高斯过程回归|机器学习推导系列(二十四)
一、概述
将⼀维高斯分布推⼴到多变量中就得到了高斯网络,将多变量推⼴到无限维,就得到了高斯过程。高斯过程是定义在连续域(时间/空间)上的无限多个高斯随机变量所组成的随机过程。具体的形式化的定义如下:
对于时间轴上的随机变量序列 { ξ t } t ∈ T \left \{\xi _{t}\right \}_{t\in T} {ξt}t∈T, T T T是一个连续域,如果 ∀ n ∈ N + \forall n\in N^{+} ∀n∈N+, t 1 , t 2 , ⋯ , t n ∈ T t_{1},t_{2},\cdots ,t_{n}\in T t1,t2,⋯,tn∈T,满足 { ξ t 1 , ξ t 2 , ⋯ , ξ t n } ≜ ξ t 1 − t n ∼ N ( μ t 1 − t n , Σ t 1 − t n ) \left \{\xi _{t_{1}},\xi _{t_{2}},\cdots ,\xi _{t_{n}}\right \}\triangleq\xi _{t_{1}-t_{n}}\sim N(\mu _{t_{1}-t_{n}},\Sigma _{t_{1}-t_{n}}) {ξt1,ξt2,⋯,ξtn}≜ξt1−tn∼N(μt1−tn,Σt1−tn),那么 { ξ t } t ∈ T \left \{\xi _{t}\right \}_{t\in T} {ξt}t∈T就是一个高斯过程(Gaussian Process)。
上面的定义中 t t t称为index, ξ t \xi _{t} ξt是随机变量。
一个高斯过程可以有两个函数,即均值函数 m ( t ) m(t) m(t)和协方差函数 k ( s , t ) k(s,t) k(s,t)来确定:
G P ( m ( t ) , k ( s , t ) ) { m ( t ) = E [ ξ t ] k ( s , t ) = E [ ( ξ s − E [ ξ s ] ) ( ξ t − E [ ξ t ) ] GP\left (m\left (t\right ),k\left (s,t\right )\right )\\ \left\{\begin{matrix} m(t)=E[\xi _{t}]\\ k\left (s,t\right )=E[(\xi _{s}-E[\xi _{s}])(\xi _{t}-E[\xi _{t})] \end{matrix}\right. GP(m(t),k(s,t)){m(t)=E[ξt]k(s,t)=E[(ξs−E[ξs])(ξt−E[ξt)]
举个例子来说,下图的时间轴(也就是定义中的连续域)代表了人的一生,这里假设人能活100岁,从这个连续域里任意取多个时刻都会对应了一个高斯随机变量:
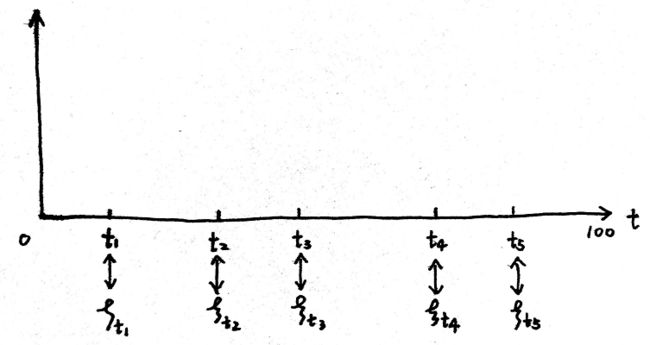
这里的每个随机变量可以认为是一个人在一生中这个阶段的表现值,服从一个高斯分布:

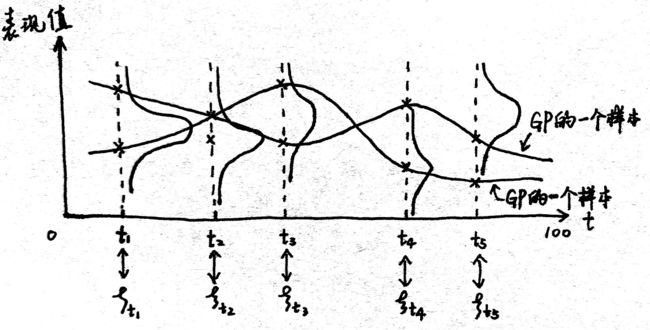
在这个人人生的每一个阶段,如果他比较努力,他的表现可能就比均值高,如果不努力可能表现就比均值低,将每个高斯分布采样的样本点连起来就是高斯过程的一个样本:
二、核贝叶斯线性回归-权重空间角度
之前的贝叶斯线性回归博客:贝叶斯线性回归|机器学习推导系列(二十三)
对于线性的数据,我们可以直接应用贝叶斯线性回归的方法,而对于非线性数据,可以尝试使用核方法将低位数据扩展到高维空间,然后再应用贝叶斯线性回归。类比支持向量机的核方法,如果最后的结果只和一个核函数,也就是关于 x x x的内积有关,那么就可以应用核方法,同样的在非线性的贝叶斯线性回归回归中,如果将数据拓展到高维空间后后验的均值和方差都只与一个核函数有关,那说明将核方法应用在贝叶斯线性回归中是可行的。
对于线性数据的预测来说,有:
f ( x ∗ ) ∣ X , Y , x ∗ ∼ N ( ( x ∗ ) T σ − 2 Λ w − 1 X T Y , ( x ∗ ) T Λ w − 1 x ∗ ) , 其 中 Λ w = σ − 2 X T X + Σ p − 1 f(x^{*})|X,Y,x^{*}\sim N\left (\left (x^{*}\right )^{T}\sigma ^{-2}\Lambda _{w}^{-1}X^{T}Y,\left (x^{*}\right )^{T}\Lambda _{w}^{-1}x^{*}\right ),\; 其中\Lambda _{w}=\sigma ^{-2}X^{T}X+\Sigma _{p}^{-1} f(x∗)∣X,Y,x∗∼N((x∗)Tσ−2Λw−1XTY,(x∗)TΛw−1x∗),其中Λw=σ−2XTX+Σp−1
对于非线性数据,要使用核方法,首先要对其进行低维到高维的非线性转换:
I f : ϕ : x ↦ z , x ∈ R p , z = ϕ ( x ) ∈ R q , q > p D e f i n e : Φ = ϕ ( X ) = ( ϕ ( x 1 ) ϕ ( x 2 ) ⋯ ϕ ( x N ) ) N × q T T h e n : f ( x ) = ϕ ( x ) T w f ( x ∗ ) ∣ X , Y , x ∗ ∼ N ( σ − 2 ϕ ( x ∗ ) T Λ w − 1 Φ T Y , ϕ ( x ∗ ) T Λ w − 1 ϕ ( x ∗ ) ) , Λ w = σ − 2 Φ T Φ + Σ p − 1 If:\phi :x \mapsto z,\; x\in \mathbb{R}^{p},\; z=\phi (x)\in \mathbb{R}^{q},\; q> p\\ Define:\Phi =\phi (X)=\begin{pmatrix} \phi (x_{1}) & \phi (x_{2}) & \cdots & \phi (x_{N}) \end{pmatrix}_{N\times q}^{T}\\ Then:f(x)=\phi (x)^{T}w\\ f(x^{*})|X,Y,x^{*}\sim N\left (\sigma ^{-2}\phi \left (x^{*}\right )^{T}\Lambda _{w}^{-1}\Phi ^{T}Y,\phi \left (x^{*}\right )^{T}\Lambda _{w}^{-1}\phi \left (x^{*}\right )\right ),\; \Lambda _{w}=\sigma ^{-2}\Phi ^{T}\Phi +\Sigma _{p}^{-1} If:ϕ:x↦z,x∈Rp,z=ϕ(x)∈Rq,q>pDefine:Φ=ϕ(X)=(ϕ(x1)ϕ(x2)⋯ϕ(xN))N×qTThen:f(x)=ϕ(x)Twf(x∗)∣X,Y,x∗∼N(σ−2ϕ(x∗)TΛw−1ΦTY,ϕ(x∗)TΛw−1ϕ(x∗)),Λw=σ−2ΦTΦ+Σp−1
上面的式子中,均值和方差都存在 Λ w − 1 \Lambda _{w}^{-1} Λw−1,这一项可以通过伍德伯里矩阵恒等式(Woodbury Matrix Identity)求出来,该恒等式如下:
( A + U C V ) − 1 = A − 1 − A − 1 U ( C − 1 + V A − 1 U ) − 1 V A − 1 其 中 A : n × n , U : n × k , C : k × k , V : k × n (A+UCV)^{-1}=A^{-1}-A^{-1}U(C^{-1}+VA^{-1}U)^{-1}VA^{-1}\\ 其中A:n\times n,U:n\times k,C:k\times k,V:k\times n (A+UCV)−1=A−1−A−1U(C−1+VA−1U)−1VA−1其中A:n×n,U:n×k,C:k×k,V:k×n
按照伍德伯里矩阵恒等式的形式,我们可以将 Λ w \Lambda _{w} Λw对应为 A + U C V A+UCV A+UCV:
Λ w = Σ p − 1 ⏟ A + Φ T ⏟ U σ − 2 I ⏟ C Φ ⏟ V \Lambda _{w}=\underset{A}{\underbrace{\Sigma _{p}^{-1}}}+\underset{U}{\underbrace{\Phi ^{T}}}\underset{C}{\underbrace{\sigma ^{-2}I}}\underset{V}{\underbrace{\Phi}} Λw=A Σp−1+U ΦTC σ−2IV Φ
