python数据分析基础01——numpy基础、pandas数据清洗
文章目录
-
- Numpy
-
- 常用属性
- 索引和切片
- 变形
- 级联
- 图片操作
- 统计函数
- 矩阵
- Pandas
-
- Series
- DataFrame
-
- 股票分析案例
- 数据清洗
-
- 空值数据
- 重复数据
- 异常数据
Numpy
python语言中做数据科学的基础库,注重数值的计算,大多数python科学计算库的基础
# 数组和列表的区别
# 数组中只可以存储相同类型的元素
# 数组中出现不同类型的元素,会根据类型优先级进行数据转换
# 数据优先级
# 字符串>浮点型>整型
# 创建数组的方式
# 1、np.array()
# 2、plt创建
# 3、np的routines创建
import numpy as np
import matplotlib.pyplot as plt
# 创建一维数组
arr1 = np.array([1, 2, 3, 4, 5])
# 二维数组
arr2 = np.array([[1, 2, 3], [4, 5, 6]])
# 图片加载也是数组
result = plt.imread(r"F:\1.png")
# print(result)
# 可返回默认值多维数组 shape是数组结构 dtype是默认值类型
a1 = np.ones(shape=(3, 4), dtype="int")
print(a1)
# 返回一维数组 按范围和数量输出等差数列
a2 = np.linspace(0, 100, num=10)
print(a2)
# 返回一维数组 按范围和步长也就是公差输出等差数列
a3 = np.arange(0, 20, step=2)
print(a3)
# 可返回多维数组 按范围随机生成元素值 size是数组的结构
a4 = np.random.randint(0, 100, size=(4, 5))
print(a4)
# 可返回多维随机元素数组 按默认范围(0,1)随机生成元素值 size是数组的结构
a5 = np.random.random(size=(2, 3))
print(a5)
常用属性
import numpy as np
arr = np.random.randint(0, 100, size=(5, 6))
print(arr)
print(arr.shape) # 结构(5,6) 五行六列
print(arr.ndim) # 维度
print(arr.size) # 元素个数
print(arr.dtype) # 元素类型
# 修改元素类型
arr = np.array([1, 2, 3, 4, 5], dtype='int')
print(arr.dtype) # int默认是int32
arr1 = arr.astype('int8') # 修改类型,返回新的数组,原来数组不变
print(arr1.dtype)
索引和切片
arr = np.random.randint(0, 100, size=(4, 5))
print(arr)
print(arr[0][0]) # 二维数组第一个元素
arr1 = np.random.randint(0, 100, size=(5, 6))
print(arr1)
print(arr1[0:3]) # 切行
print(arr1[:, 0:3]) # 切列
print(arr1[0:3, 0:2]) # 切前三行前两列
变形
arr = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9])
arr1 = arr.reshape((3, 3)) # 一维变二维,但元素数量必须一致
print(arr1)
级联
将多个numpy数组进行横向或纵向的拼接
arr1 = np.random.randint(0, 100, size=(3, 4))
arr2 = np.random.randint(0, 100, size=(2, 4))
print(arr1)
print("=" * 100)
print(arr2)
print("=" * 100)
# 匹配级联:级联的数组形状一致
arr = np.concatenate((arr1, arr1), axis=0) # 表示维度,从0开始,如二维就是0表示纵向,1表示横向
print(arr)
# 不匹配级联:
arr = np.concatenate((arr1, arr2), axis=0) # 匹配的维度个数一定要一致,比如(3,4) 和 (2,4),只能匹配纵向
print(arr)
图片操作
# 照片的九宫格
import matplotlib.pyplot as plt
import pylab
ima_arr = plt.imread(r'F:\图片.jpg')
ima_arr_3 = np.concatenate((ima_arr, ima_arr, ima_arr), axis=1)
