zookeeper与dubbo快速入门案例
文章目录
- zookeeper&dubbo
- 1. 概述
-
- 1.1. 什么是zookeeper
- 1.2. 本质及主要作用
-
- 1.2.1. 统一命名服务
- 1.2.2. 配置管理
- 1.2.3. 集群管理
- 2. 下载及安装
-
- 2.1. 安装
- 2.2. 配置文件解读
- 2.3. 启动zookeeper
- 2.4. 客户端连接
- 3. Znode数据模型
-
- 3.1. 数据结构图
- 3.2. 节点类型
- 3.3. 节点属性
- 4. 通知机制(watch)
-
- 4.1. watch机制特点
- 4.2. shell客户端演示
- 5. java客户端
- 6. dubbo入门
-
- 6.1. 架构
- 6.2. 注册中心
- 6.3. 监控中心
- 6.4. 服务提供者
- 6.5. 服务消费者
- 6.6. 创建通用的interface工程
- 7. zookeeper集群(扩展)
-
- 7.1. zookeeper集群结构
- 7.2. zookeeper集群的特性
- 7.3. Zookeeper的选主机制
-
- 7.3.1. 全新集群
- 7.3.2. 非全新集群
- 7.4. 集群搭建
-
- 7.4.1. 配置zoo.cfg
- 7.4.2. 复制zookeeper,并修改配置
- 7.4.3. 启动zookeeper集群
- zookeeper 启动报address already in use
zookeeper&dubbo
分布式数据一致性解决方案
1. 概述
1.1. 什么是zookeeper
Zookeeper是集群分布式中大管家
分布式集群系统比较复杂,子模块很多,但是子模块往往不是孤立存在的,它们彼此之间需要协作和交互,各个子系统就好比动物园里的动物,为了使各个子系统能正常为用户提供统一的服务,必须需要一种机制来进行协调——这就是ZooKeeper。
Zookeeper 是为分布式应用程序提供高性能协调服务的工具集合,也是Google的Chubby一个开源的实现,是Hadoop 的分布式协调服务。
1.2. 本质及主要作用
ZooKeeper 本质上是一个分布式的小文件存储系统(Znode)。提供基于类似于文件系统的目录树方式的数据存储,并且可以对树中的节点进行有效管理。从而用来维护和监控你存储的数据的状态变化。通过监控这些数据状态的变化,从而可以达到基于数据的集群管理。
主要作用:
- 统一命名服务(Name Service,zk会生成类似于文件系统的树状结构,可以生成不重复唯一名称,例如注册中心、分布式锁)
- 配置管理(Configuration Management如淘宝开源配置管理框架Diamond)
- 集群管理(不仅能够帮你维护当前的集群中机器的服务状态,而且能够帮你选出一个“总管”,让这个总管来管理集群)
1.2.1. 统一命名服务
分布式应用中,通常需要有一套完整的命名规则,既能够产生唯一的名称又便于人识别和记住,通常情况下用树形的名称结构是一个理想的选择,树形的名称结构是一个有层次的目录结构,既对人友好又不会重复。
在Dubbo实现中:
服务提供者在启动的时候,向ZK上的指定节点/dubbo/${serviceName}/providers目录下写入自己的URL地址,这个操作就完成了服务的发布。
服务消费者启动的时候,订阅/dubbo/${serviceName}/providers目录下的提供者URL地址, 并向/dubbo/${serviceName} /consumers目录下写入自己的URL地址。
1.2.2. 配置管理
在大型的分布式系统中,为了服务海量的请求,同一个应用常常需要多个实例。如果存在配置更新的需求,常常需要逐台更新,给运维增加了很大的负担同时带来一定的风险(配置会存在不一致的窗口期,或者个别节点忘记更新)。zookeeper可以用来做集中的配置管理,存储在zookeeper集群中的配置,如果发生变更会主动推送到连接配置中心的应用节点,实现一处更新处处更新的效果

