MySQL实战:order by 语句怎么优化?

order by是怎么工作的?
CREATE TABLE `person` (
`id` int(11) NOT NULL,
`city` varchar(16) NOT NULL,
`name` varchar(16) NOT NULL,
`age` int(11) NOT NULL,
`addr` varchar(128) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `city` (`city`)
) ENGINE=InnoDB;
explain select city, name, age from person where city = '杭州' order by name limit 1000;

Extra列中有Using filesort说明进行了排序
全字段排序
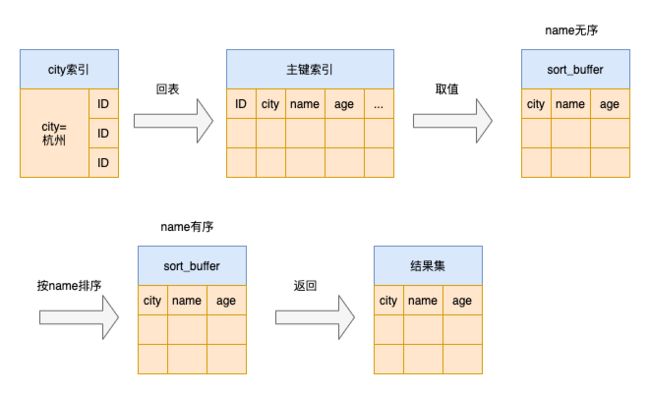
- 初始化 sort buffer,从 city 索引找满足city=杭州条件的主键id
- 根据主键id回表找到对应的记录,取出 name city age 三个字段的值,存入 sort buffer
- 从 city 索引找到下一个记录的主键
- 重复步骤2,3,找到所有满足条件的记录
- 对 sort buffer 中的数据按照字段 name 排序,排序结果取前1000行返回客户端
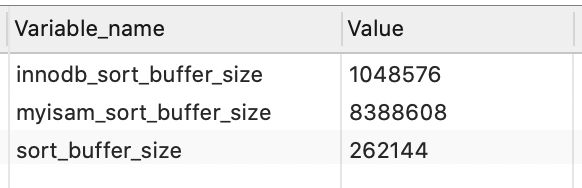
我们可以通过执行如下语句查看sort buffer的大小
show variables like '%sort_buffer%'
我们把这个排序的过程叫做全字段排序
按name排序这个动作,可能在内存中完成,也可能需要使用外部排序。这取决于排序需要的内存大小和 sort_buffer_size(mysql为排序开辟的内存大小,即sort buffer)
如果数据量太大,则需要利用磁盘文件排序
rowid排序
如果查询要返回的字段很多的话,那么sort buffer里面需要放的字段数也很多,此时就会分成很多临时文件,排序的性能会很差
如果单行很大,这个方法效率不够好。
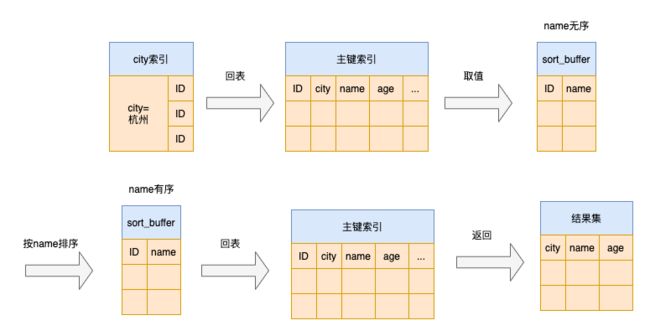
我们把这个排序的过程叫做rowid排序
SET max_length_for_sort_data = 16;
max_length_for_sort_data,单行的长度超过这个值,mysql认为单行太大,需要换一个算法
全字段排序,rowid排序如何选择?
当内存足够的时候会采用全字段排序,减少磁盘访问。当内存不够的时候才会采用rowid排序
我们可以给city,name建一个联合索引
alter table t add index city_user(city, name);
流程如下
- 从索引(city,name)找到第一个满足city=杭州的主键
- 根据主键回表找出整行,取出 name city age 三个字段的值,作为结果集的一部分直接返回
- 从索引(city,name)取出下一个主键
- 重复2,3步骤,直到查到第1000条记录,或者不满足city=杭州条件,循环结果
当然并不是所有的 order by 语句,都是需要排序操作的。MySQL之所以要生成临时表,并在临时表上做排序操作,其原因是原来的数据都是无序的
有没有可能取数据的时候,name就已经是有序的?
我们建一个 city 和 name 的联合索引不就满足了
alter table person add index city_user(city, name);

可以看到执行计划的Extra列已经没有 Using filesort 了,说明不用排序
作为进一步骤优化,我们完全可以建一个 city, name, age 的联合索引,这样所需的字段都能从联合索引上获取,而不用回表,产生索引覆盖的效果
alter table person add index city_user_age(city, name, age);

假设现在person表对 city 和 name 建了联合索引,那么下面语句需要排序吗?
select * from person where city in ('杭州') order by name limit 100
![]()
答案是不会,因为用了用了联合索引后,一个城市的name是有序的,不用排序
如果是下面的语句呢?
explain select * from person where city in ('杭州', '苏州') order by name limit 100
![]()
答案是会,因为用了联合索引后,一个城市的name不是有序的,需要排序
当 order by 语句执行的比较慢时,我们可以通过如下方法来进行优化
- 排序的字段增加索引
- 增大 sort buffer 的大小
- 不要用 * 作为查询列表,只返回需要的列
参考博客
[1]https://mp.weixin.qq.com/s/yUrq3UfCKP91jRp9VEFT6w
[2]https://zhuanlan.zhihu.com/p/380671457
[3]https://time.geekbang.org/column/article/73479