《Spark快速大数据分析》——读书笔记(5)
第五章 数据读取与保存
5.1 动机
动机:数据量比较大,单台机器无法完成。
三类常见的数据源:
- 文件格式与文件系统。对于存储在本地文件系统或分布式文件系统(比如NFS、HDFS、Amazon S3等)中的数据,Spark可以访问很多种不同的文件格式,包括文本文件、JSONSequenceFile以及protocal buffer。
- Spark SQL中的结构化数据源。
- 数据库与键值存储。
5.2 文件格式

5.2.1 文本文件
将一个文本文件读取为RDD时,输入的每一行都会成为RDD的一个元素。也可以将多个完整的文本文件一次性读取为一个pair RDD,键是文件名,值是文件内容。
1. 读取文本文件
使用SparkContext的textFile()函数。
例5-1:在Python中读取一个文本文件
input=sc.textFile("file:///..../README.md")如果有多个输入文件以一个包含数据所有部分的目录的形式出现。有两种处理方式:
- 仍使用textFile函数,传递目录作为参数。
- 使用SparkContext.wholeTextFiles()方法,该方法会返回一个pairRDD,键是输入文件的文件名。
Spark支持读取给定目录中的所有文件,以及在输入路径中使用通配字符。
2. 保存文本文件
saveAsTextFile()方法接收一个路径,并将RDD中的内容都输入到路径对应的文件中。这个方法中,我们不能控制数据的哪一部分输出到那个文件中,不过有些输出格式支持控制。
例5-5:在Python中将数据保存为文本文件
result.saveAsTextFile(outputFile)5.2.2 JSON
1. 读取JSON
将数据作为文本文件读取,然后对JSON数据进行解析,该方法在所有支持的编程语言中都可以使用。该方法假设文件中每一行都是一条JSON记录。
例5-6:在Python中读取非结构化的JSON
import json
data=input.map(lambda x:json.loads(x))需要注意格式不正确的记录的处理。
2. 保存JSON
可以使用之前将字符串RDD转为解析好的JSON数据的苦,将由结构化数据组成的RDD转为字符串RDD,然后使用Spark的文本文件API写出去。
例5-9:在Python保存为JSON
(data.filter(lambda x:x["lovePandas"]).map(lambda x:json.dumps(x)).saveAsTextFile(outputFile))5.2.3 逗号分隔值与制表符分割值
1. 读取CSV
先把文件当做普通文本文件来读取数据,再对数据进行处理。
如果CSV的所有数据字段均没有包含换行符,可以使用textFile()读取并解析数据。
例5-12:在Python中使用textFile()读取CSV
import csv
import StringIO
---
def loadRecord(line):
"""解析一行CSV记录"""
input=StringIO.StringIO(line)
reader=csv.DictReader(input,fieldnames=["name","favouriteAnimal"])
return reader.next()
input=sc.textFile(inputFile).map(loadRecord)如果在字段中嵌有换行符,就需要完整读入每个文件,然后解析各段,如果每个文件都很大,读取和解析过程可能会成为性能瓶颈。
例5-15:在Python中完整读取CSV
def loadRecords(fileNameContents):
"""读取给定文件中的所有记录"""
input=StringIO.StringIO(fileNameContents[1])
reader=csv.DictReader(input,fieldnames=["name","favouriteAnimal"])
return reader
fullFileData=sc.wholeTextFiles(inputFile).flatMap(loadRecords)2. 保存CSV
和JSON数据一样,写出CSV/TSV可以通过重用输出编码器来加速。由于在CSV中我们不会在每条记录中输出字段名,因此为了使输出保持一致,需要创建一种映射关系。
例5-18:在Python中写CSV
def writeRecords(records)
"""写出一些CSV记录"""
output=StringIO.StringIO()
writer=csv.DictWriter(output,fieldnames=["name","favoriteAnimal"])
for record in records:
write.writerow(record)
return [output.getvalue()]
pandaLovers.mapPartitions(writeRecords).saveAsTextFile(outputFile)5.2.4 SequenceFile
SequenceFile是由没有相对关系结构的键值对文件组成的常用Hadoop格式。SequenceFile文件有同步标记,Spark可以用它定位到文件中的某个点,然后再与记录的边界对齐。这可以让Spark使用多个节点高效地并行读取SequenceFile文件。
由于Hadoop使用了一套自定义的序列化框架,因此SequenceFile是由实现Hadoop的Writable接口元素组成。

1. 读取SequenceFile