ima_arr_9 = np.concatenate((ima_arr_3, ima_arr_3, ima_arr_3), axis=0)
plt.imshow(ima_arr_3)
plt.imshow(ima_arr_9)
pylab.show()
plt.imshow(ima_arr[:, ::-1, :]) # 左右翻转
plt.imshow(ima_arr[::-1, :, :]) # 上下翻转
plt.imshow(ima_arr[50:200, 150:350, :]) # 切割
统计函数
arr = np.random.randint(0, 100, size=(5, 6))
print(arr)
print(arr.sum()) # 元素之和
# 求出每一列的和
print(arr.sum(axis=0)) # 表示维度,从0开始,如二维就是0表示纵向,1表示横向
arr = np.array([1, 3, 5, 7.451, 2.445])
print(np.around(arr, 1)) # 四舍五入,保留小数
arr = np.random.randint(0, 100, size=(4, 6))
print(arr)
print(np.ptp(arr, axis=0)) # 计算最大值和最小值的差值
print(np.median(arr, axis=0)) # 计算中位数
常用的统计函数
numpy.amin() 和 numpy.amax(),用于计算数组中的元素沿指定轴的最小、最大值。
numpy.ptp():计算数组中元素最大值与最小值的差(最大值 - 最小值)。
numpy.median() 函数用于计算数组 a 中元素的中位数(中值)
标准差std():标准差是一组数据平均值分散程度的一种度量。
公式:std = sqrt(mean((x - x.mean())**2))
如果数组是 [1,2,3,4],则其平均值为 2.5。 因此,差的平方是 [2.25,0.25,0.25,2.25],并且其平均值的平方根除以 4,即 sqrt(5/4) ,结果为 1.1180339887498949。
方差var():统计中的方差(样本方差)是每个样本值与全体样本值的平均数之差的平方值的平均数,即 mean((x - x.mean())** 2)。换句话说,标准差是方差的平方根。
矩阵
NumPy 中包含了一个矩阵库 numpy.matlib,该模块中的函数返回的是一个矩阵,而不是 ndarray 对象。一个 的矩阵是一个由行(row)列(column)元素排列成的矩形阵列。
numpy.matlib.identity() 函数返回给定大小的单位矩阵。单位矩阵是个方阵,从左上角到右下角的对角线(称为主对角线)上的元素均为 1,除此以外全都为 0。
Pandas
Series
Series是一种类似与一维数组的对象,由下面两个部分组成:
-
values:一组数据(ndarray类型)
-
index:相关的数据索引标签
# 创建Series的方式
import pandas as pd
from pandas import Series, DataFrame
import numpy as np
s1 = Series(data=['xiao','li','yan'])
s2 = Series(data=np.random.randint(0,10,size=(3,)))
dic ={
'xiao':22,
'li':23,
'yan':23
}
s3 = Series(data=dic)
s4 = Series([100, 100, 120], index=['math', 'english', 'ch'])
Series的索引
- 隐式索引:默认形式的索引(0,1,2…)
- 显示索引:自定义的索引,可以通过index参数设置显示索引
s = Series(data=np.linspace(start=0, stop=100, num=5), index=['a', 'b', 'c', 'd', 'e'])
print(s)
print(s[0]) # 隐式索引
print(s['a']) # 显示索引
print(s.a) # 打点的方式访问显示索引
Series的常用属性
- shape
- size
- index
- values
s = Series(data=np.linspace(start=0, stop=100, num=5), index=['a', 'b', 'c', 'd', 'e'])
print(s.shape) # 结构
print(s.size) # 元素数目
print(s.index) # 索引
print(s.values) # 值
(5,)
5
Index(['a', 'b', 'c', 'd', 'e'], dtype='object')
[ 0. 25. 50. 75. 100.]
