ECCV2020最佳论文 | 全面解析光流计算模型RAFT
作者‖ flow
编辑‖ 3D视觉开发者社区
导语:
RAFT这篇文章荣获了ECCV 2020的best paper,可以说实至名归,也将在光流领域的研究历史中留下浓重彩墨的一笔,本文将从RAFT算法的实现、迭代更新及实验结果对该篇文章进行解析,旨在为光流估计以及立体匹配相关研究人员提供学习参考。

ECCV 2020 best paper: RAFT
-
论文链接:
- https://arxiv.org/pdf/2003.12039.pdf
-
代码链接:
- https://github.com/princeton-vl/RAFT
0. 概述
RAFT算法在全分辨率上去提取特征,然后构建多尺度的4D 相关空间,尽管这一步骤的计算量比较大,但是之后可以通过查表的方式去获取 cost volume,而不必再另外做计算。
此外,RAFT通过GRU循环单元去迭代更新光流场,进而模拟传统方法中优化迭代的过程。GRU的引入,创新性地有着非常好的效果。这与以往从粗到精的策略有着本质上的不同,Raft一直在高分辨率上进行迭代更新,而非先在低分辨率估计光流,然后逐层传递给高分辨率最后再在高分辨率上进行优化。这样做的好处是,不会遭受低分辨率上的错误估计的影响,也相对来说不会错过快速移动的小物体的信息,更是由于绑定的固定权重,整体的参数量较小,收敛快,无需过多的训练次数。
更为吸引个人眼球的是,RAFT算法具有非常强的泛化能力。而泛化好的主要原因还是网络的底层结构设计的好,很好地模仿了传统优化更新的过程:
By constraining optical flow to be the product of a series of identical update steps, we force the network to learn an update operator which mimics the updates of a first-order descent algorithm.
This constrains the search space, reduces the risk of over-fitting, and leads to faster training and better generalization.
目前看来,NLP与CV逐渐地进行交融,或许也是大势所趋。
1. 方法
整体看来,Raft的网络结构设计非常简洁,如下图所示:
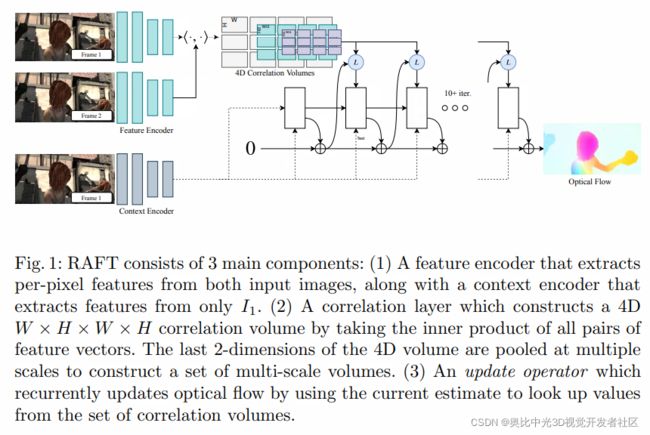
RAFT可以分为以下几个模块:
- Feature Extractor(特征提取模块;权重共享)& Context Extractor(语义特征提取模块)
特征提取模块逐像素地提取两张图片的特征,而语义特征提取模块架构与特征提取是一样的,但是只对一个模块进行提取。 - Visual Similarity Calculator(相似性计算模块)
通过计算两张图两两特征向量之间的点积来构建4D的相关空间。值得注意的是,这里的 W ∗ H ∗ W ∗ H W * H * W * H W∗H∗W∗H并非指的是影像的全分辨率,而是指的是特征的全分辨率。比如说,我们在1/8分辨率上构建得到特征向量,那么我们所谓的全分辨率就变成了1/8分辨率。 - Updator(更新迭代模块)
这个模块使用当前的光流估计结果,从相关空间金字塔中查找需要的特征,而后再作为输入进行迭代更新。
以下将对几个重要模块进行进一步的介绍。
1.1 特征提取
特征提取是在1/8分辨率上进行的,即对原始输入的两张影像都进行了提取,并将提取到的信息映射为1/8分辨率的密集特征,假设特征提取器命名为 g θ g_{\theta} gθ,则有 R H × W × 3 ↦ R H / 8 × W / 8 × D \mathbb{R}^{H \times W \times 3} \mapsto \mathbb{R}^{H / 8 \times W / 8 \times D} RH×W×3↦RH/8×W/8×D,特别地,我们将特征的通道维度设定为256。总的来说,特征提取器中包含了两个在1/2分辨率上的残差block,两个在1/4分辨率上的残差block,两个在1/8分辨率上的残差block,一共六个残差block。
此外,还用了一个语义信息提取器,命名为 h θ h_{\theta} hθ,其仅仅针对第一张输入影像进行信息的提取,值得注意的是,语义信息提取器的网络架构跟特征提取器的架构是一样的。
在Raft中,无论是特征提取器还是语义信息提取器在网络中都只会被过一遍,而不会进行迭代。
1.2 计算相似性
