【数据库】MySQL表的增删改查
CRUD即增加(Create)、查询(Retrieve)、更新(Update)、删除(Delete)四个单词的首字母缩写
一、新增(Create)
insert into 表名 values(列的值); 往表里插入数据 into可省略
-- 创建一张学生表
DROP TABLE IF EXISTS student;
CREATE TABLE student (
id INT,
sn INT comment '学号',
name VARCHAR(20) comment '姓名',
qq_mail VARCHAR(20) comment 'QQ邮箱'
);
- 单行数据 + 全列插入
-- 插入两条记录,value_list 数量必须和定义表的列的数量及顺序一致
INSERT INTO student VALUES (100, 10000, '唐三藏', NULL);
INSERT INTO student VALUES (101, 10001, '孙悟空', '11111');
- 多行数据 + 指定列插入
-- 插入两条记录,value_list 数量必须和指定列数量及顺序一致
INSERT INTO student (id, sn, name) VALUES
(102, 20001, '曹孟德'),
(103, 20002, '孙仲谋');
1、 注意:
-
要求values后面()中的字段的个数和表头约定的列数以及每个列的类型,要匹配
-
在SQL中表示字符串,可以使用’也可以使用”.Java中要求只能是"表示字符串.'表示的是字符但是在SQL里面,没有单独的“字符类型"
-
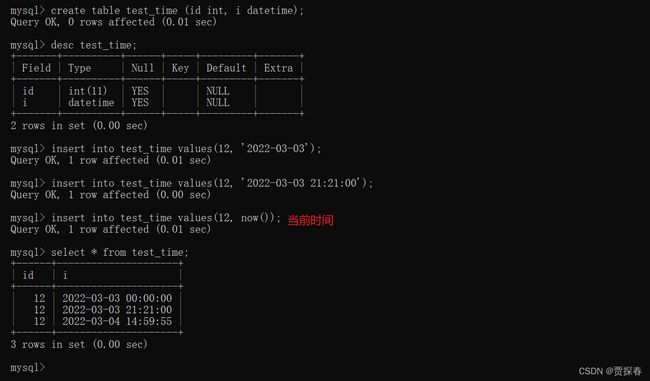
如果某一列是 datetime,此时如何进行插入呢?
1)通过指定格式的字符串来插入一个指定时间. YYY-MM-DD hh:mm:ss
2)通过now()函数来插入一个当前系统时间.
-
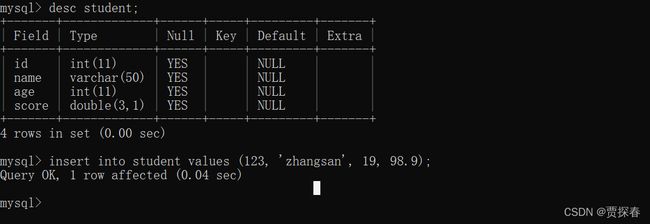
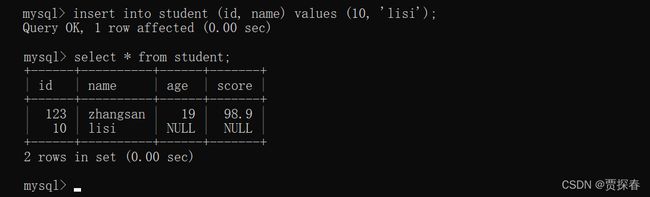
insert进行插入的时候,可以只插入其中的某一列或者某几个列的,此时其他的列将采用默认值
-
一次插入多行,用逗号分开
values后面的每个()都对应到一行,可以一次性的带有多个(),多个()之间使用逗号来分割
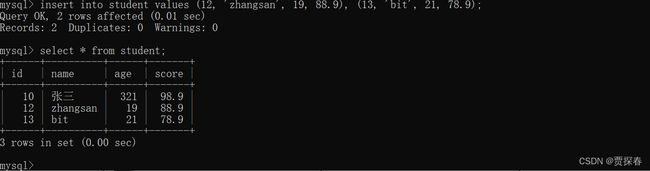
一次插入N条记录,的速度比一次插入一条,分N词插入,要快很多!!(好几倍)
