python 机器学习——特征筛选实现
特征筛选实现
- 1、特征筛选
- 2、特征筛选具体案例操作
- 参考文献:
1、特征筛选
(1)含义
特征筛选/选择( Feature Selection )也称特征子集选择( Feature Subset Selection , FSS ),或属性选择( Attribute Selection )。是指从已有的 M 个特征( Feature )中选择 N 个特征使得系统的特定指标最优化,是从原始特征中选择出一些最有效特征以降低数据集维度的过程,是提高学习算法性能的一个重要手段,也是模式识别中关键的数据预处理步骤。对于一个学习算法来说,好的学习样本是训练模型的关键。
(2)目的
在有限的样本数目下,用大量的特征来设计分类器计算开销太大而且分类性能差。特征筛选可去掉一些冗余特征,提高模型的精度,减少计算量,减少特征数量、降维,使模型泛化能力更强,减少过拟合。
(3)一些区别
① 特征筛选与特征提取区别:特征提取 ( Feature extraction )是指利用已有的特征计算出一个抽象程度更高的特征集,也指计算得到某个特征的算法。
② 特征筛选和 PCA 的区别:对于 PCA 而言,我们经常无法解释重建之后的特征,而特征筛选不存在对特征数值的修改,而更加侧重于寻找那些对模型的性能提升较大的少量特征。
注意:降维和特征选择都是为了使数据维度降小,但实际上两者的区别很大,它们的本质是完全不同的: 降维本质上是从一个维度空间映射到另一个维度空间,特征的多少别没有减少,当然在映射的过程中特征的数值也会相应的变化(在这个过程中,特征发生了根本性的变化,原始的特征消失了);而特征选择就是单纯地从提取到的所有特征中选择部分特征作为训练集特征,特征在选择前和选择后不改变值,但是选择后的特征维数肯定比选择前小,因为只选择了其中的一部分特征(没有被舍弃的特征没有发生任何变化)。
将高维空间的样本通过映射或者是变换的方式转换到低维空间,达到降维的目的,然后通过特征筛选删选掉冗余和不相关的特征来进一步降维。
(4)特征选取的原则
① 获取尽可能小的特征子集
② 不显著降低分类精度
③ 不影响类分布
④ 特征子集应具有稳定适应性强等特点
在筛选特征时需要注意:处理的数据类型、处理的问题规模、问题需要分类的数量、对噪声的容忍能力和无噪声环境下,产生稳定性好、最优特征子集的能力。
(5)特征获取方法
假设原始特征集中有 n 个特征(也称输入变量),那么存在 2 n − 1 2^n-1 2n−1个可能的非空特征子集。搜索策略就是为了从包含 2 n − 1 2^n-1 2n−1 个候选解的搜索空间中寻找最优特征子集而采取的搜索方法。按照特征子集的形成方式可以分为三种:穷举法( exhaustion )、启发法( heuristic )和随机法( random )。
1)穷举式搜索它可以搜索到每个特征子集。缺点是它会带来巨大的计算开销,尤其当特征数较大时,计算时间很长。
2)序列搜索它避免了简单的穷举式搜索,在搜索过程中依据某种次序不断向当前特征子集中添加或剔除特征,从而获得优化特征子集。比较典型的序列搜索算法如:前向后向搜索、等。序列搜索算法较容易实现,计算复杂度相对较小,但容易陷入局部最优。
3)随机搜索由随机产生的某个候选特征子集开始,依照一定的启发式信息和规则逐步逼近全局最优解。例如:遗传算法(Genetic Algorithm, GA)、模拟退火算法(SimulatedAnnealing, SA)、粒子群算法(Particl Swarm Optimization,PSO)和免疫算法(Immune Algorithm, IA)等。
综上穷举法需要遍历特征空间中所有的特征组合,所以方法复杂度最大,实用性不强;启发法通过采用期望的人工机器调度规则,重复迭代产生递增的特征子集,复杂度略低于穷举法,但是只能获取近似最优解;随即方法分为完全随机方法和概率随机方法两种,对参数设置的依赖性较强。
2、特征筛选具体案例操作
以“泰坦尼克号沉船事故”数据集为例:
# 导入 pandas 并且更名为 pd。
import pandas as pd
# 从互联网读取 titanic 数据。
titanic = pd.read_csv('http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt')
# 分离数据特征与预测目标。
y = titanic['survived']
X = titanic.drop(['row.names', 'name', 'survived'], axis = 1)
# 对对缺失数据进行填充。
X['age'].fillna(X['age'].mean(), inplace=True)
X.fillna('UNKNOWN', inplace=True)
# 分割数据,依然采样 25% 用于测试。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=33)
# 类别型特征向量化。
from sklearn.feature_extraction import DictVectorizer
vec = DictVectorizer()
X_train = vec.fit_transform(X_train.to_dict(orient='record'))
X_test = vec.transform(X_test.to_dict(orient='record'))
# 输出处理后特征向量的维度。
print(len(vec.feature_names_))

