机器学习读书笔记:支持向量机
文章目录
- 支持向量
- 怎么找这个“超平面”
-
- 简化
- 对偶问题求解
- SMO
- 软间隔
- 简化版SMO代码
- 其他
-
- 核函数
- SVM回归
支持向量
整篇文章大量参考小白学习机器学习,在这里先感谢作者。
支持向量机里最难理解的部分之一就是搞清楚什么是支持向量。我尽量用比较通俗易懂的方式来讲讲我自己的理解。
总的来说,支持向量机就是要通过找支持向量来找划分超平面。
以二维平面的样本来做例子,高维数据样本请自行想象和推理。并且SVM最常用和适用的场景是做二分类,如果是多分类的话需要做一些其他的处理(可以用之前的那种方式,参考之前的博客),处理回归问题(连续值)的话后面也有涉及。
假设所有的样本 X = x 1 , x 2 . . . x n , x i = ( x i 1 , x i 2 ) X = {x_1, x_2...x_n}, x_i = (x_{i1},x_{i2}) X=x1,x2...xn,xi=(xi1,xi2),每个样本两个属性。 y ∈ ( + 1 , − 1 ) y\in(+1, -1) y∈(+1,−1)。
假设上述的样本集在二维坐标系里面的分布如下所示:
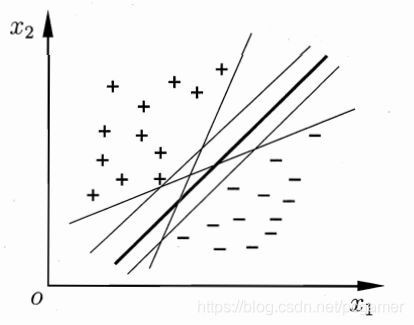
从图中可以看出,这些样本是线性可分的,可以用一条直线分开,而且是无限多条直线,这些直线可以用
w x + b = 0 wx + b = 0 wx+b=0
这样一个方程来表达,由 w w w和 b b b来确定这条直线的斜率和相对原点的偏移量。
那么推广到多维空间的话,这个方程就变成了:
w T x + b = 0 w^Tx+b=0 wTx+b=0
其中的 w T w^T wT就是表示向量。从距离上看,到这个超平面距离等于1的点,也就是恰好等于 y y y的点就是样本点中的支持向量,其他样本点的结果都会大于1。
我们需要这条分界线(超平面)最好是离两边的样本,也就是每类样本距离都远一点,这样的话,泛化误差会好一些。不会出现一点抖动就分类错误。所以,这个分界线是最好在中间位置,如下图所示:

也就是找到最中间的那个分界线。假设存在了这条分界线,所有样本点到这条分界线的距离可以用下面这个公式来计算(至于为什么,自己去看线性代数和解析几何啥的):
r i = ∣ w i T x i + b ∣ ∣ ∣ w ∣ ∣ r_i = \frac{|w_i^Tx_i+b|}{||w||} ri=∣∣w∣∣∣wiTxi+b∣
其中 ∣ ∣ w ∣ ∣ ||w|| ∣∣w∣∣表示向量 w w w的范数,一般就是 w 1 2 + w 2 2 + . . . + w n 2 \sqrt{w_1^2+w_2^2+...+w_n^2} w12+w22+...+wn2。
然后,所有样本点中到这条分界线最近的那些样本,也就是我们这篇文章的重点:支持向量。
支持向量用公式表示的话就是:
γ = min i = 1 , 2... m r i \gamma = \min_{i=1,2...m}r^i γ=i=1,2...mminri
很明显,对于每一条分界线或者超平面,同一个样本集 D D D都会得到不同支持向量 γ \gamma γ。支持向量机模型的目的就是找到最合适的分界线或者超平面,这个超平面的特征就是使得支持向量到这个分界面的距离最大,也就是上文说到的,这个分界面到两个类别都比较远(公式1)。
max w , b γ s . t . y i ( w x i + b ∣ ∣ w ∣ ∣ ) ≥ γ \max_{w,b}\gamma\\s.t. y_i(\frac{wx_i+b}{||w||}) \geq\gamma w,bmaxγs.t.yi(∣∣w∣∣wxi+b)≥γ
优化项 max w , b γ \max_{w,b}\gamma maxw,bγ比较好理解,也就是找到一个 w w w和 b b b来确定一个分界面,使得支持向量们到分界面的距离 γ \gamma γ最大。其中的约束条件就是说所有的点到平面的距离都应该大于等于这个距离 γ \gamma γ。
有些地方的这个约束条件是写的:
s . t . ( w x i + b ∣ ∣ w ∣ ∣ ) ≥ γ s.t.(\frac{wx_i+b}{||w||}) \geq \gamma s.t.(∣∣w∣∣wxi+b)≥γ
我的理解是 y i y_i yi反正是只能取值1或者-1,而在上图里面, y i = 1 y_i=1 yi=1的时候, w x i + b ≥ γ wx_i+b \geq \gamma wxi+b≥γ,也就是说分界线 w x + b = 0 wx+b=0 wx+b=0把整个空间划分成了两个部分,一个是大于0,一个是小于0。所以 y i ( w x i + b ) y_i(wx_i+b) yi(wxi+b)总是可以保证符号为正,而 y i y_i yi就可以忽略了。