现在把这些配置全部放到zookeeper上去,保存在 Zookeeper 的某个目录节点中,然后所有相关应用程序对这个目录节点进行监听,一旦配置信息发生变化,每个应用程序就会收到 Zookeeper 的通知,然后从 Zookeeper 获取新的配置信息应用到系统中就好。
1.2.3. 集群管理
Zookeeper 能够很容易的实现集群管理的功能,如有多台 Server 组成一个服务集群,那么必须要一个“总管”知道当前集群中每台机器的服务状态,一旦有机器不能提供服务,集群中其它集群必须知道,从而做出调整重新分配服务策略。同样当增加集群的服务能力时,就会增加一台或多台 Server,同样也必须让“总管”知道。
Zookeeper 不仅能够帮你维护当前的集群中机器的服务状态,而且能够帮你选出一个“总管”,让这个总管来管理集群,这就是 Zookeeper 的另一个功能 Leader Election。

2. 下载及安装
官网首页:https://zookeeper.apache.org/
下载地址:http://archive.apache.org/dist/zookeeper/

推荐使用课前资料中下载好的安装包《zookeeper-3.4.14.tar.gz》
2.1. 安装
需要先安装好Java环境
-
上传到/opt目录下并解压:
tar -zxvf zookeeper-3.4.14.tar.gz -
重命名为zookeeper:
mv zookeeper-3.4.14 zookeeper进入zookeeper目录,结构如下:

- zookeeper启动时会找conf/zoo.cfg配置文件,进入配置目录:
cd conf

有一个zookeeper的默认配置模板文件,需要复制并重命名为zoo.cfg:cp zoo_sample.cfg zoo.cfg
- 配置文件不需要做任何修改,即可启动。
2.2. 配置文件解读
tickTime:
通信心跳数,Zookeeper服务器心跳时间,单位毫秒。
用于集群状态下,服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime 时间就会发送一个心跳,时间单位为毫秒。
initLimit:
这个配置项是用来配置Zookeeper接收Follower客户端(这里所说的客户端不是用户链接Zookeeper服务器的客户端,而是Zookeeper服务器集群中连接到leader的Follower服务器,Follower在启动过程中,会从Leader同步所有最新数据,然后确定自己能够对外服务的起始状态。Leader允许Follower在 initLimit 时间内完成这个工作)初始化连接是最长能忍受多少个心跳的时间间隔数。
当已经超过10个心跳的时间(也就是tickTime)长度后Zookeeper服务器还没有收到客户端返回的信息,那么表明这个客户端连接失败。总的时间长度就是10*2000=20秒
syncLimit: LF同步通信时限
集群中Leader与Follower之间的最大响应时间单位。
在运行过程中,Leader负责与ZK集群中所有机器进行通信,例如通过一些心跳检测机制,来检测机器的存活状态, 假如响应超过syncLimit * tickTime(假设syncLimit=5 ,请求和应答时间长度,最长不能超过多少个tickTime的时间长度,总的时间长度就是5*2000=10秒。),Leader认为Follwer死掉,从服务器列表中删除Follwer。
在运行过程中,Leader负责与ZK集群中所有机器进行通信,例如通过一些心跳检测机制,来检测机器的存活状态。如果L发出心跳包在syncLimit之后,还没有从F那收到响应,那么就认为这个F已经不在线了。
dataDir:
数据文件目录+数据持久化路径
保存内存数据库快照信息的位置,如果没有其他说明,更新的事务日志也保存到数据库(可设置dataLogDir参数指定log日志目录)。
clientPort:
客户端连接端口(对外服务端口)
2.3. 启动zookeeper
切换到bin目录下
1) zookeeper命令:
启动zookeeper: ./zkServer.sh start
停止zookeeper: ./zkServer.sh stop
查看状态: ./zkServer.sh status
2) 如果出现错误:
先stop 掉原zk: ./zkServer.sh stop
然后以./zkServer.sh start-foreground方式启动,会看到启动日志
zkServer.sh start-foreground

2.4. 客户端连接
前提:必须要先启动服务端。
A:启动客户端工具:
zkCli.sh -server { ip }:port
本地连接直接:./zkCli.sh即可
这里的参数可以省略,如果省略,默认访问的是本机的zookeeper节点即:localhost:2181
B:使用 ls 命令来查看当前 ZooKeeper 中所包含的内容: ls / (显示根节点下的子节点)
C:查看当前节点数据并能看到更新次数等数据: ls2 /
D:创建节点,并设置初始内容: create /zk "test" 创建一个新的 znode节点“ zk ”以及与它关联的字符串
E:获取节点内容及状态:get /zk
F:查看节点状态:stat /zk
G:修改节点内容:set /zk "test22"
H:删除无子的节点: delete /zk 将刚才创建的 znode 删除
I:递归删除:rmr /zk 如果/zk节点有子子孙孙节点,使用这种方式删除
J:退出客户端: quit
K:帮助命令: help
一句话:和redis的KV键值对类似,只不过key变成了一个路径节点值,v就是data
3. Znode数据模型
Zookeeper维护一个类似文件系统的数据结构。
ZooKeeper数据模型的结构与Unix文件系统很类似,整体上可以看作是一棵树,每个节点称做一个ZNode。每一个znode默认能够存储1MB的数据,每个ZNode都可以通过其路径唯一标识
3.1. 数据结构图
如同 Unix 中的文件路径。路径必须是绝对的,因此他们必须由斜杠字符来开头。除此以外,他们必须是唯一的。