我们假设 g θ ( I 1 ) ∈ R H × W × D g_{\theta}\left(I_{1}\right) \in \mathbb{R}^{H \times W \times D} gθ(I1)∈RH×W×D以及 g θ ( I 2 ) ∈ R H × W × D g_{\theta}\left(I_{2}\right) \in \mathbb{R}^{H \times W \times D} gθ(I2)∈RH×W×D分别表示影像 I 1 I_1 I1和 I 2 I_2 I2的特征。
进而,所谓的correlation volume可以通过计算两两特征向量之间的点乘得到,用公式可以表达为:
C ( g θ ( I 1 ) , g θ ( I 2 ) ) ∈ R H × W × H × W , C i j k l = ∑ h g θ ( I 1 ) i j h ⋅ g θ ( I 2 ) k l h \mathbf{C}\left(g_{\theta}\left(I_{1}\right), g_{\theta}\left(I_{2}\right)\right) \in \mathbb{R}^{H \times W \times H \times W}, \quad C_{i j k l}=\sum_{h} g_{\theta}\left(I_{1}\right)_{i j h} \cdot g_{\theta}\left(I_{2}\right)_{k l h} C(gθ(I1),gθ(I2))∈RH×W×H×W,Cijkl=h∑gθ(I1)ijh⋅gθ(I2)klh
在上述公式中的 h h h代表的是维度, h h h的取值范围应该是[0,D-1],也即这个4D的代价空间中的每一个格网表示的两个特征图中的像素对所有特征点乘的加和。
以下为了简便起见,将称呼correlation volume为代价空间。
1.2.1. 代价空间金字塔
我们知道,特征可以分成不同分辨率,也就是说,可以构造不同分辨率的特征金字塔,同理,我们也可以构造代价空间的金字塔,但构造方式还是有些区别。
具体来说,我们构造4层的金字塔 { C 1 , C 2 , C 3 , C 4 } \{C^1,C^2,C^3,C^4\} {C1,C2,C3,C4}的示意图如下图所示:

其实就是将后两个通道通过卷积的方式进行降采样。而金字塔标号与其维度的关系是: C k − > H ∗ W ∗ H / 2 k ∗ H / 2 k C^k -> H* W * H/2^k * H/2^k Ck−>H∗W∗H/2k∗H/2k。非常有意思的是,这里的代价空间的前两个通道的维数是全分辨率的,并没有做下采样,做下采样的是后面两个维度。也就是说,对于第一张影像来说,是全分辨率的。
1.2.2. 代价空间查表
Raft设计了一个查表的操作符: L C L_C LC ,能够通过代价空间中的序标生成特征图。
给定当前光流的状态,记为 ( f 1 , f 2 ) (f^1,f^2) (f1,f2),通过这个光流的状态,我们可以得到 I 1 I_1 I1图在 I 2 I_2 I2图上的对应点 x ′ x' x′,为: x ′ = ( u + f 1 ( u ) , v + f 2 ( v ) ) \mathbf{x}^{\prime}=\left(u+f^{1}(u), v+f^{2}(v)\right) x′=(u+f1(u),v+f2(v))。
此时,我们定义 x ′ x' x′的邻域格网,记为: N ( x ′ ) r = { x ′ + d x ∣ d x ∈ Z 2 , ∥ d x ∥ 1 ≤ r } \mathcal{N}\left(\mathbf{x}^{\prime}\right)_{r}=\left\{\mathbf{x}^{\prime}+\mathbf{d} \mathbf{x} \mid \mathbf{d} \mathbf{x} \in \mathbb{Z}^{2},\|\mathbf{d} \mathbf{x}\|_{1} \leq r\right\} N(x′)r={x′+dx∣dx∈Z2,∥dx∥1≤r},而该领域格网,我们就可以对应地找到其在中的代价空间中的位置/index。在所有层级的金字塔上都通过 N ( x ′ / 2 k ) \mathcal{N}\left(\mathbf{x}^{\prime}/2^k\right) N(x′/2k)执行查找,越低的金字塔对应着越为全局的语义特征。
构建代价空间以及查表的代码实现为:
class CorrBlock:
def __init__(self, fmap1, fmap2, num_levels=4, radius=4):
self.num_levels = num_levels
self.radius = radius
self.corr_pyramid = []
# all pairs correlation
corr = CorrBlock.corr(fmap1, fmap2)
batch, h1, w1, dim, h2, w2 = corr.shape
corr = corr.reshape(batch*h1*w1, dim, h2, w2)
