1. 应用背景及痛点介绍
华米科技是一家基于云的健康服务提供商,拥有全球领先的智能可穿戴技术。在华米科技,数据建设主要围绕两类数据:设备数据和APP数据,这些数据存在延迟上传、更新频率高且广、可删除等特性,基于这些特性,前期数仓ETL主要采取历史全量+增量模式来每日更新数据。随着业务的持续发展,现有数仓基础架构已经难以较好适应数据量的不断增长,带来的显著问题就是成本的不断增长和产出效率的降低。
针对数仓现有基础架构存在的问题,我们分析了目前影响成本和效率的主要因素如下:
- 更新模式过重,存在较多数据的冗余更新增量数据的分布存在长尾形态,故每日数仓更新需要加载全量历史数据来做增量数据的整合更新,整个更新过程存在大量历史数据的冗余读取与重写,带来的过多的成本浪费,同时影响了更新效率;
- 回溯成本高,多份全量存储带来的存储浪费,数仓设计中为了保证用户可以访问数据某个时间段的历史状态,会将全量数据按照更新日期留存多份,故大量未变化的历史冷数据会被重复存储多份,带来存储浪费;
为了解决上述问题,保证数仓的降本提效目标,我们决定引入数据湖来重构数仓架构,架构如下:
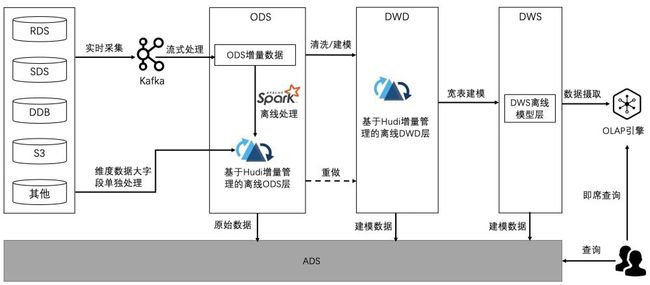
- 业务数据源实时接入Kafka,Flink接Kafka构建ODS实时增量数据层,实时ODS增量层主要作用有两方面:
- 依赖ODS实时增量数据(保留原始格式,不做清洗转化)每日离线入湖来构建ODS层离线湖仓,ODS层数据后续作为业务数据的备份、满足DWD层全量数据重做需求;
- 对ODS实时增量数据进行清洗、转换,编码后,每日增量数据离线写入DWD层,构建DWD层离线湖仓;
- DWS层定义为主题公共宽表层,主要是对DWD层和DIM维度层各表信息,根据业务需求做多表关联转换整合,为业务和分析人员提供更易用的模型数据
- OLAP层会提供强大的数据快速查询能力,作为对外的统一查询入口,用户直接通过OLAP引擎来即席查询分析湖仓中所有的表数据
- ADS层会依赖其他各层数据来对业务提供定制化的数据服务
2. 技术方案选型
| Hudi | Iceberg | Delta | |
|---|---|---|---|
| 引擎支持 | Spark、Flink | Spark、Flink | Spark |
| 原子语义 | Delete/Update/Merge | Insert/Merge | Delete/Update/Merge |
| 流式写入 | 支持 | 支持 | 支持 |
| 文件格式 | Avro、Parquet、ORC | Avro、Parquet、ORC | Parquet |
| MOR能力 | 支持 | 不支持 | 不支持 |
| Schema Evolution | 支持 | 支持 | 支持 |
| Cleanup能力 | 自动 | 手动 | 手动 |
| Compaction | 自动/手动 | 手动 | 手动 |
| 小文件管理 | 自动 | 手动 | 手动 |
基于上述我们比较关心的指标进行对比。Hudi可以很好的在任务执行过程中进行小文件合并,大大降低了文件治理的复杂度,依据业务场景所需要的原子语义、小文件管理复杂度以及社区活跃度等方面综合考量,我们选择Hudi来进行湖仓一体化改造。
3. 问题与解决方案
3.1.增量数据字段对齐问题
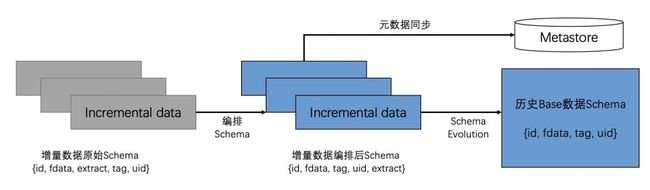
华米数据云端由于业务原因会产生表Schema变更需求,从而避免因Schema变更而重做历史Base数据带来的高额计算成本。但由于新增产生的数据实体字段相对位置的乱序问题,导致入湖同步Hive的过程中产生异常。针对该问题,华米大数据团队也在和社区联动,解决数据字段对齐问题。在社区支持更完善的Schema Evolution之前,当前华米大数据团队的解决方案为:根据历史Base数据的Schema顺序重新对增量数据Schema顺序做编排,然后统一增量入湖。具体处理流程如下图所示:历史Base数据的Schema顺序为{id, fdata, tag, uid},增量数据的Schema{id, fdata, extract, tag, uid},可见新增extract字段顺序打乱了原先历史Base数据的Schema,可以根据所读取的历史数据Schema顺序对新增数据进行调整:
将{id, fdata, extract, tag, uid}变更为{id, fdata, tag, uid, extract},然后调用Schema Evolution给历史Base数据的Schema添加一个extract字段,最终将调整后的增量数据写入历史Base。
3.2 全球存储兼容性问题
华米大数据存储涉及多种存储(HDFS,S3,KS3),华米大数据团队新增对KS3存储的支持并合入社区代码,在Hudi0.9版本后可以支持KS3存储。
3.3 云主机时区统一问题