代入恒等式求解得到 Λ w − 1 \Lambda _{w}^{-1} Λw−1:
Λ w − 1 = ( Σ p − 1 + Φ T σ − 2 I Φ ) − 1 = Σ p − Σ p Φ T ( σ 2 I + Φ Σ p Φ T ) − 1 Φ Σ p \Lambda _{w}^{-1}=(\Sigma _{p}^{-1}+\Phi ^{T}\sigma ^{-2}I\Phi)^{-1}\\ =\Sigma _{p}-\Sigma _{p}\Phi ^{T}(\sigma ^{2}I+\Phi\Sigma _{p}\Phi ^{T})^{-1}\Phi\Sigma _{p} Λw−1=(Σp−1+ΦTσ−2IΦ)−1=Σp−ΣpΦT(σ2I+ΦΣpΦT)−1ΦΣp
将 Λ w − 1 \Lambda _{w}^{-1} Λw−1代入就能 f ( x ∗ ) ∣ X , Y , x ∗ f(x^{*})|X,Y,x^{*} f(x∗)∣X,Y,x∗,就能得到均值和方差,不过这里的均值直接代入比较复杂,可以通过对 Λ w \Lambda _{w} Λw做一些变换来得到均值:
Λ w = σ − 2 Φ T Φ + Σ p − 1 ⇔ Λ w Σ p = σ − 2 Φ T Φ Σ p + I ⇔ Λ w Σ p Φ T = σ − 2 Φ T Φ Σ p Φ T + Φ T ⇔ Λ w Σ p Φ T = σ − 2 Φ T ( Φ Σ p Φ T + σ 2 I ) ⇔ Σ p Φ T = σ − 2 Λ w − 1 Φ T ( Φ Σ p Φ T + σ 2 I ) ⇔ σ − 2 Λ w − 1 Φ T = Σ p Φ T ( Φ Σ p Φ T + σ 2 I ) − 1 ⇔ σ − 2 ϕ ( x ∗ ) T Λ w − 1 Φ T Y = ϕ ( x ∗ ) T Σ p Φ T ( Φ Σ p Φ T + σ 2 I ) − 1 Y \Lambda _{w}=\sigma ^{-2}\Phi ^{T}\Phi +\Sigma _{p}^{-1}\\ \Leftrightarrow \Lambda _{w}\Sigma _{p}=\sigma ^{-2}\Phi ^{T}\Phi \Sigma _{p}+I\\ \Leftrightarrow \Lambda _{w}\Sigma _{p}\Phi ^{T}=\sigma ^{-2}\Phi ^{T}\Phi \Sigma _{p}\Phi ^{T}+\Phi ^{T}\\ \Leftrightarrow \Lambda _{w}\Sigma _{p}\Phi ^{T}=\sigma ^{-2}\Phi ^{T}(\Phi \Sigma _{p}\Phi ^{T}+\sigma ^{2}I)\\ \Leftrightarrow \Sigma _{p}\Phi ^{T}=\sigma ^{-2}\Lambda _{w}^{-1}\Phi ^{T}(\Phi \Sigma _{p}\Phi ^{T}+\sigma ^{2}I)\\ \Leftrightarrow \sigma ^{-2}\Lambda _{w}^{-1}\Phi ^{T}=\Sigma _{p}\Phi ^{T}(\Phi \Sigma _{p}\Phi ^{T}+\sigma ^{2}I)^{-1}\\ \Leftrightarrow \sigma ^{-2}\phi (x^{*})^{T}\Lambda _{w}^{-1}\Phi ^{T}Y=\phi (x^{*})^{T}\Sigma _{p}\Phi ^{T}(\Phi \Sigma _{p}\Phi ^{T}+\sigma ^{2}I)^{-1}Y Λw=σ−2ΦTΦ+Σp−1⇔ΛwΣp=σ−2ΦTΦΣp+I⇔ΛwΣpΦT=σ−2ΦTΦΣpΦT+ΦT⇔ΛwΣpΦT=σ−2ΦT(ΦΣpΦT+σ2I)⇔ΣpΦT=σ−2Λw−1ΦT(ΦΣpΦT+σ2I)⇔σ−2Λw−1ΦT=ΣpΦT(ΦΣpΦT+σ2I)−1⇔σ−2ϕ(x∗)TΛw−1ΦTY=ϕ(x∗)TΣpΦT(ΦΣpΦT+σ2I)−1Y
由此求得了 f ( x ∗ ) ∣ X , Y , x ∗ f(x^{*})|X,Y,x^{*} f(x∗)∣X,Y,x∗的均值,将 Λ w − 1 \Lambda _{w}^{-1} Λw−1带入方差可以计算得到方差:
ϕ ( x ∗ ) T Σ p ϕ ( x ∗ ) − ϕ ( x ∗ ) T Σ p Φ T ( σ 2 I + Φ Σ p Φ T ) − 1 Φ Σ p ϕ ( x ∗ ) \phi(x^{*})^{T}\Sigma _{p}\phi(x^{*})-\phi(x^{*})^{T}\Sigma _{p}\Phi ^{T}(\sigma ^{2}I+\Phi\Sigma _{p}\Phi ^{T})^{-1}\Phi\Sigma _{p}\phi(x^{*}) ϕ(x∗)TΣpϕ(x∗)−ϕ(x∗)TΣpΦT(σ2I+ΦΣpΦT)−1ΦΣpϕ(x∗)
因此最终得到 f ( x ∗ ) ∣ X , Y , x ∗ f(x^{*})|X,Y,x^{*} f(x∗)∣X,Y,x∗的概率分布如下:
f ( x ∗ ) ∣ X , Y , x ∗ ∼ N ( ϕ ( x ∗ ) T Σ p Φ T ( Φ Σ p Φ T + σ 2 I ) − 1 Y , ϕ ( x ∗ ) T Σ p ϕ ( x ∗ ) − ϕ ( x ∗ ) T Σ p Φ T ( σ 2 I + Φ Σ p Φ T ) − 1 Φ Σ p ϕ ( x ∗ ) ) f(x^{*})|X,Y,x^{*}\sim N({\color{Red}{\phi (x^{*})^{T}\Sigma _{p}\Phi ^{T}}}({\color{Red}{\Phi \Sigma _{p}\Phi ^{T}}}+\sigma ^{2}I)^{-1}Y,{\color{Red}{\phi(x^{*})^{T}\Sigma _{p}\phi(x^{*})}}-{\color{Red}{\phi(x^{*})^{T}\Sigma _{p}\Phi ^{T}}}(\sigma ^{2}I+{\color{Red}{\Phi\Sigma _{p}\Phi ^{T}}})^{-1}{\color{Red}{\Phi\Sigma _{p}\phi(x^{*})}}) f(x∗)∣X,Y,x∗∼N(ϕ(x∗)TΣpΦT(ΦΣpΦT+σ2I)−1Y,ϕ(x∗)TΣpϕ(x∗)−ϕ(x∗)TΣpΦT(σ2I+ΦΣpΦT)−1ΦΣpϕ(x∗))
通过上面式子的红色部分可以看出 f ( x ∗ ) ∣ X , Y , x ∗ f(x^{*})|X,Y,x^{*} f(x∗)∣X,Y,x∗的分布只与 K ( x , x ′ ) = ϕ ( x ) T Σ p ϕ ( x ′ ) K(x,x^{'})=\phi(x)^{T}\Sigma _{p}\phi(x^{'}) K(x,x′)=ϕ(x)TΣpϕ(x′)这样的项有关,如果可以证明这是一个核函数(能够表示成一个内积的形式)的话就说明对于非线性数据来说是可以引入核技巧来将数据映射到高维空间然后再应用贝叶斯线性回归的。现在来做以下定义:
∵ Σ p : 正 定 且 对 称 , Σ p = ( Σ p 1 / 2 ) 2 ∴ K ( x , x ′ ) = ϕ ( x ) T Σ p 1 / 2 Σ p 1 / 2 ϕ ( x ′ ) = ( Σ p 1 / 2 ϕ ( x ) ) T Σ p 1 / 2 ϕ ( x ′ ) = < ψ ( x ) , ψ ( x ′ ) > , ψ ( x ) = Σ p 1 / 2 ϕ ( x ) \because \Sigma _{p}:正定且对称,\Sigma _{p}=(\Sigma _{p}^{1/2})^{2}\\ \therefore K(x,x^{'})=\phi(x)^{T}\Sigma _{p}^{1/2}\Sigma _{p}^{1/2}\phi(x^{'})=\left (\Sigma _{p}^{1/2}\phi(x)\right )^{T}\Sigma _{p}^{1/2}\phi(x^{'})=<\psi (x),\psi (x^{'})>,\; \; \psi (x)=\Sigma _{p}^{1/2}\phi(x) ∵Σp:正定且对称,Σp=(Σp1/2)2∴K(x,x′)=ϕ(x)TΣp1/2Σp1/2ϕ(x′)=(Σp1/2ϕ(x))TΣp1/2ϕ(x′)=<ψ(x),ψ(x′)>,ψ(x)=Σp1/2ϕ(x)
因此这是一个核函数。
