文/龙蜥社区高性能网络SIG
引言
Shared Memory Communication over RDMA (SMC-R) 是一种基于 RDMA 技术、兼容 socket 接口的内核网络协议,由 IBM 提出并在 2017 年贡献至 Linux 内核。SMC-R 能够帮助 TCP 网络应用程序透明使用 RDMA,获得高带宽、低时延的网络通信服务。阿里云云上操作系统 Alibaba Cloud Linux 3 以及龙蜥社区开源操作系统 Anolis 8 配合神龙弹性 RDMA (eRDMA) 首次将 SMC-R 带上云上场景,助力云上应用获得更好的网络性能:《技术揭秘:阿里云发布第四代神龙 ,SMC-R 让网络性能提升 20%》。
由于 RDMA 技术在数据中心领域的广泛使用,龙蜥社区高性能网络 SIG 认为 SMC-R 将成为下一代数据中心内核协议栈的重要方向之一。为此,我们对其进行了大量的优化,并积极将这些优化回馈到上游 Linux 社区。目前,龙蜥社区高性能网络 SIG 是除 IBM 以外最大的 SMC-R 代码贡献团体。由于 SMC-R 相关中文资料极少,我们希望通过一系列文章,让更多的国内读者了解并接触 SMC-R,也欢迎有兴趣的读者加入龙蜥社区高性能网络 SIG 一起沟通交流(二维码见文末)。
本篇作为系列文章的第一篇,将从宏观的角度带领读者初探 SMC-R。
一、从 RDMA 谈起
Shared Memory Communication over RDMA 的名称包含了 SMC-R 网络协议的一大特点——基于 RDMA。因此,在介绍 SMC-R 前我们先来看看这个高性能网络领域中的绝对主力:Remote Direct Memory Access (RDMA) 技术。
1.1 为什么需要 RDMA ?
随着数据中心、分布式系统、高性能计算领域的快速发展,网络设备性能进步显著,主流物理网络带宽已达到了 25-100 Gb/s,网络时延也进入了十微秒的时代。
然而,网络设备性能提升的同时一个问题也逐渐显露:网络性能与 CPU 算力逐渐失配。传统网络中,负责网络报文封装、解析和用户态/内核态间数据搬运的 CPU 在高速增长的网络带宽面前逐渐显得力不从心,面临越来越大的压力。
以 TCP/IP 网络的一次数据发送与接收过程为例。发送节点 CPU 首先将数据从用户态内存拷贝至内核态内存,在内核态协议栈中完成数据包封装;再由 DMA 控制器将封装好的数据包搬运到 NIC 上发送到对端。接收端 NIC 获得数据包后通过 DMA 控制器搬运到内核态内存中,由内核协议栈解析,层层剥离帧首或包头后再由 CPU 将有效负载 (payload) 拷贝到用户态内存中,完成一次数据传输。
(图/传统 TCP/IP 网络传输模型)
在这一过程中,CPU 需要负责:
1)用户态与内核态间的数据拷贝。
2)网络报文的封装、解析工作。
这些工作“重复低级”,占用了大量 CPU 资源 (如 100 Gb/s 的网卡跑到满带宽需要打满多个 CPU 核资源),使得 CPU 在数据密集型场景下无法将算力用到更有益的地方。
所以,解决网络性能与 CPU 算力失配问题成为了高性能网络发展的关键。考虑到摩尔定律逐渐失效,CPU 性能短时间内发展缓慢,将网络数据处理工作从 CPU 卸载到硬件设备的思路就成为了主流解决方案。这使得以往专用于特定高性能领域的 RDMA 在通用场景下得到愈来愈多的应用。
1.2 RDMA 的优势
RDMA (Remote Direct Memory Access) 是一种远程内存直接访问技术,自提出以来经过 20 余年的发展已经成为了高性能网络的重要组成。那么 RDMA 是如何完成一次数据传输的呢?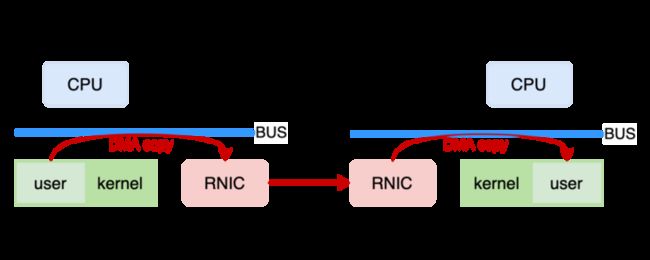
(图/用户态 RDMA 网络传输模型)
RDMA 网络 (用户态模式) 中,具备 RDMA 能力的网卡 RNIC 直接从发送端用户态内存中取得数据,在网卡中完成数据封装后传输到接收端,再由接收端 RNIC 将数据解析剥离,将有效负载 (payload) 直接放入用户态内存中完成数据传输。
