Docker容器技术原理速览
这一篇博客不讲实战,而是用人话简要地介绍一下docker的实现原理和例子。
所以会一点docker的操作基础的话能看得更舒服。
Intro
Docker基于Go语言开发,使用Linux的cgroup, namespace和OverlayFS的UnionFS技术进行开发。
cgroup是linux中限制进程可用资源的技术。
namespace是限制进程“可视范围”的技术(在一个特定的namespace下,不属于此namespace的文件是不可见的)。
Docker对进程进行封装隔离,是OS层面的虚拟化技术。
Docker在0.7版本之前用的LinuxContainer实现,此后使用他们自己开发的libcontainer,从1.11开始用RunC和containerd
这里的runc和containerd等等等等都是用来管理容器的东西,包括创建销毁、镜像管理etc

传统虚拟机虚拟出一套硬件,而容器直接运行在宿主的内核上。
Docker镜像
Docker镜像,是一个特殊的文件系统。它提供了容器运行时需要的程序、资源、库、配置,也会提供一些配置参数(卷、环境变量、用户etc)。镜像不含动态数据,在构建后内容不会改变。
在构建后内容不会改变:一个直观的印象便是镜像构建的每一层都打了hash码
例如,一个ubuntu镜像是包含了完整Ubuntu最小系统的root文件系统。
分层存储:
镜像包含完整的root文件系统,而完整的root是很大的。因此,在docker设计的时候,利用了UnionFS的技术,将镜像做成分层存储的架构。使用UnionFS的目的有二:
- 将多个地方的文件挂到同一个目录下
- 将一个只读的分支和一个可写的分支联合在一起。比如依赖只读,应用程序日志可读写。
UnionFS,可以把多个目录的内容联合挂载到同一个目录下,而这些目录的物理位置是分开的。最经典的例子是安装linux系统时不同的硬盘中的文件挂在同一个目录下。UnionFS允许只读和可读写目录并存。
在容器启动时,所有的依赖会被打包在一个根目录里(根文件系统rootfs)。
在镜像构建时,会一层层构建,逐渐往rootfs里增删改,前层是后层的基础。每一层构建完就不再改变。后一层的所有改变都只发生在自己的这一层。
比如我在某一层删一个文件,这个操作只是在当前层标记这个文件已删除。容器运行时,虽然看不到这个文件,但是这个文件会一直跟随镜像。
这样,应用A和应用B所在的容器共同引用相同的操作系统层、语言环境层(作为只读层),而各自有各自应用程序层,和可写层。启动容器的时候通过UnionFS把相关的层挂载到一个目录,作为容器的根文件系统。
rootfs只是一个程序运行时包含的文件、配置和目录,不含有OS内核。所以牢记一点,如果容器要配置内核,那么这样的配置将在全局生效。
Docker容器
容器本质是进程。但是容器运行在它自己独立的namespace中。因此容器拥有独立的root文件系统、网络配置、进程空间、用户ID空间。
缸 中 之 脑
容器也是分层存储。容器运行时以镜像为基础层,在其上创建一个当前容器的存储层,用于容器运行时的读写。
容器消亡时,容器存储层也会死掉。因此保存在容器存储层的数据会丢失。
因此,容器不应该向其存储层内写入任何数据,要保持无状态化。所有的文件写入操作,都应该使用数据卷或者绑定宿主目录,在这些位置的读写会跳过容器存储层,直接对宿主(或网络存储)发生读写,其性能和稳定性更高。
数据卷的生存周期独立于容器,容器消亡,数据卷不会消亡。
Docker存储
在docker容器里管理数据主要有两种方式:
- 数据卷(volumes)
- 挂载主机目录(Bind mounts)
- 其实上面两种方法,本质上是一样的。
数据卷/本机目录挂载简介
docker的镜像是由多个只读的文件系统叠加在一起形成的。当我们在启动一个容器的时候,docker会加载这些只读层并在这些只读层的上面(栈顶)增加一个读写层。这时如果修改正在运行的容器中已有的文件,那么这个文件将会从只读层复制到读写层。该文件的只读版本还在,只是被上面读写层的该文件的副本隐藏。删除容器后更改便会消失。
