python-数据分析工具-numpy
python-数据分析工具-numpy
- 1 数组的索引和切片
-
- 1.1 一维数组索引和切片
- 1.2 多维数组
- 2 布尔索引
- 3 值的替换
- 4 广播机制
- 5 形状操作
-
- 5.1 数组叠加
- 5.2 数组分割
- 5.3 转置和轴对换
- 5.4 矩阵乘法(线代乘法)
- 6 浅拷贝和深拷贝
-
- 6.1 View/浅拷贝
- 6.2 深拷贝
- 7 文件操作
-
- 7.1 文件保存
- 7.2 加载数据
- 7.3 save和load可以保存和加载多维数组
- 8 NAN和INF值处理
-
- 8.1 简介
- 8.2 删除缺失值
- 8.3 替换缺失值
- 9 random模块
-
- 9.1 np.random.rand
- 9.2 np.random.randn
- 9.3 np.random.ranint
- 9.4 np.random.choice
- 9.5 np.random.shuffle
- 10 axis轴
- 11 通用函数
-
- 11.1 一元函数
- 11.2 二元函数
- 11.3 聚合函数
- 11.4 布尔判断
- 11.5 排序
- 11.6 其他函数
1 数组的索引和切片
1.1 一维数组索引和切片
import numpy as np
# 生成等差array
data1 = np.arange(1,10,2)
data1 #结果 array([1, 3, 5, 7, 9])
# 1.一维数组索引
data1[1] #结果 3
# 2. 一维数组切片
data1[0:3] #结果 array([1, 3, 5])
# 3. 一维数组切片
data1[::2] #结果 array([1, 5, 9])
# 4.一维数组索引
data1[-1]#结果 9
1.2 多维数组
2 布尔索引
3 值的替换
4 广播机制
5 形状操作
5.1 数组叠加
hstack:代表水平方向叠加,要想叠加成功,行必须一致
vstack:代表垂直方向叠加,要想叠加成功,列必须一致
concatenate:手动指定叠加方向,axis=0 表示垂直方向叠加,axis=1表示水平方向叠加,axis=None表示叠加为一维数组。
import numpy as np
h1 = np.random.randint(0,10,size=(3,1))
h1 #结果:
'''array([[4],
[8],
[2]])'''
h2 = np.random.randint(0,10,size=(3,4))
h2 #结果:
'''array([[6, 9, 5, 0],
[6, 1, 9, 4],
[8, 8, 9, 8]])'''
h4 = np.random.randint(0,10,size=(1,4))
h4 # 结果
'''array([[2, 3, 5, 5]])'''
# 2.横向堆叠
h3 = np.hstack([h1,h2])
h3 #结果:
'''array([[4, 6, 9, 5, 0],
[8, 6, 1, 9, 4],
[2, 8, 8, 9, 8]])'''
# 3.使用concatenate进行自定义拼接
np.concatenate([h1,h2],axis=1) #横向拼接 结果:
'''array([[4, 6, 9, 5, 0],
[8, 6, 1, 9, 4],
[2, 8, 8, 9, 8]])'''
# 3.使用concatenate进行自定义堆叠
np.concatenate([h1,h2],axis=None)#拼接成一维数组 结果:
'''
array([4, 8, 2, 6, 9, 5, 0, 6, 1, 9, 4, 8, 8, 9, 8])
'''
# 3.使用concatenate进行自定义堆叠
np.concatenate([h2,h3],axis=0)#纵向拼接 结果
'''array([[6, 9, 5, 0],
[6, 1, 9, 4],
[8, 8, 9, 8],
[2, 3, 5, 5]])'''
5.2 数组分割
hsplit:水平方向分割。
vsplit:垂直方向分割。