图中的每个节点称为一个 Znode。 每个 Znode 由 3 部分组成:
-
stat:此为状态信息, 描述该 Znode 的版本, 权限等信息
-
data:与该 Znode 关联的数据
-
children:该 Znode 下的子节点
3.2. 节点类型
Znode 有两种,分别为临时节点和永久(持久)节点。
节点的类型在创建时即被确定,并且不能改变。
临时节点:该节点的生命周期依赖于创建它们的会话。一旦会话结束,临时节点将被自动删除,当然可以也可以手动删除。临时节点不允许拥有子节点。
永久节点:又称持久化节点,该节点的生命周期不依赖于会话,并且只有在客户端显式执行删除操作的时候,他们才能被删除。
Znode还有一个序列化的特性,如果创建的时候指定的话,该 Znode 的名字后面会自动追加一个不断增加的序列号。序列号对于此节点的父节点来说是唯一的,这样便会记录每个子节点创建的先后顺序。它的格式为“%10d”(10 位数字,没有数值的数位用 0 补充,例如“0000000001”)。
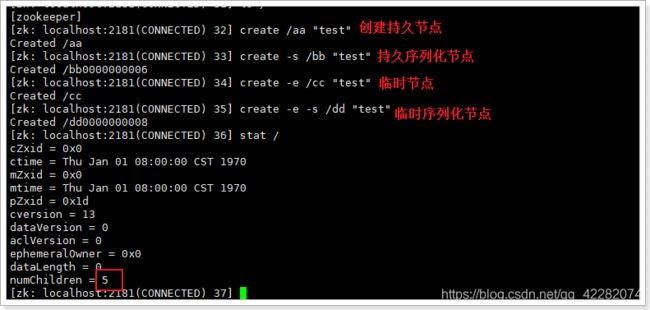
这样便会存在四种类型的 Znode 节点,分别对应:
-
PERSISTENT:永久节点。客户端与zookeeper断开连接后,该节点依旧存在
-
EPHEMERAL:临时节点。客户端与zookeeper断开连接后,该节点被删除
-
PERSISTENT_SEQUENTIAL:永久节点、序列化。客户端与zookeeper断开连接后,该节点依旧存在,只是Zookeeper给该节点名称进行顺序编号
-
EPHEMERAL_SEQUENTIAL:临时节点、序列化。客户端与zookeeper断开连接后,该节点被删除,只是Zookeeper给该节点名称进行顺序编号
创建这四种节点:
3.3. 节点属性
Znode维护了一个stat结构,这个stat包含数据变化的版本号、访问控制列表变化、还有时间戳。版本号和时间戳一起,可让Zookeeper验证缓存和协调更新。每次znode的数据发生了变化,版本号就增加。
例如,无论何时客户端检索数据,它也一起检索数据的版本号。并且当客户端执行更新或删除时,客户端必须提供他正在改变的znode的版本号。如果它提供的版本号和真实的数据版本号不一致,更新将会失败。
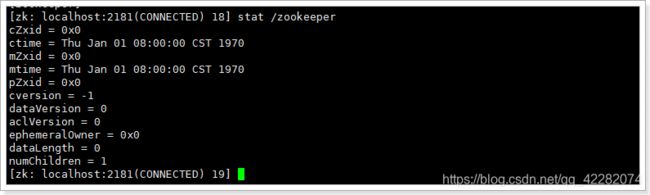
| 参数名 | 说明 |
|---|---|
| cZxid | 创建节点的事务zxid(ZooKeeper Transaction Id) |
| ctime | znode创建时间(毫秒数) |
| mZxid | znode最后更新的事务zxid |
| mtime | znode最后修改时间(毫秒数) |
| pZxid | znode最后更新的子节点zxid |
| cversion | znode子节点版本号。znode的子节点有变化时,cversion 的值就会增加1 |
| dataVersion | znode数据变化号 |
| aclVersion | znode访问控制列表的变化号(Access Control List,访问控制) |
| ephemeralOwner | 如果是临时节点,这个是znode拥有者的session id。如果不是临时节点则是0。 |
| dataLength | znode的数据长度 |
| numChildren | znode子节点数量 |
4. 通知机制(watch)
Watch 说的是 Zookeeper 的监听机制。一个 Watch 事件是一个一次性的触发器,当被设置了 Watch 的数据发生了改变的时候,则服务器将这个改变发送给设置了 Watch 的客户端,以便通知它们。
4.1. watch机制特点
特点:
-
一次性触发
数据发生改变时,一个 watcher event 会被发送到 client,但是 client 只会收到一次这样的信息。
-
Watcher event 异步发送
watcher 的通知事件从 server 发送到 client 是异步的。
-
数据监视
Zookeeper 有数据监视和子数据监视
具体玩法:
-
注册 watcher
get、stat、ls/ls2
-
触发 watcher
create、delete、set、子节点变更、链接状态变化
4.2. shell客户端演示

