thinkPHP6.0入门笔记(九)——路由的使用
thinkPHP6.0路由的使用
-
-
- 1.路由存在的意义
- 2.路由的定义方式
- 3.路由的限制规则
- 4.多级路由的访问
- 5.路由的函数筛选
- 6.路由的跨域请求
- 7.路由的分组与MISS
-
- 7.1路由的分组
- 7.2路由的MISS
- 8.资源路由
- 9.注解路由与url的生成原理
-
- 9.1注解路由
- 9.2 url的生成
-
- 参考文献:
-
1.路由存在的意义
首先简单说一下路由是干什么的。之前我们在使用PHP函数的时候,是通过如下方式使用的:
localhost/index.php/index/hello/name/world
简单解释一下,localhost/index.php是入口文件,index表示的是控制器,hello表示的是index这个控制器里面的方法,name指的是前面提到的hello方法里面的参数名,world就是参数值。如果这个不直观的话,请看下图,对应的代码如下:

总结如下:在不使用路由的情况下调用函数的方式为:
localhost/index.php/控制器名称/函数名称/参数名称/参数值
你可能想问如果有多个参数应该怎么办呢?很简单在后面照加就行:
localhost/index.php/控制器名称/函数名称/param1/value1/param2/value2
当你写完之后,你肯定有点不爽了,这要是我不知道名字,这怎么分辨呀,又是控制器名又是参数名,还加个参数值,他们没有什么区分方式也太难受了。其实,也是可以区分的,根据上面的规则,将index.php之后的第一个看做控制器,之后看成函数名,后面依次是参数和值交替出现。
虽然是这个道理,总觉得说了也白说。好,看如下两种种方式:
http://localhost/index.php/index/hello?name=world&index=8
http://localhost/index.php/index/hello/:name/world/:index/8
第一种方式就不用怎么说了,其实就是最常见的get提交方式,比如百度搜索就是这样的。对于第二种方式,其实是在参数前面加了一个“:”方便区分参数。
那么问题来了,你平时见过这么长的url吗?太多了,比如CSDN的链接分享。额…确实,但是我们自己设计总不想把url设计成这么长吧。route的意义就在这里,它可以使我们的url更加简洁。
2.路由的定义方式
这里我们不多说明了,起初接触路由的时候,你可能像我一样觉得有些不适应,倒想回到原始状态。这其实是还没有掌握规则,当你熟悉了之后,你就会发现它是真的香。使用规则大致分为两种:(1)指定方式路由;(2)附加方式路由;
首先,我们必须要知道,浏览器的提交共有五种方式:get、post、delete、put、patch;前面两种是比较常用的,后面的三种可以先放一下^_^。简单说一下这个get和post,get一般用来获取服务器上的资源,post一般是向服务器提交资源,对于一个网站来说,get多用于路由的跳转,post多用于表单数据的提交,至于二者的详细区别,有兴趣可以看看这篇文章,讲的还挺详细,推荐给大家:
GET和POST两种基本请求方法的区别
具体的路由定义方式为,在route/app.php文件中写入如下代码:
Route::get('simplify/:name/:index','Index/hello');
//访问方式:localhost/index.php/simplify/value1/value2
第一个参数是简写后的访问方式,第二个参数是路由位置(控制器名称/方法名称)至于其他的请求方式只需要将get方法改成post、delete等就行,但是得提醒一下的是不同的路由请求方式浏览器处理机制是不一样的。换句话说就是利用get请求的写法发送post请求报错是很正常的。再补充如下几点:
(1)将get换成any表示任意一种方式的路由都包含;
(2)浏览器对于路由的匹配是从上到下的,如果匹配就执行,对于重复的路由是不会报错的。
(3)已经定义路由之后,再使用原始的路由方式会报错,这是因为thinkPHP会默认去检测路由是否存在(这样也便于减少冲突)。
