B站python子木教程笔记
下述全都来源B站木子python花了2万多买的Python教程全套,现在分享给大家,入门到精通(Python全栈开发教程)_哔哩哔哩_bilibili
1、print函数
基本格式
print(520) #直接输出数字
print('helloworld') #输出引号里的内容 可以是双引号
print(helloworld) #报错!因为不能直接输出字母
print(3+1) #输出表达式(含有操作符和运算数)
print('hello','world') #一行输出多内容的时候用逗号隔开逗号后面最好加空格
python语句中的 end=' ' 的作用
为末尾end传递一个空字符串,这样print函数不会在字符串末尾添加一个换行符,而是添加一个空字符串,其实这也是一个语法要求,表示这个语句没结束。
print默认是打印一行,结尾加换行。end=' '意思是末尾不换行,加空格
2、快捷输出ctrl+shift+F10
3、open函数结合print进行打开文件
fp=open('D:/text_pycharm_open','a+')
print('helloworld',file=fp)
fp.close()
4、转义字符、原字符
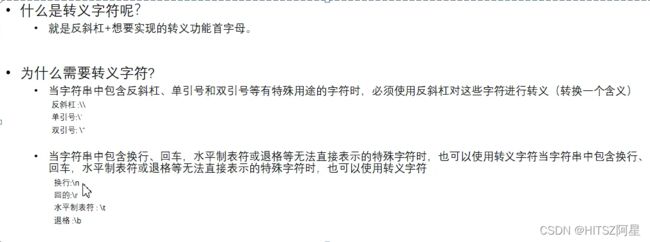
原字符: 
注意:任何一句话最后一个字符不能是一个反斜杠\
可以是俩个反斜杠\\
5、换行输出
点击这个Soft Wrap
6、整数类型不同进制的表示
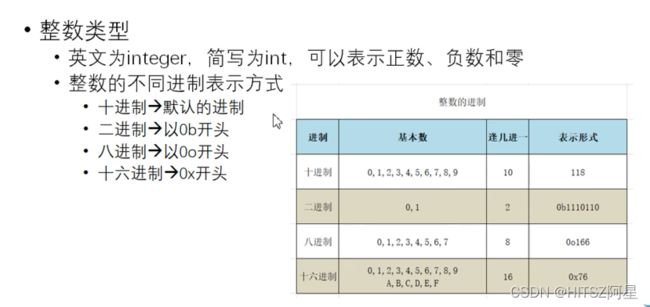
print('二进制',0b010101111) #输出175 注意是0b不是ob7、浮点类型和decimal

注意大写的D!
8、字符串类型和多行字符串

三引号:'''(三个单引号)和“””(三个双引号)可以用来把字符串多行输出
9、类型转换

注意 整形int和bool类型的转换成浮点型float的时候会加个“.0"
浮点转化成整形是“抹零取值”
10、注释

11、算术运算符

//代表整除
%代表取余数
幂是俩个乘法运算符**
其中取余数%和整除//有一些特殊情况

整除一正一负向下取整数 取更小的
但是取余操作的公式为被除数-除数*商 这里的商向下取整
记住取余的结果介于除数和0之间、
赋值运算中支持


交换变量不需要中间变量(C++震怒!)

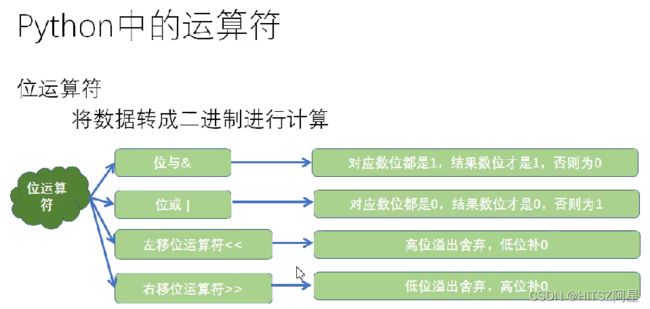
12、位运算符

13、对象的布尔值
 14、if else判断语句和条件表达式(简写if else语句块)
14、if else判断语句和条件表达式(简写if else语句块)
以下转自python if语句用法解析_vicdd的博客-CSDN博客_python的if语句用法
-
if的基本语法格式看下面:第一行是条件语句(注意:变量也可以当做判断语句 因为可以看作bool变量),如果满足条件就会执行第二行,没有括号或者结束语句,比如endif,没有。 if和后面的判断语句中间要加空格