Series的常用方法
- head(),tail()
- unique()
- isnull(),notnull()
- add() sub() mul() div()
s = Series(data=np.linspace(start=0, stop=100, num=5), index=['a', 'b', 'c', 'd', 'e'])
print(s.head(3)) # 前3
print(s.tail(3)) # 后3
s1 = Series(data=[1, 1, 2, 2, 3, 3])
print(s1.unique()) # 去重,返回numpy数组
print(s1.nunique()) # 去重后的元素个数
print(s1.value_counts()) # 统计元素出现的次数
s2 = Series([1, 2, 3, 4, 5], index=['a', 'b', 'c', 'd', 'e'])
s3 = Series([1, 2, 3, 4, 5], index=['a', 'b', 'c', 'f', 'e'])
s4 = s2 + s3 # 索引一致的元素进行计算
print(s4)
print(s4.isnull()) # 判断每个元素是否为空,为空返回True notnull也可以
# 如何去除series内的空值,布尔值可以作为series的索引使用
print(s4[[True, True, True, False, True, False]])
print(s4.notnull())
# 直接将notnull作为清洗空指的索引
print(s4[s4.notnull()])
print(s4[~s4.isnull()]) # 等同于notnull
print(s4.sum()) # 求和
print(s4.mean()) # 求均值
print(s4.std()) # 求标准差
DataFrame
表格型的数据结构,也就是series从一维上升到多维,分为行索引、列索引、值,三部分组成
df1 = DataFrame(data=np.random.randint(0, 100, size=(5, 6)))
print(df1)
result:
0 1 2 3 4 5
0 1 92 13 0 23 54
1 37 98 42 22 41 30
2 21 43 96 49 35 99
3 58 3 19 3 59 70
4 16 33 83 46 89 1
dic = {
'name': ['xiao', 'li', 'li'],
'salary': [10000, 20000, 30000]
}
df2 = DataFrame(data=dic) # 字典的key作为列索引,行为默认
print(df2)
df3 = DataFrame(data=[[1, 2, 3], [4, 5, 6]], index=['a', 'b'], columns=['A', 'B', 'C']) # index为行索引,colums为列索引
print(df3)
DataFrame的属性
- values、columns、index、shape
df3.values
df3.columns
df3.index
df3.shape
- 索引操作
- 取单列:df[col]
- 取多列:df[[col1,col2,…]]
- 取单行:df.iloc[index]
- 取多行:df.iloc[[index1,index2,…]]
- 取元素:df.iloc[index,col]
- 切片操作
- 切行:df[index1:index3]
- 切列:df.iloc[:,col1:col3]
df3 = DataFrame(data=[[1, 2, 3], [4, 5, 6]], index=['a', 'b'], columns=['A', 'B', 'C']) # index为行索引,colums为列索引