这一过程中 CPU 除了必要的控制面功能外,几乎不用参与数据传输。数据就像是通过 RNIC 直接写入到远程节点的内存中一样。因此,与传统网络相比,RDMA 将 CPU 从网络传输中解放了出来,使得网络传输就像是远程内存直接访问一样方便快捷。
(图/传统网络与 RDMA 网络协议栈对比)
对比传统网络协议,RDMA 网络协议具有以下三个特点:
1.旁路软件协议栈
RDMA 网络依赖 RNIC 在网卡内部完成数据包封装与解析,旁路了网络传输相关的软件协议栈。对于用户态应用程序,RDMA 网络的数据路径旁路了整个内核;对于内核应用程序,则旁路了内核中的部分协议栈。由于旁路了软件协议栈,将数据处理工作卸载到了硬件设备,因而 RDMA 能够有效降低网络时延。
2.CPU 卸载
RDMA 网络中,CPU 仅负责控制面工作。数据路径上,有效负载由 RNIC 的 DMA 模块在应用缓冲区和网卡缓冲区中拷贝 (应用缓冲区提前注册,授权网卡访问的前提下),不再需要 CPU 参与数据搬运,因此可以降低网络传输中的 CPU 占用率。
3.内存直接访问
RDMA 网络中,RNIC 一旦获得远程内存的访问权限,即可直接向远程内存中写入或从远程内存中读出数据,不需要远程节点参与,非常适合大块数据传输。
二、回到 SMC-R
通过上述介绍,相信读者对 RDMA 主要特点以及性能优势有了初步的了解。不过,虽然 RDMA 技术能够带来可喜的网络性能提升,但是想使用 RDMA 透明提升现有 TCP 应用的网络性能仍有困难,这是因为 RDMA 网络的使用依赖一系列新的语义接口,包括 ibverbs 接口与 rdmacm 接口 (后统称 verbs 接口)。
部分 ibverbs与rdmacm接口[1]
相较于传统 POSIX socket 接口,verbs 接口数量多,且更接近硬件语义。对于已有的基于 POSIX socket 接口实现的 TCP 网络应用,想要享受 RDMA 带来的性能红利就不得不对应用程序进行大量改造,成本巨大。
因此,我们希望能够在使用 RDMA 网络的同时沿用 socket 接口,使现有 socket 应用程序透明的享受 RDMA 服务。针对这一需求,业界提出了以下两个方案:
其一,是基于 libvma 的用户态方案。libvma 的原理是通过 LD_PRELOAD 来将应用所有 socket 调用引入自定义实现,在自定义实现中调用 verbs 接口,完成数据收发。但是,由于实现在用户态,libvma 一方面缺少内核统一资源管理,另一方面对 socket 接口的兼容性较差。
其二,是基于 SMC-R 的内核态方案。作为内核态协议栈,SMC-R 对 TCP 应用的兼容性相较于用户态方案会好很多,这种 100% 兼容意味着极低的推广和复用成本。此外,实现在内核态使得 SMC-R 协议栈中的 RDMA 资源能够被用户态不同进程共享,提高资源利用率的同时降低频繁资源申请与释放的开销。不过,完全兼容 socket 接口就意味着需要牺牲极致的 RDMA 性能 (因为用户态 RDMA 程序可以做到数据路径旁路内核与零拷贝,而 SMC-R 为了兼容 socket 接口,无法实现零拷贝),但这也换来兼容与易用,以及对比 TCP 协议栈的透明性能提升。未来,我们还计划拓展接口,以牺牲小部分兼容性的代价将零拷贝特性应用于 SMC-R,使它的性能得到进一步改善。
2.1 透明替换 TCP
SMC-R is an open sockets over RDMA protocol that provides transparent exploitation of RDMA (for TCP based applications) while preserving key functions and qualities of service from the TCP/IP ecosystem that enterprise level servers/network depend on!
