Vision Transformer(ViT)
1. 前言
本文讲解Transformer模型在计算机视觉领域图片分类问题上的应用——Vision Transformer(ViT)。
本人全部文章请参见:博客文章导航目录
本文归属于:计算机视觉系列
2. Vision Transformer(ViT)
Vision Transformer(ViT)是目前图片分类效果最好的模型,超越了最好的卷积神经网络(CNN)。ViT在2020年10月挂在arXiv上,2021年正式发表。在所有的公开数据集上,ViT的表现都超越了最好的ResNet,前提是在足够大的数据集上预训练ViT。在越大的数据集上做预训练,则ViT的优势越明显。
Transformer原本是用在自然语言处理领域的模型,ViT是Transformer在计算机视觉领域成功的应用。ViT模型并没有任何创新的地方,其本质就是Transformer模型的Encoder网络。
本文不会讲解Transformer模型原理,想了解其原理可以参见自然语言处理系列。其中Sequence-to-Sequence模型原理一文讲解了Seq2Seq模型原理(Transformer模型也是一种Seq2Seq模型),注意力机制(Attention):Seq2Seq模型的改进一文讲解了注意力机制(Transformer模型是基于注意力层和自注意力层搭建的深度神经网络),自注意力机制(Self-Attention):从Seq2Seq模型到一般RNN模型一文讲解了自注意力机制,Attention is all you need:剥离RNN,保留Attention一文讲解了注意力层和自注意力层原理,搭建Transformer模型一文讲解了Transformer模型原理,BERT与ERNIE一文讲解了Transformer模型预训练方法BERT和ERNIE。
2.1 ViT图片分类
使用ViT实现图片分类,首先需将图片分割成不同的块(Patches)。分割图片可以使不同的Patches之间存在重叠(Overlap),也可以让不同Patches之间不存在重叠。如下图所示,指定patch_size=16x16,stride=16x16,左侧48x48大小的图片可以被分割成右侧所示9个Ptaches。
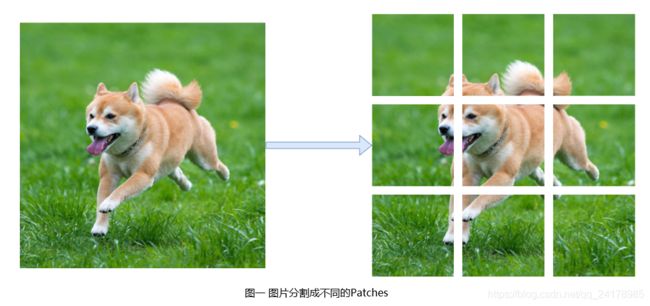
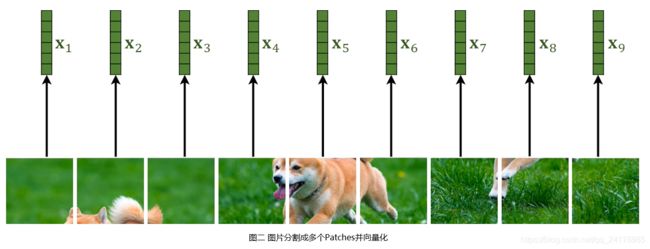
图片被分割成9个Patches,每个Patch都是一张小彩色图片,有RGB三个通道,即每一个Patch均是一个张量。下一步是向量化(Vectorization),即将各个张量拉伸成向量。
如图二所示,经过上述操作,每张图片可以表示成9个向量: [ x 1 , x 2 , ⋯ , x 9 ] [x_1,x_2,\cdots,x_9] [x1,x2,⋯,x9]。其中每个Patch对应的张量的形状为(3,16,16),对应向量的形状为(768,1)。
假设图片被划分成 n n n个Patches,则经过上述操作可以得到 n n n个向量: [ x 1 , x 2 , ⋯ , x n ] [x_1,x_2,\cdots,x_n] [x1,x2,⋯,xn]。使用一个不包含激活函数的全连接层对 n n n个向量做线性变换,得到 n n n个向量: [ z 1 , z 2 , ⋯ , z n ] [z_1,z_2,\cdots,z_n] [z1,z2,⋯,zn]。其中 n n n个全连接层共享参数,即 z 1 = W x 1 + b , z 2 = W x 2 + b , ⋯ , z n = W x n + b z_1=Wx_1+b,z_2=Wx_2+b,\cdots,z_n=Wx_n+b z1=Wx1+b,z2=Wx2+b,⋯,zn=Wxn+b。