-
插入中文,可能会失败

MySQL默认的编码方式是拉丁文,就需要把数据库给配置成支持中文(配置成utf8编码方式)
如何进行配置编码方式:
1、先查看一下当前数据库的编码方式
show variables like 'character%';
2、通过修改mysql 配置文件的方式来进行处理
通过以下方式先找到配置文件:
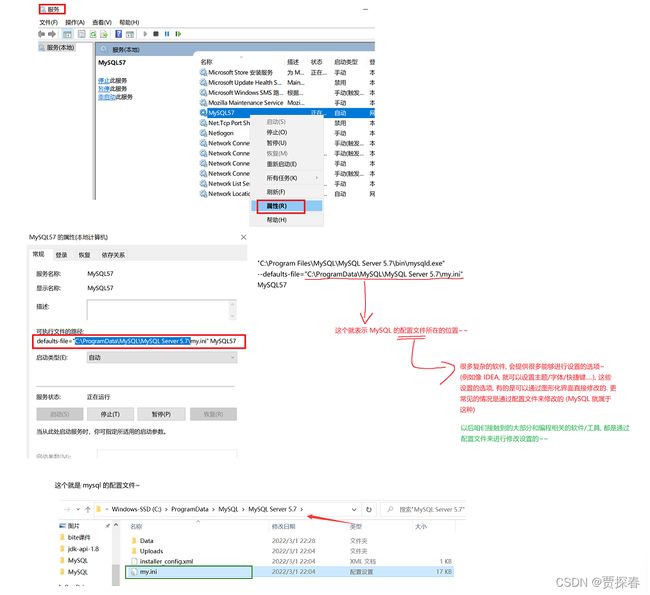
3、使用记事本打开这个文件,进行编辑. (修改之前,一定要先备份!!)这是一个良好的工作习惯.以后我们在公司里修改任何重要的数据一定都是先备份再修改,防止修改出错,难以还原!!!

4、改完保存,重新启动mysql服务器(重启电脑也行)
5、还得把之前的数据库删了,重新创建新的数据库(旧的数据库不会收到影响)
二、查询(Retrieve)
查找语句是SQL中最核心也最复杂的操作心
1、全列查找
直接把一个表的所有的列,和所有的行都查询出来~
select * from表名; * 就叫做"通配符",表示一个表的所有列
实例:
-- 创建考试成绩表
create table exam_result (
id int,
name varchar(20),
chinese decimal(3,1),
math decimal(3.1),
english decimal(3.1)
);
-- 创建考试成绩表
INSERT INTO exam_result (id,name, chinese, math, english) VALUES
(1,'唐三藏', 67, 98, 56),
(2,'孙悟空', 87.5, 78, 77),
(3,'猪悟能', 88, 98.5, 90),
(4,'曹孟德', 82, 84, 67),
(5,'刘玄德', 55.5, 85, 45),
(6,'孙权', 70, 73, 78.5),
(7,'宋公明', 75, 65, 30);
- 查看:
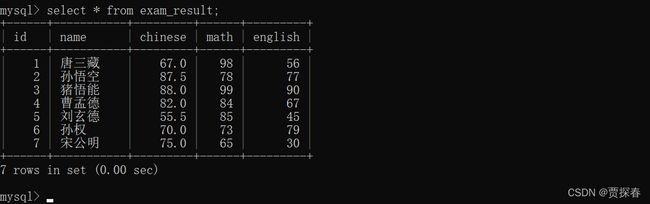
把一个表里面的所有的行和所有的列都查找到,查找的结果是一个"临时表"
之前咱们说的数据库的表,都是在硬盘上的
而此处的这个查询结果临时表,不是在硬盘上,而是在内存中,随着进行了输出之后,数据也就被释放了
注意:
像select * from表名这个操作也是一个危险操作!!!
如果直接在生产环境的服务器上,执行 select * from表名,很可能带来灾难
生产环境保存的数据量可能是非常大的,几个TB级别的.