5. java客户端
- 引入依赖
<dependency>
<groupId>org.apache.zookeepergroupId>
<artifactId>zookeeperartifactId>
<version>3.4.14version>
dependency>
- 常用api及其方法
// 初始化zookeeper客户端类,负责建立与zkServer的会话
new ZooKeeper(connectString, 30000, new Watcher() {
@Override
public void process(WatchedEvent event) {
System.out.println("获取链接成功!!");
}
});
// 创建一个节点,1-节点路径 2-节点内容 3-访问控制控制 4-节点类型
String fullPath = zooKeeper.create(path, null, ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
// 判断一个节点是否存在
Stat stat = zooKeeper.exists(rootPath, false);
if(stat != null){...}
// 查询一个节点的内容
Stat stat = new Stat();
byte[] data = zooKeeper.getData(path, false, stat);
// 更新一个节点
zooKeeper.setData(rootPath, new byte[]{}, stat.getVersion() + 1);
// 删除一个节点
zooKeeper.delete(path, stat.getVersion());
// 查询一个节点的子节点列表
List<String> children = zooKeeper.getChildren(rootPath, false);
// 关闭链接
if (zooKeeper != null){ zooKeeper.close(); }
6. dubbo入门
官方地址:http://dubbo.io/
6.1. 架构
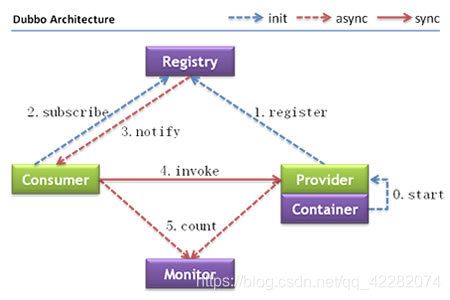
节点角色说明:
| 节点 | 角色说明 |
|---|---|
Provider |
暴露服务的服务提供方 |
Consumer |
调用远程服务的服务消费方 |
Registry |
服务注册与发现的注册中心 |
Monitor |
统计服务的调用次数和调用时间的监控中心 |
Container |
服务运行容器 |
调用关系说明:
- 服务容器负责启动,加载,运行服务提供者。
- 服务提供者在启动时,向注册中心注册自己提供的服务。
- 服务消费者在启动时,向注册中心订阅自己所需的服务。
- 注册中心返回服务提供者地址列表给消费者,如果有变更,注册中心将基于长连接推送变更数据给消费者。
- 服务消费者,从提供者地址列表中,基于软负载均衡算法,选一台提供者进行调用,如果调用失败,再选另一台调用。
- 服务消费者和提供者,在内存中累计调用次数和调用时间,定时每分钟发送一次统计数据到监控中心。
6.2. 注册中心
dubbo官方推荐使用的注册中心是zookeeper
zookeeper的安装过程这里略。。。。。。
6.3. 监控中心
启动监控中心:先解压课前资料中的dubbo-admin-0.1.zip
这是一个前后端分离工程,项目结构如下:

切换到dubbo-admin-ui工程下,执行如下命令启动:
npm install
npm start
切换到dubbo-admin-server工程中,打包并启动:
# 打包
mvn clean package -Dmaven.skip.test=true
# 切换到target目录下,执行jar包
java -jar dubbo-admin-server-0.1.jar
访问:http://localhost:8081
6.4. 服务提供者
步骤:
-
创建服务提供者springboot工程,不需要选择任何启动器
<dependency> <groupId>org.apache.dubbogroupId> <artifactId>dubbo-spring-boot-starterartifactId> <version>2.7.5version> dependency> <dependency> <groupId>org.apache.dubbogroupId> <artifactId>dubbo-dependencies-zookeeperartifactId> <version>2.7.5version> <exclusions> <exclusion> <groupId>org.apache.zookeepergroupId> <artifactId>zookeeperartifactId> exclusion> exclusions> dependency> <dependency> <groupId>org.apache.zookeepergroupId> <artifactId>zookeeperartifactId> <version>3.4.8version> dependency> -
application.properties
dubbo.application.name=服务名 dubbo.registry.address=zk的ip地址:2181 dubbo.registry.protocol=zookeeper dubbo.protocol.name=dubbo dubbo.protocol.port=20880 dubbo.monitor.protocol=registry -
添加注解:
在启动类上添加@EnableDubbo注解,开启dubbo的注解开发功能
对外暴露的UserServiceImpl上,添加dubbo的@Service注解
具体实现:

pom.xml:
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starterartifactId>
dependency>
<dependency>
<groupId>org.apache.dubbogroupId>
<artifactId>dubbo-spring-boot-starterartifactId>
<version>2.7.5version>
dependency>
<dependency>
<groupId>org.apache.dubbogroupId>
<artifactId>dubbo-dependencies-zookeeperartifactId>
<version>2.7.5version>
dependency>
<dependency>
<groupId>org.apache.zookeepergroupId>
<artifactId>zookeeperartifactId>
<version>3.4.8version>
dependency>
application.properties:
dubbo.application.name=provider
dubbo.registry.address=127.0.0.1:2181
dubbo.registry.protocol=zookeeper
dubbo.protocol.name=dubbo
dubbo.protocol.port=20880
dubbo.monitor.protocol=registry
启动类:
@SpringBootApplication
@EnableDubbo
public class DubboProviderApplication {
public static void main(String[] args) {
SpringApplication.run(DubboProviderApplication.class, args);
}
}
UserServiceImpl实现类:
@Service // 使用dubbo的service注解
public class UserServiceImpl implements UserService {
@Override
public User queryUserById() {
return new User(1l, "liuyan", 20);
}
}
6.5. 服务消费者
步骤:
-
创建消费者,需要选择web启动器
并引入dubbo依赖,同提供者
-
application.properties
dubbo.application.name=服务名 dubbo.registry.address=zookeeper://ip:2181 dubbo.monitor.protocol=registry -
注解
在启动类上添加@EnableDubbo注解,开启dubbo的注解开发功能
在HelloController中通过@Reference注解注入需要的service
具体实现:

pom.xml:
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
<dependency>
<groupId>org.apache.dubbogroupId>
<artifactId>dubbo-spring-boot-starterartifactId>
<version>2.7.5version>
dependency>
<dependency>
<groupId>org.apache.dubbogroupId>
<artifactId>dubbo-dependencies-zookeeperartifactId>
<version>2.7.5version>
dependency>
<dependency>
<groupId>org.apache.zookeepergroupId>
<artifactId>zookeeperartifactId>
<version>3.4.8version>
dependency>
application.properties:
server.port=10000
dubbo.application.name=consumer
dubbo.registry.address=zookeeper://127.0.0.1:2181
dubbo.monitor.protocol=registry
DubboConsumerApplication启动类:
@SpringBootApplication
@EnableDubbo
public class DubboConsumerApplication {
public static void main(String[] args) {
SpringApplication.run(DubboConsumerApplication.class, args);
}
}
HelloController:
@RestController
public class HelloController {
@Reference
private UserService userService;
@GetMapping("test")
public User getUser(){
User user = this.userService.queryUserById();
return user;
}
}
6.6. 创建通用的interface工程
pojo(一定要实现序列化接口)及service接口放在该工程

