python&numpy&torch数据操作
目录
python基础数据类型
numpy多维数组
torch中的Tensor
torch中tensor操作
算术操作,以加法为例
索引操作
改变形状
运算内存开销
Tensor与numpy互相转换
tensor 转 numpy
numpy转tensor
tensor可以放到GPU上
由于在机器学习领域,python中的基础数据类型一般要转换成numpy中的多维数组或者torch的tensor来计算,本来简要描述其中的一些要点。https://tangshusen.me/Dive-into-DL-PyTorch/#/chapter02_prerequisite/2.2_tensor
python基础数据类型
严格来讲,python中是没有数组这个数据结构的,数组一般要求其中的元素类型形同。python中用来实现数组功能有两种基本数据类型,即列表list和元素tuple,其区别是前者是可变的,后者是不可变的。
python中赋值运算符与C++中有所不同,python中的赋值本质上是产生一个原对象的引用。
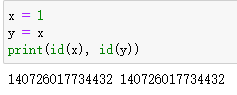
id()可用于获取对象的内存地址,可以看到x和y的内存地址是相同的,即y得本质是x的一个引用。再看下边这个例子,如果y是x的引用,如果改变了y,那么x应该跟着变,但是这里y改变了 以后x并没有跟着变,并且x与y彻底分道扬镳,内存地址也不同了,变成了两个不同的对象。出现这种现象的原因是python六大基础类型中有可变对象与不可变对象之分,其中列表,集合,字典是可变类型,数字,字符串,元素是不可变类型,这里我们将一个不可变类型y改变数值时,会另外分配一块内存。

如下图所示,改变一个不可变对象,会重新分配内存空间。

再如先下边这个例子,尽管x是可变对象,不过y是x的一个元素的引用,所以y仍是数字类型的引用,因此改变y依然不影响x。

但是当我们让y直接引用一个列表对象x时候,因为list是可变的,因此y的改变就会影响到x。

一个比较有趣的点是python的数字类型Numbers只有int float bool complex这四种,而没有区分int和float的精度问题,据说可以认为是任意精度的。
numpy多维数组
numpy是python最常用的一个扩展库,主要用于矩阵运算,其最重要的一个数据结构是ndarray类型,即多维数组,要直接由python列表(或元组)创建一个多维数组只需要调用np.array()函数就行。如下两个例子,由例子2也可以看出,从列表转换成numpy数组之后元素并没有共享空间。


此外还有一些生成指定形状多维数组的api:

其中np.empty()是创建指定形状数组的最快的方法,因为其不对数组内的元素进行初始化,即其中元素都是 随机值。
numpy中的数据类型比python内置类型多很多,也有数据精度的区分。具体可见https://www.runoob.com/numpy/numpy-dtype.html
此外numpy库中一个常用的库是numpy.random
https://blog.csdn.net/weixin_42029738/article/details/81977492
此外python标准库中也有random模块,与numpy中的random模块有一点区别。一般生成随机数,打乱一维数组等,可以用标准库中的random模块,而与随机数组相关的用numpy.random即可。
https://blog.csdn.net/weixin_45798949/article/details/106523172?utm_medium=distribute.pc_relevant.none-task-blog-2~default~baidujs_title~default-0.essearch_pc_relevant&spm=1001.2101.3001.4242
名叫random的模块有三个,python标准库中一个,numpy中一个,torch中也有一个。
torch中的Tensor
torch.Tensor是最重要的数据类型,更准确地说,Tensor是torch中默认张量对象FloatTensor的别名。
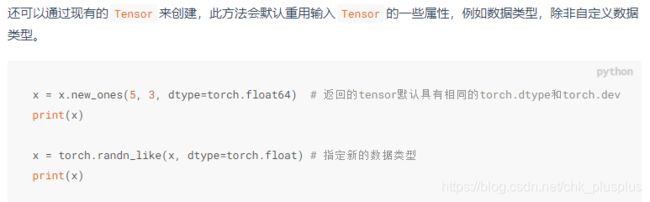
需要注意的是torch.Tensor()和torch.tensor()都可以用于生成张量对象,torch.tensor()则是一个函数,可以将python的内置数据类型list,tuple等,或者numpy数组转换成张量对象,且张量对象中数据类型由原对象数据类型决定,并不一定是单精度浮点数,另一个比较重要的特点是torch.tensor()生成张量是拷贝了原对象的数据,也就是说并不会跟原对象中的数据共享内存。
https://blog.csdn.net/weixin_42018112/article/details/91383574
张量相当于是numpy中的多维数组,只是其比多维数据还多了梯度等信息。
与numpy中接口类型,torch.empty()也可以生成未初始化的张量。
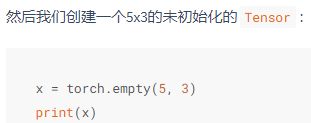