摘自:
SMC-R 作为一套与 TCP/IP 协议平行,向上兼容 socket 接口,底层使用 RDMA 完成共享内存通信的内核协议栈,其设计意图是为 TCP 应用提供透明的 RDMA 服务,同时保留了 TCP/IP 生态系统中的关键功能。
为此,SMC-R 在内核中定义了新的网络协议族 AF_SMC,其 proto_ops 与 TCP 行为完全一致。
/* must look like tcp */
static const struct proto_ops smc_sock_ops = {
.family = PF_SMC,
.owner = THIS_MODULE,
.release = smc_release,
.bind = smc_bind,
.connect = smc_connect,
.socketpair = sock_no_socketpair,
.accept = smc_accept,
.getname = smc_getname,
.poll = smc_poll,
.ioctl = smc_ioctl,
.listen = smc_listen,
.shutdown = smc_shutdown,
.setsockopt = smc_setsockopt,
.getsockopt = smc_getsockopt,
.sendmsg = smc_sendmsg,
.recvmsg = smc_recvmsg,
.mmap = sock_no_mmap,
.sendpage = smc_sendpage,
.splice_read = smc_splice_read,
};
由于 SMC-R 协议支持与 TCP 行为一致的 socket 接口,使用 SMC-R 协议非常简单。总体来说有两个方法:
(图/SMC-R 的使用方法)
其一,使用 SMC-R 协议族 AF_SMC 开发。通过创建 AF_SMC 类型的 socket,应用程序的流量将进入到 SMC-R 协议栈;
其二,透明替换协议栈。将应用程序创建的 TCP 类型 socket 透明替换为 SMC 类型 socket。透明替换可以通过以下两种方式实现:
- 使用 LD_PRELOAD 实现协议栈透明替换。在运行 TCP 应用程序时预加载一个动态库。在动态库中实现自定义 socket() 函数,将 TCP 应用程序创建的 AF_INET 类型 socket 转换为 AF_SMC 类型的 socket,再调用标准 socket 创建流程,从而将 TCP 应用流量引入 SMC-R 协议栈。
int socket(int domain, int type, int protocol)
{
int rc;
if (!dl_handle)
initialize();
/* check if socket is eligible for AF_SMC */
if ((domain == AF_INET || domain == AF_INET6) &&
// see kernel code, include/linux/net.h, SOCK_TYPE_MASK
(type & 0xf) == SOCK_STREAM &&
(protocol == IPPROTO_IP || protocol == IPPROTO_TCP)) {
dbg_msg(stderr, "libsmc-preload: map sock to AF_SMC\n");
if (domain == AF_INET)
protocol = SMCPROTO_SMC;
else /* AF_INET6 */
protocol = SMCPROTO_SMC6;
domain = AF_SMC;
}
rc = (*orig_socket)(domain, type, protocol);
return rc;
}开源用户态工具集 smc-tools 中的 smc_run 指令即实现上述功能[2]。
- 通过 ULP + eBPF 实现协议栈透明替换。SMC-R 支持 TCP ULP 是龙蜥社区高性能网络 SIG 贡献到上游 Linux 社区的新特性。用户可以通过 setsockopt() 指定新创建的 TCP 类型 socket 转换为 SMC 类型 socket。同时,为避免应用程序改造,用户可以通过 eBPF 在合适的 hook 点 (如 BPF_CGROUP_INET_SOCK_CREATE、BPF_CGROUP_INET4_BIND、BPF_CGROUP_INET6_BIND 等) 注入 setsockopt(),实现透明替换。这种方式更适合在容器场景下可以依据自定义规则,批量的完成协议转换。