-
假如第二行没有缩进,就会产生错误。
-

-
新手容易犯一个错误就是条件语句后面不写冒号,出现这样的错误:

-
我们假如有多个条件,我们可以使用else,当条件不满足的时候执行它下面的语句块。当然else是顶个写,并且后面记得写冒号。

-
如果还有更多的条件,我们可以使用elif,同样不要忘记冒号和缩进和空格
-

python里的else if缩写为elif
比如
score=int(input('请输入一个成绩:'))
if score>=90 & score<=100:
print(score,'是A等级')
elif score>=80 and score<90:
print(score,'是B等级')
elif score>=60 and score<80:
print(score,'是C等级')
elif score>=0 and score<60:
print(score,'是F等级')
else:
print('输入有错')注意 python里用and
python里的and和&的关系和区别
Python中&和and的区别_l2014204559的博客-CSDN博客_&和and python
条件表达式

15、python里的缩进
和其它程序设计语言(如 Java、C 语言)采用大括号“{}”分隔代码块不同,Python 采用代码缩进和冒号( : )来区分代码块之间的层次。
在 Python 中,对于类定义、函数定义、流程控制语句、异常处理语句等,行尾的冒号和下一行的缩进,表示下一个代码块的开始,而缩进的结束则表示此代码块的结束。
注意,Python 中实现对代码的缩进,可以使用空格或者 Tab 键实现。但无论是手动敲空格,还是使用 Tab 键,通常情况下都是采用 4 个空格长度作为一个缩进量(默认情况下,一个 Tab 键就表示 4 个空格)。
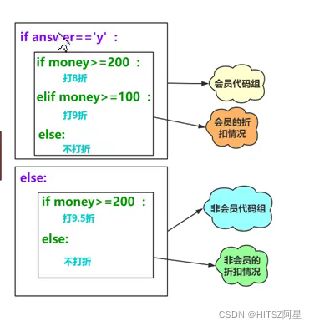
16、嵌套if

17、pass语句
有时候我们需要先不写内容,先写框架,我们可以用pass语句来跳过内容填写,防止报错。
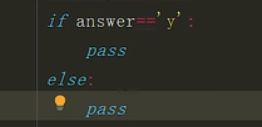
不写pass会报错
18、range语句

左开右闭的区间
range只能遍历整数,拒绝小数!
19、while循环结构

注意判断N+1次 因为最后一次也判断了(判断为false 终止)
20、for-in循环结构(结合range函数)
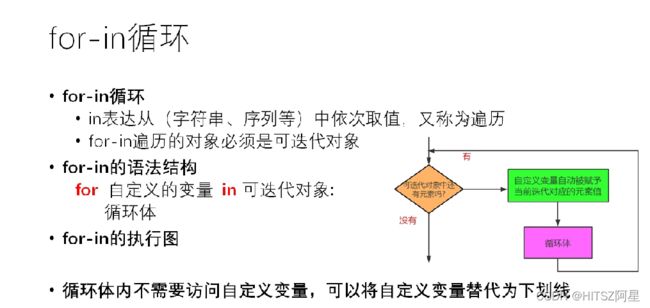

for 循环可以不用变量,用下划线_代替变量来用作循环次数
for是自带遍历的,所以不需要+=1这种操作
21、break和continue语句
break是跳出当前循环结构
continue是结束当前循环,进入下一次循环。
break和continue都只用于本层循环的操作
22、else语句