怎么找这个“超平面”
实际上不应该叫做怎么找支持向量,应该是来确定这个超平面的两个参数 w w w和 b b b。
这里还是要简单描述一下后面的推导过程,因为SVM的整个过程就是数学推导的过程。
简化
把公式一拿出来研究一下:
首先,那个约束条件来简化一下:
- 不等式两边除以 γ \gamma γ,变成 y i ( w x i + b ∣ ∣ w ∣ ∣ γ ) ≥ 1 y_i(\frac{wx_i+b}{||w||\gamma}) \geq 1 yi(∣∣w∣∣γwxi+b)≥1。
- 展开一下,变成 y i ( w x i ∣ ∣ w ∣ ∣ γ + b ∣ ∣ w ∣ ∣ γ ) ≥ 1 y_i(\frac{wx_i}{||w||\gamma} + \frac{b}{||w||\gamma}) \geq 1 yi(∣∣w∣∣γwxi+∣∣w∣∣γb)≥1。
- 上面的 ∣ ∣ w ∣ ∣ ||w|| ∣∣w∣∣和 γ \gamma γ都是标量,可以把值吸入到向量 w w w和 b b b中,这就和x本身代表了一个变量,x和x/2是一个意思一样。这样就把公式变成了 y i ( w x i + b ) ≥ 1 y_i(wx_i+b)\geq1 yi(wxi+b)≥1
然后,再把那个优化项拿出来简化一下:
1. max w , b γ \max_{w,b}\gamma maxw,bγ展开一下变成 max w , b ∣ w i T x i + b ∣ ∣ ∣ w ∣ ∣ \max_{w,b}\frac{|w_i^Tx_i+b|}{||w||} maxw,b∣∣w∣∣∣wiTxi+b∣
- 最大化 γ \gamma γ的话,就可以最大化 1 ∣ ∣ w ∣ ∣ \frac{1}{||w||} ∣∣w∣∣1,或者说最小化 ∣ ∣ w 2 ∣ ∣ ||w^2|| ∣∣w2∣∣
- 加上一个1/2,也就是最小化 1 2 ∣ ∣ w 2 ∣ ∣ \frac{1}{2}||w^2|| 21∣∣w2∣∣,这是因为后面要求导,直接把指数的2弄下来乘以1/2,就不需要写了。
最后,这个公式一就变成了(公式2):
min w , b 1 2 ∣ ∣ w 2 ∣ ∣ s . t . y i ( w i T x i + b ) ≥ 1 \min_{w,b}\frac{1}{2}||w^2|| \\ s.t. y_i(w_i^Tx_i+b)\ge 1 w,bmin21∣∣w2∣∣s.t.yi(wiTxi+b)≥1
对偶问题求解
SVM里求解这个二次规划问题是使用朗格朗日算子来进行计算,本人对拉格朗日算子是学过,考过,然后就直接过了。所以我差不多能理解个大概,知道是在干什么,怎么干成的,为什么能干成,那就不知道了。
- 用上一个朗格朗日算子 α i \alpha_i αi的向量,就可以把优化问题转换成一个等价的问题:将优化项和约束项放在一个式子里去求解。上面的公式2增加朗格朗日算子之后变成(公式3):
L ( w , b , α ) = 1 2 ∣ ∣ w 2 ∣ ∣ − ∑ i = 1 N α i ( y i ( w x i + b ) − 1 ) L(w,b,\alpha) = \frac{1}{2}||w^2|| - \sum_{i=1}^N{\alpha_i(yi(wx_i+b) - 1)} L(w,b,α)=21∣∣w2∣∣−i=1∑Nαi(yi(wxi+b)−1)
也就是说把求解公式2中的极值问题改成了求解这个公式3–拉格朗日函数的极值。
-
我们最初的问题是求最小值。再来看一下这个公式3,这个函数应该在可行解区域内与原目标函数完全一致,而在可行解区域外的数值非常大,甚至是无穷大,那么这个没有约束条件的新目标函数的优化问题就与原来有约束条件的原始目标函数的优化问题等价。那么怎么令这个函数达到这个目标呢?从可行解区域入手,也就是约束条件入手。
- 先再准备一个函数: θ ( w ) = max α i ≥ 0 L ( w , b , α ) \theta(w) = \max_{\alpha_i\ge0}{L(w,b,\alpha)} θ(w)=maxαi≥0L(w,b,α)
- 假设样本不满足约束条件,也就是 y i ( x i T + b ) < 1 y_i(x_i^T+b)<1 yi(xiT+b)<1,此时,假设将 α i \alpha_i αi设置为无穷大,那么函数 L ( w , b , α ) L(w,b,\alpha) L(w,b,α)的后面的部分就是负无穷大, y i ( w x i + b ) − 1 < 0 y_i(wx_i+b) - 1 < 0 yi(wxi+b)−1<0,一个负数乘以无穷大就是负无穷大,再弄个 - 号就是无穷大了。那么此时函数 θ ( w ) \theta(w) θ(w)也就是无穷大了。