static int smc_ulp_init(struct sock *sk)
{
struct socket *tcp = sk->sk_socket;
struct net *net = sock_net(sk);
struct socket *smcsock;
int protocol, ret;
/* only TCP can be replaced */
if (tcp->type != SOCK_STREAM || sk->sk_protocol != IPPROTO_TCP ||
(sk->sk_family != AF_INET && sk->sk_family != AF_INET6))
return -ESOCKTNOSUPPORT;
/* don't handle wq now */
if (tcp->state != SS_UNCONNECTED || !tcp->file || tcp->wq.fasync_list)
return -ENOTCONN;
if (sk->sk_family == AF_INET)
protocol = SMCPROTO_SMC;
else
protocol = SMCPROTO_SMC6;
smcsock = sock_alloc();
if (!smcsock)
return -ENFILE;
<...>
}
SEC("cgroup/connect4")
int replace_to_smc(struct bpf_sock_addr *addr)
{
int pid = bpf_get_current_pid_tgid() >> 32;
long ret;
/* use-defined rules/filters, such as pid, tcp src/dst address, etc...*/
if (pid != DESIRED_PID)
return 0;
<...>
ret = bpf_setsockopt(addr, SOL_TCP, TCP_ULP, "smc", sizeof("smc"));
if (ret) {
bpf_printk("replace TCP with SMC error: %ld\n", ret);
return 0;
}
return 0;
}综合上述介绍,TCP 应用程序透明使用 RDMA 服务可以体现在以下两个方面:
2.2 SMC-R 架构

(图/SMC-R 架构)
SMC-R 协议栈在系统内部处于 socket 层以下,RDMA 内核 verbs 层以上。是一个具备 "hybrid" 特点的内核网络协议栈。这里的 "hybrid" 主要体现在 SMC-R 协议栈中混合了 RDMA 流与 TCP 流:
数据流量基于 RDMA 网络传输
SMC-R 使用 RDMA 网络来传递用户态应用程序的数据,使应用程序透明的享受到 RDMA 带来的性能红利,即上图中黄色部分所示。
发送端应用程序的数据流量通过 socket 接口从应用缓冲区来到内核内存空间;接着通过 RDMA 网络直接写入远程节点的一个内核态 ringbuf (remote memory buffer, RMB) 中;最后由远程节点 SMC-R 协议栈将数据从 RMB 拷贝到接收端应用缓冲区中。
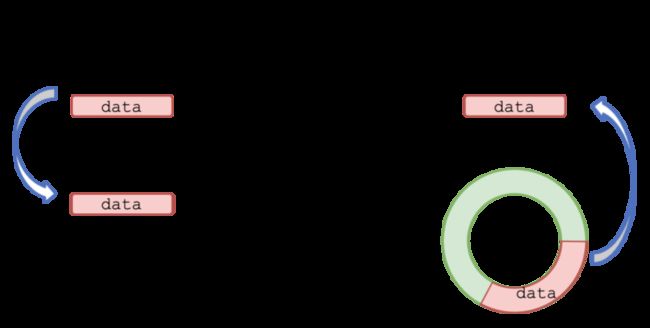
(图/SMC-R 共享内存通信)
显然,SMC-R 名称中的共享内存通信指的就是基于远程节点 RMB 进行通信。与传统的本地共享内存通信相比,SMC-R 将通信两端拓展为了两个分离的节点,利用 RDMA 实现了基于“远程”共享内存的通信。
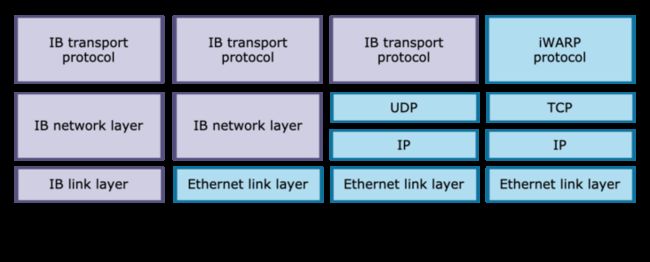
(图/主流 RDMA 实现)
目前,RDMA 网络的主流实现有三种:InfiniBand、RoCE 和 iWARP。其中,RoCE 作为在高性能与高成本中权衡的方案,在使用 RDMA 的同时兼容以太网协议,既保证了不错的网络性能,同时也降低了网络组建成本,因此倍受企业青睐,Linux 上游社区版本的 SMC-R 也因此使用 RoCE v1 和 v2 作为其 RDMA 实现。
而 iWARP 则是基于 TCP 实现了 RDMA,突破了其余两者对无损网络的刚性需求。iWARP 具备更好的可拓展性,非常适用于云上场景。阿里云弹性 RDMA (eRDMA) 基于 iWARP 将 RDMA 技术带到云上。阿里云操作系统 Alibaba Cloud Linux 3 与龙蜥社区开源操作系统 Anolis 8 中的 SMC-R 也进一步支持了 eRDMA (iWARP),使云上用户透明无感的使用 RDMA 网络。
