哈工大李治军操作系统--进程与线程
CPU/进程管理初探
操作系统是管理硬件的,CPU是最主要的硬件。本节展示了多道程序设计以及引出进程的概念。如何使用CPU呢?让程序跑起来,CPU就一直取指执行了。如何充分利用CPU呢?启动多个程序,交替执行。
多道程序设计(并发)
先看一个例子,下面代码让无I/O指令执行10000000次,而让I/O指令执行10000次,发现前者用时竟然比后者用时还要短!笔者使用的还是固态硬盘!

显然,I/O操作非常耗时,当CPU运行一个程序的时候,遇到了I/O操作,如果一直等I/O完成再执行后续的指令的话,CPU会空转很长时间,导致CPU利用率大大下降。但是如果CPU此时暂时离开去执行别的程序,那么CPU空转时间就会大大减少,提高CPU的利用率。下面就是一个展示多道程序设计的例子。

进程的提出
CPU面对多道程序,在多个程序之间切换,就需要记录每个程序的现场信息(用PCB记录),以便再切回到一个程序时可以恢复。程序是静态的,但进程需要记录运行程序的现场信息等。可以简单地认为进程就是运行的程序。
多进程图像
多进程图像就是多个进程交替推进的样子。对于普通用户来说,打开任务管理器,就可以看到各个进程的样子,比如对CPU、内存的使用情况等;对于操作系统来说,操作系统就会创建并维护好各个进程的PCB,保证多进程合理地向前推进。
linux/init/main.c中的main()函数完成内核初始化后执行if (!fork()) { init(); }代码,而init()函数就是启动一个shell(Windows启动一个窗口桌面),供用户使用。而shell中输入命令执行还是创建一个进程。自计算机开机到关机多进程图像就伴随始终,是操作系统的核心图像。
// shell的核心代码
int main(int argc, char * argv[])
{
while(1)
{
scanf(“%s”, cmd);
if(!fork())
{
exec(cmd);
}
wait();
}
}
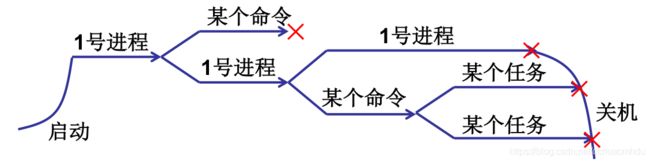
总之,用户使用计算机就是启动若干进程,用户/操作系统管理计算机就是管理这些进程。
多进程组织(PCB队列+状态)
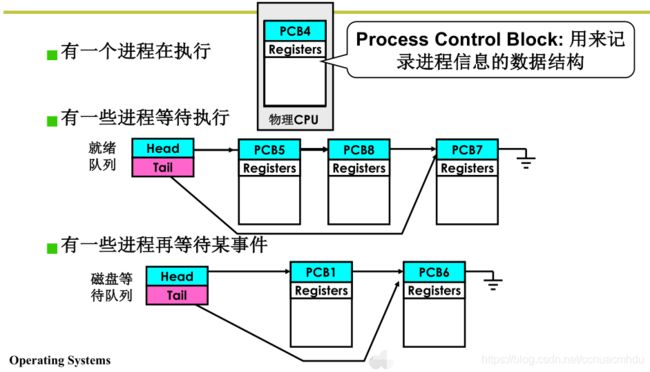

多线程交替(队列操作+调度+切换)
举一个例子,如下。
启动磁盘读写;
pCur.state = ‘W’; // 运行状态 -> 等待状态
将 pCur 放到 DiskWaitQueue; // 当前进程PCB pCur 进入等待队列(队列操作)
schedule(); // 调度+切换
schedule()
{
pNew = getNext(ReadyQueue); // 从就绪队列中调度一个进程,新进程的PCB是 pNew
switch_to(pCur,pNew); // 从 pCur 进程切换到 pNew 进程,当前现场信息存
// 入pCur,用pNew信息恢复现场(CPU各寄存器等),
// 这需要精细控制(汇编实现)
}
多进程带来的问题
如下图,进程1修改了进程2地址空间的数据,这很糟糕!怎么办?多进程的地址空间相互隔离(内存管理的主要内容)。