self.corr_pyramid.append(corr)
for i in range(self.num_levels-1):
corr = F.avg_pool2d(corr, 2, stride=2)
self.corr_pyramid.append(corr)
def __call__(self, coords):
r = self.radius
coords = coords.permute(0, 2, 3, 1)
batch, h1, w1, _ = coords.shape
out_pyramid = []
for i in range(self.num_levels):
corr = self.corr_pyramid[i]
dx = torch.linspace(-r, r, 2*r+1)
dy = torch.linspace(-r, r, 2*r+1)
delta = torch.stack(torch.meshgrid(dy, dx), axis=-1).to(coords.device)
centroid_lvl = coords.reshape(batch*h1*w1, 1, 1, 2) / 2**i
delta_lvl = delta.view(1, 2*r+1, 2*r+1, 2)
coords_lvl = centroid_lvl + delta_lvl
corr = bilinear_sampler(corr, coords_lvl)
corr = corr.view(batch, h1, w1, -1)
out_pyramid.append(corr)
out = torch.cat(out_pyramid, dim=-1)
return out.permute(0, 3, 1, 2).contiguous().float()
@staticmethod
def corr(fmap1, fmap2):
batch, dim, ht, wd = fmap1.shape
fmap1 = fmap1.view(batch, dim, ht*wd)
fmap2 = fmap2.view(batch, dim, ht*wd)
corr = torch.matmul(fmap1.transpose(1,2), fmap2)
corr = corr.view(batch, ht, wd, 1, ht, wd)
return corr / torch.sqrt(torch.tensor(dim).float())
1.2.3. 高分辨率影像的高效计算
考虑到下方公式中表达的等效关系,我们可以将 O ( N 2 ) O(N^2) O(N2)的点对之间的计算复杂度,缩减到 O ( N M ) O(NM) O(NM)
C i j k l m = 1 2 2 m ∑ p 2 m ∑ q 2 m ⟨ g i , j ( 1 ) , g 2 m k + p , 2 m l + q ( 2 ) ⟩ = ⟨ g i , j ( 1 ) , 1 2 2 m ( ∑ p 2 m ∑ q 2 m g 2 m k + p , 2 m l + q ( 2 ) ⟩ \mathbf{C}_{i j k l}^{m}=\frac{1}{2^{2 m}} \sum_{p}^{2^{m}} \sum_{q}^{2^{m}}\left\langle g_{i, j}^{(1)}, g_{2^{m} k+p, 2^{m} l+q}^{(2)}\right\rangle=\left\langle g_{i, j}^{(1)}, \frac{1}{2^{2 m}}\left(\sum_{p}^{2^{m}} \sum_{q}^{2^{m}} g_{2^{m} k+p, 2^{m} l+q}^{(2)}\right\rangle\right. Cijklm=22m1p∑2mq∑2m⟨gi,j(1),g2mk+p,2ml+q(2)⟩=⟨gi,j(1),22m1(p∑2mq∑2mg2mk+p,2ml+q(2)⟩
其实通常来说,直接计算点对之间的相关也不会成为性能瓶颈,但是如果有需求的话,确实可以切换到等效的实现中。
此外,raft的开源代码中也提供了代价空间的快速实现,可以通过编译cuda进行调用。
1.3 迭代更新
从初始的光流状态 f 0 \mathbf{f_0} f0开始,更新操作符输出了N次光流的结果 { f 1 , … , f N } \left\{\mathbf{f}_{1}, \ldots, \mathbf{f}_{N}\right\} {f1,…,fN}。
每一次迭代,更新操作符都输出一个优化的光流 Δ f \Delta \mathbf{f} Δf,并将其与当前的光流状态进行叠加,得到更新后的光流状态: f k + 1 = Δ f + f k + 1 \mathbf{f}_{k+1} = \Delta \mathbf{f} + \mathbf{f_{k+1}} fk+1=Δf+fk+1。