此时就意味着MySQL服务器就会疯狂的来读取硬盘数据,瞬间就会把硬盘的IO给吃满
硬盘的读取速度是存在上限,尤其是机械硬盘,同时MySQL服务器又会立即的返回响应数据~由于返回的响应数据也很大很多,也会把网卡的带宽吃满~(百兆,千兆,万兆网卡)
一旦服务器的硬盘和网络被吃满,此时数据库服务器就难以对其他的客户端的请求做出响应
(而生产环境的服务器,无事不刻要给普通用户提供响应)数据库就好像废了一样
实际开发中,一般公司都会对SQL的执行时间做出监控~一旦发现出现了这种长时间执行的“慢SQL”,就强制把这个SQL给杀死
2、指定列查询
select列名,列名.... from表名; 只查询自己关注的列
这个查询结果,只是一个临时表,(在客户端内存临时保存的一个数据表,随着打印的进行,内存就释放了) 临时表的结果对于数据库服务器的原始数据没有任何影响
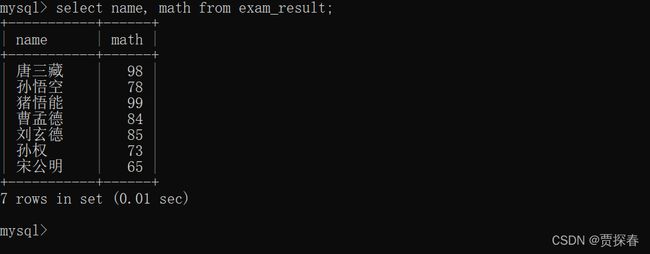
这里在查询的时候会显式的告诉数据库要查的是哪些列,数据库就会有针对性的进行返回数据了
相比于刚才的全列查询,这种指定列查询就要更高效很多,后面再工作中接触的数据库,一个表里面十几列都是挺正常
因此平时开发中还是这种指定列查询比全列查询要使用的频率高很多
3、指定查询字段为表达式
在查询的时候,同时进行一些运算操作 (列和列之间)
-
例如,期望查询结果中的语文成绩比真实的多10分
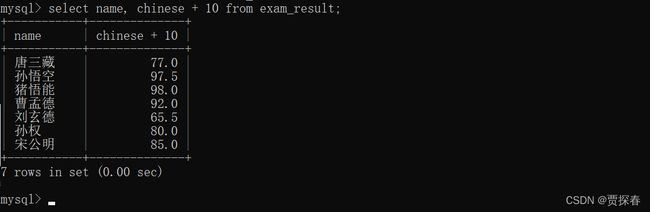
select 操作的结果是“临时表",原来数据库服务器上的数据没有改变,这里的查询结果变了,只是数据库服务器针对查询的结果进行了加工,把加工后的数据作为临时表显示出来了 -
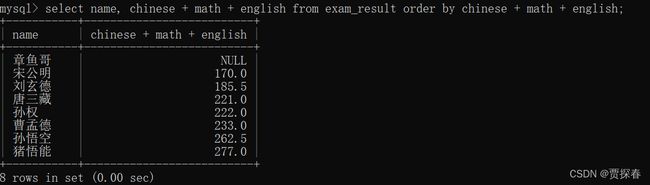
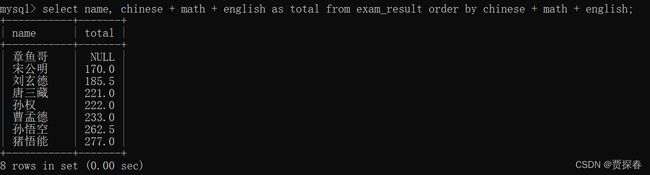
查询一下每个同学的总分~(语文+数学+英语)
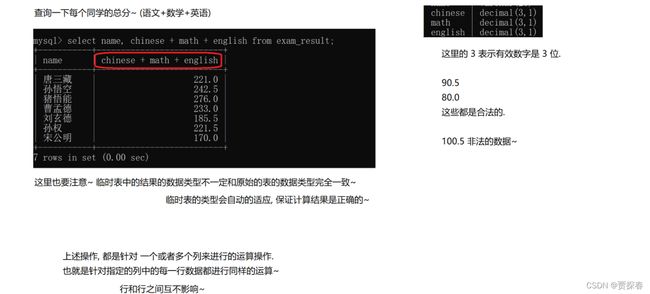
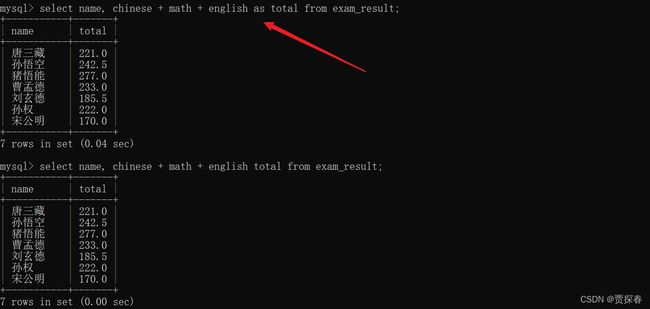
4、查询字段指定别名
相当于是给查询结果的临时表,指定新的列名,通过指定别名的方式,来避免得到的临时表,名字比较乱
as可省略,不过容易混淆
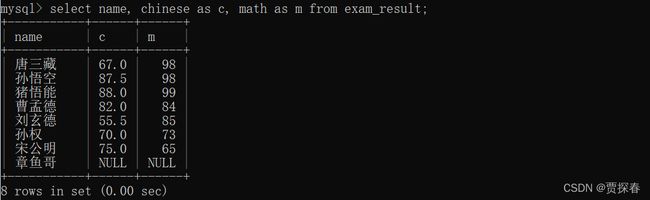
- 指定多个别名
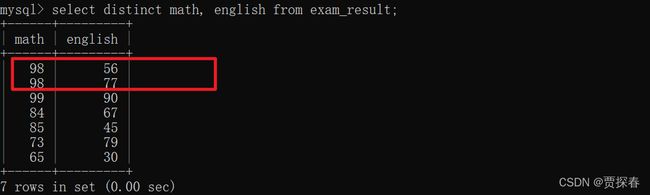
5、针对查询结果去重 distinct
distinct 针对查询的结果把重复的记录给去掉
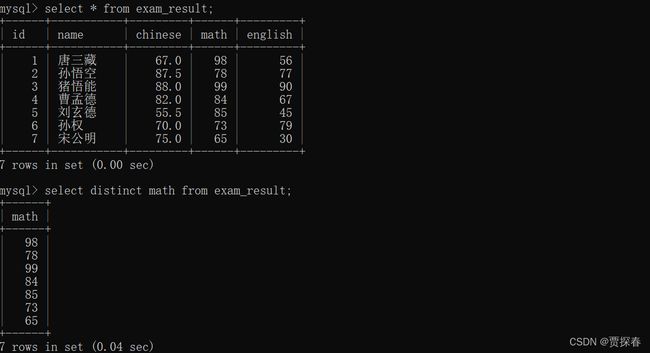