想保存其实也可以,比如docker commit命令可以把改动做成镜像。但是docker commit这个命令只能够保存提交结果,从这个结果反推咱们做的事情是很难的。
为了更好实现数据保存和数据共享,Docker提出了Volume这个概念,简单的说就是绕过默认的UnionFS(因为咱们做的更改在容器死掉之后就消失了),而以正常的文件或者目录的形式存在于宿主机上。又被称作数据卷。
数据卷是被设计用来做持久化存储的。数据卷的生命周期和容器无关,即容器死了也不会影响数据卷里的数据,也不存在啥垃圾回收机制来处理无主的数据卷(因为数据卷本质上是宿主机上的文件和目录)。数据卷可以提供下面的特性:
- 在容器之间共享和复用
- 对数据卷的修改会立即生效
- 对数据卷的更新,不会影响镜像
和UnionFS相比较,在UnionFS上做的改动只会保存在容器运行时那个存储层上,但是数据卷中的改动是直接对挂载的磁盘进行操作。
对数据卷比较容易想到的一个类比便是有多个USB接口的U盘,可以分别插在不同的机器上并且被读写(文件读写同步问题先按下不表,感觉docker必然会在里面提供相应的机制)。
和镜像中的目录类似,在容器里,数据卷对应的是rootfs中的某个目录。只不过,对数据卷改动会直接对应本机文件的改动,而对一般的来自于镜像的目录进行改动,只会让容器把改动结果写在临时存储层上。
数据卷/本机目录挂载的实现原理
实际上,跑一个容器看看就知道数据卷和挂载主机目录没有本质区别。
数据卷和主机目录的挂载都是由Docker的容器运行时维护的。在新建数据卷时,可以指定数据卷挂载的目录(比如 /home/[usrname]/blablabla )。如果不指定的话,Docker会把这个数据卷依照数据卷名称 vname 保存到 /var/lib/docker/volumes/[vname] 下。
就是说数据卷总是保存在本地,但是是保存在docker相对私有且用户不好找的一个目录下,还是一个用户方便查看的目录下,这个就可以自己指定了。
Docker网络初步
Docker 允许通过外部访问容器或容器互联的方式来提供网络服务。
Kubernetes有更强大的支持。
容器和外部进行交互的窗口
容器中跑一些网络应用。如果想让外部访问这些应用,可以指定端口映射,建立宿主机端口和容器端口之间的联系。
容器之间进行交互的方法
Docker可以为容器之间搭建内部网络。可选项有bridge和overlay等。overlay在docker swarm中有相关应用。此处按下不表。
更多的Docker网络原理可见博客《Docker网络技术原理速览》。
Docker高级网络配置
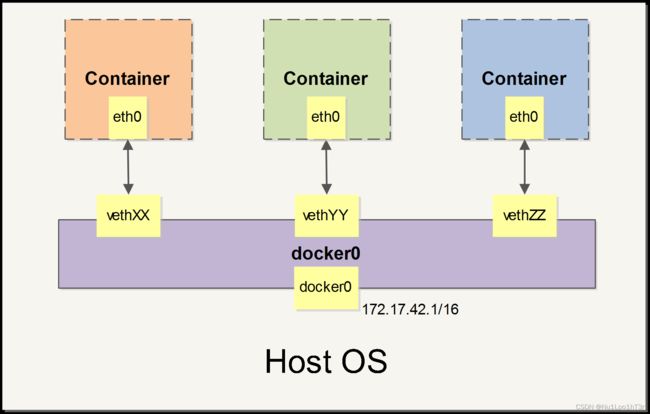
在Docker启动时,它会在主机上新建一个 docker0 虚拟网络。这个虚拟网络实际上是一个linux虚拟网桥。可以理解为一个用软件实现的交换机。这个 docker0 会用于“插”在它上面的虚拟网卡之间进行数据包之间的转发。
Linux Bridge(网桥)是用纯软件实现的虚拟交换机,有着和物理交换机相同的功能,运行在TCP/IP五层模型的数据链路层上,例如二层交换,MAC地址学习等。
因此我们可以把tun/tap,veth pair等设备绑定到网桥上,就像是把设备连接到物理交换机上一样。此外它和veth pair、tun/tap一样,也是一种虚拟网络设备,具有虚拟设备的所有特性,例如配置IP,MAC地址等。
Linux Bridge通常是搭配KVM、docker等虚拟化技术一起使用的,用于构建虚拟网络。
建立虚拟网络之后,Docker会随机分配一个本地未用的私有网段(比如172.17.0.0)给docker0接口。此后,容器内的网口也会分配同一个网段的地址。
在查了网上一些东西之后我才意识到一些以前没注意到的问题。
比如私有网段,有ABC三类。
