C语言——知识点汇总
1.基本数据类型
C语言的基本数据类型包括**字符型、整数型、浮点型**。
2.常量
常量或常数,表示固定不变的数据,是具体的数据。
1)字符常量,如'6','a','F',不能是中文,例如'女',因为一个汉字和全角的符号占两个字节(GBK编码)。
2)整型常量,如6,27,-299。
3)浮点型常量,如5.43,-2.3,5.67,6.0。
4)字符串常量,如"625","女","www.freecplus.net","西施"。
3.变量
字符串变量
在C语言中,**没有“字符串”这个数据类型**,而是用字符数组来存放字符串,并提供了丰富的库函数来操作字符串。
char name[21]; // 定义一个可以存放20字符的字符串。
注意几个细节:
1)如果要定义一个存放20个英文的字符串,数组的长度应该是20+1,原因以后再讨论。
2)中文的汉字和标点符号需要两个字符宽度来存放(GBK编码)。
例如name[21]可以存放20个英文字符,或10个中文字符。
3)字符串不是C语言的基本数据类型,不能用“=”赋值,不能用“>”和“<”比较大小,不能用“+”拼接,不能用==和!=判断两个字符串是否相同,要用函数,具体方法我以后再介绍,现在了解就可以。
- 变量的命名
变量名属于标识符,需要符合标识符的命名规范,具体如下:
1)变量名的第一个字符必须是字母或下划线,不能是数字和其它字符。
2) 变量名中的字母是区分大小写的。比如a和A是不同的变量名,num和Num也是不同的变量名。
3)变量名绝对不可以是C语言的关键字。
4)关于变量的命名,为了便于理解,尽可能用英文单词或多个英文单词的简写,太短不能表达含义,太长了书写麻烦,如果英语不好,那就用中文拼英的第一个字母,例如身份证号码,cardid、userid都可以,sfzhm也行,不要怕被笑话,英语不好的程序员很多。
- 变量的初始化
变量在定义后,操作系统为它分配了一块内存,但并不会把这块内存打扫干静,也就是说内存中可能有垃圾数据,建议在使用之间对其初始化(打扫干静)。
变量初始化是一个良好的编程习惯,否则有时候程序可能会产生意想不到的结果。
1、整数型、字符型、浮点型变量初始化
对整数型、字符型、浮点型变量来说,初始化就是给它们赋0值。
可以在定义的时候立即初始化。
int ii=0; // 定义整数型变量并初始化
char cc=0; // 定义字符型变量并初始化
double money=0; // 定义浮点型变量并初始化
也可以先定义,然后再初始化。
int ii; // 定义整数型变量
char cc; // 定义字符型变量
double money; // 定义浮点型变量
ii=0; // 初始化ii为0
cc=0; // 初始化cc为0
money=0; // 初始化money为0
2、字符串变量的初始化
对字符串变量来说,初始化就是把内容清空,本质上也是赋0值。
char name[21]; // 定义一个可以存放20字符的字符串
memset(name,0,sizeof(name)); // 清空字符串name中的内容
- 变量的赋值
strcpy(name1,name); // 把name的值赋给name1
注意了,字符串变量的赋值与其它类型不同,不能用=号,要用strcpy函数
- const约束
const double pi = 3.1415926;
用const定义的变量的值是不允许改变的,不允许给它重新赋值,即使是赋相同的值也不可以。所以说它定义的是只读变量。这也就意味着必须在定义的时候就给它赋初值,如果程序中试图改变它的值,编译的时候就会报错。
4.数据输入
在C语言中,有三个函数可以从键盘获得用户输入。
getchar:输入单个字符,保存到字符变量中。
gets:输入一行数据,保存到字符串变量中。
scanf:格式化输入函数,一次可以输入多个数据,保存到多个变量中。
- 详解scanf,其他忽略:
scanf函数是格式化输入函数,用于接受从键盘输入的数据,用户输入数据完成后,按回车键(Enter)结束输入。
输入整数的格式用%d表示
输入字符串的格式用%s表示
输入字符的格式用%c表示
输入浮点数的格式用%lf表示
输入字符串:
char name[21];
memset(name,0,sizeof(name));
printf("请输入您姓名:");
scanf("%s",name); // 注意了,字符串变量名前可以不加符号&,不要问原因,以后再介绍。
5.数据输出
在C语言中,有三个函数可以把数据输出到屏幕。
putchar:输出单个字符。
puts:输出字符串。
printf:格式化输出函数,可输出常量、变量等。
- 详解printf输出,其他忽略:
printf函数是格式化输出函数, 用于向屏幕输出数据。
调用一次printf函数可以输出多个常量或变量。
int age=18;
char xb='x';
double weight=62.5;
char name[21];
memset(name,0,sizeof(name));
strcpy(name, "西施");