核贝叶斯线性回归也就是高斯过程回归,这个从参数 w w w的角度进行推导的过程是高斯过程回归的权重空间角度。
三、从权重空间角度到函数空间角度
对于应用了核方法的贝叶斯线性回归,满足:
f ( x ) = ϕ ( x ) T w y = f ( x ) + ε ε ∼ N ( 0 , σ 2 ) f(x)=\phi (x)^{T}w\\ y=f(x)+\varepsilon \\ \varepsilon \sim N(0,\sigma ^{2}) f(x)=ϕ(x)Twy=f(x)+εε∼N(0,σ2)
这里给定先验 w w w满足一个高斯分布:
w ∼ N ( 0 , Σ p ) w\sim N(0,\Sigma _{p}) w∼N(0,Σp)
w w w是一个随机变量,那么 f ( x ) f(x) f(x)也是一个随机变量,对于不同 x x x, f ( x ) f(x) f(x)就是不同的随机变量, { f ( x ) } \left \{f(x)\right \} {f(x)}就是一些随机变量的组合。接下来,对于 f ( x ) f(x) f(x),我们看一下它的均值和协方差:
E [ f ( x ) ] = E [ ϕ ( x ) T w ] = ϕ ( x ) T E [ w ] = 0 c o v ( f ( x ) , f ( x ′ ) ) = E [ ( f ( x ) − E [ f ( x ) ] ⏟ = 0 ) ( f ( x ′ ) − E [ f ( x ′ ) ] ⏟ = 0 ) ] = E [ f ( x ) ⋅ f ( x ′ ) ] = E [ ϕ ( x ) T w ⋅ ϕ ( x ′ ) T w ] = E [ ϕ ( x ) T w w T ϕ ( x ′ ) ] = ϕ ( x ) T E [ w w T ] ϕ ( x ′ ) = ϕ ( x ) T E [ ( w − 0 ) ( w T − 0 ) ] ϕ ( x ′ ) = ϕ ( x ) T Σ p ϕ ( x ′ ) = K ( x , x ′ ) E[f(x)]=E[\phi (x)^{T}w]=\phi (x)^{T}E[w]=0\\ cov\left (f(x),f(x^{'})\right )=E[(f(x)-\underset{=0}{\underbrace{E[f(x)]}})(f(x^{'})-\underset{=0}{\underbrace{E[f(x^{'})]}})]\\ =E[f(x)\cdot f(x^{'})]\\ =E[\phi (x)^{T}w\cdot \phi (x^{'})^{T}w]\\ =E[\phi (x)^{T}ww^{T}\phi (x^{'})]\\ =\phi (x)^{T}E[ww^{T}]\phi (x^{'})\\ =\phi (x)^{T}E[(w-0)(w^{T}-0)]\phi (x^{'})\\ =\phi (x)^{T}\Sigma _{p}\phi (x^{'})\\ =K(x,x^{'}) E[f(x)]=E[ϕ(x)Tw]=ϕ(x)TE[w]=0cov(f(x),f(x′))=E[(f(x)−=0 E[f(x)])(f(x′)−=0 E[f(x′)])]=E[f(x)⋅f(x′)]=E[ϕ(x)Tw⋅ϕ(x′)Tw]=E[ϕ(x)TwwTϕ(x′)]=ϕ(x)TE[wwT]ϕ(x′)=ϕ(x)TE[(w−0)(wT−0)]ϕ(x′)=ϕ(x)TΣpϕ(x′)=K(x,x′)
显然 f ( x ) f(x) f(x)的协方差是一个核函数,类比高斯过程的定义, x x x也就相当于index t t t,每个 x x x对应一个随机变量 f ( x ) f(x) f(x), f ( x ) f(x) f(x)也就相当于 ξ t \xi _{t} ξt,只不过这里 f ( x ) f(x) f(x)和 x x x有明确的函数关系,而 ξ t \xi _{t} ξt和 t t t没有,另外 f ( x ) f(x) f(x)的协方差也满足一个核函数,这说明 f ( x ) f(x) f(x)就是一个高斯过程,这也说明了核贝叶斯线性回归为什么就是高斯线性回归。
求解高斯过程回归的方法分为权重空间和函数空间两种,上一节的权重空间角度的方法我们关注的是权重 w w w,而函数空间的方法关注的是 f ( x ) f(x) f(x),下一小节就介绍一下函数空间角度的求解方法。