print(df3)
df = DataFrame(data=np.random.randint(0, 100, size=(6, 8)))
print(df)
print(df[0]) # 取的第0列
print(df[[1, 2, 3]]) # 取多列
print(df.iloc[0]) # 取第0行
print(df.iloc[[1, 2, 3]]) # 取多行 loc取显示索引,iloc取隐式索引,可兼容
print(df3.loc[0])
print(df[0:3]) # 切行
print(df.iloc[:, 0:3]) # 切列
- 时间数据类型的转换
- pd.to_datetime(col)
- 将某一列设置为行索引
- df.set_index()
# to_datetime将字符串转换为时间类型
dic = {
'hire_date': ['2020-01-01', '2011-10-09', '2018-10-07'],
'name': ['zhangsan', 'lisi', 'wangwu']
}
df = DataFrame(data=dic)
print(df.dtypes) # object
print(pd.to_datetime(df['hire_date'])) # datetime64[ns]
print(df.index)
# 将某一列设置为行索引
print(df.set_index('hire_date'))
- 信息输出info()
- 每一列统计指标输出describe()
df = DataFrame(data=np.random.randint(0, 100, size=(10, 5)))
print(df)
df.iloc[2, 3] = None
df.iloc[4, 4] = None
print(df)
# info() 返回dataframe的信息,可查到那些列中存有空数据,查看每一列的数据类型
print(df.info())
# describe() 返回dataframe每一列的指标统计结果
print(df.describe())
print(df.describe([.1, .3, .5, .7, .9, .99])) # 自定义中位数的范围
股票分析案例
# 导包获取数据
import tushare as ts
import pandas as pd
data = ts.get_k_data(code='600519',start='1900-01-01')
data.to_csv('./maotai.csv') # 保存成csv文件
df = pd.read_csv('./maotai.csv') # pandas读取csv文件
# df结果如下图
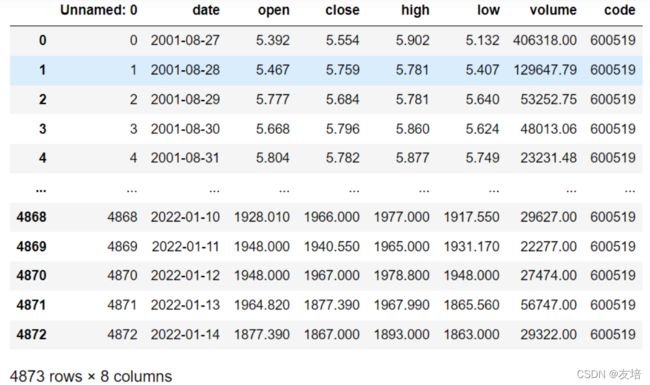
# 上图结果明显多一列,在drop系列函数和take函数中axis0表示行,1表示列
df.drop(labels='Unnamed: 0',axis=1,inplace=True) # inplace改变原df
# df现在结果如下图
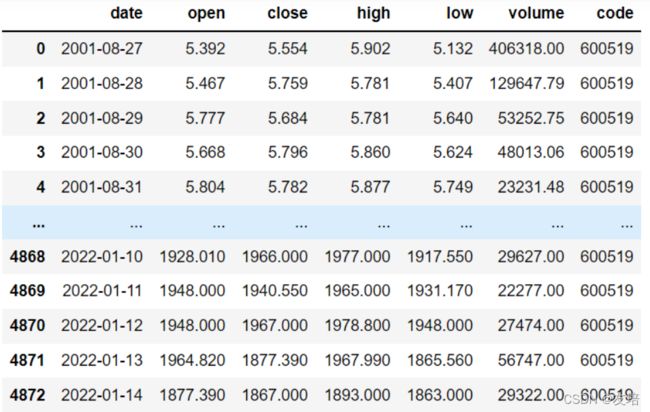
# 将date列转换为时间类型,再变成此df的行索引
df['date'] = pd.to_datetime(df['date'])
df.set_index('date',inplace=True)
# df现在结果如下图
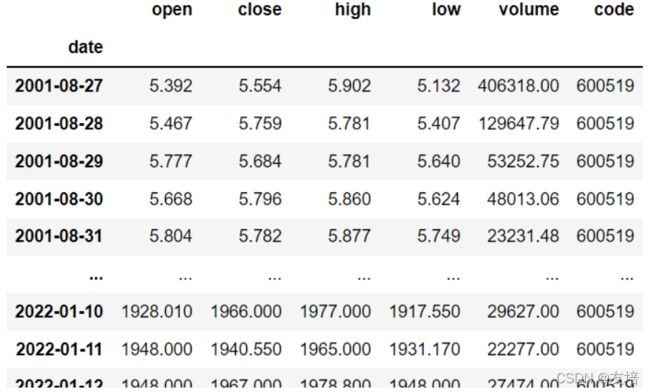
需求一:输出该股票所有收盘比开盘上涨3%以上的日期
#(收盘-开盘)/开盘 > 0.03
ex = (df['close']-df['open'])/df['open']>0.03
# 如何获取上一步True对应的索引:将布尔值作为df的行索引
df.loc[ex].index