- 如果是针对多个列来进行去重,就得这多个列的值都相同的时候才视为重复
6、排序 order by
select列名... from表名order by 列名asc/desc;
针对查询结果 (临时表)进行排序 ,(不会影响到数据库服务器上的原始数据的)
asc 如果省略不写,默认也是升序
-
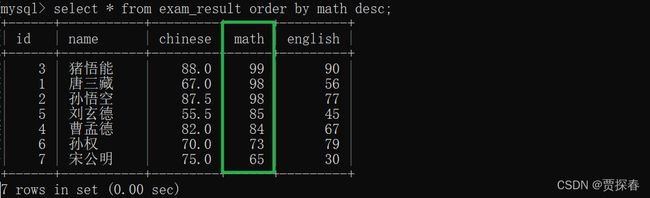
例:针对数学成绩进行升序排序

像数据库查询结果,如果不去指定排序,此时查询结果的顺序是不可预期的~~(写代码的时候不能依赖默认的顺序) -
desc降序:
-
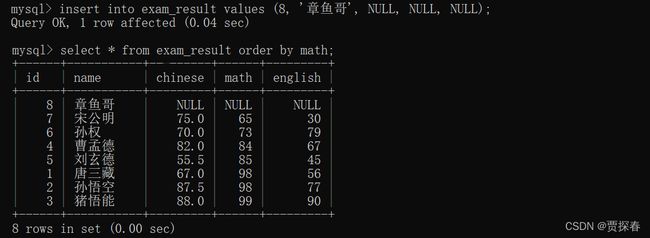
有的数据库记录中是带有NULL值的,像这样的NULL认为是最小的 (升序排就在最前面,降序就再最后面)
-
排序也可以依据表达式或者别名来进行排序
-
上述加上别名排序
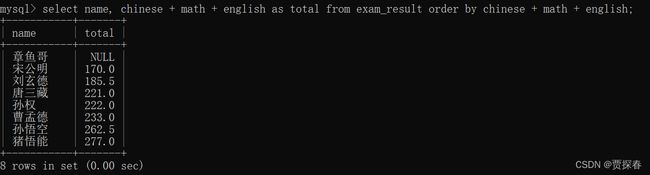
-
排序的时候还可以通过
order by来指定多个列进行排序~~
先根据第一个列进行排序. 如果第一个列结果相同, 相同结果之间再通过第二个列排序…
先按照数学排序.如果数学成绩相同,再按照语文排序…
多个列排序的时候是有明确优先级的
如果不指定多个列的话,只有指定一个列,此时如果结果相同,彼此之间的顺序都是不可预期的
7、select 中的条件查询 where
select列名from表名where 条件;
查询结果就会把满足条件的记录保留,把不满足条件的记录给过滤掉
7.1、运算符
比较运算符:
| 运算符 | 说明 |
|---|---|
| >, >=, <, <= | 大于,大于等于,小于,小于等于 |
| = | 等于,NULL 不安全,例如 NULL = NULL 的结果是 NULL |
| <=> | 等于,NULL 安全,例如 NULL <=> NULL 的结果是 TRUE(1) |
| !=, <> | 不等于 |
| BETWEEN a0 AND a1 | 范围匹配,[a0, a1],如果 a0 <= value <= a1,返回 TRUE(1) |
| IN (option, …) | 如果是 option 中的任意一个,返回 TRUE(1) |
| IS NULL | 是 NULL |
| IS NOT NULL | 不是 NULL |
| LIKE | 模糊匹配。% 表示任意多个(包括 0 个)任意字符;_ 表示任意一个字 符 |
= 表示比较相等,而不是赋值了
NULL = NULL , 结果仍然是NULL , NULL 会视为是假,条件不成立
<=> 也是比较相等,用法和=基本一致,只是使用<=>,比较空值结果是真,NULL <=> NULL进行比较.