split/array_split: 自定义分割,axis=1 水平分割,axis=0 垂直方向分割。
# 4.分割-水平方向分割
h5 = np.random.randint(0,100,size=(6,4))
h5
'''array([[13, 7, 29, 65],
[57, 50, 79, 12],
[ 9, 16, 82, 86],
[97, 62, 43, 92],
[66, 21, 78, 34],
[95, 33, 51, 63]])'''
np.hsplit(h5,2) # 将h5水平分割等分两个数组,被分割的列一定为指定分割数的倍数
'''[array([[13, 7],
[57, 50],
[ 9, 16],
[97, 62],
[66, 21],
[95, 33]]),
array([[29, 65],
[79, 12],
[82, 86],
[43, 92],
[78, 34],
[51, 63]])]'''
np.hsplit(h5,[1,3])#将h5从下标为1、3的地方水平分割
'''[array([[13],
[57],
[ 9],
[97],
[66],
[95]]),
array([[ 7, 29],
[50, 79],
[16, 82],
[62, 43],
[21, 78],
[33, 51]]),
array([[65],
[12],
[86],
[92],
[34],
[63]])]
'''
# 5 分割-纵向分割
np.vsplit(h5,3)
'''
[array([[13, 7, 29, 65],
[57, 50, 79, 12]]),
array([[ 9, 16, 82, 86],
[97, 62, 43, 92]]),
array([[66, 21, 78, 34],
[95, 33, 51, 63]])]
'''
np.vsplit(h5,[1,2])
'''
[array([[13, 7, 29, 65]]),
array([[57, 50, 79, 12]]),
array([[ 9, 16, 82, 86],
[97, 62, 43, 92],
[66, 21, 78, 34],
[95, 33, 51, 63]])]
'''
# 6 分割-自定义分割
np.split(h5,2,axis=1) #横向分割,按列分割
'''
[array([[13, 7],
[57, 50],
[ 9, 16],
[97, 62],
[66, 21],
[95, 33]]),
array([[29, 65],
[79, 12],
[82, 86],
[43, 92],
[78, 34],
[51, 63]])]
'''
np.split(h5,3,axis=0)#纵向分割,按行分割
'''
[array([[13, 7, 29, 65],
[57, 50, 79, 12]]),
array([[ 9, 16, 82, 86],
[97, 62, 43, 92]]),
array([[66, 21, 78, 34],
[95, 33, 51, 63]])]
'''
5.3 转置和轴对换
.T: T属性可对数组进行转置
.transpose:返回一个View(浅拷贝),修改返回值,会影响到原来的数组
# 7 转置
h6 = np.random.randint(0,100,size=(3,1))
h6
'''
array([[52],
[17],
[80]])
'''
h6.T #T属性转置
'''
array([[52, 17, 80]])
'''
h7 = h6.transpose() #浅拷贝
h7
'''
array([[52, 17, 80]])
'''
h7[0,0]=100
h6
'''
array([[100],
[ 17],
[ 80]])
'''
5.4 矩阵乘法(线代乘法)
# 8 矩阵乘法
h6.dot(h6.T)
'''
array([[10000, 1700, 8000],
[ 1700, 289, 1360],
[ 8000, 1360, 6400]])
'''
6 浅拷贝和深拷贝
6.1 View/浅拷贝
对变量进行拷贝,但是它们指向的内存空间都是相同的。
下图示意