- 假设样本满足了约束条件,也就是 y i ( x i T + b ) ≥ 1 y_i(x_i^T+b)\ge1 yi(xiT+b)≥1,此时, θ ( w ) \theta(w) θ(w)就等于 1 2 ∣ ∣ w ∣ ∣ 2 \frac{1}{2}||w||^2 21∣∣w∣∣2,因为什么呢,在这种情况下, α ≥ 0 \alpha \ge0 α≥0, y i ( x i T + b ) − 1 ≥ 0 y_i(x_i^T+b) - 1\ge0 yi(xiT+b)−1≥0,那么后面无论如何都是一个大于等于0的数,而 θ ( w ) \theta(w) θ(w)的定义就是 m a x L maxL maxL,那么最大是啥呢,就是后面那一截等于0的情况下, L L L能取得最大值,所以 θ ( w ) = 1 2 ∣ ∣ w ∣ ∣ 2 \theta(w) = \frac{1}{2}||w||^2 θ(w)=21∣∣w∣∣2
-
所以说,从上面的公式3,经过第二步的变换(不知道什么样的脑袋才能想出这个来),新的目标函数就变成了:
θ ( w ) = { 1 2 ∣ ∣ w ∣ ∣ 2 x 满 足 约 束 + ∞ x 不 满 足 约 束 \theta(w)=\begin{cases}\frac{1}{2}||w||^2 x满足约束 \\ +\infin x不满足约束 \end{cases} θ(w)={21∣∣w∣∣2x满足约束+∞x不满足约束 -
在 x x x满足要求的情况下,我们得到了一个更简单的函数形式 θ ( w ) \theta(w) θ(w),根据第二步,我们是要求解原函数的最小值,经过等价之后,相当于要求解 min w θ ( w ) \min_{w}\theta(w) minwθ(w),也就是满足函数 θ ( w ) \theta(w) θ(w)的最小的 w w w值。也就是
min w θ ( w ) = min w max α i ≥ 0 L ( w , b , α ) \min_w{\theta(w)} = \min_w{\max_{\alpha_i\geq0}{L(w,b,\alpha)}} wminθ(w)=wminαi≥0maxL(w,b,α) -
继续转换成更容易求解的方式:根据拉格朗日函数对偶性,将最小和最大的位置交换一下(至于为什么有对偶性,我是忘记了,不纠结这个东西),优化的函数就变成对偶问题(公式4):
max α i ≥ 0 min w L ( w , b , α ) \max_{\alpha_i\geq0}{\min_w{L(w,b,\alpha)}} αi≥0maxwminL(w,b,α)
不过这里要满足这个对偶性,也就是这个max和min可以互换需要满足两个条件:- 函数 L ( w , b , α ) L(w,b,\alpha) L(w,b,α)是凸函数
- 满足KKT条件(咱也不懂啥是KKT,既然大佬说满足就满足吧)
-
对于公式4,先看里面的一部分
min w L ( w , b , α ) = min w 1 2 ∣ ∣ w ∣ ∣ 2 − ∑ i = 1 N α i ( y i ( w x i + b ) − 1 ) \min_w{L(w,b,\alpha)} = \min_w\frac{1}{2}||w||^2 - \sum_{i=1}^N{\alpha_i(yi(wx_i+b) - 1)} wminL(w,b,α)=wmin21∣∣w∣∣2−i=1∑Nαi(yi(wxi+b)−1)
先假设其中的 α \alpha α为常量,将函数 L L L对 w w w和 b b b求偏导,令偏导的结果等于0,这样求出来的就是令函数 L L L取得最小值的 w w w和 b b b。得到结果是:
w = ∑ i = 1 N α i y i x i 0 = ∑ i = 1 N α i y i w=\sum_{i=1}^N{\alpha_iy_ix_i} \\ 0=\sum_{i=1}^N{\alpha_iy_i} w=i=1∑Nαiyixi0=i=1∑Nαiyi
b b b直接没有了,因为求导的时候会得到 ∂ L ∂ w = ∑ i = 1 N α i y i b = 0 \frac{\partial L}{\partial w} = \sum_{i=1}^N{\alpha_iyib = 0} ∂w∂L=∑i=1Nαiyib=0,如果b不为0,那么就是 0 = ∑ i = 1 N α i y i 0=\sum_{i=1}^N{\alpha_iy_i} 0=∑i=1Nαiyi -
把上面那两个式子代入到公式4里面去求解 α \alpha α,公式4经过一通变形转换就会变成:
∑ i = 1 N α i − 1 2 ∑ i , j = 1 N α i α j y i y j x i T x j \sum_{i=1}^N{\alpha_i} - \frac{1}{2}\sum_{i,j=1}^N{\alpha_i\alpha_jy_iy_jx_i^Tx_j} i=1∑Nαi−21i,j=1∑NαiαjyiyjxiTxj
我理解里面 α i α j \alpha_i\alpha_j αiαj和 y i y j y_iy_j yiyj是指每个样本之间的内积。然后,再在这个式子前面加上一个max,然后再加上两个约束条件就是各种转换之后的优化函数了(公式5):
max α ∑ i = 1 N α i − 1 2 ∑ i , j = 1 N α i α j y i y j x i T x j s . t . α ≥ 0 ∑ i = 1 N α i y i = 0 \max_{\alpha}{\sum_{i=1}^N{\alpha_i} - \frac{1}{2}\sum_{i,j=1}^N{\alpha_i\alpha_jy_iy_jx_i^Tx_j}} \\ s.t. \alpha \ge 0 \\ \sum_{i=1}^N{\alpha_iy_i} = 0 αmaxi=1∑Nαi−21i,j=1∑NαiαjyiyjxiTxjs.t.α≥0i=1∑Nαiyi=0 -
然后,使用SMO方法来求解这个函数中的 α \alpha α,进而再计算出 w w w和 b b b。
SMO
SMO全称为序列最小优化法:Sequential Minimal Optimizaion。是针对SVM算法的一种数据训练方法,通过不同的迭代计算去算出公式5中合适的一系列 α \alpha α。中心思想就是在一系列的 α \alpha α中,每次挑选出两个参数: α i \alpha_i αi和 α j \alpha_j αj,根据约束条件和优化函数计算出这两个参数的调整值,或者是最新值。
先看一下怎么个计算法:
-
假设算法初始的 α \alpha α是随机值,注意初始化的随机值需要大于等于0(约束条件,N个样本对应N个 α \alpha α值。
-
根据某种策略(后面提到一种启发式的方法,这里先当时随机)挑选出两个 α \alpha α值,比如就是 α i \alpha_i αi和 α j \alpha_j αj。那么对应的样本就是 ( x i , y i ) (x_i, y_i) (xi,yi)和 ( x j , y j ) (x_j, y_j) (xj,yj)。
-
因为存在条件 ∑ i = 1 N α i y i = 0 \sum_{i=1}^N{\alpha_iy_i} = 0 ∑i=1Nαiyi=0,那么我们可以得知 α i y i + α j y j = c \alpha_iy_i+\alpha_jy_j = c αiyi+αjyj=c(公式6), c就等于其他的 α \alpha α和 y y y的和: ∑ k , k ≠ i , j α k y k = − c \sum_{k,k\neq i,j}{\alpha_ky_k} = -c ∑k,k=i,jαkyk=−c。
-
把公式6两边都乘以 y i y_i yi,就变成 α i y i y i + α j y j y i = c y i \alpha_iy_iy_i+\alpha_jy_jy_i = cy_i αiyiyi+αjyjyi=cyi,因为 y ∈ ( 1 , − 1 ) y \in (1, -1) y∈(1,−1),所以 y i y i y_iy_i yiyi肯定等于1,再令 s = y i y j s=y_iy_j s=yiyj, γ = c y i \gamma = cy_i γ=cyi,公式6可以变换成 α i = γ − s α j \alpha_i = \gamma - s\alpha_j αi=γ−sαj(公式7)。
-
把公式7代入到上面的优化函数,也就是公式7中,会得到一个很长的公式,然后针对这个公式求偏导之后就会得到另外一个很长的公式(里面的 α 2 n e w \alpha_2^{new} α2new就是我么你这里的 α i \alpha_i αi,根据这两个样本训练得出的值),令求完偏导后等于0就可以得到:
α j n e w = y j ( y j − y i + y i γ ( x i T x i − x i T x j ) + v i − v j ) x i T x i + x j T x j − 2 x i T x j \alpha_j^{new}=\frac{y_j(y_j-y_i+y_i\gamma(x_i^Tx_i-x_i^Tx_j)+v_i-v_j)}{x_i^Tx_i+x_j^Tx_j-2x_i^Tx_j} αjnew=xiTxi+xjTxj−2xiTxjyj(yj−yi+yiγ(xiTxi−xiTxj)+vi−vj) -