我们可以看到特征向量的维度为474.
# 使用决策树模型依靠所有特征进行预测,并作性能评估。
from sklearn.tree import DecisionTreeClassifier
dt = DecisionTreeClassifier(criterion='entropy')
dt.fit(X_train, y_train)
dt.score(X_test, y_test)

使用所有特征建立决策树得到的测试集准确率为0.8267
# 从 sklearn 导入特征筛选器。
from sklearn import feature_selection
# 筛选前 20% 的特征,使用相同配置的决策树模型进行预测,并且评估性能。
fs = feature_selection.SelectPercentile(feature_selection.chi2, percentile=20)
X_train_fs = fs.fit_transform(X_train, y_train)
dt.fit(X_train_fs, y_train)
X_test_fs = fs.transform(X_test)
dt.score(X_test_fs, y_test)

筛选前 20% 的特征建立决策树得到的测试集准确率为0.8298
# 通过交叉验证(下一节将详细介绍)的方法,按照固定间隔的百分比筛选特征,并作图展示性能随特征筛选比例的变化。
from sklearn.model_selection import cross_val_score
import numpy as np
percentiles = range(1, 100, 2)
results = []
for i in percentiles:
fs = feature_selection.SelectPercentile(feature_selection.chi2, percentile = i)
X_train_fs = fs.fit_transform(X_train, y_train)
scores = cross_val_score(dt, X_train_fs, y_train, cv=5)
results = np.append(results, scores.mean())
print(results)
# 找到体现最佳性能的特征筛选的百分比。
opt = np.where(results == results.max())[0]
print('Optimal number of features %d' %percentiles[int(opt)])
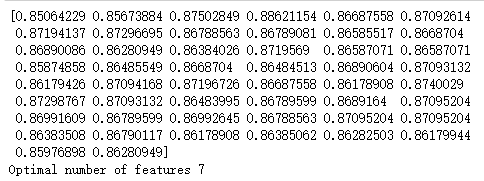
我们可以看到筛选7%的特征能够使得我们的训练集准确率达到最高。
import pylab as pl
pl.plot(percentiles, results)
pl.xlabel('percentiles of features')
pl.ylabel('accuracy')
pl.show()

# 使用最佳筛选后的特征,利用相同配置的模型在测试集上进行性能评估。
from sklearn import feature_selection
fs = feature_selection.SelectPercentile(feature_selection.chi2, percentile=7)
X_train_fs = fs.fit_transform(X_train, y_train)
dt.fit(X_train_fs, y_train)
X_test_fs = fs.transform(X_test)
dt.score(X_test_fs, y_test)

由上面的输出结果可知:
① 经过初步的特征处理后,最终的训练与测试数据均有 474 个维度的特征;
② 如果直接使用全部 474 个维度的特征用于训练决策树模型进行分类预测,那么模型在测试集上的准确性约为 81.76% ;
③ 如果筛选前 20% 维度的特征,在相同的模型配置下进行预测,那么在测试集上表现的准确性约为 82.37% ;
④ 如果按照固定的间隔采用不同百分比的特征进行训练与测试,通过交叉验证得出的准确性有着很大波动,并且最好的模型性能表现在选取前 7% 的维度的特征的时候;
⑤ 如果使用前 7% 的维度的特征,那么最终决策树模型可以在该分类预测任务的测试集上表现出 85.71% 的准确性,比起最初使用全部特征的模型性能高出接近 4 个百分比。
参考文献:
[1] 范淼,李超.Python 机器学习及实践[M].清华大学出版社, 北京, 2016.
[2] JasonDing.http://www.jianshu.com/p/ab697790090f
[3] 苍梧.http://www.cnblogs.com/heaad/archive/2011/01/02/1924088.html