printf("我的姓名是:%s,姓别:%c,年龄:%d岁,体重%lf公斤。\n",name,xb,age,weight);
注意,printf函数第一个参数(格式化字符串)的格式与后面的参数列表(常量或变量的列表)要一一对应,一个萝卜一个坑的填进去,不能多,不能少,顺序也不能错,否则会产生意外的结果。
6.if语句
如果if后只有一行语句,可以省略大括号。多行不能省略。
C语言用“&&”表示“并且”,用“||”表示“或者”,官方用语就是逻辑运算符。
7.循环
- for
for (语句1;表达式;语句2)
{
语句块
}
在for循环中,语句1、表达式和语句2都可以为空(此时为死循环),for (;;)等同于while (1)。
8.数组
数组(array)是一组数据类型相同的变量,可以存放一组数据,它定义的语法是:
数据类型 数组名[数组长度];
例如:
double money[20];
定义数组的时候,数组的长度必须是整数,可以是常量,也可以是变量。
数据的下标也必须是整数,可以是常量,也可以是变量。
使用数组元素和使用同类型的变量一样。
scanf("%lf", &money[4]); // 把一个值读入数组的第5个元素
数组是有多个变量组成,占用内存总空间的大小为多个变量占用的内存空间之和,用sizeof(数组名)就可以得到整个数组占用内存的大小,如下:
int ii[10]; // 定义一个整型数组变量
printf("sizeof(ii)=%d\n",sizeof(ii)); // 输出结果:sizeof(ii)=40
- 数组的初始化
采用memset函数对数组进行初始化,如下:
int no[10];
memset(no,0,sizeof(no));
数组下标越界相当于访问了其它程序的内存,可能会导致程序异常中断(Core dump)。由操作系统的内核中断。
段错误,就是程序非法操作内存,引起程序的崩溃。
- 二维数组定义的语法是:
数据类型 数组名[第一维的长度][第二维的长度];
二维数组的初始化也是用memset,例如:
memset(girl,0,sizeof(girl));
9.字符串
字符串就是一个以空字符’\0’结束的字符数组,是一个特殊的字符数组,这是约定,是规则。
空字符’\0’也可以直接写成0。
//字符数组中写的\0等于对某个字符赋值0;
char str1[11]="123\0 567";
char str[4]=0;

因为字符串需要用0结束,所以在定义字符串的时候,要预留多一个字节来存放0。
- 如果字符串不用0结束,会有什么样的结果,我们用代码来演示一下
#include 上面代码输出abc之后,有乱码,并且每次执行程序输出的结果不可预知。
输出时会在name后的内存中一直找到‘\0’才会结束输出,这也是后面,乱码的来源。
如果‘\0’在字符串中间,后面的内容将被丢弃。
- 字符串长度问题
1.对于strlen来说,计量标准为字符串数组中的非终结符字符个数;
2.对于sizeof来说,计量标准为字符串中的所有位数,包含非终结符号;
对于相同的字符串char[]="12345";
strlen的结果为5;
sizeof的结果为6;
所以得出一个结论:定义n字节的char字符串,只能存放n-1个字符,最后一位一定是\0
sizeof字符数组的大小和字符数组的实际大小一定是一样的。
char str[3]="12\0";
printf("str=%s",str);
printf("str len=%d",strlen(str));
printf("str3 sizeof=%ld\n",sizeof(str3));
//输出结果:12.
- 越界问题
数组越界:
二维数组的两个变量之间的内存是连续的,第一个元素之后没有多余的空间,如果给两个变量strcpy大于数组长度的数据,那么输出肯定会有问题。
普通变量越界:
如果给普通字符串变量strcpy数据不一定会报错,因为该变量后面的地址可能是空的,如果不是空的也可能会报错,看运气。
- 字符串比较大小
两个字符串比较的方法是比较字符的ASCII码的大小,从两个字符串的第一个字符开始,如果分不出大小,就比较第二个字符,如果全部的字符都分不出大小,就返回0,表示两个字符串相等。
10.变量的作用域
1)在所有函数外部定义的是全局变量。
2)在头文件中定义的是全局变量。
3)在函数或语句块内部定义的是局部变量。
4)函数的参数是该函数的局部变量。
全局变量在主程序退出时由系统收回内存空间。
局部变量和全局变量的名称可以相同,在某函数或语句块内部,如果局部变量名与全局变量名相同,就会屏蔽全局变量而使用局部变量。
11.指针
指针也是一种内存变量,是内存变量就要占用内存空间,
在C语言中,任何类型的指针占用8字节的内存(32位操作系统4字节)
int x=11;
//p的值就跟x的值是一样的,代表的是变量的值。
//例如:x的值就是11;p的值就是&x的值,
//&p的值是指针变量p的内存地址。
int * p=&x;
- 空指针
就是说指针没有指向任何内存变量,指针的值是空,所以不能操作内存,否则可能会引起程序的崩溃。
12.数组的地址
数组占用的内存空间是连续的,数组名是数组元素的首地址,也是数组的地址。