然后再令 E i = f ( x i ) − y i , 其 中 f ( x i ) = x I T + b E_i = f(x_i) - y_i, 其中f(x_i) = x_I^T+b Ei=f(xi)−yi,其中f(xi)=xIT+b, 令 η = x i T x i + x j T x j − 2 x i T x j \eta = x_i^Tx_i + x_j^Tx_j - 2xi^Tx_j η=xiTxi+xjTxj−2xiTxj,就可以得到 α i \alpha_i αi的计算方式: a i n e w = a i o l d + y j ( E i − E j ) η a_i^{new} = a_i^{old} + \frac{y_j(E_i-E_j)}{\eta} ainew=aiold+ηyj(Ei−Ej)。也就是说,每次迭代,都可以在原有的基础上进行更新。其中:
E E E就是误差, η \eta η就是学习率。
-
根据 α j o l d = γ − s α i o l d \alpha_j^{old}=\gamma-s\alpha_i^{old} αjold=γ−sαiold和 α j n e w = γ − s α i n e w \alpha_j^{new}=\gamma-s\alpha_i^{new} αjnew=γ−sαinew,两个公式相减,可以得到 α j n e w = α i o l d + y i y j ( α i o l d − α i n e w ) \alpha_j^{new} = \alpha_i^{old} + y_iy_j(\alpha_i^{old}-\alpha_i^{new}) αjnew=αiold+yiyj(αiold−αinew)
-
回到第二步,这里的某种策略,一般可以选择两个差异较大 α \alpha α,因为两个差别较大的值调整,对目标函数的改变较大,更加容易收敛。
-
上面迭代结束的条件一般可以设置为,整体误差小于某个值,或者规定迭代多少次。
-
接下来就是计算 b b b,前面求偏导之后,没有获得 b b b与 α \alpha α之间的关系。这里可以根据其中的一个KKT条件来求解 b b b: α i ( y i f ( x i ) − 1 ) = 0 \alpha_i(y_if(x_i)-1) = 0 αi(yif(xi)−1)=0,我们有条件 α ≥ 0 \alpha\ge0 α≥0。假设 α = 0 \alpha=0 α=0,不管样本取啥值,都可以满足这个条件,但是,如果某个样本所对应的 α = 0 \alpha = 0 α=0,在公式5中就不会起到作用,也就是可以不用考虑这种样本。所以只考虑 α ≠ 0 \alpha\neq0 α=0的情况,那么就是 y i ( w T x i + b ) = 1 y_i(w^Tx_i+b) = 1 yi(wTxi+b)=1(公式8)。这个里面的 y i y_i yi不是等于-1,就是等于1。所以 w T x i + b w^Tx_i+b wTxi+b也是等于1或者-1,符号与 y i y_i yi相同。这样的样本实际上就是在最大间隔上,也就是上面说到的支持向量。
-
假设讨论的样本中, i = 1 , j = 2 i=1, j=2 i=1,j=2。把上面的公式8两边乘以 y 1 y_1 y1,就会变成 w x 1 + b = y 1 wx_1+b = y1 wx1+b=y1,而 w = ∑ i = 1 N α i y i x i w=\sum_{i=1}^N{\alpha_iy_ix_i} w=∑i=1Nαiyixi,所以可以得到 ∑ i = 1 N α i y i x i x 1 + b = y 1 \sum_{i=1}^N{\alpha_iy_ix_i}x_1+b=y_1 ∑i=1Nαiyixix1+b=y1。因为我们已经获得了 α 1 \alpha_1 α1和 α 2 \alpha_2 α2的两个新值,所以,需要将1和2从前面的求和中拆出来,再去更新参数 b b b。也就是公式:
b 1 n e w = y 1 − ∑ i = 3 N α i y i x i T x 1 − α 1 n e w y 1 x 1 T x 1 − α 2 n e w y 2 x 2 T x 2 b_1^{new}=y_1-\sum_{i=3}^N\alpha_iy_ix_i^Tx_1-\alpha_1^{new}y_1x_1^Tx_1-\alpha_2^{new}y_2x_2^Tx_2 b1new=y1−i=3∑NαiyixiTx1−α1newy1x1Tx1−α2newy2x2Tx2
-