else主要和for、while、语句进行搭配使用
①else和if搭配:比较好理解 if不成立 那就else的情况
②else和for、while搭配的时候,如果for下面一路没有碰到break 那就会按照顺序结构执行else
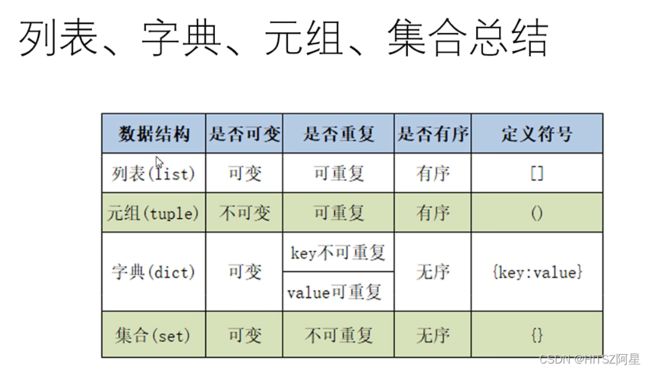
23、列表(list)
列表类似C语言里的数组
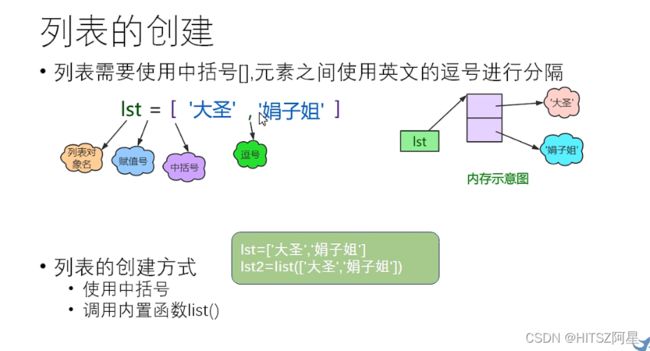
list1=['hello', 'world', 'False', '86.2'] #第一种方式用方括号直接
list2=list(['hello', 'world', 'False', '86.2']) #使用内置函数list

python的索引有从第一个元素从0增加到N,也有从最后一个元素从-1减少到-M。
所以如果是-1,那就是最后一个,-2是倒数第二个
列表是可变数据类型
23.1列表的查询和切片操作
列表的查询用index函数操作,具体可百度
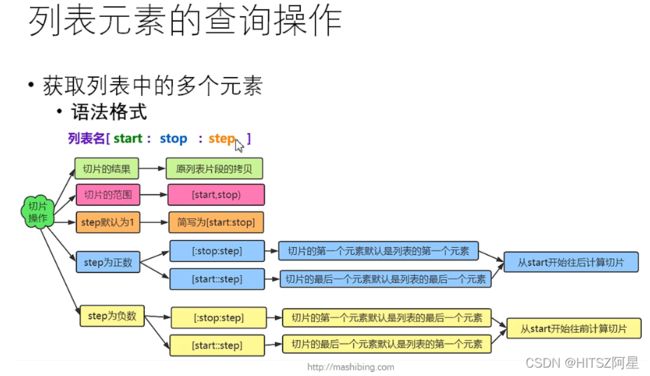
23.2列表元素的添加、删除、修改、排序操作

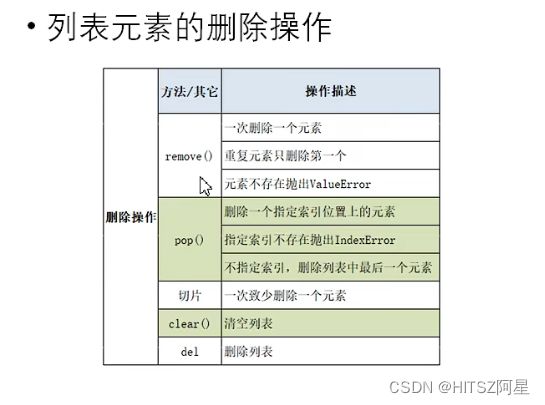
切片是一个很神奇的操作!

