经过前面三天的学习,Node.js的基础知识已逐渐掌握,今天继续学习缓存区和文件操作,并稍加整理加以分享,如有不足之处,还请指正。
缓存区
1. 什么是缓存区?
JavaScript语言自身只有基本数据类型(如:字符串),没有二进制数据类型。二进制数据可以存储电脑中任何数据(如:一段文本,一张图片等)。Node.js作为服务端,在处理TCP网络流或文件流时,必须使用到二进制数据。因此在Node.js中定义了一个Buffer类,用来创建一个专门存放二进制数据的缓存区。所以缓存区就是在内存中开辟一个临时用于存储需要运算的字节码的区域。
2. 创建指定长度的缓存区
在Node.js中提供了一个Buffer对象,可以直接创建指定长度的缓存区,如下所示:
var buffer = Buffer.alloc(10);;
buffer.write('abcdefghij');
console.log(buf);
示例输出结果,如下所示:
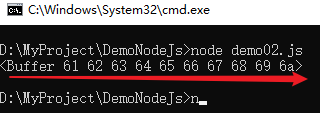
通过以上示例可以看出,写入的一串英文字符,在缓存区中是以十六进制格式显示的。
关于字符的十六进行表示,可以参考ASCII ((American Standard Code for Information Interchange): 美国信息交换标准代码)。
ASCII ((American Standard Code for Information Interchange): 美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言。它是最通用的信息交换标准,并等同于国际标准ISO/IEC 646。ASCII第一次以规范标准的类型发表是在1967年,最后一次更新则是在1986年,到目前为止共定义了128个字符 [1] 。示例如下所示:

在缓存区存储汉字的时候,也会转换成UTF-8编码的字节码,并以十六进制表示,如下所示:
var buffer = Buffer.alloc(10);
buffer.write('张三');
console.log(buffer);
示例如下所示:

通过以上示例,可以看出,在Node.js中,采用UTF-8编码,1个英文字符占1个字节;1个中文汉字3-4个字节(UTF-8编码是变长的)。
3. 通过数组创建缓存区
在Node.js中,通过数组创建缓存区,如下所示:
var buffer = Buffer.from([97,98,99,100,101,102]); console.log(buffer); console.log(buffer.toString());
示例结果如下:
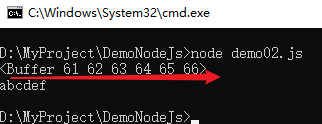
通过以上示例看出,数组的格式是十进制整数,存储到缓存区时,转换成了十六进行表示。
4. 通过字符串创建缓存区
Buffer.from方法,不仅可以通过数组创建,还可以传入字符串内容,如下所示:
var buffer = Buffer.from("我是小六子呀!");
console.log(buffer);
console.log(buffer.toString());
示例结果如下所示:
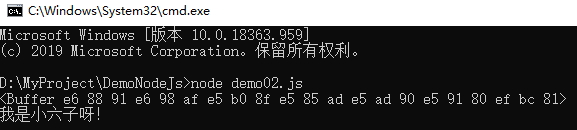
5. 读写缓存区
在Node.js中,通过toString方法读取缓存区的内容,通过write方法写入缓存区。如下所示:
var buffer = Buffer.alloc(10);
buffer.write('张三');
console.log(buffer.toString());
示例如下:
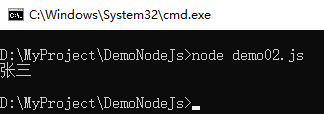
6. 复制缓存区
通过copy方法,可以将缓存区内容从一个缓存区拷贝到新的缓存区。如下所示:
var buffer = Buffer.from("我是小六子呀!");
var buffer2 = Buffer.alloc(21);
console.log("复制前",buffer2);
buffer.copy(buffer2);
console.log("复制后:",buffer2);
示例结果如下所示:

文件操作
Node.js作为服务端程序,新增了读取文件操作。文件I/O操作是对标准POSIX函数的简单封装,通过require('fs')使用该模块,所有方法都有同步和异步的方式。读写文件主要有两种方式:a.直接读取,b.流式读取
1. 异步直接读取
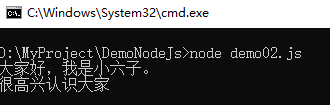
将硬盘上的所有内容全部读入内存以后才触发回调函数。如下所示:
var fs =require('fs');
fs.readFile('./test.txt',function(err,data){
if(err){
console.log(err);
}else{
console.log(data.toString());//默认data为Buffer类型
}
});
示例如下所示:
2. 同步直接读取
同步方式直接返回数据内容,不再使用回调函数,如下所示:
var fs =require('fs');
var data = fs.readFileSync('./test.txt');
console.log(data.toString());
3. 流式读取
当需要读取的文件比较大时,无法一次读取完成,则需要采用流式读取的方式,将数据从硬盘中一节一节的读取。循环读取一节就触发回调函数,以实现大文件操作。
假如现在有一个文件,采用流式读取,如下所示:
var fs =require('fs');
//创建流
var stream=fs.createReadStream('./test.txt');
//监控流获取数据事件
stream.on('data',function(data){
console.log('--------------------------');
console.log(data.length);
console.log(data);
});
读取示例如下所示:

通过以上示例可以看出,每一次字节流读取的数据大小为65536字节,即64KB。如果文件大小大于64KB,则会分为多节进行读取。
4. 写入文件
写入文件与读取文件相对,如下所示:
var fs =require('fs');
var test="这周都没有上班了,在居家办公,好不方便呀!!!";
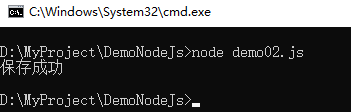
fs.writeFile('./test1.txt',test,function(err){
if(err){
console.log(err);
}else{
console.log('保存成功');
}
});
示例如下:
文件默认为utf-8编码,如下所示:

同步写入就是在异步写入的方法后加入Sync即可。
5. 流式写入文件
字节流的方式写入文件,如下所示:
var fs =require('fs');
var stream = fs.createWriteStream('./input.txt');
stream.write("小六子潇洒呀");
stream.write("小六公子潇洒呀");
stream.write("小六痞子潇洒呀");
stream.end();
写入成功后,文件如下:

注意,流式写入文件,一定要有end方法结束字节流。字节流还有其他事件,如:end,finish,error,都可以通过on进行监听。
6. 读取文件信息
Node.js不仅可以读取写入文件内容,还可以读取文件信息,如文件大小,创建时间等内容,如下所示:
var fs =require('fs');
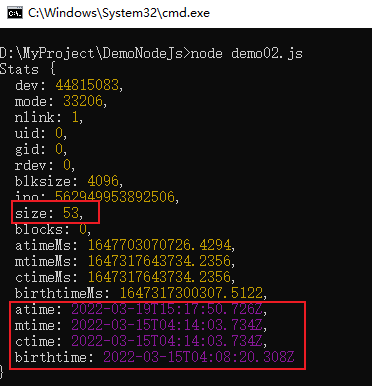
fs.stat('./test.txt',function(err,stat){
if(err){
console.log(err);
}else{
console.log(stat);
}
});
读取文件信息返回的是一个对象,包含文件的各个属性,示例结果如下所示:
注意:返回的Stat对象,同时包含isFile和isDirectory方法,用于判断路径是否文件和文件夹。
7. 删除文件
删除文件可以采用unlink方法,如下所示:
var fs =require('fs');
fs.unlink('./test.txt',function(err){
if(err){
console.log(err);
}else{
console.log('删除成功');
}
});
如果要删除的文件不存在,则会返回错误信息,如果存在,则提示删除成功。示例结果如下所示:

8. 管道
管道(pipe)提供了一个输出流到输入流的机制。
通常我们复制大文件,采用从一个流中获取数据,并将数据传递到另外一个流中。如下所示:
var fs =require('fs');
var s1=fs.createReadStream('./test.txt');
var s2 = fs.createWriteStream('./input.txt');
//以流的方式实现大文件复制,读取一节,传递一节
s1.on('data',function(data){
s2.write(data);
});
s1.on('end',function(){
s2.end();
console.log('文件复制完成');
});
以上方式稍微有点复杂,采用管道方式,可以简化操作,如下所示:
var fs =require('fs');
var s1=fs.createReadStream('./test.txt');
var s2 = fs.createWriteStream('./input.txt');
s1.pipe(s2);//管道方式
9. 链式流
将数据流通过管道链接起来,实现链式管理。如压缩等方式。
var fs =require('fs');
var zlib =require('zlib');
var s1=fs.createReadStream('./test.txt');
var s2 = fs.createWriteStream('./test.zip');
s1.pipe(zlib.createGzip()).pipe(s2);
到此这篇关于Node.js基础入门之缓存区与文件操作详解的文章就介绍到这了,更多相关Node.js缓存区 文件操作内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!