Spark有专门用来读取SequenceFile的接口。在SparkContext中,可以调用sequenceFile(path, keyClass, valueClass, minpartitions),前面提及SequenceFile使用Writable类,因此keyClass和valueClass都必须使用正确的Writable类。
例5-20:在Python中读取SequenceFile
val data=sc.sequenceFile(inFile,"org.apache.hadoop.io.Text", "org.apache.hadoop.io.IntWritable")2. 保存SequenceFile
在Scala中,需要创建一个又可以写出到SequenceFile的类型构成的PairRDD,如果要保存的是Scala的原生类型,可以直接调用saveSequenceFile(path) 。如果键和值不能自动转为Writable类型,或想使用变长类型,可以对数据进行映射操作,在保存之前进行类型转换。
5.2.5 对象文件
对象文件看起来详实对SequenceFile的简单封装,它允许存储至包含值的RDD。和SequenceFile不一样的是,对象文件是使用Java序列化写出的。
注意:如果你修改了类,比如增减了几个字段,已经生成的对象文件就不再可读了。
对对象文件使用Java序列化需要注意:
- 和普通的SequenceFile不同,对同样的对象,对象文件的输出和Hadoop的输出不一样。
- 对象文件通常用于Spark作业间的通信。
- Java序列化有可能相当慢。
对象文件的保存:RDD上调用saveAsObjectFile。
对象文件的读取:用SparkContext中的objectFile()接受路径,返回RDD。
对象文件的优点:可以用来保存几乎任意对象而不需要额外的工作。
对象文件在Python中无法使用,不过Python中RDD和SparkContext支持saveAsPickleFile()和pickleFile()方法替代。
5.2.6 Hadoop输入输出格式
除了Spark封装的格式外,也可以与任何Hadoop支持的格式交互。Spark支持新旧两套Hadoop文件API。
1. 读取其他Hadoop输入格式
新版的Hadoop API读入文件,newAPIHadoopFile。第一个类是“格式”类,代表输入格式,第二个类是键的类,最后一个类是值的类。
旧版的Hadoop API读入文件,HadoopFile。
我们学习了通过读取文本文件并加以解析以读取JSON数据的方法。也可以自定义Hadoop输入格式来读取JSON数据。
2. 保存Hadoop输出格式
使用旧式API保存pair RDD。
例5-26:在Java保存SequenceFile
public static class ConvertToWritableTypes implements
PairFunction<Tuple2<String,Integer>,Text,IntWritable>{
public Tuple2 call(Tuple2 record){
return new Tuple2(new Text(record._1),new IntWritable(record._2));
}
}
JavaPairRDD rdd=sc.parallelizePairs(input);
JavaPairRDD result=rdd.mapToPair(new ConvertToWritableTypes());
result.saveAsHadoopFile(fileName,Text.calss,IntWritable.class,SequenceFileOutputFormat.class); 3. 非文件系统数据源
hadoopDataset/saveAsHadoopDataSet和newAPIHadoopDataset/saveAsNewAPIHadoopDataset可以访问Hadoop所支持的非文件系统的存储格式。
5.2.7 文件压缩
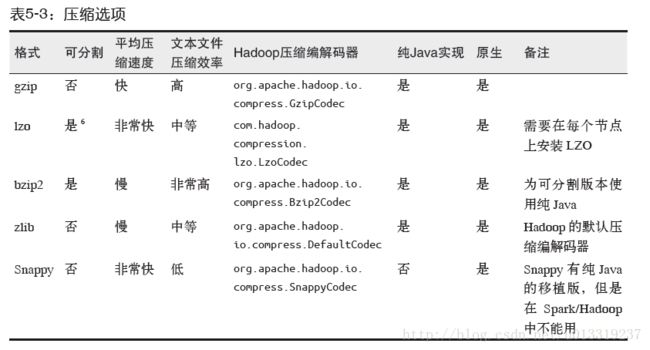
大数据工作中,我们经常需要对数据进行压缩以节省存储空间和网络传输开销。对于大多数Hadoop输出格式,我们可以制定一种压缩编码器来压缩数据。
这些压缩选项只是用与支持压缩的Hadoop格式,也就是那些写出到文件系统的格式。写入数据库的Hadoop格式一般没有实现压缩支持。
可以很容易从多个节点上并行读取的格式被称为“可分割”的格式。
5.3 文件系统
5.3.1 本地/“常规”文件系统
Spark支持从本地文件系统中读取文件,不过它要求文件在集群中所有节点的相同路径下可以找到。
一些像NFS、AFS以及MapR的NFS layer这样的网络文件系统会把文件以常规文件系统的形式暴露给用户。如果数据已经在这些系统中,则指定输入为一个file://路径;只要这个文件系统挂载在每个节点的同一个路径下,Spark就会自动处理,如例5-29。
例5-29:在Scala中从本地文件系统读取一个压缩的文本文件
val rdd=sc.textFile("file:///home/holden/happypandas.gz")如果文件还没有放在集群中的所有节点上,可以在驱动器程序中从本地读取改文件而无需使用整个集群,然后再调用parallellize将内容分发给工作节点。不过这种方式可能会比较慢。
5.3.2 Amazon S3
要在Spark中访问S3数据,
首先应该吧S3访问凭据设置为AWS_ACCESS_KEY_ID和AWS_SECRET_ACCESS_KEY环境变量。
然后,将以s3n://开头的路径以s3n://bucket/path-within-bucket的形式传给Spark的输入方法。