A类是10.0.0.0网段(就这一个网段),IP地址范围 10.0.0.0~10.255.255.255
B类是172.16.0.0 - 172.31.0.0(16个网段),IP地址范围 172.16.0.0~172.31.255.255
C类是192.168.0.0~192.168.255.0(256个网段),IP地址范围 192.168.0.0 - 192.168.255.255
此后,每当一个容器建立起来,就会相应地建立一对veth pair。这时候,接口的一端在容器里,称为eth0,另一端在网桥上,名称以veth开头。通过这种方式,主机可以跟容器通信,容器之间也可以相互通信。
这里的veth pair就相当于一根网线的两头,一头插在电脑上,另一头插在路由器上。
容器的访问控制
主要通过 Linux 上的 iptables 防火墙来进行管理和实现。iptables 是 Linux 上默认的防火墙软件,在大部分发行版中都自带。
容器访问外网
这件事需要本地系统的转发支持。可以通过
$ sysctl net.ipv4.ip_forward
命令检查是否支持本地转发。
容器之间的访问
如果要想实现任意两个容器之间的访问,需要有下面两个事的支持:
- 容器的网络拓扑是否互联。默认情况下,所有的容器都会被连接到docker0网桥上。
- 本地系统的 iptables 是否允许通过。
Docker安全性
在评估Docker的安全性时,主要有下面三个方面需要考虑。
- 由内核的命名空间和控制组机制提供的容器内在安全
- 程序本身的鲁棒性
- 内核安全性的加强机制对容器安全性的影响
内核命名空间namespace
在docker run启动容器之后,内核就会创建独有的namespace和cgroup。
命名空间提供了最基础也是最直接的隔离,在容器中运行的进程不会被运行在主机上的进程和其它容器发现和作用。
每个容器都有自己独立的网络栈。即,它们不能访问这台物理机上其他的socket或者网卡。
但是,经过合理的设置,容器可以像跟主机交互一样的和其他容器交互。
控制组
控制组是 Linux 容器机制的另外一个关键组件,负责实现资源的审计和限制。
它可以确保各个容器可以公平地分享主机的内存、CPU、磁盘 IO 等资源;
更重要的是,控制组确保了当容器内的资源使用产生压力时不会连累主机系统。
尽管控制组不负责隔离容器之间相互访问、处理数据和进程,它在防止拒绝服务(DDOS)攻击方面仍然是必不可少的。
Docker服务端的防护
一句话让运维破防:
宿主机的根目录
/被映射到某个容器的/host下了
因此,我们确保只有可信的用户才可以访问 Docker 服务。Docker 允许用户在主机和容器间共享文件夹,同时不需要限制容器的访问权限,这就容易让容器突破资源限制。如果上面那个事成真了,那么容器理论上就可以对主机的文件系统进行任意修改了。
事实上几乎所有虚拟化系统都允许类似的资源共享,而没法禁止用户共享主机根文件系统到虚拟机系统。
最近改进的 Linux 命名空间机制将可以实现使用非 root 用户来运行全功能的容器。这将从根本上解决了容器和主机之间共享文件系统而引起的安全问题。
内核能力机制
是linux内核实现的一个强大特性,可以提供细粒度的权限访问控制。这种细粒度的访问控制可以作用在进程上,也可以作用在文件上。
例如,一个 Web 服务进程只需要绑定一个低于 1024 的端口的权限,并不需要 root 权限。那么它只需要被授权
net_bind_service能力即可。
再比如,在服务器上会运行一堆需要特权权限的进程,包括有 ssh、cron、syslogd、硬件管理工具模块(例如负载模块)、网络配置工具等等。但是容器都不会用到它们。几乎所有的特权进程都由容器以外的支持系统来进行管理,而容器都用不着。
因此,为了加强安全,容器可以禁用一些没必要的权限。
这样,就算攻击者在容器中取得了 root 权限,也不能获得本地主机的较高权限,能进行的破坏也有限。