根据上面的公式,前面的两项 y 1 − ∑ i = 3 N α i y i x i T x 1 y_1-\sum_{i=3}^N\alpha_iy_ix_i^Tx_1 y1−∑i=3NαiyixiTx1又可以变换为: − E 1 + α 1 o l d y 1 x 1 T x 1 + α 2 o l d y 2 x 2 T x 2 -E_1+\alpha_1^{old}y_1x_1^Tx_1+\alpha_2^{old}y_2x_2^Tx_2 −E1+α1oldy1x1Tx1+α2oldy2x2Tx2,然后,就可以得到
b 1 n e w = b o l d − E 1 − y 1 ( α 1 n e w − α 1 o l d ) x 1 T x 1 − y 2 ( α 2 n e w − α 2 o l d ) x 2 T x 1 b_1^{new} = b^{old}-E_1-y_1(\alpha_1^{new}-\alpha_1{old})x_1^Tx_1-y_2(\alpha_2^{new}-\alpha_2{old})x_2^Tx_1 b1new=bold−E1−y1(α1new−α1old)x1Tx1−y2(α2new−α2old)x2Tx1
同样,可得到:
b 2 n e w = b o l d − E 2 − y 1 ( α 1 n e w − α 1 o l d ) x 1 T x 2 − y 2 ( α 2 n e w − α 2 o l d ) x 2 T x 2 b_2^{new} = b^{old}-E_2-y_1(\alpha_1^{new}-\alpha_1{old})x_1^Tx_2-y_2(\alpha_2^{new}-\alpha_2{old})x_2^Tx_2 b2new=bold−E2−y1(α1new−α1old)x1Tx2−y2(α2new−α2old)x2Tx2
如果两个样本都是支持向量,那么 b 1 n e w = b 2 n e w b_1^{new} = b_2^{new} b1new=b2new,随便取一个就行,如果不相等,取均值: ( b 1 n e w + b 2 n e w ) / 2 (b_1^{new}+b_2^{new})/2 (b1new+b2new)/2 -
迭代求出 b b b和 α \alpha α后,就可以可以根据 w = ∑ i = 1 N α i y i x i w=\sum_{i=1}^N{\alpha_iy_ix_i} w=∑i=1Nαiyixi计算得到最后一个参数 w w w,最终确认模型。
软间隔
看下下面这样的分布图:

假设一个超平面可以将绝大部分的样本分开,只有少数几个样本没法分开。其实我们是接受这样的超平面划分的,但是上面提到的“硬间隔”就没法进行这样的划分,所以就有这“软间隔”这一说。
“软间隔”的话,也就是某些样本不满足条件 y i f ( x i ) ≥ 1 y_if(x_i)\ge1 yif(xi)≥1。当然,我们希望这样的样本越少越好。那么优化的目标函数就变成(公式10):
min w , b 1 2 ∣ ∣ w ∣ ∣ 2 + C ∑ i = 1 N ρ 0 / 1 ( y i ( w T x i + b ) − 1 ) \min_{w,b}{\frac{1}{2}||w||^2}+C\sum_{i=1}^N{\rho_{0/1}(y_i(w^Tx_i+b)-1)} w,bmin21∣∣w∣∣2+Ci=1∑Nρ0/1(yi(wTxi+b)−1)
就是在原优化函数的后面加了一截,这一截里面的C表示一个大于0的常数, ρ \rho ρ为一个损失函数:
ρ = { 1 , i f z < 0 0 , o t h e r w i s e \rho = \begin{cases}1, if z<0 \\ 0, otherwise\end{cases} ρ={1,ifz<00,otherwise
-
如果C为无穷大,那么就要求函数 ρ \rho ρ的取值必须为0,因为如果 ρ \rho ρ不为0,这个函数就没有解了,函数的后面一截就是无穷大,没法求最小值。如果 ρ \rho ρ要为0,就必须保证自变量 Z ≥ 0 Z \ge0 Z≥0,也就是说 y i ( w T x i + b ) ≥ 1 y_i(w^Tx_i+b)\ge1 yi(wTxi+b)≥1,也就是样本点都满足条件,那么就是原目标函数。如果C为有限值,就允许某些样本点不满足条件,使得 Z < 0 Z<0 Z<0,这样我们的目标函数才有可能有解。我理解是如果不满足条件的样本越少,后面一截的值就越小,目标函数的解就越容易一点。
-
这里还引入了一个变量,叫做“松弛变量”: ξ , ξ = ρ 0 / 1 ( y i ( w T x i + b ) − 1 ) \xi, \xi=\rho_{0/1}(y_i(w^Tx_i+b)-1) ξ,ξ=ρ0/1(yi(wTxi+b)−1),至于为啥叫松弛变量,就不清楚了。
-