# 日期结果为下图

需求二:输出该股票所有开盘比前日收盘跌幅超过2%的日期
# 和需求一类似,只是需要将每天收盘数据往下移动一个单元格
# (开盘-前日收盘)/前日收盘 < -0.02
ex = (df['open']-df['close'].shift(1))/df['close'].shift(1) < -0.02
df.loc[ex].index
需求三:假如我从2010年1月1日开始,每月第一个交易日买入1手股票,每年最后一个交易日卖出所有股票,到今天为止,我的收益如何?- 股票的单价:
- 买入股票的单价使用当日的开盘价,使用当日的收盘价出售股票
- 一个完整的年:
- 买入12手1200支股票
- 股票的单价:
new_df = df.loc['2010':'2022'] # 获取2010-2022的行,切片
df_monthly = new_df.resample(rule='M').first() # 按照月份分组,并不是直接按照月份而是按照年和月份,然后取第一条数据,也就是当月买入的数据
cost_money = df_monthly['open'].sum()*100 # 计算总花费的费用,一手表示100支
df_yearsly = new_df.resample(rule='A').last() # 按年分,取每年最后一条数据
df_yearsly = df_yearsly.iloc[:-1] # 这里需要切除当前年份最后一条,因为今年还没过去,不会卖出,只会每月首日买入
# 下图为df_yearsly
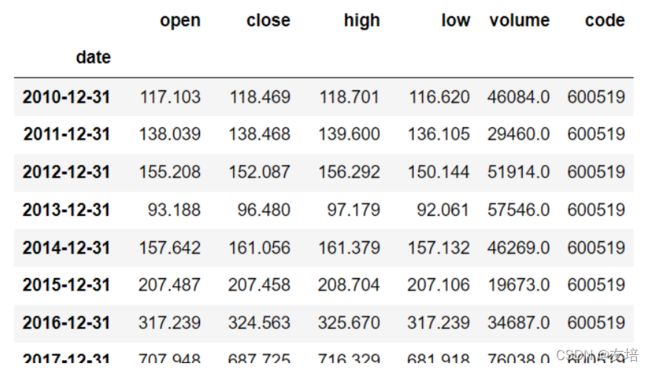
resv_money = df_yearsly['close'].sum()*1200 # 计算总共卖出所得,注意,这里不含当前年,上面已去除
# 将没有卖出去的股票大致估价,将估价计算到总收益中,当前时间为2022-1-17,所以就只入手了1月
last_price = df.iloc[-1]['close'] # 利用现有数据最后一条关盘价计算未卖出收益
last_money = last_price * 1 *100
last_money+resv_money-cost_money # 最后结果,茅台肯定是赚的,啊哈哈
经典案例:利用金融股票的金叉死叉,求出金叉死叉时间点
# 全新股票的数据
import tushare as ts
import pandas as pd
# 和之前操作类似,不再赘述
data = ts.get_k_data(code='000001',start='2000-01-01')
data.to_csv('./pingan.csv')
df = pd.read_csv('./pingan.csv')
df.drop(labels='Unnamed: 0',axis=1,inplace=True)
df['date'] = pd.to_datetime(df['date'])
df.set_index('date',inplace=True)
- 计算该股票历史数据的5日均线和30日均线
- 什么是均线?
- 对于每一个交易日,都可以计算出前N天的移动平均值,然后把这些移动平均值连起来,成为一条线,就叫做N日移动平均线。移动平均线常用线有5天、10天、30天、60天、120天和240天的指标。
- 5天和10天的是短线操作的参照指标,称做日均线指标;
- 30天和60天的是中期均线指标,称做季均线指标;
- 120天和240天的是长期均线指标,称做年均线指标。
- 对于每一个交易日,都可以计算出前N天的移动平均值,然后把这些移动平均值连起来,成为一条线,就叫做N日移动平均线。移动平均线常用线有5天、10天、30天、60天、120天和240天的指标。
- 均线计算方法:MA=(C1+C2+C3+…+Cn)/N C:某日收盘价 N:移动平均周期(天数)
- 什么是均线?