User对象:
@Data
@AllArgsConstructor
@NoArgsConstructor
public class User implements Serializable {
private Long id;
private String name;
private Integer age;
}
UserService接口:
public interface UserService {
public User queryUserById();
}
7. zookeeper集群(扩展)
7.1. zookeeper集群结构
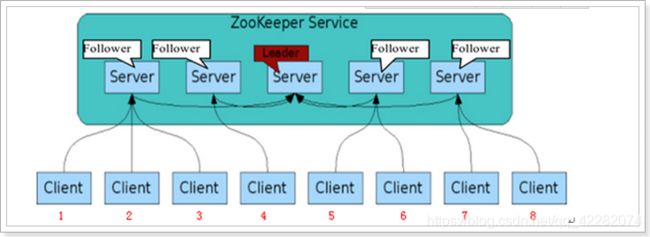
在ZooKeeper集群当中,集群中的服务器角色有两种:1个Leader和多个Follower,具体功能如下:
-
领导者(leader)
监控集群中的节点是否存活(心跳机制)
事务请求(写操作)的唯一调度和处理者,保证集群事务处理的顺序性;集群内部各个服务器的调度者。对于 create,setData,delete 等有写操作的请求,则需要统一转发给leader 处理,leader 需要决定编号、执行操作,这个过程称为一个事务。
-
follower
处理客户端非事务(读操作)请求,转发事物请求给 Leader;
参与集群 Leader 选举投票。
7.2. zookeeper集群的特性
- 全局数据一致:每个 server 保存一份相同的数据副本,client 无论连接到哪个 server,展示的数据都是一致的,这是最重要的特征;
- 可靠性:如果消息被其中一台服务器接受,那么将被所有的服务器接受。
- 顺序性:包括全局有序和偏序两种:全局有序是指如果在一台服务器上消息 a 在消息 b 前发布,则在所有 Server 上消息 a 都将在消息 b 前被发布;偏序是指如果一个消息 b 在消息 a 后被同一个发送者发布,a 必
将排在 b 前面。 - 数据更新原子性:一次数据更新要么成功(半数以上节点成功),要么失败,不存在中间状态;
- 实时性:Zookeeper 保证客户端将在一个时间间隔范围内获得服务器的更新信息,或者服务器失效的信息。
7.3. Zookeeper的选主机制
7.3.1. 全新集群
以一个简单的例子来说明整个选举的过程.
假设有五台服务器组成的zookeeper集群,它们的id从1-5,同时它们都是最新启动的,也就是没有历史数据,在存放数据量这一点上,都是一样的.假设这些服务器依序启动,来看看会发生什么.
- 服务器1启动,此时只有它一台服务器启动了,它发出去的报没有任何响应,所以它的选举状态一直是LOOKING状态
- 服务器2启动,它与最开始启动的服务器1进行通信,互相交换自己的选举结果,由于两者都没有历史数据,所以id值较大的服务器2胜出,但是由于没有达到超过半数以上的服务器都同意选举它(这个例子中的半数以上是3),所以服务器1,2还是继续保持LOOKING状态.
- 服务器3启动,根据前面的理论分析,服务器3成为服务器1,2,3中的老大,而与上面不同的是,此时有三台服务器选举了它,所以它成为了这次选举的leader.
- 服务器4启动,根据前面的分析,理论上服务器4应该是服务器1,2,3,4中最大的,但是由于前面已经有半数以上的服务器选举了服务器3,所以它只能接收当小弟的命了.
- 服务器5启动,同4一样,当小弟.
7.3.2. 非全新集群
那么,初始化的时候,是按照上述的说明进行选举的,但是当zookeeper运行了一段时间之后,有机器down掉,重新选举时,选举过程就相对复杂了。
需要加入数据id、leader id和逻辑时钟。
数据id:数据新的id就大,数据每次更新都会更新id。
Leader id:就是我们配置的myid中的值,每个机器一个。
逻辑时钟:这个值从0开始递增,每次选举对应一个值,也就是说: 如果在同一次选举中,那么这个值应该是一致的 ; 逻辑时钟值越大,说明这一次选举leader的进程最新.
选举的标准就变成:
1、统一逻辑时钟后,数据id大的胜出
2、数据id相同的情况下,leader id大的胜出
3、逻辑时钟小的选举结果被忽略
根据这个规则选出leader。
7.4. 集群搭建
在条件允许的情况下,zookeeper集群应该搭建在不同的服务器上,例如:
192.168.56.101、192.168.56.102、192.168.56.103
server.1=192.168.56.101:2888:3888
server.2=192.168.56.102:2888:3888
server.3=192.168.56.103:2888:3888
这里咱们在同一台服务器上,搭建zookeeper集群,通过端口号区分每个zookeeper服务。
之前搭建redis集群只需有多个redis.conf配置即可,因为redis启动时,可以指定配置文件
而zookeeper服务启动时,不能指定配置文件启动,它会默认找zookeeper根目录下的conf/zoo.cfg配置。也就是说一个zookeeper服务,必须在一个完整的zookeeper目录下,否则无法运行。所以,在虚拟机中需要3个zookeeper完整目录,分别修改器配置文件指定不同的端口信息。
7.4.1. 配置zoo.cfg
为了简化配置,可以先配置好一个zookeeper,然后再复制2个。
-
进入/opt/zookeeper/conf目录,编辑配置文件:vi zoo.cfg
修改或者添加以下这段儿配置:
dataDir=/opt/zookeeper/data dataLogDir=/opt/zookeeper/log clientPort=2181 server.1=172.16.116.100:2001:3001 server.2=172.16.116.100:2002:3002 server.3=172.16.116.100:2003:3003dataDir:数据目录
dataLogDir:日志目录
clientPort:对外提供服务的端口号
server后的数字是服务器id
x.x.x.x是服务器的ip地址
port1是心跳端口
port2是数据端口