然后针对这个目标函数(公式10)同样的转换成对偶问题的函数,不过这里因为后面有另外一截,所以有两个拉格朗日乘子: α \alpha α和 μ \mu μ。在KKT条件中需要增加两条: μ i ≥ 0 \mu_i\ge0 μi≥0, ξ i μ i = 0 \xi_i\mu_i=0 ξiμi=0。同样,不知道为啥,知道这个结论就好。
-
然后,和硬间隔类似,对对偶问题的 L ( w , b , α , μ , ξ ) L(w,b,\alpha,\mu,\xi) L(w,b,α,μ,ξ)中的 ξ \xi ξ求偏导等于0后可以得到一个条件: C = α i + μ i C=\alpha_i+\mu_i C=αi+μi,也就是说这个常量C由两个朗格朗日乘子确定。
-
因为 α ≥ 0 \alpha\ge0 α≥0, μ ≥ 0 \mu\ge0 μ≥0,所以在求解公式5的时候,需要增加一个条件: C ≥ α i ≥ 0 C\ge\alpha_i\ge0 C≥αi≥0。
-
由上面一堆公式可以推出(各位看官联合上面的一堆公式一起看):若 α i < C \alpha_i
αi<C ,则 μ i > 0 , ( α i + μ i = C ) \mu_i>0, (\alpha_i+\mu_i=C) μi>0,(αi+μi=C),进而有 ξ = 0 \xi=0 ξ=0,所以此时有: y f ( x i ) = 1 yf(x_i)=1 yf(xi)=1,即该样本恰好在最大间隔边界上;若 α i = C \alpha_i=C αi=C,则有 μ i = 0 \mu_i=0 μi=0,此时若 ξ i < = 1 \xi_i<=1 ξi<=1, 则该样本落在最大间隔内部;若 ξ i > 1 \xi_i>1 ξi>1则该样本被错误分类。由此可以看出,软间隔支持向量机的最终模型仅与支持向量有关。 -
根据这里的两个 α \alpha α还有另外的约束,根据硬间隔内容中的第三步里面的公式6,可以分成两种情况,如果 y i ≠ y j y_i\neq y_j yi=yj,那么可以得到 α i o l d − α j o l d = c \alpha_i^{old}-\alpha_j^{old}=c αiold−αjold=c,配合条件 C ≥ α C\ge\alpha C≥α,可以得到图(抄的图,图中的 ζ \zeta ζ就是我公式中的 c c c):

从图中清楚的看出, α \alpha α的最小值 L = m a x ( 0 , − c ) , c < 0 L=max(0,-c), c<0 L=max(0,−c),c<0;最大值为 H = m i n ( C − c , C ) H=min(C-c,C) H=min(C−c,C)
当 y i = y j y_i=y_j yi=yj时,可以得到 α i o l d + α j o l d = c \alpha_i^{old}+\alpha_j^{old}=c αiold+αjold=c,可以得到图:
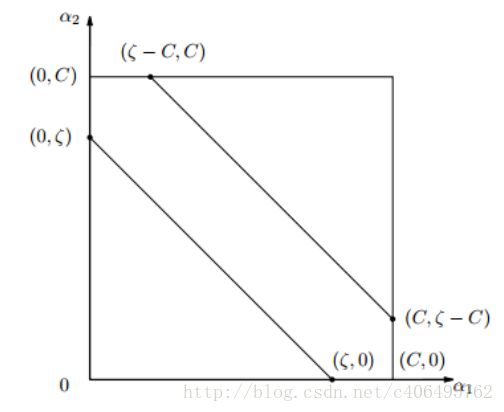
从图中得知, α \alpha α的最小值 L = m a x ( 0 , c − C ) L=max(0,c-C) L=max(0,c−C),最大值 H = m i n ( c , C ) H=min(c,C) H=min(c,C)
在代码中,需要根据 y i , y j y_i, y_j yi,yj的取值来判断最大最小值。如果计算得出的 α \alpha α超过了最大最小值,就直接赋值为最大最小值。
-
其他步骤和硬间隔的步骤一致。
简化版SMO代码
截取的是《机器学习实战》中的代码:
def smoSimple(dataMatIn, classLabels, C, toler, maxIter):
#转换为numpy的mat存储
dataMatrix = np.mat(dataMatIn); labelMat = np.mat(classLabels).transpose()
#初始化b参数,统计dataMatrix的维度
b = 0; m,n = np.shape(dataMatrix)
#初始化alpha参数,设为0
alphas = np.mat(np.zeros((m,1)))
#初始化迭代次数
iter_num = 0
#最多迭代matIter次
while (iter_num < maxIter):
alphaPairsChanged = 0
for i in range(m):
#步骤1:计算误差Ei
fXi = float(np.multiply(alphas,labelMat).T*(dataMatrix*dataMatrix[i,:].T)) + b
Ei = fXi - float(labelMat[i])
#优化alpha,更设定一定的容错率。