如果得到S3访问权限错误,请确保制定了访问秘钥的账号对数据通有“read”和“list”的权限。
5.3.3 HDFS
在Spark中使用HDFS只需要将输入输出路径指定为hdfs://master:port/path就够了。
5.4 Spark SQL中的结构化数据
在各种情况下,我们把一条SQL查询给Spark SQL,让它对一个数据源执行查,然后得到有Row对象组成的RDD,每个Row对象表示一条记录。在Java和Scala中,Row对象的访问是基于下标的。每个Row都有一个get()方法,会返回一个一般类型让我们可以进行类型转换。在Python中,可以使用row[column_number]以及row.column_name来访问元素。
5.4.1 Apache Hive
Spark可以读取Hive支持的任何表。
要把Spark SQL连接到已有的Hive上,你需要提供Hive的配置文件。你需要将hive-site.xml文件复制到Spark的./conf/目录下。这样做好之后,再创建出HiveContext对象,也就是Spark SQL的入口,就可以使用HQL进行查询。
例5-30:用Python创建HiveContext并查询数据
from pyspark.sql import HiveContext
hiveCtx=HiveContext(sc)
rows=hiveCtx.sql("SELECT name, age FROM users")
firstRow=rows.first()
print firstRow.name5.4.2 JSON
要读取JSON数据,首先需要和使用Hive一样创建一个HiveContext(这时不用安装好Hive)。然后使用HiveContext.jsonFile方法来从整个文件中获取由Row对象组成的RDD。
例5-34:在Python中使用SparkSQL读取JSON数据
tweets = hiveCtx.jsonFile("tweets.json")
tweets.registerTempTable("tweets")
results = hiveCtx.sql("SELECT user.name, text FROM tweets")5.5 数据库
通过数据库提供的Hadoop连接器或者自定义Spark连接器,Spark可以访问一些常用的数据库系统。
5.5.1 Java数据库连接
Spark可以从任何支持Java数据库连接(JDBC)的关系型数据库中读取数据,包括MySQL、Postgre等系统。要访问这些数据需要构建一个org.apache.spark.rdd.JdbcRDD,将SparkContext和其他参数一起传给他。
JdbcRDD接受参数:
- 一个用于对数据库创建连接的函数。这个函数让每个节点在连接必要的配置后创建自己读取数据的连接。
- 一个可读取一定范围内数据的查询,以及查询参数中的lowerBound和upperBound的值。
- 可以将输出结果从java.sql.ResultSet转为对操作数据有用的格式的函数。
和其他数据源一样,使用JdbcRDD时,需确保数据库可以应付Spark并行读取的负载。
5.5.2 Cassandra
随着DataStax 开源其用于Spark 的Cassandra 连接器(https://github.com/datastax/spark-cassandraconnector),Spark 对Cassandra 的支持大大提升。这个连接器目前还不是Spark 的一部分,因此你需要添加一些额外的依赖到你的构建文件中才能使用它。Cassandra 还没有使用Spark SQL,不过它会返回由CassandraRow 对象组成的RDD,这些对象有一部分方法与Spark SQL 的Row 对象的方法相同,如例5-38 和例5-39 所示。Spark 的Cassandra 连接器目前只能在Java 和Scala 中使用。
5.5.3 HBase
由于org.apache.hadoop.hbase.mapreduce.TableInputFormat 类的实现,Spark 可以通过Hadoop 输入格式访问HBase。这个输入格式会返回键值对数据,其中键的类型为org.apache.hadoop.hbase.io.ImmutableBytesWritable,而值的类型为org.apache.hadoop.hbase.client.Result。Result 类包含多种根据列获取值的方法,在其API 文档(https://hbase.apache.org/apidocs/org/apache/hadoop/hbase/client/Result.html)中有所描述。
5.5.4 Elasticsearch
Spark 可以使用Elasticsearch-adoop(https://github.com/elastic/elasticsearch-hadoop)从Elasticsearch中读写数据。Elasticsearch 是一个开源的、基于Lucene 的搜索系统。Elasticsearch 连接器和我们研究过的其他连接器不大一样,它会忽略我们提供的路径信息,而依赖于在SparkContext 中设置的配置项。Elasticsearch 的OutputFormat 连接器也没有用到Spark 所封装的类型,所以我们使用saveAsHadoopDataSet 来代替,这意味着我们需要手动设置更多属性。
5.6 总结
在本章结束之际,你应该已经能够将数据读取到Spark 中,并将计算结果以你所希望的方式存储起来。我们调查了数据可以使用的一些不同格式,一些压缩选项以及它们对应的数据处理的方式。现在我们已经掌握了读取和保存大规模数据集的方法,后续章节会介绍一些用来编写更高效更强大的Spark 程序的方法。