IN (option, ...) 通过后面这个()给出几个固定的值.判定当前结果是否在这几个值之中~
IS NULL IS NOT NULL 也是专门用来和空值比较的
LIKE LIKE能够针对结果进行"模糊匹配"
逻辑运算符:
| 运算符 | 说明 |
|---|---|
| AND | 多个条件必须都为 TRUE(1),结果才是 TRUE(1) |
| OR | 任意一个条件为 TRUE(1), 结果为 TRUE(1) |
| NOT | 条件为 TRUE(1),结果为 FALSE(0) |
相当于 && || !
注:
- WHERE条件可以使用表达式,但不能使用别名。
- AND的优先级高于OR,在同时使用时,需要使用小括号()包裹优先执行的部分
案例:
- 基本查询
-- 查询英语不及格的同学及英语成绩 ( < 60 )
SELECT name, english FROM exam_result WHERE english < 60;
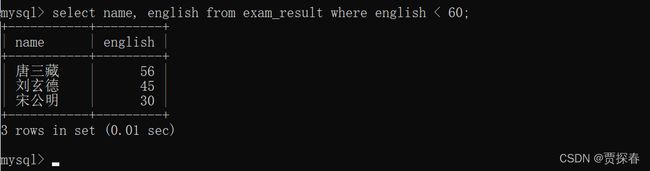
这个条件就会针对查询结果进行筛选
服务器就会遍历表中的每一条记录,如果记录符合条件,就返回给客户端.如果不符合条件,就跳过.
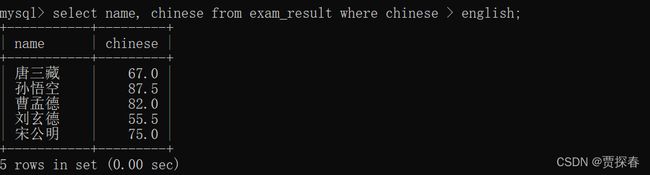
-- 查询语文成绩好于英语成绩的同学
SELECT name, chinese, english FROM exam_result WHERE chinese > english;
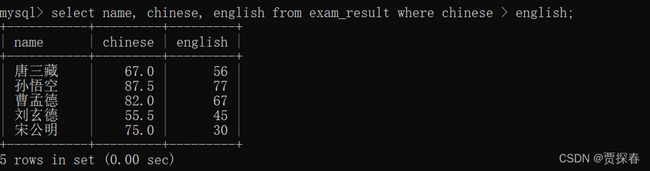
指的是针对同一行的语文和英语之间进行比较不涉及行和行之间的比较
这里显示什么,取决于select后面要查询的列怎么写,写或者不写不影响后面的条件,where后面的条件和前面写的列之间没有关系
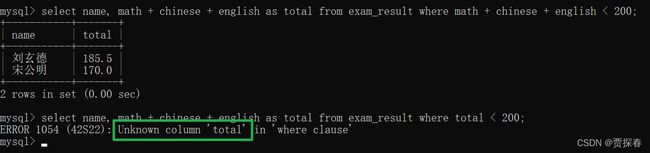
-- 查询总分在 200 分以下的同学
SELECT name, chinese + math + english 总分 FROM exam_result
WHERE chinese + math + english < 200;

- where字句不能使用别名,查询语句,要查询的列和where后面访问的列之间是没啥关联关系的
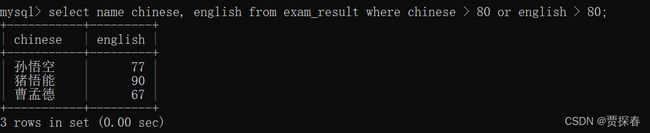
- AND与OR
-- 查询语文成绩大于80分,且英语成绩大于80分的同学
SELECT * FROM exam_result WHERE chinese > 80 and english > 80;

-- 查询语文成绩大于80分,或英语成绩大于80分的同学
SELECT * FROM exam_result WHERE chinese > 80 or english > 80;
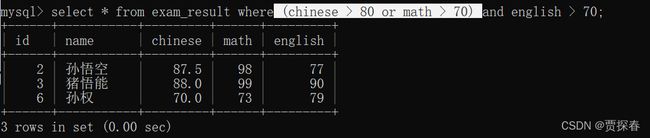
-- 观察AND 和 OR 的优先级:
SELECT * FROM exam_result WHERE chinese > 80 or math>70 and english > 70;
SELECT * FROM exam_result WHERE (chinese > 80 or math>70) and english > 70;
AND的优先级高于OR

加上()之后,就是先算 or后算and .对于曹孟德来说,前面的or表达式。—是成立的,但是and后面english >70不成立,整体还是不成立的
- 范围查询:
1).BETWEEN ... AND...
