开发者李雷小朋友维护了一个自己的关系链图数据库,他怎么能从图数据库中查询出与他互相关注且年龄大于30的朋友呢?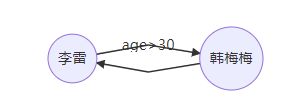
这里先介绍几种图原生查询语言写法:
1.gremlin
g.V("李雷").outE('friend').has('age',gt(30)).otherV().where(out('friend').
(hasId('李雷'))).limit(100)2.cypher
match (a)-[r1:friend]->(b)-[r2:friend]->(c) where a.mid='李雷' and r1.age>30 and a=c return id(b) limit 100以上两种写法等价,只是使用的图查询语言有区别。前者使用gremlin(Apache软件基金会下TinkerPop开发的graph traversal language)编写, 后者为Neo4j于2015年发布的图查询语言开源版本openCypher。
查询方式一览
GES支持多种查询方式,本文主要讨论复杂查询,如多跳过滤,简单环路查询,模式匹配等复杂查询类。当前GES主要通过gremlin,cypher和一些原生API来支持各种场景的查询需求。
| 优点 | 缺点 | 说明 | ||
|---|---|---|---|---|
| Gremlin | functional language | 1.表达能力(图灵完备) 2.支持groovy脚本 | 1.性能差(exponential runtime tree) 2.复杂的查询书写困难 | 适用于体验,demo,或不追求性能的场景 |
| Cypher | Pattern match style, declarative | 1.类SQL写法 2.深度集成于GES,性能比gremlin好一些 | 1.表达能力对图来说差一些(仅为SQL complete) 2.流式支持有限 | 适用于一般性场景 |
| 原生API | json parameter | 1.性能非常好 2.傻瓜参数形式 | 1.灵活性差 2.使用场景有限 3.表达能力差 | 提供常用查询API,适用于最求性能,高并发,低延迟的场景 |
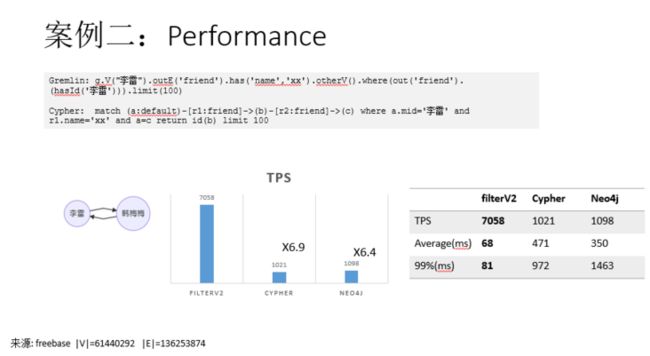
性能
本节以上文所述李雷的好友场景展示一个查询k=2环路的性能测试,用以帮助大家更直观地了解各个查询间的性能差距:
其中,
- filterV2 - GES原生API,该API性能最佳,TPS与延迟表现优异。
- Cypher - GES的cypher查询。
- Neo4j - Neo4j community 4.2.3版本cypher。
- gremlin - GES的gremlin,未在图中体现,实际性能最差,故未做对比。
gremlin使用手册
gremlin包括OLTP和OLAP两个部分的语法。其OLTP的语法灵活多变,符合图原生的表达方式,被广泛集成于各个图数据库厂商。
GES查询能力优异,但我们仅建议在demo/简单查询中使用gremlin。其性能远远低于内核原生API与cypher, 这是由gremlin的集成方式决定的,虽然GES在常用语法上做了适当的优化,但是并不能完全覆盖所有的gremlin查询。我们向您推荐使用集成度更加高的cypher查看后续cypher章节进行常态化查询,如果有更需要性能的场景,请使用原生API。
查看以下参考资料获取更多信息:
- tinkerpop documentation tinkerpop官方文档。内容详实,各个step都有案例介绍。
- gremlin 实践案例 gremlin实践案例
常用语法
g.V() //获取图中所有点。注意该行为在大图上是高危操作,小心使用。
g.V().limit(10) //取图中10个点。非随机。
g.V('小霞','小智').values('age') //获取图中id为小智和小霞的属性值age的值。
> [20, 22]
g.V('小智').out('朋友').out('朋友') //获取小智的朋友的朋友
> [小明]
g.V('小智').outE('朋友').inV().outE('朋友').inV() //该条语句含义和上条完全一致。
g.V('小智').out('朋友').has('age',gt(30)) //获取小智年龄大于30的朋友
g.V('小智').out('朋友').values('age').sum() //统计小智所有朋友的年龄总和GES gremlin特殊语法/优化
GES集成了gremlin中的OLTP功能,并在一定程度上做了部分功能增强与strategy优化。
增强版Text Predicate
g.V().has('name', Text.textSubString('xx'))...| Predicate | 描述 |
|---|---|
| textSubString | 子字符串 |
| textCISubString | 忽略大小写的子字符串 |
| textFuzzy | 模糊匹配 |
| textPrefix | 前缀查询 |
| textRegex | 正则匹配 |
注意事项
在指定schema时,最好不要给属性取名为id, label, property, properties。