13.整数
下面是64位linux和32位占字节数:

注意:
1)计算机用最高位1位来表达符号(0-正数,1-负数),unsigned修饰过的正整数不需要符号位,在表达正整数的时候比signed修饰的正整数取值大一倍。
- 二进制
二进制由 0 和 1 两个数字组成,书写时**必须以0b或0B(不区分大小写)**开头,例如:
// 以下是合法的二进制
int a = 0b101; // 换算成十进制为 5
int b = -0b110010; // 换算成十进制为 -50
int c = 0B100001; // 换算成十进制为 33
// 以下是非法的二进制
int m = 101010; // 无前缀 0B,相当于十进制
int n = 0B410; // 4不是有效的二进制数字
- 八进制
八进制由 0~7 八个数字组成,书写时必须以0开头(注意是数字 0,不是字母 o),例如:
// 以下是合法的八进制数
int a = 015; // 换算成十进制为 13
int b = -0101; // 换算成十进制为 -65
int c = 0177777; // 换算成十进制为 65535
// 以下是非法的八进制
int m = 256; // 无前缀 0,相当于十进制
int n = 03A2; // A不是有效的八进制数字
- 十六进制
十六进制由数字 0~9、字母 A~F 或 a~f(不区分大小写)组成,书写时必须以0x或0X(不区分大小写)开头,例如:
// 以下是合法的十六进制
int a = 0X2A; // 换算成十进制为 42
int b = -0XA0; // 换算成十进制为 -160
int c = 0xffff; // 换算成十进制为 65535
// 以下是非法的十六进制
int m = 5A; // 没有前缀 0X,是一个无效数字
int n = 0X3H; // H不是有效的十六进制数字
注意:在C语言中,不要在十进制数前加0,会被计算机误认为是八进制数。
- 整数的输出
| 输出格式 | 含义 |
|---|---|
| %hd、%d、%ld | 以十进制、有符号的形式输出short、int、long 类型的整数。 |
| %hu、%u、%lu | 以十进制、无符号的形式输出short、int、long 类型的整数。 |
| %ho、%o、%lo | 以八进制、不带前缀、无符号的形式输出 short、int、long 类型的整数 |
| %#ho、%#o、%#lo | 以八进制、带前缀、无符号的形式输出 short、int、long 类型的整数 |
| %hx、%x、%lx %hX、%X、%lX | 以十六进制、不带前缀、无符号的形式输出 short、int、long 类型的整数。如果 x 小写,那么输出的十六进制数字也小写;如果 X 大写,那么输出的十六进制数字也大写。 |
| %#hx、%#x、%#lx %#hX、%#X、%#lX | 以十六进制、带前缀、无符号的形式输出 short、int、long 类型的整数。如果 x 小写,那么输出的十六进制数字和前缀都小写;如果 X 大写,那么输出的十六进制数字和前缀都大写。 |
- 常用的库函数
使用库函数一定要加头文件stdlib.h,否则会报错。
//C语言提供了几个常用的库函数,声明如下:
int atoi(const char *nptr); // 把字符串nptr转换为int整数
long atol(const char *nptr); // 把字符串nptr转换为long整数
int abs(const int j); // 求int整数的绝对值
long labs(const long int j); // 求long整数的绝对值
14、随机数
1、生成随机数
在C语言中,我们使用 srand和rand 函数来生成随机数。
void srand(unsigned int seed); // 随机数生成器的初始化函数
int rand(); // 获一个取随机数
srand函数初始化随机数发生器(俗称种子),在实际开发中,我们可以用时间作为参数,只要每次播种的时间不同,那么生成的种子就不同,最终的随机数也就不同,通常我们采用
示例:
#include 2、生成一定范围随机数
对于产生一定范围的随机数,就需要使用一定的技巧,常用的方法是取模运算(取余数),再加上一个加法运算:
//任何数取余的余数一定是小于被除数(50)的,因为除不下时才会剩下余数。
int a = rand() % 50; // 产生0~49的随机数
如果要规定上下限:
int a = rand() % 51 + 100; // 产生100~150的随机数
15、数据类型的别名
使用 typedef 关键字来给数据类型定义一个别名,示例如下:
typedef unsigned int size_t;
size_t ii; 等同于 unsigned int ii;
16、字符
- ASCII码表
省略。
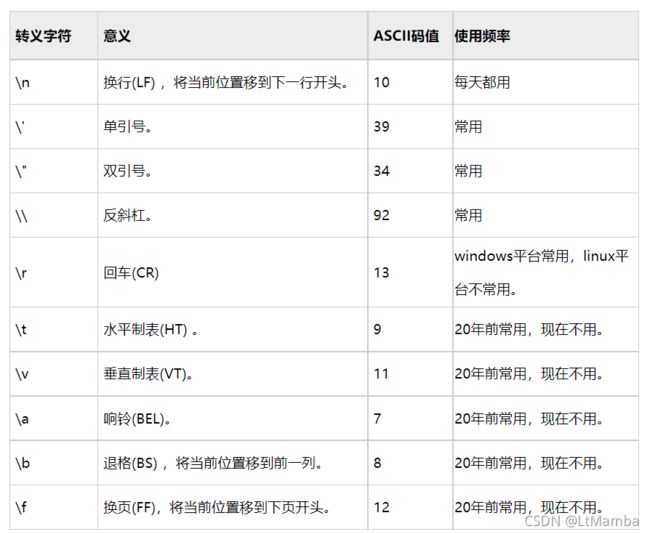
- 转义字符
C语言中,字符需要转义的情况有两种:
