8.3.2 节点链接法实现树(单向链表)



8.4 树的应用




使用递归实现

用字典代替if语句
8.5 树的遍历



树的遍历,另外一种实现方法,放到类中

9 二叉树

9.1 完全二叉树实现二叉堆
优先队列


每次能得到最小值,但是又没有进行排序

任何一条路径是排序好的,不同的路径不是排好序的
二叉堆的关键就是任何节点的父节点都比它小






9.2 二叉查找树
为了方便查找,对二叉树进行特殊的编排的二叉树



二叉查找树的实现





9.3 平衡二叉查找树(AVL树)
为了改进二叉查找树的性能,让左右树平衡,


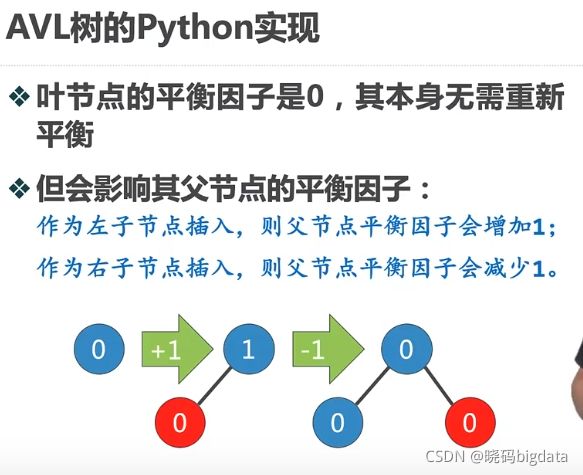









10 图
(1)无向图
(2)有向无环图
(3)有向带环图


10.1 基本概念


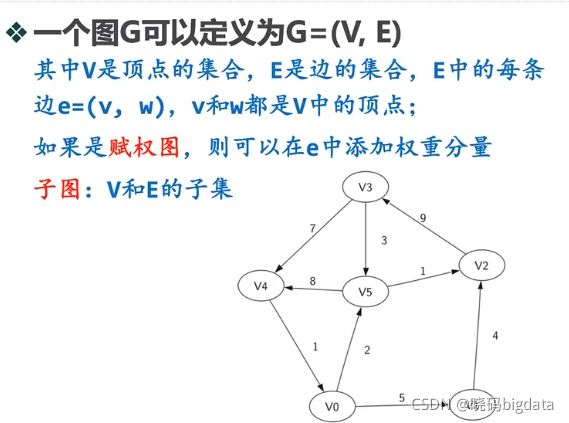



10.2 图的实现

10.2.1 用邻接举证实现(耗费空间)


10.2.2 邻接列表


10.3 有向图的实现



10.4 几种搜索方式
10.4.1 广度优先



10.4.2 深度优先

10.5 图的应用
10.5.1 词梯问题








10.5.2 骑士周游问题














10.5.3 拓扑排序
工程问题用拓扑排序,用有向无环图解决。



10.5.4 强连通分支



10.5.5 最短路径问题



10.5.6 最小生成树





11需要会的代码
11.1 数据结构的实现,主要是结构和基本方法(增删改查,len)
(1)栈的实现
(2)队列的实现
(3)双向队列
(4)单向链表(节点和链表两个class,注意头节点和尾节点)
(5)双向链表的实现
11.2 算法
(6)递归的实现,进行列表的相加
(7)递归实现找零问题以及改进代码
https://www.bilibili.com/video/BV1VC4y1x7uv?p=41
(8)动态规划实现博物馆大盗的问题
11.3 查找
(9)顺序查找的while实现
(10)二分查找
(11)二分查找的递归实现
11.4 排序
(12)冒泡排序
(13)选择排序
(14)插入排序
(15)希尔排序
(16)归并排序
(17)快速排序
11.5 树
(18)树的列表实现
(19)树的链表实现
(20)树的三种遍历方式,使用外部函数的方法
(21)树的三种遍历方式,使用类内部函数的方法
(22)二叉堆
(23)二叉查找树
(24)平衡二叉树
11.6 图
(25)图的实现
(26)词梯问题(最短路径)
(27)骑士周游
(28)广度搜索
(29)深度搜索
(30)最短路径
(31)拓扑排序算法
(32)最小生成树
12 总结
(1)不同算法有不同优势,看你实际应用,要相互匹配
(2)解决算法题,先找到解决思路,不要先编程,有了思路和步骤以后再去编程实现。
(3)启发式规则在算法中加入一些人为的调整规定,缩短搜索时间和算法时间。
(4)刷题,刷题就是数据结构
参考资料
【1】非常好:【北京大学】数据结构与算法Python版(完整版)_哔哩哔哩_bilibili
https://www.bilibili.com/video/BV1VC4y1x7uv?p=7&spm_id_from=pageDriver
[2] 一些算法的可视化过程
https://www.cs.usfca.edu/~galles/visualization/Algorithms.html