在进行gremlin操作时,有很多step会把结果转化为map结果。众所周知,在map结构中,是不允许出现两个相同key的,一般来说当我们向一个map中重复insert多个相同的key,其value会被覆盖 or 该操作被取消。
故如果我们把属性名取为id, label, property, properties,在很多操作中,如果id与属性中的id一起返回,结果将是不完整的。
cypher使用手册
cypher在语法上更接近于SQL,表达能力稍微欠缺一些(sql完备),但已能应对绝大多数场景。
GES对于cypher的集成更加接近内核端,充分利用了内核的性能优势。
查看以下参考资料获取更多信息:
- cypher refcard cypher语法参考卡。
- GES cypher GES cypher公有云API文档,包含兼容性说明,数据类型支持,表达式,函数等说明。
常用语法
match (n) return n //获取图中所有点。注意该行为在大图上需小心使用。
match (n) return n limit 10 //取图中10个点。非随机。
match (n) where n.movieid IN ['小霞','小智'] return n.age //获取图中id为小智和小霞的属性值age的值。
match (n)-->(m1:朋友)-->(s1)-->(m2:朋友)-->(s2) where id(n)='小智' return s2 //获取小智的朋友的朋友
match (n)-->(m1:朋友)-->(s) where id(n)='小智' and s.age>30 return s //获取小智年龄大于30的朋友兼容性说明
GES对cypher会进行持续性的优化与加强。当前因为特性/开发进度的原因暂不支持包括:
- 目前暂不支持union、merge、foreach、optional等操作,暂不支持使用Cypher语句增删索引,后续会逐渐开放支持。
- 由于GES的元数据不是Schema Free的,点边label属性等有严格的限制,因此不支持Remove操作。
- Order by子句不支持List类型的排序,当属性值的Cardinality不为single时,排序结果未知。
以上说明可在cypher文档中获取最新的支持情况。
GES cypher 特殊化处理
预置条件
为了加速查询以及优化查询计划,GES的Cypher查询编译过程中使用了基于label的点边索引。可通过界面/API添加相关的索引新建索引API。
POST http://{SERVER_URL}/ges/v1.0/{project_id}/graphs/{graph_name}/indices
{
"indexName": "cypher_vertex_index",
"indexType": "GlobalCompositeVertexIndex",
"hasLabel": "true",
"indexProperty": []
}原生API使用手册
内核原生API是专门为常用场景提供的高性能版本。其输入输出均为json格式。
GES提供了丰富多样的原生API接口,包括管理面API(主要是图操作,导入导出备份等),业务面API。业务面API包括基础的图数据库功能,如点边的CRUD,索引的管理,高级查询path query,高级算法库。
查看以下参考资料获取更多信息:
- 管理面API概览
- 业务面API概览,业务面API的调用方法可以参考此篇博文。
- 执行算法说明
常用API说明
一.Path Query
该接口支持对多跳过滤,循环执行遍历查询进行加速。
例如以下gremlin语句:
g.V('node1').repeat(out('label_1')).times(3).emit()以上gremlin是一个三跳查询,从点node1出发,查询其出边关系为label1的邻居的邻居的邻居。并返回过程中所有涉及到的点。该脚本通过repeat来组织查询,并通过times来控制loop的次数,甚至后续还可以通过关键字until来终止traversal。
以上gremlin使用path query调用可使用:
POST /ges/v1.0/{projectId}/graphs/{graphName}/action?action_id=path-query
{
"repeat": [
{
"operator": "outV",
"edge_filter": {
"property_filter": {
"leftvalue": {
"label_name": "labelName"
},
"predicate": "=",
"rightvalue": {
"value": "label_1"
}
}
}
}
],
"emit": true,
"times": 3,
"vertices": [
"node1"
]
}1. by mode
例如针对二跳邻居,我们可以通过参数by对id,label,property进行过滤:
g.V("a").repeat(out()).times(2).by(id()) //输出a的所有一跳二跳邻居的id。