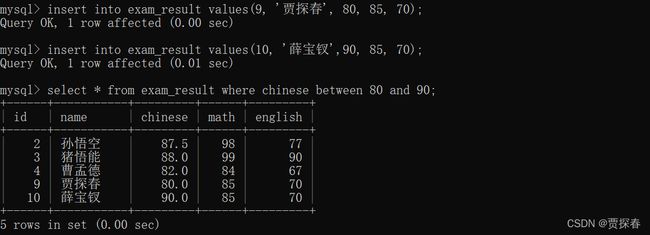
-- 查询语文成绩在 [80, 90] 分的同学及语文成绩
SELECT name, chinese FROM exam_result WHERE chinese BETWEEN 80 AND 90;
包含边界:
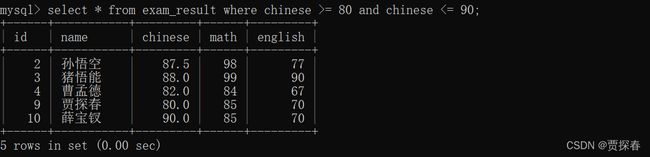
-- 使用 AND 也可以实现
SELECT name, chinese FROM exam_result WHERE chinese >= 80 AND chinese
<= 90;
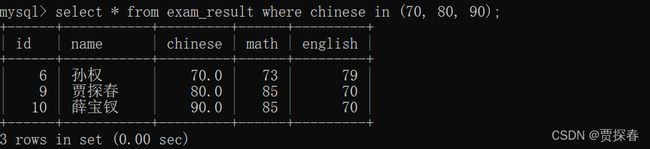
2). IN
-- 查询数学成绩是 58 或者 59 或者 98 或者 99 分的同学及数学成绩
SELECT name, math FROM exam_result WHERE math IN (58, 59, 98, 99);
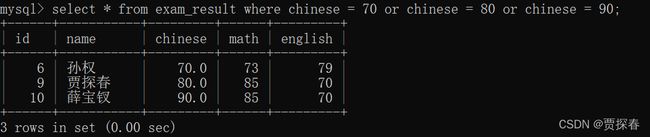
-- 使用 OR 也可以实现
SELECT name, math FROM exam_result WHERE math = 58 OR math = 59 OR math
= 98 OR math = 99;
- 模糊查询:LIKE
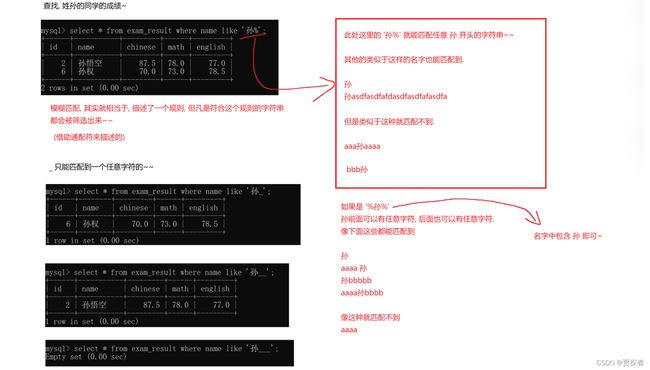
like,搭配通配符来使用.只要对方的字符串符合你此处描述的一个形式
%代表任意一个任意字符 (也包含 0 个字符)
_代表任意一个字符
-- % 匹配任意多个(包括 0 个)字符
SELECT name FROM exam_result WHERE name LIKE '孙%';-- 匹配到孙悟空、孙权
-- _ 匹配严格的一个任意字符
SELECT name FROM exam_result WHERE name LIKE '孙_';-- 匹配到孙权
- NULL 的查询:IS [NOT] NULL
-- 查询 qq_mail 已知的同学姓名