if ((labelMat[i]*Ei < -toler) and (alphas[i] < C)) or ((labelMat[i]*Ei > toler) and (alphas[i] > 0)):
#随机选择另一个与alpha_i成对优化的alpha_j
j = selectJrand(i,m)
#步骤1:计算误差Ej
fXj = float(np.multiply(alphas,labelMat).T*(dataMatrix*dataMatrix[j,:].T)) + b
Ej = fXj - float(labelMat[j])
#保存更新前的aplpha值,使用深拷贝
alphaIold = alphas[i].copy(); alphaJold = alphas[j].copy();
#步骤2:计算上下界L和H
if (labelMat[i] != labelMat[j]):
L = max(0, alphas[j] - alphas[i])
H = min(C, C + alphas[j] - alphas[i])
else:
L = max(0, alphas[j] + alphas[i] - C)
H = min(C, alphas[j] + alphas[i])
if L==H: print("L==H"); continue
#步骤3:计算eta
eta = 2.0 * dataMatrix[i,:]*dataMatrix[j,:].T - dataMatrix[i,:]*dataMatrix[i,:].T - dataMatrix[j,:]*dataMatrix[j,:].T
if eta >= 0: print("eta>=0"); continue
#步骤4:更新alpha_j
alphas[j] -= labelMat[j]*(Ei - Ej)/eta
#步骤5:修剪alpha_j
alphas[j] = clipAlpha(alphas[j],H,L)
if (abs(alphas[j] - alphaJold) < 0.00001): print("alpha_j变化太小"); continue
#步骤6:更新alpha_i
alphas[i] += labelMat[j]*labelMat[i]*(alphaJold - alphas[j])
#步骤7:更新b_1和b_2
b1 = b - Ei- labelMat[i]*(alphas[i]-alphaIold)*dataMatrix[i,:]*dataMatrix[i,:].T - labelMat[j]*(alphas[j]-alphaJold)*dataMatrix[i,:]*dataMatrix[j,:].T
b2 = b - Ej- labelMat[i]*(alphas[i]-alphaIold)*dataMatrix[i,:]*dataMatrix[j,:].T - labelMat[j]*(alphas[j]-alphaJold)*dataMatrix[j,:]*dataMatrix[j,:].T
#步骤8:根据b_1和b_2更新b
if (0 < alphas[i]) and (C > alphas[i]): b = b1
elif (0 < alphas[j]) and (C > alphas[j]): b = b2
else: b = (b1 + b2)/2.0
#统计优化次数
alphaPairsChanged += 1
#打印统计信息
print("第%d次迭代 样本:%d, alpha优化次数:%d" % (iter_num,i,alphaPairsChanged))
#更新迭代次数
if (alphaPairsChanged == 0): iter_num += 1
else: iter_num = 0
print("迭代次数: %d" % iter_num)
return b,alphas
其他
核函数
当样本集 D = ( x i , y i ) , i ∈ N D={(x_i,y_i), i\in N} D=(xi,yi),i∈N在 d d d维空间中不是线性可分时,也就是一个超平面无法有效分开这些样本时,可以通过一个函数将样本集从 d d d维升到 d + 1 d+1 d+1维,从而从高维上来进行划分。这个从 d d d维到 d + 1 d+1 d+1维的过程就是通过核函数来实现。
我理解核函数可以形成一个矩阵M,将数据集从一个 n ∗ d n*d n∗d的矩阵乘以这个矩阵M后就可以变成一个新的矩阵 n ∗ ( d + 1 ) n*(d+1) n∗(d+1)。
这个矩阵的样子就是:

核函数有以下几种常用的:

核函数的应用就超出我的数学理解范围了,知道了就好。
SVM回归
使用SVM解决回归问题,也就是连续值得问题,可以参考西瓜书,懒得写了,太累。