四、函数空间角度
已有数据如下:
X = ( x 1 x 2 ⋯ x N ) N × p T Y = ( y 1 y 2 ⋯ y N ) N × 1 T X=\begin{pmatrix} x_{1} & x_{2} & \cdots & x_{N} \end{pmatrix}_{N\times p}^{T}\\ Y=\begin{pmatrix} y_{1} & y_{2} & \cdots & y_{N} \end{pmatrix}_{N\times 1}^{T} X=(x1x2⋯xN)N×pTY=(y1y2⋯yN)N×1T
对于 f ( X ) f(X) f(X),满足:
f ( X ) ∼ N ( μ ( X ) , K ( X , X ) ) f(X)\sim N(\mu (X),K(X,X)) f(X)∼N(μ(X),K(X,X))
对于 Y Y Y,满足:
Y ∼ N ( μ ( X ) , K ( X , X ) + σ 2 I ) Y\sim N(\mu (X),K(X,X)+\sigma ^{2}I) Y∼N(μ(X),K(X,X)+σ2I)
解释一下方差矩阵 K ( X , X ) + σ 2 I K(X,X)+\sigma ^{2}I K(X,X)+σ2I的由来,对于方差矩阵对角线上的元素:
E [ y ⋅ y ] = E [ ( f ( x ) + ε ) ( f ( x ) + ε ) ] = E [ f ( x ) ⋅ f ( x ) + 2 f ( x ) ⋅ ε + ε ⋅ ε ] = E [ f ( x ) ⋅ f ( x ) ] ⏟ f ( x ) 的 方 差 + 2 E [ f ( x ) ⋅ ε ] ⏟ 相 互 独 立 变 量 的 协 方 差 + E [ ε ⋅ ε ] ⏟ ε 的 方 差 = K ( x , x ) + σ 2 E[y\cdot y]=E[(f(x)+\varepsilon )(f(x)+\varepsilon )]\\ =E[f(x)\cdot f(x)+2f(x)\cdot \varepsilon +\varepsilon \cdot \varepsilon ]\\ =\underset{f(x)的方差}{\underbrace{E[f(x)\cdot f(x)]}}+2\underset{相互独立变\\量的协方差}{\underbrace{E[f(x)\cdot \varepsilon ]}}+\underset{\varepsilon 的方差}{\underbrace{E[\varepsilon \cdot \varepsilon ]}}\\ =K(x,x)+\sigma ^{2} E[y⋅y]=E[(f(x)+ε)(f(x)+ε)]=E[f(x)⋅f(x)+2f(x)⋅ε+ε⋅ε]=f(x)的方差 E[f(x)⋅f(x)]+2相互独立变量的协方差 E[f(x)⋅ε]+ε的方差 E[ε⋅ε]=K(x,x)+σ2
对于方差矩阵非对角线上的元素:
E [ y ⋅ y ′ ] = E [ ( f ( x ) + ε ) ( f ( x ′ ) + ε ′ ) ] = E [ f ( x ) ⋅ f ( x ′ ) + ε ⋅ f ( x ′ ) + f ( x ) ⋅ ε ′ + ε ⋅ ε ′ ] = E [ f ( x ) ⋅ f ( x ′ ) ] + E [ ε ⋅ f ( x ′ ) ] ⏟ 相 互 独 立 变 量 的 协 方 差 + E [ f ( x ) ⋅ ε ′ ] ⏟ 相 互 独 立 变 量 的 协 方 差 + E [ ε ⋅ ε ′ ] ⏟ 相 互 独 立 变 量 的 协 方 差 = K ( x , x ′ ) E[y\cdot y^{'}]=E[(f(x)+\varepsilon )(f(x^{'})+\varepsilon ^{'})]\\ =E[f(x)\cdot f(x^{'})+\varepsilon \cdot f(x^{'})+f(x)\cdot \varepsilon ^{'}+\varepsilon \cdot \varepsilon ^{'}]\\ =E[f(x)\cdot