6.2 深拷贝
对变量进行拷贝,但是它们指向的内存空间都是不相同的。


7 文件操作
7.1 文件保存
np.savetxt(frame,array,fmt=’%.18e’,delimiter=None)
frame:文件、字符串或产生器,可以是.gz或.bz2文件
array:存入文件的数组
fmt:写入文件格式.
delimiter:分割字符串,默认是空格


7.2 加载数据
loadtxt(fname, dtype=
fname:解析文件名,一般为csv文件
dtype:数据类型转换
comments:最开始处的注释标识
delimiter:分隔符解析
skiprows:跳过多少行
7.3 save和load可以保存和加载多维数组
np.save(fname,array):npy后缀名文件,可不设置header
np.savez(fname,array):npz后缀名文件,压缩格式,可不设置header
np.load(fname):
8 NAN和INF值处理
8.1 简介
NAN:not a number。不是一个数字的意思,但它属于浮点类型,想要进行数据操作请注意它的类型。
特点:NAN和NAN是不相等的,NAN和任何值做运算,值都为NAN。
很多时候文件中存在缺失值,读取默认用NAN代替

inf:Infinity,代表无穷大,属于浮点类型,np.inf代表正无穷大,-np.inf代表负无穷大。2/0

8.2 删除缺失值

8.3 替换缺失值


9 random模块
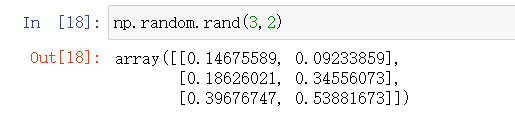
9.1 np.random.rand
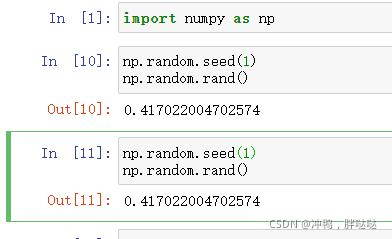
np.random.seed()不指定值,将默认为当前时间作为种子随机产生数值,若是seed固定,则随机数将固定。
9.2 np.random.randn
生成均值( μ \mu μ)为0,标准差( σ \sigma σ)为1的正态分布的值

9.3 np.random.ranint
生成指定范围内的随机数,可通过size参数指定维度

9.4 np.random.choice
从一个列表或数值中,随机进行采用,或者从指定的区间中进行采样,采用的个数指定

9.5 np.random.shuffle
把原来数组的元素位置打乱。(注意原来数组数据会发生改变)

10 axis轴
axis=0 代表最外面的轴,依次往里的括号对应axis的计数依次加1。


11 通用函数
11.1 一元函数
| 函数 | 描述 |
|---|---|
| np.abs | 绝对值 |
| np.sqrt | 开根 |
| np.exp | 计算指数 |
| np.log,np.log10,np.log2,np.log1p | 求e为底,以10为底,以2为底,以(1+x)为底的对数,给的值必须>0且不为1 |
| np.sign | 将数据中的值标签化,大于0的为1,等于0的为0,小于1的为-1 |
| np.ceil | 朝着无穷大的方向取整,比如5.1会变成6,-6.3会变成-6 |
| np.floor | 朝着无穷肖的方向取整,比如5.1会变成5,-6.3会变成-7 |
| np.rint,np.round | 返回四舍五入的值 |
| np.modf | 将整数部分和小数部分分开返回 |
11.2 二元函数
| 函数 | 描述 |
|---|---|
| np.add | 加法运算 |
| np.subtract | 减法运算 |
| np.negative | 负数运算 |
| np.multiply | 乘法运算 |
| np.divide | 除法运算 |
| np.floor_divide | 取整运算 |
| np.mod | 取余运算 |
| greater,greater_equal,less,less_equal,equal,not_equal | >,>=,<,<=,=,!= |
| logical_and | & |
| logical_or | | |
11.3 聚合函数
| 函数 | 描述 |
|---|---|
| np.sum | 计算元素的和 |
| np.prod | 计算元素的积 |
| np.mean | 计算元素的平均值 |
| np.std | 计算元素的标准差 |
| np.var | 计算元素的方差 |
| np.min | 计算元素的最小值 |
| np.max | 计算元素的最大值 |
| np.argmin | 计算元素的最大值所在位置 |
| np.argmax | 计算元素的最大值所在位置 |
| np.median | 计算元素的最大值所在位置 |
11.4 布尔判断
| 函数 | 描述 |
|---|---|
| np.any | 验证任何一个元素是否为真 |
| np.all | 验证所有元素是否为真 |
11.5 排序
| 函数 | 描述 |
|---|---|
| np.sort | 默认升序排序,不改变值 |
| ndarry.sort | 排序,会改变ndarray的值 |
| -np.sort(-ndarray) | 降序排序,不改变值 |
| np.argsort(ndarray) | 获取排序索引 |
11.6 其他函数
- np.apply_along_axis:沿着某个轴指定执行指定的函数。

- np.linpace:用来将指定区间平均分成多少份

- np.unique:返回数据中的唯一值
-
更多可以参考: https://numpy.org/doc/stable/reference/index.html.