g.V("a").repeat(out()).times(2).by(label()) //输出a的所有一跳二跳邻居的label。而使用path query我们可以很轻易地把上述gremlin转化为原生API以获得更加优异的性能,关键字含义几乎一致。在by中可以指定输出的形式,如输出id:
{
"repeat": [
{
"operator": "outV"
}
],
"times": 2,
"vertices": [
"a"
],
"by": [{"id": true}]
}2. select+by mode
该模式可任意选择traverse路径上经过的N层。
如上图,我们希望显示李雷与其第二跳好友的关联关系:
gremlin写法:
g.V('李雷').as('v0').repeat(out()).times(2).as('v2').select('v0','v2').by(id()).by(id()).dedup()
{//返回样例
"results": [
{
"v0": "李雷",
"v2": "小智"
},
{
"v0": "李雷",
"v2": "小霞"
}
]
}cypher写法:
match (v0)<--(v1)<--(v2) where id(v0)='1' return distinct id(v0),id(v2)
//返回json如下,形式稍显冗余:
{
"data": [
{
"row": [
"李雷",
"小智"
],
"meta": [
null,
null
]
},
{
"row": [
"李雷",
"小霞"
],
"meta": [
null,
null
]
}
]
}使用path query:
{
"repeat": [
{
"operator": "outV"
}
],
"times": 2,
"vertices": [
"李雷"
],
"by": [{"id": true},{"id": true}],
"select": ["v0", "v2"]
}
//返回json如下,直接返回select中的参数:
{
"select": [
["李雷", "小智"],
["李雷", "小霞"]
]
}二.算法API
算法API提供丰富的原生算法库,可以通过界面或者API使用。
在界面上直接运行算法能够可视化地查看算法结果,关于每个算法的详情,也可以查询官方算法文档。
| 参数 | 是否必选 | 说明 | 类型 | 取值范围 | 默认值 |
|---|---|---|---|---|---|
| alpha | 否 | 权重系数(又称阻尼系数) | Double | 0~1,不包括0和1 | 0.85 |
| convergence | 否 | 收敛精度 | Double | 0~1,不包括0和1 | 0.00001 |
| max_iterations | 否 | 最大迭代次数 | Integer | 1~2000 | 1000 |
| directed | 否 | 是否考虑边的方向 | Boolean | true或false | true |
如上pagerank算法参数列表,列出了参数说明,取值范围以及默认值。
此外,我们也可以直接使用RESTful API的形式调用算法,大部分算法以异步的形式交互:调用算法后我们可以获得一个jobId。使用jobId我们可以查询算法运行的状态及运行结果。同时也可以对结果进行分页及数量截取。
GET http://{SERVER_URL}/ges/v1.0/{project_id}/graphs/{graph_name}/jobs/{job_id}/status?offset=0&limit=2最短路径 shortest_path
最短路径属于一个传统的图论问题,其包含各种不同的形式。如单源最短路,多源最短路。常用的算法如Dijkstra, Bellman-Ford, Floyd-Warshall, Johnson等算法。
GES提供多种场景的最短路径,如shortest_path, all_shortest_paths, shortest_path_of_vertex_sets等。均以原生API或图形界面的方式提供
该API属于算法API,其调用方式查看文档。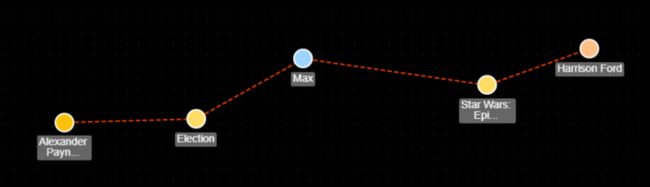
POST /ges/v1.0/{project_id}/graphs/{graph_name}/action?action_id=execute-algorithm
{
"executionMode": "sync",
"algorithmName": "shortest_path",
"parameters": {
"source": "Alexander Payne",
"target": "Harrison Ford",
"weight":"score"
}
}不同查询方式场景详解
案例1-好友推荐
我们向李雷推荐好友,思路是:向他推荐其好友的好友,但是推荐的好友中不应包含李雷本身的好友,比如图中韩梅梅同时是李雷的一跳好友和二跳好友。这时我们不应向李雷推荐韩梅梅,因为她已经是李雷的好友了。
下面将分别展示使用gremlin,cypher和path query查询,返回均为推荐路径:李雷->李雷好友->推荐好友。
gremlin
gremlin>
g.V("李雷").repeat(out("friend").simplePath().where(without('1hop')).store('1hop')).