# rolling函数拿到5 30 日数据,再用mean函数求均值
ma5 = df['close'].rolling(5).mean()
ma30 = df['close'].rolling(30).mean()
# 原df加两列
df['ma5'] = ma5
df['ma30'] = ma30
# 舍弃前三十天数据,因为之前数据有为空的,所以直接丢掉
df = df[30:]
# 制图查看结果,结果如下图
import matplotlib.pyplot as plt
plt.plot(ma5[0:100],c='red')
plt.plot(ma30[0:100],c='blue')
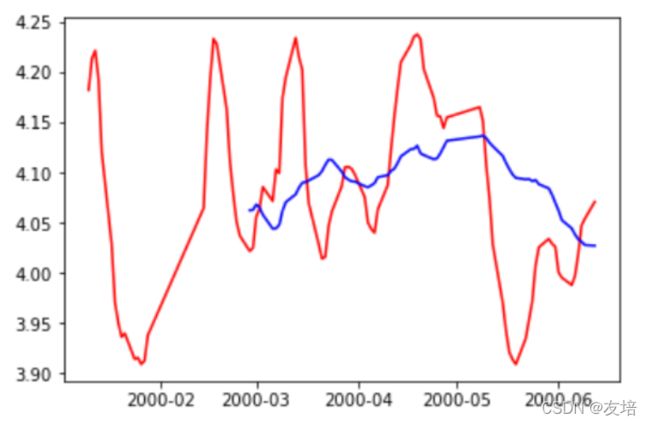
- 分析输出所有金叉日期和死叉日期
- 股票分析技术中的金叉和死叉,可以简单解释为:
- 分析指标中的两根线,一根为短时间内的指标线,另一根为较长时间的指标线。
- 如果短时间的指标线方向拐头向上,并且穿过了较长时间的指标线,这种状态叫“金叉”;
- 如果短时间的指标线方向拐头向下,并且穿过了较长时间的指标线,这种状态叫“死叉”;
- 一般情况下,出现金叉后,操作趋向买入;死叉则趋向卖出。当然,金叉和死叉只是分析指标之一,要和其他很多指标配合使用,才能增加操作的准确性。
- 股票分析技术中的金叉和死叉,可以简单解释为:
# 按照上面言语的理解也就是之前计算的
# ma5 ma5>ma30 ---> 金叉
# ma5>ma30 ---> ma5 死叉
# ma5
# ma5>ma30 == s2
# 出现T表示s1成立,s1和s2也是对立面
| 关系式 | ||||||
|---|---|---|---|---|---|---|
| s1 | T | T | F | F | T | |
| s2 | F | F | T | T | F | |
| s2.shift(1) | F | F | T | T | F | |
| s1 & s2.shift(1) | F | F | F | T | ||
| s1 | s2.shifit(1) | T | F | T | T | ||
| ~(s1 | s2.shift(1)) | F | T | F | F |
# 上表不难发现
# 所求金叉点就是s1 & s2.shift(1)为True的点
# 所求死叉点就算~(s1 | s2.shift(1))为True的点
# 赋值s1、s2
s1 = ma5 < ma30
s2 = ma5 > ma30
# 死叉点,将一组布尔值作为索引条件
ex = s1 & s2.shift(1)
death_df = df.loc[ex]
death_df.index
# 金叉点,将一组布尔值作为索引条件
ex = ~(s1 | s2.shift(1))
gold_df = df.loc[ex]
gold_df.index
- 假如从2010年1月1日开始,初始资金为100000元,金叉尽量买入,死叉全部卖出,则到今天为止,炒股收益率如何?
- 分析:
- 买卖股票的单价使用开盘价
- 买卖股票的时机
- 最终手里会有剩余的股票没有卖出去
- 会有。如果最后一天为金叉,则买入股票。估量剩余股票的价值计算到总收益。
- 剩余股票的单价就是用最后一天的收盘价。
- 会有。如果最后一天为金叉,则买入股票。估量剩余股票的价值计算到总收益。
golden_date = gold_df.index # 金叉时间
death_date = death_df.index # 死叉时间
first_money = 100000 # 本金
money = 100000
s1 = pd.Series(data=1,index=golden_date) # value为1,索引为金叉时间
s2 = pd.Series(data=0,index=death_date) # value为0,索引为死叉时间
s = s1.append(s2)
s = s.sort_index() # value为0是死叉时间,value为1是金叉时间
hold = 0
hand = 0
for index in range(len(s)):
if s[index] ==1 : # 金叉出现
date = s.index[index]
price = df.loc[date]['open'] # 买入股票的单价
hand = money // (price * 100) # 可以买多少手股票
hold = hand * 100 # 共买多少支股票
money -= hold * price
else: # 死叉出现
date = s.index[index]
price = df.loc[date]['open']
money += hold * price
hand = 0
hold = 0
# 判定最终手里是否还有剩余股票
last_money = hold * df.iloc[-1]['open']
#总收益:
money + last_money - first_money
数据清洗
import numpy as np
import pandas as pd
from pandas import DataFrame
空值数据
- 有两种丢失数据:
- None
- np.nan(NaN)
type(None),type(np.nan)
result:
(NoneType, float)
# 创建有空值的df
df = DataFrame(data=np.random.randint(0,100,size=(10,8)))
df.iloc[3,3] = None
df.iloc[4,5] = np.nan
df.iloc[6,6] = np.nan
df.iloc[6,5] = None
如何处理丢失数据?