SELECT name, qq_mail FROM student WHERE qq_mail IS NOT NULL;
-- 查询 qq_mail 未知的同学姓名
SELECT name, qq_mail FROM student WHERE qq_mail IS NULL
查找 math 成绩为空的信息,
章鱼哥math为null,相当于null = null 比较,仍然是null,被视为 false
针对 null 进行一些算术运算操作,结果也是 null
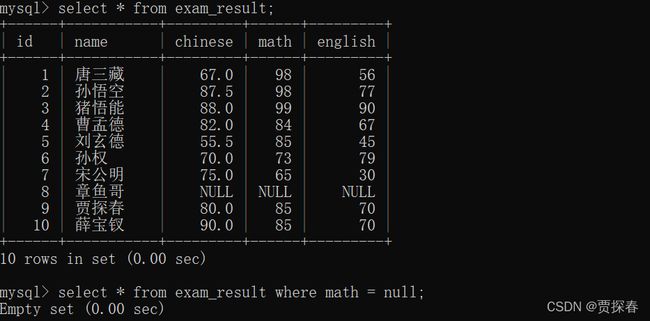
NULL <=> NULL 的结果是 TRUE

8、 分页查询:LIMIT
此处就可以约定好,一页中最多显示多少个结果,在进行查找的时候,就按照页来进行返回
假设一页显示20条记录.
第一页就显示1-20 第二页就显示21-40 第三页就显示41-60
SQL中可以通过limit 来实现分页查询

案例: 按 id 进行分页,每页 3 条记录,分别显示 第 1、2、3 页
第 1 页
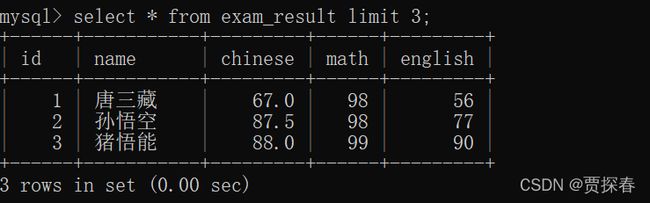
SELECT id, name, math, english, chinese FROM exam_result ORDER BY id LIMIT 3
OFFSET 0;
-- 第 2 页
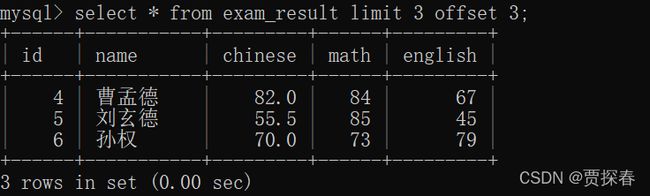
SELECT id, name, math, english, chinese FROM exam_result ORDER BY id LIMIT 3
OFFSET 3;
-- 第 3 页,如果结果不足 3 个,不会有影响
SELECT id, name, math, english, chinese FROM exam_result ORDER BY id LIMIT 3 OFFSET 6;
UPDATE table_name SET column = expr [, column = expr ...] [WHERE ...] [ORDER BY ...] [LIMIT ...]