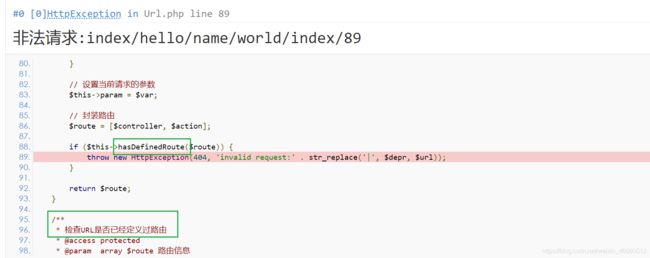
说完指定方式路由之后,附加就简单了,只是把路由方式放到了后面,具体写法,在route/app.php文件中写入如下代码:
Route::rule('simplify/:name/:index','Index/hello','get|post');
前两个参数同上,第三个参数表示访问方式,可以是‘any’,也可以是多个方式用“|”连接。推荐使用第一种方法(更利于路由匹配)。

3.路由的限制规则
有些时候我们可能需要限制用户传入的参数,还用pattern就行。紧跟上面的例子,具体写法如下:
Route::get('simplify/:name/:index','index/hello')->pattern([
'name'=>'[A-za-z]{6}',
'index'=>'\d+'
]);
对于正则规则的写法可以参照: 菜鸟教程正则表达式写法
通过数据测试发现,路由的检测将会顺着里面的正则向下检索,如果没能匹配,将会继续向下检索,如果实在没有,则采用原始方式将simplify当成控制器查询。同样做一些补充:
(1)定义某参数的全局匹配规则(不管那种路由,只要出现该参数,就需要检测相应规则),方式如下:
Route::pattern(['name'=>'[A-za-z]{6}']);
(2)路由的参数除了使用“:”区分参数外,还可以使用如下方式:
Route::get('simplify//' ,'index/hello');
(3)路由之间的访问方式比较灵活,可以使用特殊符号(只要不被浏览器解码就行),例如:
Route::get('simplify/@_@' ,'index/hello');
(4)动态路由(即将控制器的名字使用变量代替),具体写法如下:
Route::get('simplify/' ,'/index' );
4.多级路由的访问
这里还是举例说明吧,在实际应用中,当项目比较大的时候,可能需要对项目进行分组。例如下面的控制器结构:
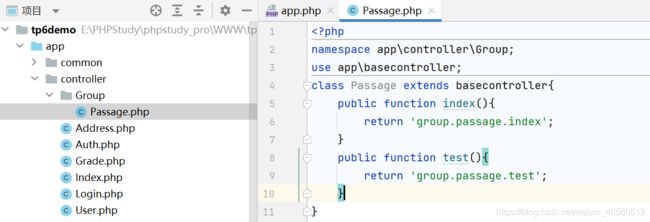
这时有如下两种路由定义方式:
(1)直接使用“.”进行分级:
Route::get('passage','Group.Passage/index');
(2)使用全局路由:
Route::get('test','app\controller\Group\Passage@test');
注:最后的方法名之前使用“@”,至于参数的传递,和上面一样。补充一点,建议使用第一种方式,在实际应用中发现:第二种由于使用的全局路径导致实际上的路径依然保留在index目录下,不会跳转到对应的二级目录下,按照常规方法使用facade门面类的时候会报错。
5.路由的函数筛选
路由方法还具有很多辅助筛选函数,比较常用的函数如下:
(1)ext函数,用于强制url路由后缀,使用方法如下:
Route::get('passage','Group.Passage/index')->ext('html|css');
解释:上述表示的是,访问的url路径必须是.html或者.css为后缀的,否则将不会匹配此条路由规则。此处补充说明一点,我们平时使用原始方法访问控制器下面的方法的时候,会发现路径后面会默认加上.html的后缀,其实这是在config/route.php的 url_html_suffix 处设置的,当此参数为false或者是空的时候表示的是并不设置后缀,同时测试发现,如果对应路径后缀与实际不符时,默认路径会失效,应该是thinkPHP框架内部对于路径作了检测或者说是规则定义,可能说的不太直观,那么看到下一个路径便会明白了(设置该参数为hml,这个也是html文件中的一类,故而后缀可行,但是设置css等默认后缀将失效):
![]()
(2)https函数,对于路由规则会筛选https的安全路由,如果使用的 不是https而是http,将不会予以匹配,用法举例如下:
Route::get('passage','Group.Passage/index')->https();
(3)denyExt函数,禁止使用某些后缀,可用于防止访问图片资源等,例如如下写法:
Route::get('passage','Group.Passage/index')->denyExt('jpg|jpeg|gif|png');