1)对于 ASCII 编码,0~31(十进制)范围内的字符为控制字符,它们都是看不见的,不能在显示器上显示,也无法从键盘输入;
2)某些字符在C语言中有特别的用途,如单引号、双引号、反斜杠。
C语言又定义了一种简单的书写方式,即转义字符的形式来表示。
转义字符完整的列表如下:
- 字符就是整数
字符和整数没有本质的区别。可以给 char 变量一个字符,也可以给它一个整数;反过来,可以给 int 变量一个整数,也可以给它一个字符。
char 变量在内存中存储的是字符对应的 ASCII 码值。如果以 %c 输出,会根据 ASCII 码表转换成对应的字符,如果以 %d 输出,那么还是整数。
int 变量在内存中存储的是整数本身,如果以 %c 输出时,也会根据 ASCII 码表转换成对应的字符。
也就是说,ASCII 码表将整数和字符关联起来了。
char类型占内存一个字节,signed char取值范围是-128-127,unsigned char取值范围是0-255。
如果整数大于255,那么整数还是字符吗?
描述再准确一些,在char的取值范围内(0-255),字符和整数没有本质区别。
字符肯定是整数,0-255范围内的整数是字符,大于255的整数不是字符。
- 常用的库函数
以下是常用的字符函数,必须掌握。
int isalpha(int ch); // 若ch是字母('A'-'Z','a'-'z')返回非0值,否则返回0。
int isalnum(int ch); // 若ch是字母('A'-'Z','a'-'z')或数字('0'-'9'),返回非0值,否则返回0。
int isdigit(int ch); // 若ch是数字('0'-'9')返回非0值,否则返回0。
int islower(int ch); // 若ch是小写字母('a'-'z')返回非0值,否则返回0。
int isupper(int ch); // 若ch是大写字母('A'-'Z')返回非0值,否则返回0。
int tolower(int ch); // 若ch是大写字母('A'-'Z')返回相应的小写字母('a'-'z')。
int toupper(int ch); // 若ch是小写字母('a'-'z')返回相应的大写字母('A'-'Z')
以下是不常用的字符函数,极少使用,了解即可。
int isascii(int ch); // 若ch是字符(ASCII码中的0-127)返回非0值,否则返回0。
int iscntrl(int ch); // 若ch是作废字符(0x7F)或普通控制字符(0x00-0x1F),返回非0值,否则返回0。
int isprint(int ch); // 若ch是可打印字符(含空格)(0x20-0x7E)返回非0值,否则返回0。
int ispunct(int ch); // 若ch是标点字符(0x00-0x1F)返回非0值,否则返回0。
int isspace(int ch); // 若ch是空格(' '),水平制表符('/t'),回车符('/r'),走纸换行('/f'),垂直制表符('/v'),换行符('/n'),返回非0值,否则返回0。
int isxdigit(int ch); // 若ch是16进制数('0'-'9','A'-'F','a'-'f')返回非0值,否则返回0。
大写转小写,ASCII码加32就可以了。
输出百分号:printf("%%\n");
17.浮点数
- 占用内存的情况

- 浮点数的精度
float数的两个特征:
1)float数据类型表达的是一个近似的数,不是准确的,小数点后的n位有误差,浮点数的位数越大,误差越大,到8位的时候,误差了1,基本上不能用了。
2)用“==”可以比较两个整数或字符是否相等,但是,看起来相等的两个浮点数,就是不会相等。
double数的两个特征:
1)double数据类型表达的也是一个近似的数,不是准确的,小数点后的n位有误差,浮点数的位数越大,误差越大,到18位的时候,误差了1,基本上不能用了。
2)用“==”可以比较两个double数值是否相等。
总结:
float只能表达6-7位的有效数字,不能用“==”判断两个数字是否相等。
double能表达15-16位有效的数字,可以用“==”判断两个数字是否相等。
long double占用的内存是double的两倍,但表达数据的精度和double相同。
在实际开发中,建议弃用float,只采用double就可以,long double暂时没有必要,但不知道以后的操作系统和编译器对long double是否有改进。
- 浮点数的输出
float采用%f占位符。
double采用%lf占位符。测试结果证明,double不可以用%f输入,但可以用%f输出,但是不建议采用%f,因为不同的编译器可能会有差别。
long double采用%Lf占位符,注意,L是大写。
浮点数输出缺省显示小数点后六位。
浮点数采用%lf输出,完整的输出格式是%m.nlf,指定输出数据整数部分和小数部分共占m位,其中有n位是小数。如果数值长度小于m,则左端补空格,若数值长度大于m,则按实际位数输出。
double ff=70001.538;
printf("ff=%lf=\n",ff); // 输出结果是ff=70001.538000=