由于华米全球各个数据中心采用按需方式进行节点扩容,申请得到的云主机可能会出现节点时区不一致,从而会造成commit失败,我们对Hudi源码进行了改造,在hudi源码中统一了Timeline的时区(UTC)时间来保证时区统一,避免commitTime回溯导致的Commit失败。
3.4 升级新版本问题
在Hudi0.9升级到0.10版本中,会发现出现版本因version不一致造成的数据更新失败问题。出现的不一致问题已经反馈至社区,社区相关同学正在解决,现在我们暂时使用重建元数据表(直接删除metadata目标)来解决该问题,再次执行作业时,Hudi会自动重新构建元数据表。
3.5 多分区Upsert性能问题
Hudi on Spark需要根据增量数据所在的分区采集文件的索引文件,更新分区过多的情况下,性能较差。针对这一问题,目前我们通过两个层面来进行处理:
- 推进上游进行数据治理,尽可能控制延迟数据,重复数据的上传
- 代码层进行优化,设定时间范围开关,控制每日入湖的数据在设定时间范围内,避免延迟较久的极少量数据入湖降低表每日更新性能;对于延迟较久的数据汇集后定期入湖,从而降低整体任务性能开销
3.6 数据特性适应问题
从数据入湖的性能测试中来看,Hudi性能跟数据组织的策略有较大的关系,具体体现在以下几个方面:
- 联合主键多字段的顺序决定了Hudi中的数据排序,影响了后续数据入湖等性能;主键字段的顺序决定了hudi中数据的组织方式,排序靠近的数据会集中分布在一起,可利用这个排序特性结合更新数据的分布特性,以尽可能减少入湖命中的base文件数据,提升入湖性能;
- 数据湖中文件块记录条数与布隆过滤器参数的适应关系,影响了索引构建的性能;在使用布隆过滤器时,官方给出的默认存储在布隆过滤器中的条目数为6万(假设maxParquetFileSize为128MB,averageRecordSize为1024),如果数据较为稀疏或者数据可压缩性比较高的话,每个文件块可能会存储的记录数远大于6万,从而导致每次索引查找过程中会扫描更多的base文件,非常影响性能,建议根据业务数据的特性适当调整该值,入湖性能应该会有较好的提升;
4. 上线收益
从业务场景和分析需求出发,我们主要对比了实时数据湖模式和离线数据湖模式的成本与收益,实时成本远高于离线模式。鉴于目前业务实时需求并不是很高,故华米数仓在引入数据湖时暂采取Hudi + Spark离线更新模式来构建湖仓ODS原始层和DWD明细层,从测试对比和上线情况来看,收益总结如下:
4.1 成本方面
引入Hudi数据湖技术后,数据仓库整体成本有一定程度的下降,预计会降低1/4~1/3的费用。主要在于利用Hudi数据湖提供的技术能力,可以较好的解决应用背景部分阐述的两大痛点,节约数仓Merge更新与存储两部分的费用开销。
4.2 效率方面
Hudi利用索引更新机制避免了每次全量更新表数据,使得数仓表每次更新避免了大量的冗余数据的读取与写入操作,故而表的更新效率有了一定的提升。从我们数仓+BI报表整体链条层面来看,整体报表产出时间会有一定程度的提前。
4.3 稳定性层面
程序稳定性层面暂时没有详细评估,结合实际场景说下目前情况:
- 中大表更新引入Hudi会相对较为稳定。基于Aws Spot Instance机制,对于数据量过大的表,每次全量shuffle的数据量过大,会导致拉取数据的时间过长,Spot机器掉线,程序重试甚至失败,或者内存原因导致的fetch失败,造成任务的不稳定。引入Hudi后,可以很大程度减少每次shuffle的数据量,有效缓解这一问题;
- Hudi的Metadata表机制功能稳定性待继续完善,开启后影响程序稳定性。考虑提升程序性能,前期开启了Metadata表,程序运行一段时间后会出现报错,影响错误已经反馈给社区,暂时关闭该功能,待稳定后再开启;
4.4 查询性能层面
Hudi写入文件时根据主键字段排序后写入,每个Parquet文件中记录是按照主键字段排序,在使用Hive或者Spark查询时,可以很好的利用Parquet谓词下推特性,快速过滤掉无效数据,相对之前的数仓表,有更好的查询效率。
5. 总结与展望
从数据湖上线和测试过程来看,目前数据湖能解决我们的一些数仓痛点,但是依然存在一些问题。
总结如下
- Hudi on Spark 布隆过滤器查找与构建索引过程性能尚待提升,由于华米数据分布特性(更新频率多,范围广),现阶段部分大表的更新性能提升有待加强;
- Metadata表的使用是为了提升整体入湖性能,但目前由于稳定性问题暂时关闭,后续会持续关注社区Metadata表的改进;
- 更新数据分布特性的研究至关重要,决定着如何组织数据湖中的数据分布,较大影响着任务性能,这块需要后续做进一步优化;
展望如下
- 利用Flink + Hudi技术栈搭建实时数仓,构建kafka -> ods -> dwd -> olap的实时数据链条,满足业务近实时需求
- 索引优化方案 -> HBase构建二级索引
以上就是Apache Hudi基于华米科技应用湖仓一体化改造 的详细内容,更多关于Apache Hudi华米科技应用改造的资料请关注脚本之家其它相关文章!