更新操作符将光流状态,相关空间,以及潜在的隐藏状态(初始的隐藏状态由语义提取器提供)作为输入,进而输出两个量,一个是用于更新的 Δ f \Delta \mathbf{f} Δf,另一个则是更新后的隐藏状态。
这样的设计主要是为了模拟传统算法中的优化过程。
在迭代更新过程中,还有一个不得不提的精华是:通过学习mask的方式得到上采样的权值,而非平常的双线性。
1.3.1 初始化
通常来说,我们会默认光流场在所有开始的时候默认值都是0。但是Raft这种迭代的方式,使得可以采用warm start的方式,比如,在将Raft应用到视频的光流估计的时候,就可以将前一帧的光流投影到下一帧去,作为下一帧的初始值。
1.3.2 输入
给定当前的光流状态 f k \mathbf{f}^k fk后,我们就利用其去检索对应在相关空间中的特征。
然后再通过两个卷积层对这些特征进行处理,此外,这两个卷积层还将应用到光流估计本身中,用于生成光流特征。最后,再从语义网络中获取信息,并将其与代价空间,光流进行concat,作为更新算子的输入。
1.3.3 更新
更新算子的核心组件是一个基于GRU的门控激活单元(gated activation unit),其使用全连接的方式来替代了以往的卷积:
z t = σ ( Conv 3 × 3 ( [ h t − 1 , x t ] , W z ) ) r t = σ ( Conv 3 × 3 ( [ h t − 1 , x t ] , W r ) ) h ~ t = tanh ( Conv 3 × 3 ( [ r t ⊙ h t − 1 , x t ] , W h ) ) h t = ( 1 − z t ) ⊙ h t − 1 + z t ⊙ h ~ t \begin{aligned} z_{t} &=\sigma\left(\operatorname{Conv}_{3 \times 3}\left(\left[h_{t-1}, x_{t}\right], W_{z}\right)\right) \\ r_{t} &=\sigma\left(\operatorname{Conv}_{3 \times 3}\left(\left[h_{t-1}, x_{t}\right], W_{r}\right)\right) \\ \tilde{h}_{t} &=\tanh \left(\operatorname{Conv}_{3 \times 3}\left(\left[r_{t} \odot h_{t-1}, x_{t}\right], W_{h}\right)\right) \\ h_{t} &=\left(1-z_{t}\right) \odot h_{t-1}+z_{t} \odot \tilde{h}_{t} \end{aligned} ztrth~tht=σ(Conv3×3([ht−1,xt],Wz))=σ(Conv3×3([ht−1,xt],Wr))=tanh(Conv3×3([rt⊙ht−1,xt],Wh))=(1−zt)⊙ht−1+zt⊙h~t
其中 x t x_t xt是光流信息,代价空间以及语义特征的concat。
卷积GRU的代码实现为:
class ConvGRU(nn.Module):
def __init__(self, hidden_dim=128, input_dim=192+128):
super(ConvGRU, self).__init__()
self.convz = nn.Conv2d(hidden_dim+input_dim, hidden_dim, 3, padding=1)
self.convr = nn.Conv2d(hidden_dim+input_dim, hidden_dim, 3, padding=1)
self.convq = nn.Conv2d(hidden_dim+input_dim, hidden_dim, 3, padding=1)
def forward(self, h, x):
hx = torch.cat([h, x], dim=1)
z = torch.sigmoid(self.convz(hx))
r = torch.sigmoid(self.convr(hx))
q = torch.tanh(self.convq(torch.cat([r*h, x], dim=1)))
h = (1-z) * h + z * q
return h
此外,还实验了用一个带有两个 G R U GRU GRU单元的结构去替代3*3的卷积,这两个GRU单元中,一个有着1*5的卷积,另一个则有着5*1的卷积。这样做的好处是,既能够增大感受野,又不会使得模型的体量变大很多。
而这个额外的结构的代码实现为:
class SepConvGRU(nn.Module):
def __init__(self, hidden_dim=128, input_dim=192+128):