(4)domain函数,用于过滤域名或者子级域名,用法举例:
Route::get('passage','Group.Passage/index')->denyExt('nightowl.top');
//Route::get('passage','Group.Passage/index')->denyExt('create');
解释:第一种表示的匹配对应的域名,第二种表示的匹配子级域名中是否含有相关的后缀。
(5)ajax函数,用于筛选是否是通过Ajax发起请求,这个需要通过jQuery封装的Ajax函数库来进行测试。经过一番思索,发现可以使用如下代码进行测试:
<script>
function btnTest(){
// console.log('Ajax请求按钮被点击!');
// $.ajax({
// type:'get',
// data:{
// 'username':'凌空暗羽',
// 'age':'20'
// },
// url:'http://localhost/index.php/test',
// success:function(res){
// console.log('发送get请求成功!',res);
// }
// })
console.log('直接跳转');
window.location.href='http://localhost/index.php/test';
}
</script>
Route::get('test','Group.Passage/test')->ajax();
解释:通过上面的两种方法和对应路由,测试发现,不使用->ajax()筛选路由时上述两种方法都能够使用。但是如果使用了筛选,将导致下面的方法由于路由不匹配而报错(因为该路由不是Ajax请求)。
(6)filter函数,用于匹配必要参数,用法如下:
Route::get('test','Group.Passage/test')->filter([
'username'=>'凌空暗羽',
'age'=>20
]);
解释:上述表示的是url请求必须含有username和age两个参数并且这两个参数的值也需要一致,否则该路由不会被匹配。
(7)append函数,用于附加参数,主要是用来页面间额外传值,用法如下:
Route::get('test','Group.Passage/test')->filter([
'hobby'=>'fishing'
]);
(8)补充说明,对于url的匹配筛选,同样遵循链式法则,也可以使用option方法直接调用数组,用法如下:
Route::get('test','Group.Passage/test')->option([
'https'=>false,
'filter'=>['username'=>'凌空暗羽','age'=>20],
'append'=>['hobby'=>'fishing'],
'ajax'=>true
]);
此外,也可以使用如下写法进行筛选:
Route::domain(['test','origin'],function(){
Route::get('passage','Group.Passage/index')->ajax(false);
});

6.路由的跨域请求
在实际请求时,我们可能会遇到如下问题:

解释:上述英文报错指的是,Cookie和XMLHttprequest层面的同源策略禁止 Ajax 直接发起跨域HTTP请求(其实可以发送请求,结果被浏览器拦截,不展示),同时 Ajax 请求不能携带与本网站不同源的 Cookie。这主要是因为浏览器为了安全起见,不支持不同域进行跨域请求,这里的域或者源指的是协议+域名+端口。
首先,说一下为什么持跨域请求不安全,跨域请求容易被不法分子利用,进而进行跨域请求伪造,简单地说,指的是不法网站借用用户身份去登录他们想要去登录的网站,并执行相关操作(比如不法网站借用用户身份去转账),具体实现的过程如下:
问题来了,有时候因为实际需要,我们还是需要发送跨域请求。说起跨域,我们很容易会想到之前我们网页引入百度图片的时候也是跨域,其实这里使用了JSONP技术,JSONP 本质上是利用