sort改变原列表
sorted不改变原列表
23.3列表生成的方法(公式)
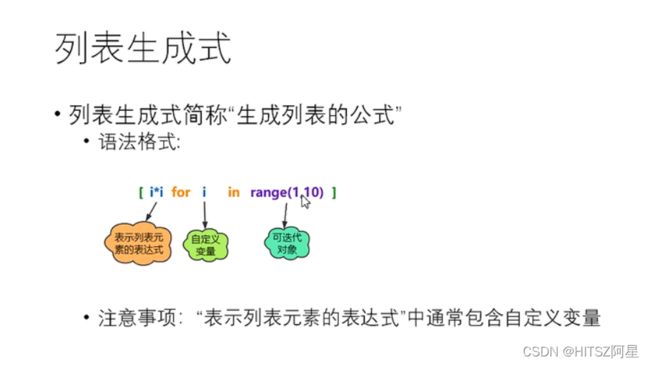
lst=[i for i in range(1,10)] #第一个i表示生成i 后面的for代表循环语句 用中括号括起
print(lst) #结果为[1, 2, 3, 4, 5, 6, 7, 8, 9]
lst=[i*i for i in range(1,10)] #第一个i*i表示生成i*i这个结果 后面的for代表循环语句 用中括号括起
print(lst) #结果为[1, 4, 9, 16, 25, 36, 49, 64, 81]

24、字典(dict)
字典类似C语言里的map容器
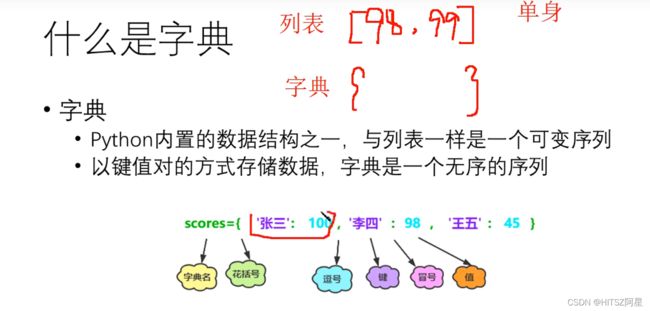

注意!:字典目前变成有序了,在python3.6之后
key必须是不可变对象,不可以是列表(列表是可变对象)
但是字典本身是可变数据类型
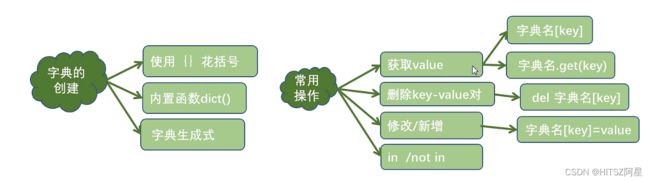
24.1 字典的创建

24.2 字典元素的获取
输出的是“值“”,根据“键”查找取值
24.3 字典元素的增、删、改

24.4 获取字典视图
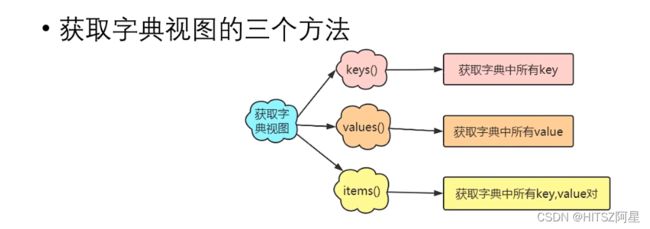
24.5 字典元素的遍历

24.6 字典的生成方法

操作总结
25、元组(tuple)

列表是中括号
元组是小括号(带上逗号)
字典是花括号
25.1 元组的创建生成

元组的关键其实是逗号 可以不要小括号 但是必须要有逗号(空元组不需要逗号)
25.2 为什么元组是不可变序列

比如一个元组的一个元素是一个列表,那么这个列表元素指向的是列表的地址,地址不可变,存在该地址里面的内容(列表的内容)是可变的
26、可变数据类型和不可变数据类型

python中不可变数据类型和可变数据类型 - 自由早晚乱余生 - 博客园
27、集合(set)