依赖 TCP 流建立连接
除 RDMA 流外,SMC-R 还会为每个 SMC-R 连接配备一条 TCP 连接,两者具有相同的生命周期。TCP 流在 SMC-R 协议栈中主要担负以下职责:
1)动态发现对端 SMC-R 能力
在 SMC-R 连接建立前,通信两端并不知道对端是否同样支持 SMC-R。因此,两端会首先建立一条 TCP 连接。在 TCP 连接三次握手的过程中通过发送携带特殊的 TCP 选项的 SYN 包表示支持 SMC-R,同时检验对端发送的 SYN 包中的 TCP 选项。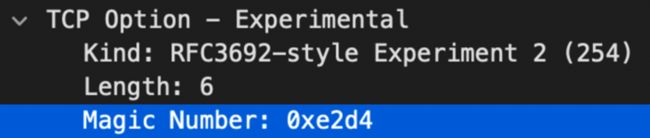
(图/表示 SMC-R 能力的 TCP 选项)
2)回退
若在上述过程中,通信两端其一无法支持 SMC-R 协议,或是在 SMC-R 连接建立过程中无法继续,则 SMC-R 协议栈将回退至 TCP 协议栈。回退过程中,SMC-R 协议栈将应用程序持有的文件描述符对应的 socket 替换为 TCP 连接的 socket。应用程序的流量将通过这条 TCP 连接承载,以保证数据传输不会中断。
3)帮助建立 SMC-R 连接
若通信两端均支持 SMC-R 协议,则将通过 TCP 连接交换 SMC-R 连接建立消息 (建连过程类似 SSL 握手)。此外,还需要使用此 TCP 连接交换两侧的 RDMA 资源信息,帮助建立用于数据传输的 RDMA 链路。
通过上述介绍,相信读者对 SMC-R 总体架构有了初步的了解。SMC-R 作为一个 "hybrid" 解决方案,充分利用了 TCP 流的通用性和 RDMA 流的高性能。后面的文章中我们将对 SMC-R 中的一次完整通信过程进行分析,届时读者将进一步体会到 "hybrid" 这一特点。
本篇作为 SMC-R 系列文章的首篇,希望能够起到一个引子的作用。回顾本篇,我们主要回答了这几个问题:
1、为什么要基于 RDMA ?
因为 RDMA 能够带来网络性能提升 (吞吐/时延/CPU占用率);
2、为什么 RDMA 能够带来性能提升?
因为旁路了大量软件协议栈,将 CPU 从网络传输过程中解放出来,使数据传输就像直接写入远程内存一样简单;
3、为什么需要 SMC-R ?
因为 RDMA 应用基于 verbs 接口实现,已有的 TCP socket 应用若想使用 RDMA 技术改造成本高;
4、SMC-R 有什么优势?
SMC-R 完全兼容 socket 接口,模拟 TCP socket 接口行为。使 TCP 用户态应用程序能够透明使用 RDMA 服务,不做任何改造就可以享受 RDMA 带来的性能优势。
5、SMC-R 的架构特点?
SMC-R 架构具有 "hybrid" 的特点,融合了 RDMA 流与 TCP 流。SMC-R 协议使用 RDMA 网络传输应用数据,使用 TCP 流确认对端 SMC-R 能力、帮助建立 RDMA 链路。
参考引用说明:
[1]:
https://network.nvidia.com/pd...
[2]:https://github.com/ibm-s390-l...
—— 完 ——
加入龙蜥社群
加入微信群:添加社区助理-龙蜥社区小龙(微信:openanolis_assis),备注【龙蜥】与你同在;加入钉钉群:扫描下方钉钉群二维码。欢迎开发者/用户加入龙蜥社区(OpenAnolis)交流,共同推进龙蜥社区的发展,一起打造一个活跃的、健康的开源操作系统生态!

关于龙蜥社区
龙蜥社区(OpenAnolis)是由企事业单位、高等院校、科研单位、非营利性组织、个人等在自愿、平等、开源、协作的基础上组成的非盈利性开源社区。龙蜥社区成立于 2020 年 9 月,旨在构建一个开源、中立、开放的Linux 上游发行版社区及创新平台。
龙蜥社区成立的短期目标是开发龙蜥操作系统(Anolis OS)作为 CentOS 停服后的应对方案,构建一个兼容国际 Linux 主流厂商的社区发行版。中长期目标是探索打造一个面向未来的操作系统,建立统一的开源操作系统生态,孵化创新开源项目,繁荣开源生态。
目前,龙蜥OS 8.4已发布,支持 X86_64 、Arm64、LoongArch 架构,完善适配飞腾、海光、兆芯、鲲鹏、龙芯等芯片,并提供全栈国密支持。
欢迎下载:
https://openanolis.cn/download
加入我们,一起打造面向未来的开源操作系统!