f(x^{'})]+\underset{相互独立变\\量的协方差}{\underbrace{E[\varepsilon \cdot f(x^{'})]}}+\underset{相互独立变\\量的协方差}{\underbrace{E[f(x)\cdot \varepsilon ^{'}]}}+\underset{相互独立变\\量的协方差}{\underbrace{E[\varepsilon \cdot \varepsilon ^{'}]}}\\ =K(x,x^{'}) E[y⋅y′]=E[(f(x)+ε)(f(x′)+ε′)]=E[f(x)⋅f(x′)+ε⋅f(x′)+f(x)⋅ε′+ε⋅ε′]=E[f(x)⋅f(x′)]+相互独立变量的协方差 E[ε⋅f(x′)]+相互独立变量的协方差 E[f(x)⋅ε′]+相互独立变量的协方差 E[ε⋅ε′]=K(x,x′)
预测问题也就是对于给定的新的数据 X ∗ = ( x 1 ∗ x 2 ∗ ⋯ x M ∗ ) X^{*}=\begin{pmatrix} x_{1}^{*} & x_{2}^{*} & \cdots & x_{M}^{*} \end{pmatrix} X∗=(x1∗x2∗⋯xM∗),需要求解对应的 Y ∗ = f ( X ∗ ) + ε Y^{*}=f(X^{*})+\varepsilon Y∗=f(X∗)+ε。
我们把 Y Y Y和 f ( X ∗ ) f(X^{*}) f(X∗)拼接成一个向量,并且按照上面得到方差矩阵的方法简单推一下就可以得到这个拼接起来的向量的分布:
( Y f ( X ∗ ) ) ∼ N ( ( μ ( X ) μ ( X ∗ ) ) , ( K ( X , X ) + σ 2 I K ( X , X ∗ ) K ( X ∗ , X ) K ( X ∗ , X ∗ ) ) ) \begin{pmatrix} Y\\ f(X^{*}) \end{pmatrix}\sim N\left (\begin{pmatrix} \mu (X)\\ \mu (X^{*}) \end{pmatrix},\begin{pmatrix} K(X,X)+\sigma ^{2}I & K(X,X^{*})\\ K(X^{*},X) & K(X^{*},X^{*}) \end{pmatrix}\right ) (Yf(X∗))∼N((μ(X)μ(X∗)),(K(X,X)+σ2IK(X∗,X)K(X,X∗)K(X∗,X∗)))
而对于预测问题,我们要求的是 P ( f ( X ∗ ) ∣ X , Y , X ∗ ) P(f(X^{*})|X,Y,X^{*}) P(f(X∗)∣X,Y,X∗)这个概率,其实也就是 P ( f ( X ∗ ) ∣ Y ) P(f(X^{*})|Y) P(f(X∗)∣Y),也就是上面拼接起来的向量的一个条件概率分布,而求解高维高斯分布的条件概率分布的方法在高斯分布|机器学习推导系列(二)这一篇中已经推导过了,有现成的公式可以套用:
x = ( x a x b ) = ( ( μ a μ b ) , ( Σ a a Σ a b Σ b a Σ b b ) ) x b ∣ a ∼ N ( u b ∣ a , Σ b ∣ a ) u b ∣ a = Σ b a Σ a a − 1 ( x a − μ a ) + μ b Σ b ∣ a = Σ b b − Σ b a Σ a a − 1 Σ a b x=\begin{pmatrix} x_{a}\\ x_{b} \end{pmatrix}=\left (\begin{pmatrix} \mu_{a}\\ \mu_{b} \end{pmatrix},\begin{pmatrix} \Sigma _{aa}&\Sigma _{ab}\\ \Sigma _{ba}&\Sigma _{bb} \end{pmatrix}\right )\\ x_{b|a}\sim N(u_{b|a},\Sigma _{b|a})\\ u_{b|a}=\Sigma _{ba}\Sigma _{aa}^{-1}(x_{a}-\mu _{a})+\mu _{b}\\ \Sigma _{b|a}=\Sigma _{bb}-\Sigma _{ba}\Sigma _{aa}^{-1}\Sigma _{ab} x=(xaxb)=((μaμb),(ΣaaΣbaΣabΣbb))xb∣a∼N(ub∣a,Σb∣a)ub∣a=ΣbaΣaa−1(xa−μa)+μbΣb∣a=Σbb−ΣbaΣaa−1Σab