字典里键不能重复,集合里的值不能重复
27.1 集合的创建方式

集合直接创建用花括号,跟列表不同,列表用中括号直接创建。
- 集合元素不可重复,列表元素可以重复
- 列表是有序的,集合是无序
集合里的元素不可以是列表,因为集合是无序的,里面的元素必须是不可变类型(集合本身是可变类型)
27.2 集合的相关操作

因为集合是无序的所以添加不能指定位置!
27.3 集合之间的关系

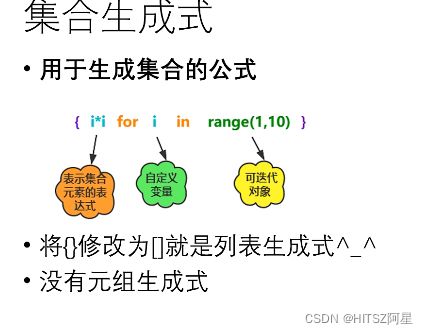
27.4 集合生成式
28、列表、字典、元组、集合区别和联系总结

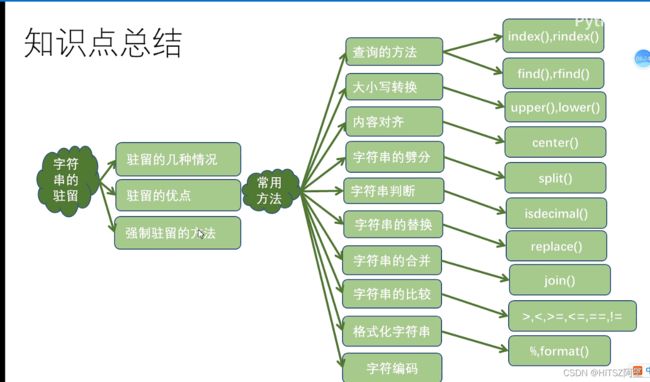
29、字符串和字符串的驻留机制
字符串也是不可变 跟元组一样。

驻留:重复的字符串不会创建新空间,只会拷贝原本的

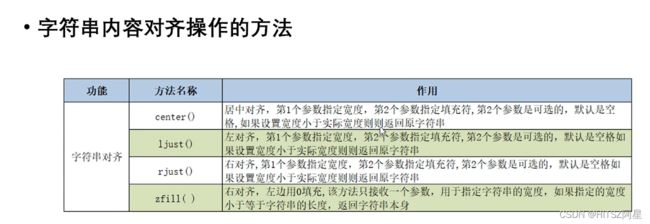
29.1 字符串的查询、大小写转换、对齐、替换、合并


哪怕原本全是小写 用lower转换后 地址也会改变。

29.2 字符串的劈分
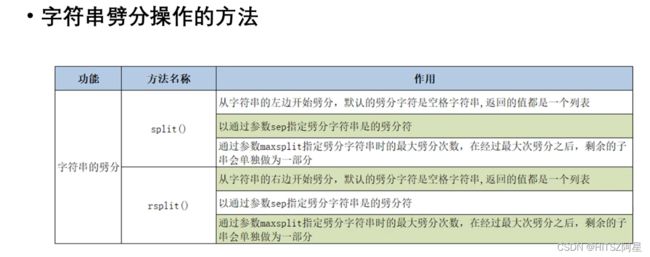
劈分就是把东西分开
29.3 判断字符串操作和字符串的比较
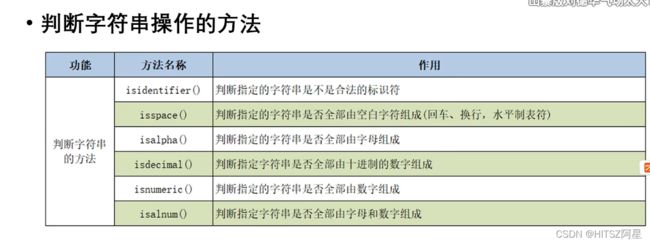

==和is的区别:

29.4 字符串的切片

29.5 字符串的格式化(重要☆)
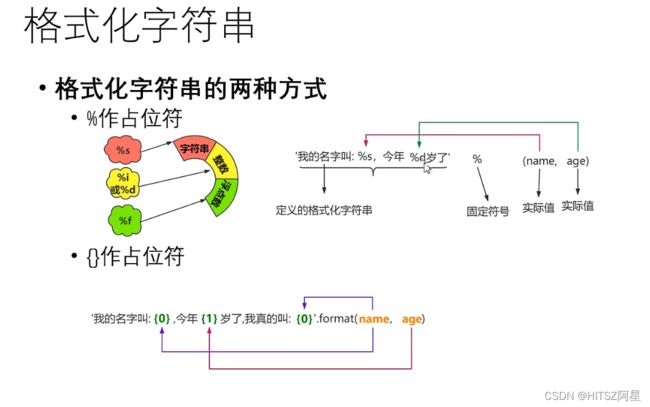
三种方法格式化
name = '张三'
age = 20
print('我叫%s,今年%d岁' % (name, age)) #根据%类型 后面加%
print('我叫{0},今年{1}岁'.format(name, age)) #以{n}来,后面加.
print(f'我叫{name},今年{age}岁') #以{变量名} 前面加f29.6 字符串知识点总结
30、函数的创建与调用


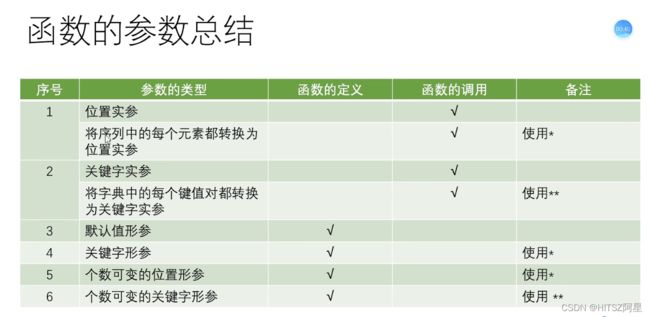
参数传递法:位置实参和关键字实参
 30.1 函数的参数传递、个数可变的位置参数
30.1 函数的参数传递、个数可变的位置参数
在python的函数参数传递中,如果是不可变类型比如一个整形数据,那么传递类似C++的值传递,不会改变实参;如果是可变类型比如一个列表,那么传递类型类似C++的引用传递,会把实参也改变自动返回。

如果一个函数定义的时候,既有个数可变的位置形参,也有个数可变的关键词形参时:

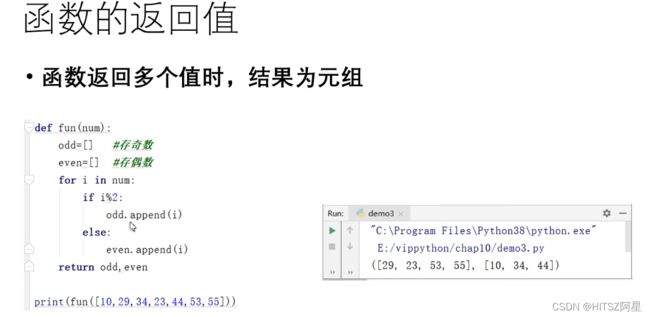
30.2 函数的返回值
30.3 函数调用和定义加不加*的总结
31、变量的作用域

