大数据之路 --- Hbase(分布式数据库)
HBase是一个在HDFS上开发的面向列的分布式数据库。
----<
HBase数据库的特点:
- 列式存储:按列存储
- 海量存储:无单机存储量限制,分布式存储
- 极易扩展:自动分区、非常容易根据数据量自动扩展
- 高并发:支持高并发、随机快速读写
- 稀疏:支持超宽列、不必每列都包含内容,可以为空值
HBase版本选择:
HBase是依赖于Hadoop的,因此需要根据Hadoop的版本来选择对应的HBase版本。
HBase的数据模型:
NameSpace(命名空间):类似于mysql中的库
- Table(表):类似于mysql中的表
-- Region(分区): HBase表按rowkey被水平划分为多个分区(可以理解为好多行构成一个分区)
-- ColumnFamily(列簇):多个列构成一个列簇,列簇中的列存在一起,便于快速检索,经常一起使用的列会设计成一个列簇
--- ColumnFamily(列):类似于mysql中的列
--- Row(行):类似于mysql中的行
---- RowKey(行键):用于唯一标识HBase中表的行
它们的关系如下:
NameSpace中有表,表中有分区,有列簇,列簇里有许多列,分区里有许多行,每行有一个行键。
HBase架构:

HBase中主要分成两种节点,HMaster和HRegionServer
HMaster:
负责Region Server的管理,DDL操作等
1.Region Server管理
2.DDL管理
- 负责分配region给RegionServer;
- 在RegionServer启动、恢复和负载均衡的时候负责重新分配region;
- 监控和管理集群中的Region Server实例(监听来自zookeeper的通知),类似于HDFS中NameNode对DataNode的管理;
- 负责表的创建、修改和删除接口
Zookeeper:
使用Zookeeper作为分布式协调服务来维护集群中服务的状态。为了保证共享状态的一致性,zookeeper的台数必须为三台(含)以上,且为奇数。
- HMaster和每个RegionServer定期发送心跳给Zookeeper,用于检查服务器是否可用,并在失效时通知;
- 当Active HMaster失效时,通知备用HMaster成为Active HMaster;
- 当某个RegionServer失效时,通知HMaster执行恢复任务;
- 维护元数据表(META Table)的路径,帮助客户端查找Region。
RegionServer:
一个HBase集群中通常包含多个RegionServer,主要负责Region中的数据的读写和管理。
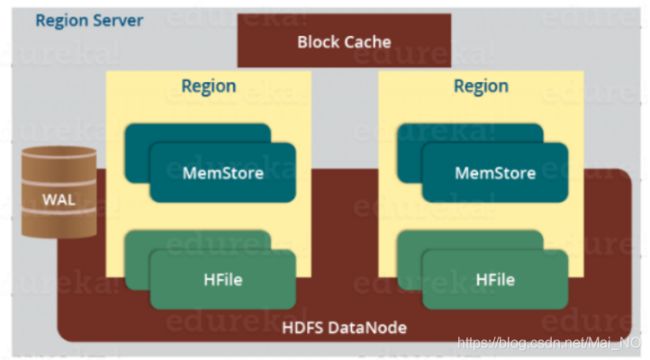
一个RegionServer中包括几个Region和一个Block Cache还有一个WAL。
Region(分区):一个分区只能存在一个RegionServer内(当然,副本可以在其他RegionServer存在),一个RegionServer中可以存在多个Region。
MemStore:写缓存,用于存储还未被提交的写入数据。Region中每个列簇都有一个MemStore。
HFile:存储在HDFS上,是HBase数据的存储文件。MemStore中的数据超过一定大小之后就提交到HFile。
Block Cache(块缓存):缓存那些被经常访问的数据
WAL(Write Ahead Log):存储未被持久化的新数据,还有一个编辑列表,每个编辑代表一次put或者delete操作,当数据丢失时,可以通过重新执行编辑列表的操作重建数据,主要用于失效情况下数据恢复。
HBase读取流程:
- 客户端首先根据配置文件中Zookeeper的地址连接Zookeeper,并去读HBase元数据表所在的RegionServer的信息。
- 将元数据表在本地缓存,然后在表中确定待检索的rowkey所在的RegionServer信息。
- 根据数据所在的RegionServer的访问信息,客户端直接向该RegionServer发送数据读取请求。
- RegionServer接收到请求之后,进行复杂的处理之后将结果返回给客户端。
HBase写入流程:
- 当客户端发出put请求之后,第一步是先把数据写到WAL中,也就是HLog。WAL主要用于数据恢复。
- 一旦数据被写入WAL之后,然后数据就更新到MemStore。这时就会给客户端发送Ack确认。
- 当MemStore积累到足够的数据时,整个数据集就被写入到一个新的HFile中,这个过程被称为HBase Region Flush。
HBase数据恢复:
当Region Server宕机时,该Server所属的region在恢复之前是不可访问的。当Zookeeper失去Region Server的心跳时,它会检测到节点的失效。这时,Zookeeper会通知HMaster,告知该Region Server已失效。
HMaster接到通知之后,会重新分配失效节点中的region给其他可用的Region Server。
为了恢复还未被写入HFile的MemStore中的数据,HMaster将失效节点的WAL分割并分配给相应的新分配的Region Server。新的Region Server读取并顺序执行WAL中的数据操作,以重建MemStore中的数据。
Rowkey设计原则:
- 长度原则:越短越好,最好是定长
- 散列原则:让key显得比较散乱,这样不会出现大多数数据集中在某一RegionServer的情况
- 唯一性原则:rowkey的设计必须保证唯一。
预分区(pre-splitting)
没有预分区的情况下,HBase默认只有一个region,当数据量增大到一定程度的时候进行split两个region。这样很容易出现数据热点问题,即数据集中在某一个region中,而且split需要消耗大量的io资源。
预分区创建方法:create 't1', 'f1', {SPLITS => ['10', '20', '30', '40']}
如此就根据rowkey的值创建了5个分区,分别是:
region1: 0-10
region2: 10-20
region3: 20-30
region4: 30-40
region5: 40-