因为Transformer’s Encoder完全基于多头自注意力和全连接层,自注意力层无法捕捉输入序列元素的位置关系(原因请参见我的博客BERT与ERNIE),分别输入图三(a)和图三(b)所示两张图片,Transformer’s Encoder的输出相同,即如果 z z z向量总不包含位置信息,则图三(a)和图三(b)在Transformer’s Encoder看来是一样的。这种情况明显不合理,因为图三(a)和图三(b)明显不是一张图片,我们期望Transformer’s Encoder能够知道这种区别,因此必须要做Positional Encoding。
ViT论文中实验表明,如果不实用Positional Encoding,会掉3个点的准确率。论文中尝试了不同的Positional Encoding方式,各种Positional Encoding的表现几乎一样,因此必须使用Positional Encoding,使用的Positional Encoding种类对结果影响不大。

对图片每一个Patch的位置做编码。图片被分割成 n n n个Patches,则位置是 1 ∼ n 1\sim n 1∼n之间的整数,每个位置被编码成一个向量,向量大小与 z z z向量相同。将位置编码得到的向量分别加到 n n n个 z z z向量上。经过上述操作, n n n个 z z z向量即包含图片各个Patches的内容信息,同时也包含各个Patches的位置信息。
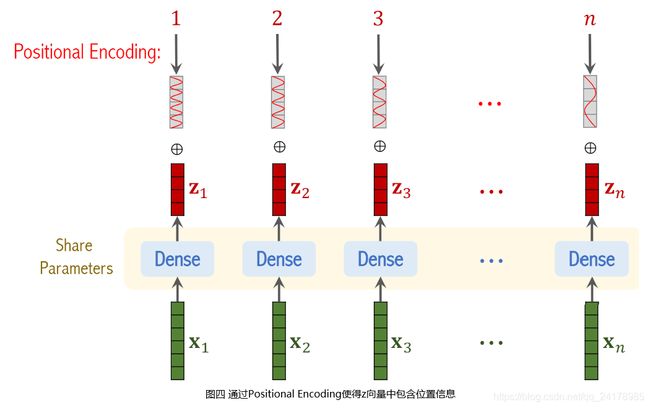
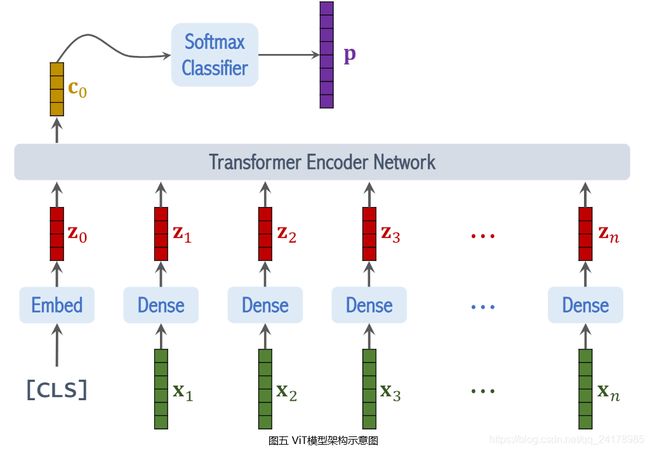
在 [ x 1 , x 2 , ⋯ , x n ] [x_1,x_2,\cdots,x_n] [x1,x2,⋯,xn]之前添加一个 [ C L S ] [CLS] [CLS]表示分类符号,并对 [ C L S ] [CLS] [CLS]符号做 E m b e d d i n g Embedding Embedding,得到向量 z 0 z_0 z0。其中 z 0 z_0 z0与其他 z z z向量大小相同,使用 [ C L S ] [CLS] [CLS]符号的原因是该位置上的输出将会被用于分类。
将 [ z 0 , z 1 , z 2 , ⋯ , z n ] [z_0,z_1,z_2,\cdots,z_n] [z0,z1,z2,⋯,zn]输入Transformer’s Encoder,得到输出 [ c 0 , c 1 , c 2 , ⋯ , c n ] [c_0,c_1,c_2,\cdots,c_n] [c0,c1,c2,⋯,cn]。 c 0 c_0 c0可以看做从输入图片中提取的特征向量,将 c 0 c_0 c0输入 S o f t m a x Softmax Softmax分类器,输出向量 p p p。训练ViT时将向量 p p p和真实标签之间的交叉熵作为损失函数,计算损失函数关于模型参数的梯度,使用梯度下降法更新模型参数。
2.2 ViT效果分析
随机初始化ViT模型参数,在相当大的数据集A上做预训练训练,得到预训练模型,然后在小规模目标数据集B上Fine-Tuning(微调模型参数),最后在数据集B对应的测试集上评价模型表现,得到测试准确率。
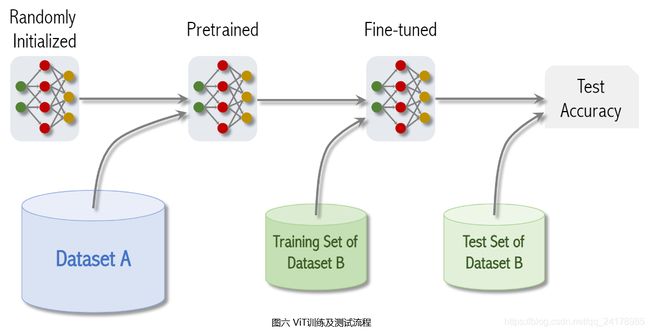
ViT论文共在3个数据集上按照上述流程探讨了ViT模型效果,分别是:
| 数据集 | 图片数 | 类别数 |
|---|---|---|
| ImageNet (Small) | 1.3 Million | 1 Thousand |
| ImageNet-21K (Medium) | 14 Million | 21 Thousand |
| JFT (Big) | 300 Million | 18 Thousand |
JFT是Google内部数据集,不对外公开。
分别使用ImageNet、ImageNet-21K和JFT预训练ViT,在ImageNet、CIFAR-10、CIFAR-100等目标数据集上Fine-Tuning并评估模型效果。根据ViT论文实验结果:
- 在
ImageNet上预训练ViT,在所有目标数据集上ViT效果均比ResNet稍微稍微差一点; - 在
ImageNet-21K上预训练ViT,在所有目标数据集上ViT效果和ResNet差不多; - 在
JFT上预训练ViT,在所有目标数据集上ViT测试准确率会比ResNet高1%左右。
实验表明,当预训练数据集不够大时,ViT效果并不好。在越大的数据集上做预训练,ViT的优势就会越大,如果预训练的数据集图片小于1亿张,ViT效果一般不如ResNet。当预训练数据集中图片超过1亿张时,ViT效果会优于ResNet。从实验结果上看,即便拥有3亿张图片的JFT数据集还是不够大,如果能继续增大预训练数据集,ViT的优势还会进一步增大。反观ResNet在预训练数据量1亿和3亿时区别不大,继续增大预训练数据集,ResNet几乎不会有提升。
总的来说,ViT(或者说Transformer)需要大数据量做预训练,随着预训练数据量增加,ViT的准确率也会一直增加。当预训练图片数据量超过1亿张时,ViT图片分类效果将会优于效果最好的卷积神经网络ResNet。
个人认为Transformer模型的潜力还远远没有被挖掘出来,更本质地说,注意力机制(Attention)的潜力还远远没有被挖掘出来。此外,论文分割图片,并将各个Patches向量化的方法有点类似于深度学习早期直接将图片按行和列展开,并且输入多层感知机的方式,这种方式不可避免地存在丢失图片中像素空间位置关系的问题。如何将CNN和Transformer结合起来,或者说如何在CNN中引入注意力机制,我想会是一个值得深入研究的方向。
不过,综合Transformer模型各种文章来看,Transformer模型优越性往往只有在超大规模数据量训练和海量算力资源加持下才能显性出去优越性。
但是任何事物都是有两面性的,当大公司采取这种“暴力的”方式提升模型效果时,没有这些资源,或许可以把更多精力放在如何巧妙地设计模型结构,更好地发挥注意力机制效能方面,这未必不是一条走得通的道路。
2021年8月23日更新:
今天在知乎上看到一文正面刚CNN,Transformer居然连犯错都像人类中提到【卷积擅长提取细节,要掌握全局信息往往需要堆叠很多个卷积层;注意力善于把握整体,但又需要大量的数据进行训练;从最近的趋势看来,Transformer在CV领域的应用,反倒是刺激了二者的结合和统一。】,也印证了上述【如何将CNN和Transformer结合起来,或者说如何在CNN中引入注意力机制,会是一个值得深入研究的方向。】的想法。
3. 参考资料链接
- https://www.youtube.com/watch?v=BbzOZ9THriY&list=PLvOO0btloRntpSWSxFbwPIjIum3Ub4GSC&index=4
- https://arxiv.org/pdf/2010.11929v2.pdf