printf("ff=%.4lf=\n",ff); // 输出结果是ff=70001.5380=
printf("ff=%11.4lf=\n",ff); // 输出结果是ff= 70001.5380=
printf("ff=%8.4lf=\n",ff); // 输出结果是ff=70001.5380=
- 常用的库函数
只介绍double
double atof(const char *nptr); // 把字符串nptr转换为double
double fabs(double x); // 求双精度实数x的绝对值
double pow(double x, double y); // 求 x 的 y 次幂(次方)
double round(double x); // double将小数第一位四舍五入到整数位
double ceil(double x); // double向上取整数
double floor(double x); // double向下取整数
double fmod(double x,double y); // 求x/y整除后的双精度余数
// 把双精度val分解成整数部分和小数部分,整数部分存放在ip所指的变量中,返回小数部分。
double modf(double val,double *ip);
- 应用经验
浮点数有一些坑,例如两个浮点数不相等和精度的问题,在实际开发中,我们经常用整数代替浮点数,因为整数是精确的,效率也更高。
例如人的身高一米七五,以米为单位,用浮点数表示是1.75米,如果以厘米为单位,用整数表示是175。
long整数的取值是-9223372036854775808~9223372036854775807,有效数字是19位,而double的有效数字才15-16位,所以,整数可以表达的小数更大的数,更实用,麻烦也更少。
货币:1.75元,如果采用0.01元为单位就是175,采用0.001元为单位就是1750,如果您说要更多小数怎么办?您这是钻牛角尖。
码农之道:高水平的程序员不容易掉坑里,注意,是不容易,不是不会,最好的方法是不要靠近坑。
- 科学计数法
科学记数法是一种记数的方法。把一个数表示成a与10n相乘的形式(1≤|a|<10,n为整数),这种记数法叫做科学记数法。
51400000000=5.14×1010,计算机表达10的幂是一般是用E或e,也就是51400000000=5.14E10或5.14e10。
0.00001=1×10-5,即绝对值小于1的数也可以用科学记数法表示为a乘10-n的形式。即1E-5或1e-5。
18.结构体
使用结构体(struct)来存放一组不同类型的数据。
- 内存占用
结构体会自动内存对齐。
C语言提供了结构体成员内存对齐的方法,在定义结构体之前,增加以下代码可以使结构体成员变量之间的内存没有空隙。
#pragma pack(1)
- 结构体的变量名
和数组不一样,结构体变量名不是结构体变量的地址。
struct st_girl stgirl;
printf("%d\n",stgirl); // 没有意义。
printf("%p\n",stgirl); // 没有意义,结构体变量名不是结构体变量的地址。
printf("%p\n",&stgirl); // 这才是结构体的地址。
- 结构体初始化
采用memset函数初始化结构体,全部成员变量的值清零:
memset(&queen,0,sizeof(struct st_girl));
或
m**加粗样式**emset(&queen,0,sizeof(queen));
- 成员的访问
采用圆点.运算符可以访问(使用)结构的成员。
- 结构体数组
结构体可以被定义成数组变量,本质上与其它类型的数组变量没有区别。
C++标准库的vector容器是一个动态的结构体数组,比结构体数组更方便。
- 结构体指针
结构体是一种自定义的数据类型,结构体变量是内存变量,有内存地址,也就有结构体指针。
struct st_girl queen;
struct st_girl *pst=&queen;
通过结构体指针可以使用结构体成员,一般形式为:
(*pointer).memberName
或者:
pointer->memberName
- 结构体的复制
函数声明:
void *memcpy(void *dest, const void *src, size_t n);
参数说明:
src 源内存变量的起始地址。
dest 目的内存变量的起始地址。
n 需要复制内容的字节数。
函数返回指向dest的地址,函数的返回值意义不大,程序员一般不关心这个返回值。
示例:
#include - 清零函数
memset和bzero函数。
bzero函数不是标准库函数,所以可移植性不是很好,建议使用memset函数代替。
bzero函数是内存空间清零。
包含在<string.h>头文件中。
函数的声明如下:
void bzero(void *s, size_t n);
s为内存空间的地址,一般是数组名或结构体的地址。
n为要清零的字节数。
如果要对数组或结构体清零,用memset和bzero都可以,没什么差别,看程序员的习惯。