32、递归函数

33、Python的异常处理机制(跳过bug的方法)
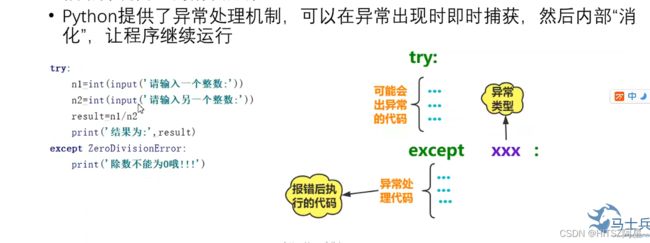


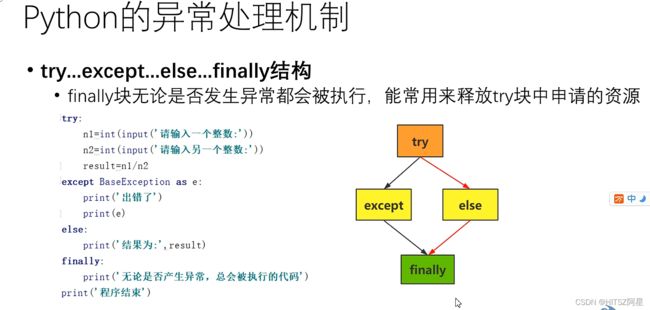
34、类的定义和创建
class Xxxx: 注意这里的X首字母要大写,这是一种规范
在类外定义的称为函数,在类内定义的称为方法
self相当于c++里的this

一般来说,使用某个类的方法,需要先将类实例化,赋予一个对象才可以调用类中的方法,但是如果使用了@staticmethod 或@classmethod,就可以不用实例化,直接类名.方法名()来调用。
如果用了staticmethod就无视这个self了,就将这个方法当成一个普通的函数使用了。
cls和self的用处一样,都是表示类本身。只不过一个是用在类方法里,一个是用在实例方法里。
我还发现一个问题就是,我们一般的的类(_ _init_ _)都是self必写。而_ _new_ _写的是cls,他们有什么不同。
查了一波资料,cla主要用于类定义方法,而self则是实例方法。
个人理解,当运行到这个方法的时候,类如果还没实例化,就是cls,否则是self。
静态方法是没有参数的 但是类方法有参数

34.1 类和对象知识点汇总
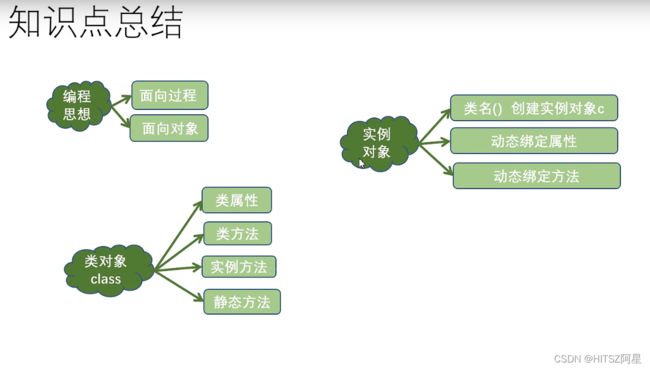
35、封装

加_ _有点类似私有属性private 但是也可以在类外通过_类名_ _来访问


36、继承

super()是调用父类的函数
调用父类的构造函数用super()._ _init_ _
37、重写方法、

38、object类

39、多态

虽然python里没有数据类型。但是也具备多态的特征。
40、特殊属性和特殊方法
两个下划线开头和结尾的称为特殊属性和方法,比如_ _init_ _

41、__new__和__init__
class Person(object):
def __new__(cls, *args, **kwargs):
print('__new__被调用执行,cls的值为{0}'.format(id(cls)))
obj=super().__new__(cls)
print('obj的super().__new__被执行,创建的对象的id为{0}'.format(id(obj)))
return obj
def __init__(self,name,age):
print('__init__被调用了,self的id值为{0}'.format(id(self)))
self.name=name
self.age=age
print('object这个类对象的id为{0}'.format(id(object)))
print('person这个类对象的id为{0}'.format(id(Person)))
#创建Person类的实例对象
p1=Person('张三',20)
print('p1这个实例对象的id为{0}'.format(id(p1)))结果为:
object这个类对象的id为140714352037376
person这个类对象的id为1939635729648
__new__被调用执行,cls的值为1939635729648
obj的super().__new__被执行,创建的对象的id为1939641818896
__init__被调用了,self的id值为1939641818896
p1这个实例对象的id为1939641818896
我们可以看到new产生的obj和p1和__init__的地址都一样。总结:
每创建一个新的类对象,都默认调用一次new,每创建一个新实例对象都会默认调用一次init
new是祖宗,init身体内的基因都是他的。先执行__new__再执行__init__,最后把对象赋给p1
super().__new__是Person这个子类里调用了父类Object的__new__函数
42、类的赋值与深、浅拷贝