super(SepConvGRU, self).__init__()
self.convz1 = nn.Conv2d(hidden_dim+input_dim, hidden_dim, (1,5), padding=(0,2))
self.convr1 = nn.Conv2d(hidden_dim+input_dim, hidden_dim, (1,5), padding=(0,2))
self.convq1 = nn.Conv2d(hidden_dim+input_dim, hidden_dim, (1,5), padding=(0,2))
self.convz2 = nn.Conv2d(hidden_dim+input_dim, hidden_dim, (5,1), padding=(2,0))
self.convr2 = nn.Conv2d(hidden_dim+input_dim, hidden_dim, (5,1), padding=(2,0))
self.convq2 = nn.Conv2d(hidden_dim+input_dim, hidden_dim, (5,1), padding=(2,0))
def forward(self, h, x):
# horizontal
hx = torch.cat([h, x], dim=1)
z = torch.sigmoid(self.convz1(hx))
r = torch.sigmoid(self.convr1(hx))
q = torch.tanh(self.convq1(torch.cat([r*h, x], dim=1)))
h = (1-z) * h + z * q
# vertical
hx = torch.cat([h, x], dim=1)
z = torch.sigmoid(self.convz2(hx))
r = torch.sigmoid(self.convr2(hx))
q = torch.tanh(self.convq2(torch.cat([r*h, x], dim=1)))
h = (1-z) * h + z * q
return h
在Raft的消融实验中,有:


其中的Conv指使用一组带有Relu激活的3个卷积层来替代ConvGRU,结果表明,使用带有GRU的更新算子能够得到更好的结果,这可能是因为门控激活的方式使得光流更容易收敛。
1.3.4 预测
GRU单元输出的潜在状态(hidden state)将会再被送进两个卷积层,用于输出更新的光流值 Δ f \Delta \mathbf{f} Δf。输出的光流的分辨率是原始图像的1/8。在训练以及越策的过程中,都会进一步地将1/8分辨率的输出上采样到全分辨率,进而能够与GT进行比较。具体上采样的方式很新颖,具体可以见节3.5。
1.3.5 上采样
Raft从1/8分辨率上采样的方式非常的新颖,并不是单纯的双线性。而是将全分辨率上的每一个像素都看做是其在1/8分辨率上的邻域像素们的某种凸组合(convex combination),进而可以通过对1/8分辨率上的邻域像素们进行采样,进而得到全分辨率上的结果。具体来说,Raft使用了两个卷积层来预测mask,这个mask的维度是 H / 8 ∗ W / 8 ∗ ( 8 ∗ 8 ∗ 9 ) H/8 * W/8 * (8*8*9) H/8∗W/8∗(8∗8∗9),为什么是 8 ∗ 8 ∗ 9 8*8*9 8∗8∗9呢,因为对于1/8分辨率上的每一个像素来说,都对应着全分辨率的8*8个像素,而Raft又认为全分辨率的每一个像素又和其领域的9个像素相关,所以mask的维度就变成了 H / 8 ∗ W / 8 ∗ ( 8 ∗ 8 ∗ 9 ) H/8 * W/8 * (8 * 8 * 9) H/8∗W/8∗(8∗8∗9)。之后再对这9个邻居的权重做softmax。最后再根据这9个邻居的权值加权得到全分辨率上的结果。而这样的过程,可以使用pytorch所提供的unfold函数进行实现。
上采样的具体代码实现为:
def upsample_flow(self, flow, mask):
""" Upsample flow field [H/8, W/8, 2] -> [H, W, 2] using convex combination """
N, _, H, W = flow.shape
mask = mask.view(N, 1, 9, 8, 8, H, W)
mask = torch.softmax(mask, dim=2)
up_flow = F.unfold(8 * flow, [3,3], padding=1)
up_flow = up_flow.view(N, 2, 9, 1, 1, H, W)
up_flow = torch.sum(mask * up_flow, dim=2)
up_flow = up_flow.permute(0, 1, 4, 2, 5, 3)