19.格式化输出
格式化输出的函数有printf、sprintf和snprintf等,功能略有不同,使用方法大同小异。
printf为例:
函数声明:
int printf(const char *format, ...);
格式说明符的形式如下(方括号 [] 中的项为可选项):
%[flags][width][.prec]type
1、类型符(type)
它用以表示输出数据的类型,以下是常用类型的汇总,不常用的就不列了。
%hd、%d、%ld 以十进制、有符号的形式输出 short、int、long 类型的整数。
%hu、%u、%lu 以十进制、无符号的形式输出 short、int、long 类型的整数
%c 输出字符。
%lf 以普通方式输出double(float弃用,long doube无用)。
%e 以科学计数法输出double。
%s 输出字符串。
%p 输出内存的地址。
%02u 输出无符号整型两位,不足两位用0吧补齐
2、宽度(width)
它用于控制输出内容的宽度。
printf("=%12s=\n","abc"); // 输出= abc=
printf("=%12d=\n",123); // 输出= 123=
printf("=%12lf=\n",123.5); // 输出= 123.500000=
3、对齐标志(flags)
flags它用于控制输出内容的对齐方式。
不填或+:输出的内容右对齐,这是缺省的方式,上一小节就是右对齐的示例。
-:输出的内容左对齐。
printf("=%-12s=\n","abc"); // 输出=abc =
printf("=%-12d=\n",123); // 输出=123 =
printf("=%-12f=\n",123.5); // 输出=123.500000 =
如果输出的内容是整数或浮点数,并且对齐的方式是右对齐,可以加0填充,例如:
printf("=%012s=\n","abc"); // 输出= abc=
printf("=%012d=\n",123); // 输出=000000000123=
printf("=%012f=\n",123.5); // 输出=00123.500000=
4、精度(prec)
如果输出的内容是浮点数,它用于控制输出内容的精度,也就是说小数点后面保留多少位,后面的数四舍五入。
printf("=%12.2lf=\n",123.5); // 输出= 123.50=
printf("=%.2lf=\n",123.5); // 输出=123.50=
printf("=%12.2e=\n",123500000000.0); // 输出= 1.24e+11=
printf("=%.2e=\n",123500000000.0); // 输出=1.24e+11=
20.main函数
- main函数的参数
main函数有三个参数,argc、argv和envp,它的标准写法如下:
int main(int argc,char *argv[],char *envp[])
int argc,存放了命令行参数的个数。
char *argv[],是个字符串的数组,每个元素都是一个字符指针,指向一个字符串,即命令行中的每一个参数。
char *envp[],也是一个字符串的数组,这个数组的每一个元素是指向一个环境变量的字符指针。
envp先放一下,先讲argc和argv。
注意几个事项:
1)argc的值是参数个数加1,因为程序名称是程序的第一个参数,即argv[0],在上面的示例中,argv[0]是./book101。
2)main函数的参数,不管是书写的整数还是浮点数,全部被认为是字符串。
3)参数的命名argc和argv是程序员的约定,您也可以用argd或args,但是不建议这么做。
示例:
#include 运行结果:
- envp参数
envp存放了当前程序运行环境的参数。
示例:
#include 运行结果:
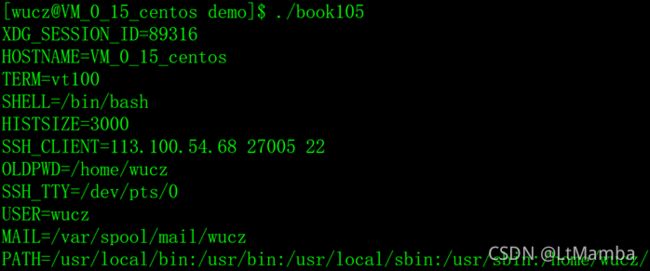
注意:示例运行的结果与linux系统的env命令相同。
在实际开发中,envp参数的应用场景不多,各位了解一下就行了。
21.动态内存管理
编写程序的时候不能确定内存的大小,希望程序在运行的过程中根据数据量的大小动态的分配内存。动态内存管理,就是指在程序运行过程中动态的申请和释放内存空间。
C语言允许程序动态管理内存,需要时随时开辟,不需要时随时释放。内存的动态管理是通过调用库函数来实现的,主要有malloc和free函数。
使用动态分配内存技术的时候,分配出来的内存必须及时释放并让指针指向空或正确的地方free(pi); pi=0;
- malloc 库函数
命名空间:<stdlib.h>
void *malloc(unsigned int size);
malloc的作用是向系统申请一块大小为size的连续内存空间,如果申请失败,函数返回0,如果申请成功,返回成功分配内存块的起始地址。
例如:
malloc(100); // 申请 100 个字节的临时分配域,返回值为其第一个字节的地址
- free 函数
函数的原型:
void free(void *p);
free的作用是释放指针p指向的动态内存空间,p是调用malloc函数时返回的地址,free函数无返回值。
例如:
free(pi); // 释放指针变量pi指向的已分配的动态空间
特别注意:
free中的指针变量,一定是mallocd动态分配出来的否则会一直报free()invalid size的错误。
3. 示例
#include 运行结果:

- 野指针
1、内存指针变量未初始化
指针变量在创建的同时应当被初始化,要么将指针的值设置为0,要么让它指向合法的内存。
int *pi=0;
或
int i;
int *pi=&i;
2、内存释放后之后指针未置空
调用free函数把指针所指的内存给释放掉,但指针不一定会赋值 0(也与编译器有关),如果对释放后的指针进行操作,相当于非法操作内存。释放内存后应立即将指针置为0。
free(pi);
pi=0;
22.文件操作
参考链接
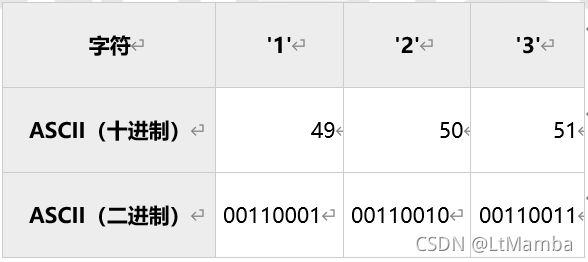
1. 文本文件和二进制文件
文本文件或ASCII文件:按文本格式存放数据的文件;文件可以用vi和记事本打开,看到的都是ASCII字符。
二进制文件:按二进制格式存放数据的文件。
- 文本文件读写:
1. 文件的打开
FILE *fopen( const char * filename, const char * mode );
参数filename 是字符串,表示需要打开的文件名,可以包含目录名,如果不包含路径就表示程序运行的当前目录。实际开发中,采用文件的全路径。
参数mode也是字符串,表示打开文件的方式(模式),打开方式可以是下列值中的一个。
返回值:
为空即为0,就是打开失败,反之为内存地址。

fopen返回的是文件结构体指针FILE:
FILE结构体指针习惯称为文件指针。
操作文件的时候,C语言为文件分配一个信息区,该信息区包含文件描述信息、缓冲区位置、缓冲区大小、文件读写到的位置等基本信息,这些信息用一个结构体来存放(struct _IO_FILE),这个结构体有一个别名FILE(typedef struct _IO_FILE FILE),FILE结构体和对文件操作的库函数在 stdio.h 头文件中声明的。
打开文件的时候,fopen函数中会动态分配一个FILE结构体大小的内存空间,并把FILE结构体内存的地址作为函数的返回值,程序中用FILE结构体指针存放这个地址。
关闭文件的时候,fclose函数除了关闭文件,还会释放FILE结构体占用的内存空间。
2. 关闭文件
int fclose(FILE *fp);
fp为fopen函数返回的文件指针。
返回值:
一般不使用此返回值做判断。
示例:
#include 注意事项:
1)调用fopen打开文件的时候,一定要判断返回值,如果文件不存在、或没有权限、或磁
盘空间满了,都有可能造成打开文件失败。
2)文件指针是调用fopen的时候,系统动态分配了内存空间,函数返回或程序退出之前,
必须用fclose关闭文件指针,释放内存,否则后果严重。
3)如果文件指针是空指针或野指针,用fclose关闭它相当于操作空指针或野指针,后果
严重。
3. 向文件中写入数据
C语言向文件中写入数据库函数有fputc、fputs、fprintf,在实际开发中,
fputc和fputs没什么用,只介绍fprintf就可以了。fprintf函数的声明如下:
int fprintf(FILE *fp, const char *format, ...);
fprintf函数的用法与printf相同,只是多了第一个参数文件指针,表示把数据输出到文件。
程序员不必关心fprintf函数的返回值。
示例:
#include 使用cat命令查看结果:

4. 从文件中读取数据
C语言从文件中读取数据的库函数有fgetc、fgets、fscanf,在实际开发中,
fgetc和fscanf没什么用,只介绍fgets就可以了。fgets函数的原型如下:
char *fgets(char *buf, int size, FILE *fp);
fgets的功能是从文件中读取一行。
参数buf是一个字符串,用于保存从文件中读到的数据。
参数size是打算读取内容的长度。
参数fp是待读取文件的文件指针。
如果文件中将要读取的这一行的内容的长度小于size,fgets函数就读取一行,如
果这一行的内容大于等于size,fgets函数就读取size-1字节的内容。
返回值:
调用fgets函数如果成功的读取到内容,函数返回buf,如果读取错误或文件已结束,
返回空,即0。如果fgets返回空,可以认为是文件结束而不是发生了错误,
因为发生错误的情况极少出现。
在读取到 size-1 个字符之前如果出现了换行,或者读到了文件末尾,则读取结束。
不管 size 的值多大,fgets函只读取一行数据,不能跨行。如果size设置过小,会导致中文字符读一半,从而导致读出数据不符合预期的问题。
在实际开发中,可以将 size 的值设置地足够大,确保每次都能读取到一行完整的数据。
特别注意:文件读和写不能共用一个FILE文件结构指针,否则谁在后面谁就失效!