-
创建数据目录和日志目录
我们在配置文件里指定了数据和日志目录。所以我们需要创建这些目录
先进入zookeeper目录,创建目录:
mkdir data
mkdir log

-
添加服务器ID信息
进入刚刚创建的data目录,创建文件
myid,并且写上ID信息:1

7.4.2. 复制zookeeper,并修改配置
复制zookeeper为zookeeper2,zookeeper3:
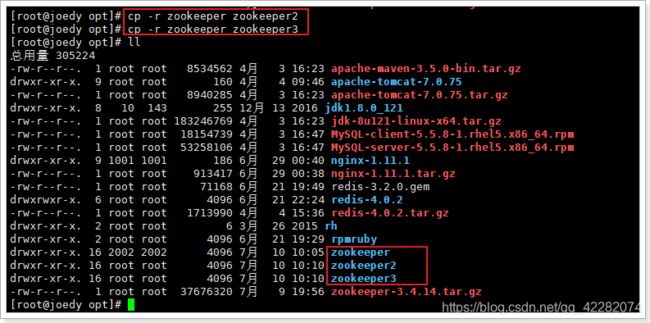
-
进入zookeeper2,修改以下配置:
conf/zoo.cfg配置
dataDir=/opt/zookeeper2/data dataLogDir=/opt/zookeeper2/log clientPort=2182data/myid配置成2
-
进入zookeeper3,修改以下配置
conf/zoo.cfg配置
dataDir=/opt/zookeeper3/data dataLogDir=/opt/zookeeper3/log clientPort=2183data/myid配置成3
7.4.3. 启动zookeeper集群
启动方式跟单台zookeeper启动方式一样,进入每个zookeeper的bin目录./zkServer.sh start
启动完成之后通过./zkServer.sh status,查看服务状态。
通过./zkCli.sh -server localhost:port连上每台zookeeper服务

zookeeper 启动报address already in use
zookeeper启动报错信息如下:
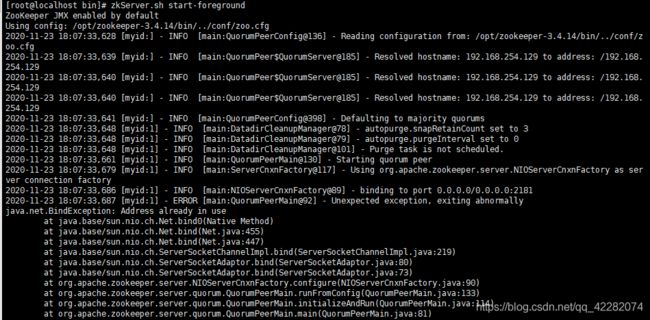
原因:zookeeper指定端口被占用的问题。用netstat查看下端口占用的情况
解决方法:
1、查看端口号被谁占用了:sudo netstat -atunlp | grep 2181
如果报错: -bash: netstat: command not found
安装命令:yum install net-tools
2、发现是java这个程序占用了端口,而89590就是进程的PID:
![]()
3、杀进程:
sudo kill -9 89590