# 方式1:
# isnull和any组合
# any:返回空所对应的行/列
ex = df.isnull().any(axis=1)
# 将空数据行取出
null_row_index = df.loc[ex].index
# 删除空列
df.drop(labels=null_row_index,axis=0)
# notnull和all组合
# all会检测一组数据是否全部为True,不是则返回False
ex = df.notnull().all(axis=1)
# 方式2:
# dropna:可以直接将缺失的行或者列进行删除
df.dropna(axis=0)
# 方式3:
# 使用任意值填充空值
df.fillna(value=666)
# 使用近邻值填充空指
# method:ffill(向前填充) 或者 bfill(向后填充)
# axis:0表示列填充,1表示行填充
df.fillna(method='ffill',axis=1)
现有原始数据如下图
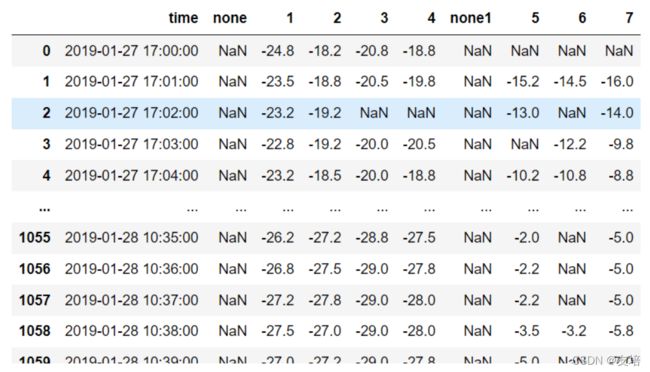
# 对上图数据清洗
data = pd.read_excel('./testData.xlsx')
# 删除多列labels是列表
data.drop(labels=['none','none1'],axis=1,inplace=True)
# 空值数据清洗:1、删除 2、补全
# 1、删除带有空值行
data.loc[data.notnull().all(axis=1)]
# 2、空值进行填充,先进行向前列填充,再向后列填充
data.fillna(method='ffill',axis=0).fillna(method='bfill',axis=0)
重复数据
# 制造重复数据
df = DataFrame(data=np.random.randint(0,100,size=(8,4)))
df.iloc[2] = [1,1,1,1]
df.iloc[4] = [1,1,1,1]
df.iloc[6] = [1,1,1,1]
# 1、分布进行
# 检查df哪些数据是重复的,keep表示取那一条,因为去重 要留一条,默认保留第一次出现
df.duplicated(keep='last')
# 过滤重复的
df.loc[~df.duplicated()]
# 2、合并操作
# 检验和删除基于一个方法实现
df.drop_duplicates(inplace=True)
异常数据
- 自定义一个1000行3列(A,B,C)取值范围为0-1的数据源,然后将C列中的值大于其两倍标准差的异常值进行清洗
df = DataFrame(data=np.random.random(size=(1000,3)),columns=['A','B','C'])
# 两倍标准差
twice_std = df['C'].std()*2
# 判定异常值条件
ex = df['C']>twice_std
# 布尔值作为过滤,得出结果
df.loc[~ex]