- 二进制文件的读写
参考链接
二进制文件没有行的概念,没有字符串的概念。
我们把内存中的数据结构直接写入二进制文件,读取的时候,也是从文件中读取数据结构的大小一块数据,直接保存到数据结构中。注意,这里所说的数据结构不只是结构体,是任意数据类型。
向文件中写入数据:
fwrite函数用来向文件中写入数据块,它的原型为:
size_t fwrite(const void *ptr, size_t size, size_t nmemb, FILE *stream);
参数的说明:
ptr:为内存区块的指针,存放了要写入的数据的地址,它可以是数组、变量、结构体等。
size:固定填1。
nmemb:表示打算写入数据的字节数。
fp:表示文件指针。
返回值是本次成功写入数据的字节数,一般情况下,程序员不必关心fwrite函数的返回值。
从文件中读取数据:
fread函数用来从文件中读取数据块,它的原型为:
size_t fread(void *ptr, size_t size, size_t nmemb, FILE *fp);
ptr:用于存放从文件中读取数据的变量地址,它可以是数组、变量、结构体等。
size:固定填1。
nmemb:表示打算读取的数据的字节数。
fp:表示文件指针。
返回值:
读取成功返回字节数;
错误或结束返回空,即0。
如果fread返回空,可以认为是文件结束而不是发生了错误,因为发生错误的情况极少出现。
综上:二进制文件中一般只写一种结构的数据,因为二进制文件无换行和字符等概念,这样易于读取。
- 文件定位
- 概念
在文件内部有一个位置指针,用来指向文件当前读写的位置。在文件打开时,如果打开方式是r和w,位置指针指向文件的第一个字节,如果打开方式是a,位置指针指向文件的尾部。每当从文件里读取n个字节或文件里写入n个字节后,位置指针也会向后移动n个字节。
文件位置指针与C语言中的指针不是一回事。位置指针仅仅是一个标志,表示文件读写到的位置,不是变量的地址。文件每读写一次,位置指针就会移动一次,它不需要您在程序中定义和赋值,而是由系统自动设置,对程序员来说是隐藏的。
在实际开发中,偶尔需要移动位置指针,实现对指定位置数据的读写。我们把移动位置指针称为文件定位。
- 相关函数
C语言提供了ftell、rewind和fseek三个库函数来实现文件定位功能。
1、ftell函数
ftell函数用来返回当前文件位置指针的值,这个值是当前位置相对于文件开始位置的字节数。它的声明如下:
long ftell(FILE *fp);
返回值:当前位置所在位置。
2、rewind函数
rewind函数用来将位置指针移动到文件开头,它的声明如下:
void rewind ( FILE *fp );
无返回值;
3、fseek函数
fseek() 用来将位置指针移动到任意位置,它的声明如下:
int fseek ( FILE *fp, long offset, int origin );
参数说明:
1)fp 为文件指针,也就是被移动的文件。
2)offset 为偏移量,也就是要移动的字节数。之所以为 long 类型,是希望移动的范围更大,能处理的文件更大。offset 为正时,向后移动;offset 为负时,向前移动。
3)origin 为起始位置,也就是从何处开始计算偏移量。C语言规定的起始位置有三种,分别为:0-文件开头;1-当前位置;2-文件末尾。
fseek(fp,100,0); // 从文件的开始位置计算,向后移动100字节。
fseek(fp,100,1); // 从文件的当前位置计算,向后移动100字节。
fseek(fp,-100,2); // 从文件的尾部位置计算,向前移动100字节。
总结:
1)可以发现用fopen函数打开文件时,位置指针都是处在文件开头处,包括用a和a+方式打开,只是在第一次写时位置指针会移动到文件末尾处。
2)只要用"a”方式打开,那么无论用fseek,rewind等文件位置指针定位函数,在写入文件信息时,均只能写入到文件末尾。
- 文件缓冲区
在操作系统中,存在一个内存缓冲区,当调用fprintf、fwrite等函数往文件写入数据的时候,数据并不会立即写入磁盘文件,而是先写入缓冲区,等缓冲区的数据满了之后才写入文件。还有一种情况就是程序调用了fclose时也会把缓冲区的数据写入文件。
如果程序员想把缓冲区的数据立即写入文件,可以调用fflush库函数,它的声明如下:
int fflush(FILE *fp);
函数的参数只有一个,即文件指针,返回0成功,其它失败,程序员一般不关心它的返回值。
- 标准输入、标准输出和标准错误
Linux操作系统为每个程序默认打开三个文件,
即标准输入stdin、标准输出stdout和标准错误输出stderr,
其中0就是stdin,表示输入流,指从键盘输入,
1代表stdout,
2代表stderr,
1,2默认是显示器。
这三个都是文件指针 FILE *.
printf("Hello world.\n");//
等同于
fprintf(stdout,"Hello world.\n");//表示把数据输出到文件(第一个参数代表文件指针),只不过这里stdout默认指的是屏幕文件指针。
这几个文件指针没什么用,让大家了解一下就行。在实际开发中,我们一般会关闭这几个文件指针。
补充知识点:
1. 进制转换
参考链接
2. C语言代码的多行书写
如果我们在一行代码的行尾放置一个反斜杠,c语言编译器会忽略行尾的换行符,而把下一行的内容也算作是本行的内容。
示例:
strcpy(str,"aaaaaaaaaa\
bbbbbbbbb");