对应到上面的拼接向量也就是:
( Y ⏟ x a f ( X ∗ ⏟ x b ) ) ∼ N ( ( μ ( X ) ⏟ μ a μ ( X ∗ ) ⏟ μ b ) , ( K ( X , X ) + σ 2 I ⏟ Σ a a K ( X , X ∗ ) ⏟ Σ a b K ( X ∗ , X ) ⏟ Σ b a K ( X ∗ , X ∗ ) ⏟ Σ b b ) ) \begin{pmatrix} \underset{x_{a}}{\underbrace{Y}}\\ \underset{x_{b}}{\underbrace{f(X^{*}}}) \end{pmatrix}\sim N\left (\begin{pmatrix} \underset{\mu _{a}}{\underbrace{\mu (X)}}\\ \underset{\mu _{b}}{\underbrace{\mu (X^{*})}} \end{pmatrix},\begin{pmatrix} \underset{\Sigma _{aa}}{\underbrace{K(X,X)+\sigma ^{2}I}} & \underset{\Sigma _{ab}}{\underbrace{K(X,X^{*})}}\\ \underset{\Sigma _{ba}}{\underbrace{K(X^{*},X)}} & \underset{\Sigma _{bb}}{\underbrace{K(X^{*},X^{*})}} \end{pmatrix}\right ) ⎝⎜⎜⎛xa Yxb f(X∗)⎠⎟⎟⎞∼N⎝⎜⎜⎛⎝⎜⎜⎛μa μ(X)μb μ(X∗)⎠⎟⎟⎞,⎝⎜⎜⎛Σaa K(X,X)+σ2IΣba K(X∗,X)Σab K(X,X∗)Σbb K(X∗,X∗)⎠⎟⎟⎞⎠⎟⎟⎞
套用公式得到概率 P ( f ( X ∗ ) ∣ Y ) P(f(X^{*})|Y) P(f(X∗)∣Y):
P ( f ( X ∗ ) ∣ Y ) = N ( K ( X ∗ , X ) ( K ( X , X ) + σ 2 I ) − 1 ( Y − μ ( X ) ) + μ ( X ∗ ) , K ( X ∗ , X ∗ ) − K ( X ∗ , X ) ( K ( X , X ) + σ 2 I ) − 1 K ( X , X ∗ ) ) P(f(X^{*})|Y)=N({\color{Red}{K(X^{*},X)(K(X,X)+\sigma ^{2}I)^{-1}(Y-\mu (X))+\mu (X^{*})}},\\ {\color{Blue}{K(X^{*},X^{*})-K(X^{*},X)(K(X,X)+\sigma ^{2}I)^{-1}K(X,X^{*})}}) P(f(X∗)∣Y)=N(K(X∗,X)(K(X,X)+σ2I)−1(Y−μ(X))+μ(X∗),K(X∗,X∗)−K(X∗,X)(K(X,X)+σ2I)−1K(X,X∗))
再加上噪声就得到 Y ∗ Y^{*} Y∗的分布:
P ( f ( X ∗ ) ∣ Y ) = N ( K ( X ∗ , X ) ( K ( X , X ) + σ 2 I ) − 1 ( Y − μ ( X ) ) + μ ( X ∗ ) , K ( X ∗ , X ∗ ) − K ( X ∗ , X ) ( K ( X , X ) + σ 2 I ) − 1 K ( X , X ∗ ) + σ 2 I ) P(f(X^{*})|Y)=N({\color{Red}{K(X^{*},X)(K(X,X)+\sigma ^{2}I)^{-1}(Y-\mu (X))+\mu (X^{*})}},\\ {\color{Blue}{K(X^{*},X^{*})-K(X^{*},X)(K(X,X)+\sigma ^{2}I)^{-1}K(X,X^{*})+\sigma ^{2}I}}) P(f(X∗)∣Y)=N(K(X∗,X)(K(X,X)+σ2I)−1(Y−μ(X))+μ(X∗),K(X∗,X∗)−K(X∗,X)(K(X,X)+σ2I)−1K(X,X∗)+σ2I)
显然比起权重空间角度的方法,从函数空间角度出发更容易求解这个问题。