可以用 x.size()方法或者x.shape成员来获取Tensor的形状(返回值的本质就是一个表示形状的元组)。
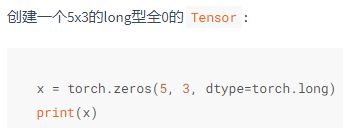
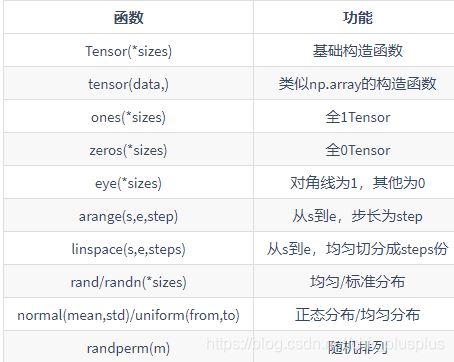
常用创建Tensor对象的api如下,跟numpy中创建多维数组也有很多相似之处啊。
torch中tensor操作
算术操作,以加法为例
有两种方式,一种使用运算符 x + y,一种使用函数torch.add(x, y),且使用函数的时候可以指定输出torch.add(x, y, out=result)
还可以进行原地加法运算。
y.add_(x)
索引操作
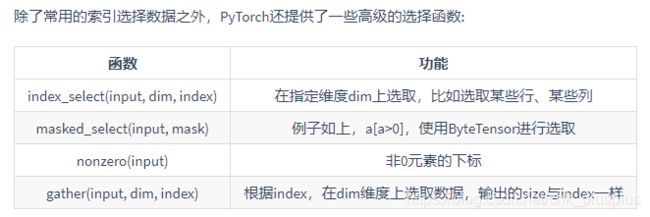
因为在动手学深度学习https://tangshusen.me/Dive-into-DL-PyTorch/#/chapter02_prerequisite/2.2_tensor上说对于tensor索引出来的结果与原数据共享内存,当经过下边两个例子验证,确实是这样子的,哪怕只索引了一个元素 x[0][0],他们的数据也是共享的,这点与python的标准数据类型是不同的。


改变形状
张量对象有一个view方法,可以用view来改变一个张量的形状

但是用view改变得到的新形状的张量与原张量是共享数据的,即view只是改变了观察数据的角度,并没有实际上改变数据。
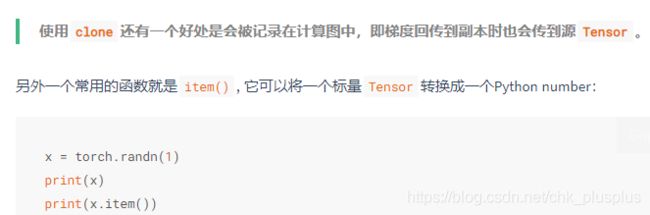
如果想要一个不共享数据的真正的副本,可以用reshape()函数来改变形状,但是此函数并不能保证返回的是拷贝,因此不推荐使用(reshape既有可能返回拷贝,也有可能跟view一样)。推荐使用clone创造一个副本然后再使用view。

运算内存开销
索引操作不开辟 新内存,而y = x + y这类操作是会开辟新内存的,可以通过索引操作来改写,使得y = x + y不开辟新内存,如下所示。

或者用add方法指定输出,也不会开辟新内存。还有y += x这种自加运算符,也不会开辟新内存。

Tensor与numpy互相转换
tensor 转 numpy
tensor对象有一个numpy()成员方法,直接a.numpy()即可,且这种方法产生的numpy数组与原张量的数据是共享内存的,即一个改变另一个也改变。

numpy转tensor
torch中有一个from_numpy()函数,这样转换得到的tensor与原numpy数组也是共享内存的。

还有一个方法是直接用torch.tensor(),但是这种方法会进行数据拷贝,开辟新内存。

tensor可以放到GPU上