假设一页里面就显示3条记录:
-
limit只取前3条
相当于 limit 3 offset 0;
-
offset从下标为3的记录开始(下标从0开始),再往后找3条
-
limit同样可以搭配条件,以及order by等操作来组合使用
查找出总成绩前三名的姓名显示出来:

9、总结
select * from表名,对于生产环境的数据库来说,非常危险
而危险不危险,看的是返回结果的数据量是多还是少,返回的数据量少,其实就还好,返回的数据量多,就比较危险
如何才能让sql不那么危险:
1、限制更严格的条件 where
2、使用 limit 更稳妥的限制
三、修改(Update)
1、语法
update 表名 set 列名 = 值, 列名 = 值 where 条件;
注意:
insert 和表名之间,有个 into
select 和表名之间,有个 from
update 和表名之间,啥都没有
set 不能省略
where 条件 指的是针对哪些行进行修改,符合条件的行就会修改,不符合条件的就不变
如果这里的 where 省略了,就是修改所有记录
这里的 where 和前面 select 那里的 where 是一样
另外,除了 where 之外,像 order by 和 limit 也是可以使用
update是会修改数据库服务器上面的原始数据的
- 案例:
-- 将孙悟空同学的数学成绩变更为 80 分
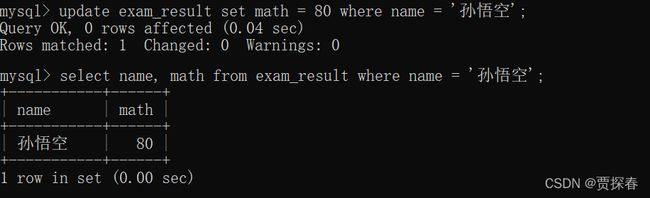
UPDATE exam_result SET math = 80 WHERE name = '孙悟空';
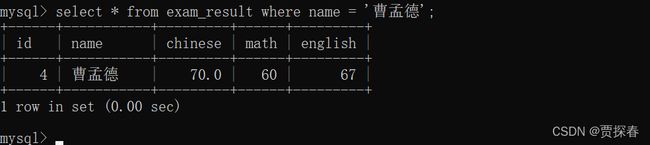
-- 将曹孟德同学的数学成绩变更为 60 分,语文成绩变更为 70 分
UPDATE exam_result SET math = 60, chinese = 70 WHERE name = '曹孟德';
-- 将总成绩倒数前三的 3 位同学的数学成绩加上 30 分
UPDATE exam_result SET math = math + 30 ORDER BY chinese + math + english LIMIT
3;
这里就需要根据总成绩排序,同时limit筛选前三再去执行这里的+ 30操作
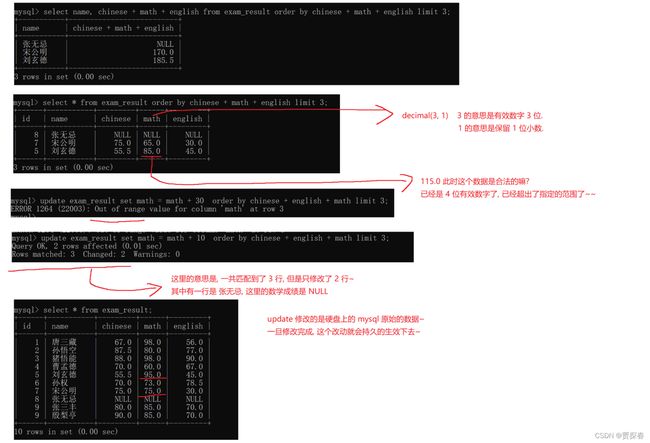
-- 将所有同学的语文成绩更新为原来的 2 倍
UPDATE exam_result SET chinese = chinese * 2;
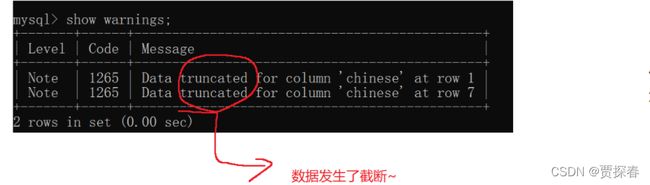
此处受限于数据的范围,直接乘⒉肯定是超出范围,也会修改失败,此处写一个/2

show warings 查看警告
四、删除(Delete)
1、语法
delete from表名where条件;
一旦这里的条件写错了,可能影响范围就会很大如果不写条件,就会把整个表的数据都给删除掉 (这个和drop table 还不一样)
除表中的所有数据,得到一个空的表
如果是 drop table 表都没了,数据也没了
- 案例:
-- 删除孙悟空同学的考试成绩
DELETE FROM exam_result WHERE name = '孙悟空';
-- 删除整张表数据
-- 准备测试表
DROP TABLE IF EXISTS for_delete;
CREATE TABLE for_delete (
id INT,
name VARCHAR(20)
);
-- 插入测试数据
INSERT INTO for_delete (name) VALUES ('A'), ('B'), ('C');
-- 删除整表数据
DELETE FROM for_delete;

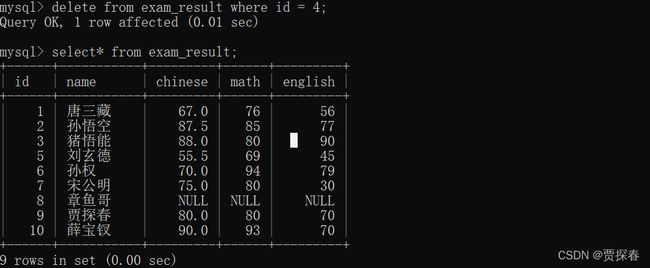
-- 删除 id 为 4 的一行
delete from exam_result where id = 4;