return up_flow.reshape(N, 2, 8*H, 8*W)
其中的mask是由更新算子过卷积后提供的:
class BasicUpdateBlock(nn.Module):
def __init__(self, args, hidden_dim=128, input_dim=128):
super(BasicUpdateBlock, self).__init__()
self.args = args
self.encoder = BasicMotionEncoder(args)
self.gru = SepConvGRU(hidden_dim=hidden_dim, input_dim=128+hidden_dim)
self.flow_head = FlowHead(hidden_dim, hidden_dim=256)
self.mask = nn.Sequential(
nn.Conv2d(128, 256, 3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 64*9, 1, padding=0))
def forward(self, net, inp, corr, flow, upsample=True):
motion_features = self.encoder(flow, corr)
inp = torch.cat([inp, motion_features], dim=1)
net = self.gru(net, inp)
delta_flow = self.flow_head(net)
# scale mask to balence gradients
mask = .25 * self.mask(net)
return net, mask, delta_flow
1.4 损失函数
RAFT进行了12次迭代,进而会产生12个全分辨率的光流结果。常理来说,越迭代到后面,理应更为接近GT,因此,给其更大的权重,进而,loss的设计为:
L = ∑ i = 1 N γ N − i ∥ f g t − f i ∥ 1 \mathcal{L}=\sum_{i=1}^{N} \gamma^{N-i}\left\|\mathbf{f}_{g t}-\mathbf{f}_{i}\right\|_{1} L=i=1∑NγN−i∥fgt−fi∥1
其中的 γ \gamma γ是一个经验参数,在Raft中设置为0.8。
2. 实验及结果
2.1 实验参数设置
测试的数据集为Sintel以及KITTI。网络在FlyingChairs以及FlyingThings上进行预训练,而后在特定的数据集上finetune。
此外,还测试了Raft在1080p的视频上的表现。
所有的模块参数都是随机初始化的,在训练中,使用了AdamW以及梯度裁剪(范围在[-1,1]之间)。测试的时候,在Sintel数据上为32次迭代,在KITTI数据上为24次迭代。每一次迭代的时候, Δ f + f k \Delta\mathbf{f}+\mathbf{f}_{k} Δf+fk只在 Δ f \Delta\mathbf{f} Δf的分支上进行梯度回传,而在 f k \mathbf{f}_k fk的分支上梯度为0。
在训练时,具体使用了两块2080Ti的GPU。在FlyingThings上训练了10w次迭代,batchsize为12,而后在FlyingThings3D上继续训练了10w次迭代,batchsize为6。
对于在Sintel上的finetune,使用了Sintel、KITTI-2015以及HD1K的混合数据又训练了10w次迭代。最后,使用KITTI-2015的数据,在Sintel Finetune的模型上再进行了5w次迭代,得到了在KITTI-2015上的模型。
2.2 消融实验
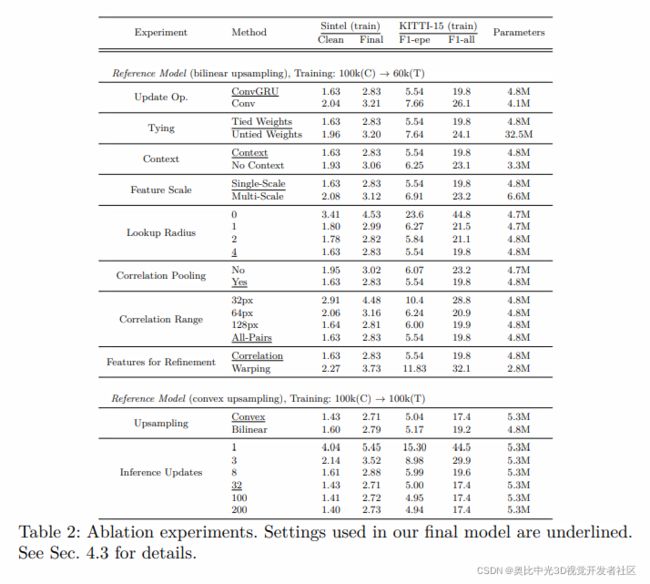
消融实验提供了非常好的参考,基本上可以说明其设计都是有作用的。表格显示的非常清楚,就不在这里赘述了。
2.3 耗时测试
当我们关注网络的实用性时,往往会关注它的耗时。
sintel数据的分辨率是1024 * 436:

Raft在耗时上的测试使用plot的形式来表达,具体可以看下图中间的图,注意到其10M的小模型可以达到50ms内的推理时间。

版权声明:本文由奥比中光3D视觉开发者社区特约作者——flow(奥比中光算法工程师,毕业于中国科学院大学,人工智能领域优秀作者。)授权原创发布,未经授权请勿转载,本文仅做学术分享,版权归原作者所有,若涉及侵权内容请联系删文。
3D视觉开发者社区是由奥比中光给所有开发者打造的分享与交流平台,旨在将3D视觉技术开放给开发者。平台为开发者提供3D视觉领域免费课程、奥比中光独家资源与专业技术支持。点击加入3D视觉开发者社区,和开发者们一起讨论分享吧~
或可微信关注官方公众号 3D视觉开发者社区 ,获取更多干货知识哦