times(2).path().by("name").limit(100)
gremlin>
[李雷,小明,小智]
[李雷,韩梅梅,小智]
[李雷,韩梅梅,小霞]cypher
match (a)-[:friend]->(d) where id(a)='李雷' with a, collect(d) as neighbor
match (a)-[:friend]-(b)-[:friend]-(c)
where not (c in neighbor)
return a.name, b.name, c.name
//返回样例
[
{
"row": ["李雷", "小明","小智"],
"meta": [null, null, null]
},
{
"row": ["李雷","韩梅梅", "小智"],
"meta": [null, null, null]
},
{
"row": ["李雷", "韩梅梅", "小霞"],
"meta": [null, null, null]
}
]path query
{
"repeat": [
{
"operator": "outV",
"edge_filter": {
"property_filter": {
"leftvalue": {
"label_name": "labelName"
},
"predicate": "=",
"rightvalue": {
"value": "friend"
}
}
}
}
],
"times": 2,
"vertices": [
"李雷"
],
"by": [{"id": true},{"id": true},{"id": true}],
"select": ["v0", "v1", "v2"]
}{
"select": [
["李雷", "小明","小智"],
["李雷","韩梅梅", "小智"],
["李雷", "韩梅梅", "小霞"]
]
}案例2-(k=2环路)
开发者李雷小朋友维护了一个自己的关系链图数据库,他怎么能从图数据库中查询出与他互相关注且年龄大于30的朋友呢?
回到文章开头,我们如何帮助李雷完成查询呢?这其实可以归结为一个环路问题。
我们需要获取李雷的双向好友。即从李雷出发的k=2且边上过滤条件为age>30,friend的环路。
下面将分别展示使用gremlin,cypher,path query和环路算法进行查询,该四种方式均可以帮助李雷完成目标。
gremlin
gremlin>
g.V("李雷").outE().has('age',gt(30)).otherV().where(out('friend').
(hasId('李雷'))).limit(100)cypher
match (a)-[r1]->(b)-[r2:friend]->(c) where a.mid='李雷' and r1.age>30 and a=c return id(b) limit 100
path query
POST /ges/v1.0/{projectId}/graphs/{graphName}/action?action_id=path-query
{
"repeat": [
{
"operator": "outV",
"edge_filter": {
"property_filter": {
"leftvalue": {
"property_name": "age"
},
"predicate": ">",
"rightvalue": {
"value": "30"
}
}
}
},
{
"operator": "outV",
"edge_filter": {
"property_filter": {
"leftvalue": {
"label_name": "label_name"
},
"predicate": "=",
"rightvalue": {
"value": "friend"
}
}
}
}
],
"limit": 100,
"times": 2,
"vertices": ["李雷"],
"by": [{ "id": true}],
"select": ["v1"]
}环路算法
{
"algorithmName": "filtered_circle_detection",
"parameters": {
"sources": "李雷",
"n": 100
},
"filters": [
{},
{
"operator": "out",
"edge_filter": {
"property_filter": {
"leftvalue": {
"property_name": "age"
},
"predicate": ">",
"rightvalue": {
"value": "30"
}
}
}
},
{
"operator": "out",
"edge_filter": {
"property_filter": {
"leftvalue": {
"label_name": "label_name"
},
"predicate": "=",
"rightvalue": {
"value": "friends"
}
}
}
}
]
}本文由华为云发布