浅拷贝的时候,拷贝对象包含的子对象还是老样子,不会把子对象也克隆新的一份,只创造拷贝对象的新克隆产生物
深拷贝的时候,拷贝对象里包含的子对象也会创造一份新的子对象。
43、模块(Modules)
变量<方法<类/函数<模块<包


导入自定义模块方法:
44、以主程序方法运行 (if __name__ =='__main__')
为了让导入的模块在导入时有些部分不执行,那些部分只在那个模块单独跑的时候才运行。我们可以设置如下所示(calc2是这个模块的名字,运行模块的时候执行这个print,导入到别的地方不运行)

45、import和from导入
在使用import导入的时候,只能导入包名和模块名。
在使用from…import导入的时候,可以导入包、模块、函数、变量名。
46、包(package)
包是new package产生的东西,可以理解成一个文件夹,里面放着一堆.py文件
包的特征就是自带一个.py文件叫__init__.py
47、编码

48、文件打开模式

49、文件对象的常用操作

关于flush和write:向文件中写入数据的时候,python并不会立刻写入,而是会写到缓冲区,等待清空的时候写入文件。用flush可以不用等close
50、with语句
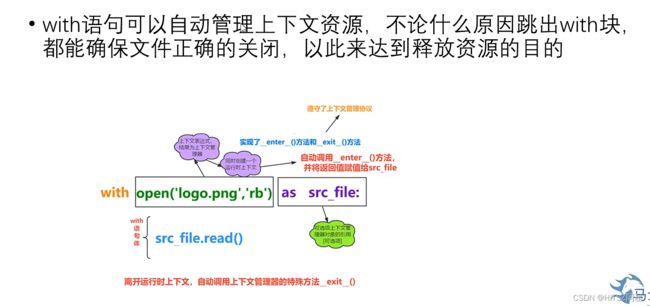
简单而言,对文件操作,with语句可以实现自动调用enter和exit语句。防止你忘记写。
即
with X as Y:
X.函数()
那么当这两句话执行的时候,会自动调用__enter__()和__exit__()
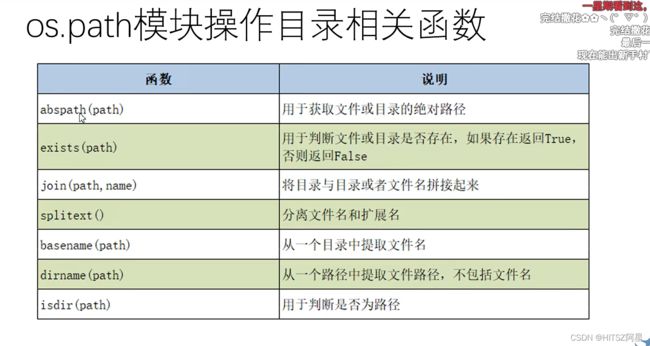
51、os语句相关目录操作
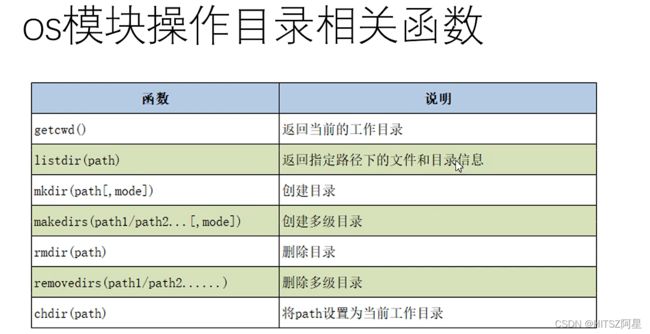
用法:比如以下语句可以实现查找当前路径
import os
print(os.getcwd())
os.path模块也有相关操作