如下图,通过映射表把某进程的访问限制在自己的地址范围内,确保访问不到其他进程的内容。
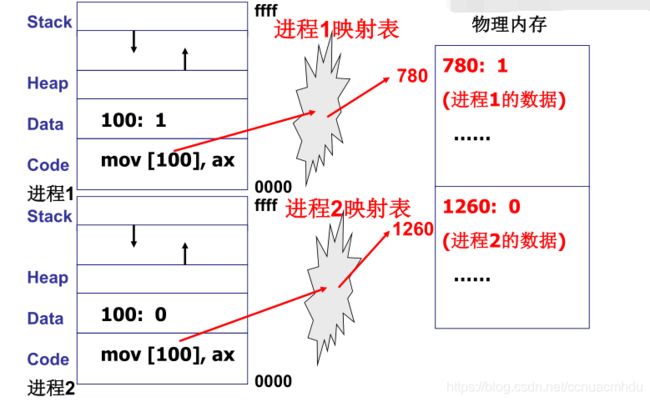
多进程合作
下面例子是说进程1和进程2同时向空闲区域7放入要打印的东西,由于多进程交替执行,有可能进程1还没有把东西全部放到7区域,进程2就开始在7区域放东西了,导致进程1和进程2打印的东西揉在了一起。
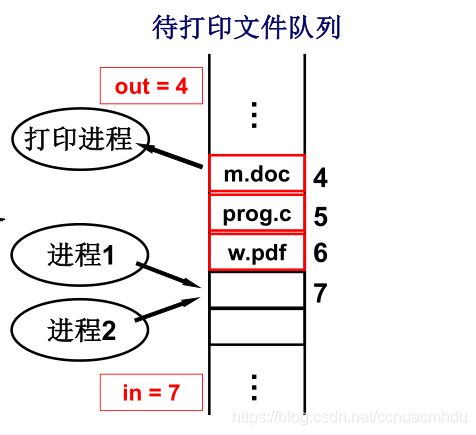
下面以生产者-消费者问题展示下多进程的合作,本节课只是简单介绍,后续章节会细致讲解。

下面是一个导致错误的示例。
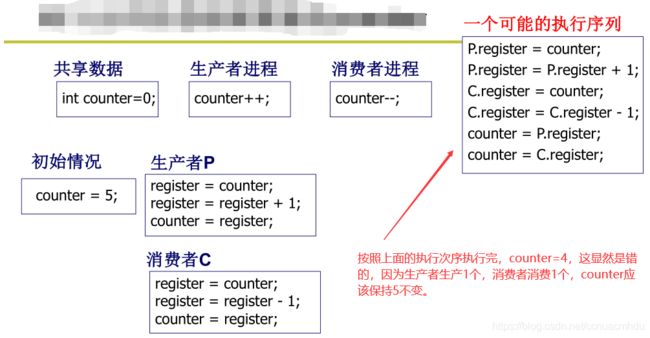
下面是解决错误的方法。

线程
用户级线程
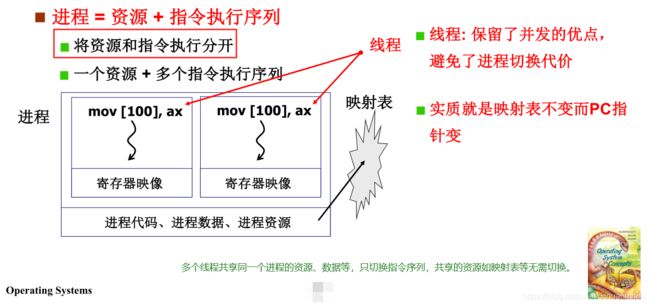
李老师使用了网页加载的例子展示了多线程的优势。当我们在浏览器的地址栏中输入一个网址的时候,需要从服务器下载网页数据,需要显示文本信息,需要处理图片(如解压缩),还需要显示图片等,这些需求都各自开一个线程,交替执行。特别是网速不好的时候,用户可以感觉到网页是一点点加载出来了,刚开始显示一个轮廓,而后细节越来越清晰。但如果不是多线程交替执行,数据下载完之后再显示,那么就会导致刚开始的时候网页一直卡顿了,用户似乎觉得自己断网了的感觉,不利于用户体验。
李老师举的这个例子中,使用多线程交替执行,合作往前推进。为啥不用多进程呢?如果用多进程,那么从服务器下载数据的进程把数据下载下来放在自己进程的缓冲区,而显示文本信息的进程还需要把这些数据读到自己的缓冲区,这既费时间又费空间!而多线程就没这个问题,多线程共享这些资源,当然还有前述所说的切换开销小等优势!
用户级线程切换(核心)
先让两个线程共用一个栈,看看有没有问题。

看来,两个线程应该各自搞一个栈。普通函数调用只能在自己线程里面跳来跳去,只有Yield()函数调用才会切换线程。下面每个线程搞一个栈,玩一玩,看看如何?

用户级多线程的缺点如下示例。
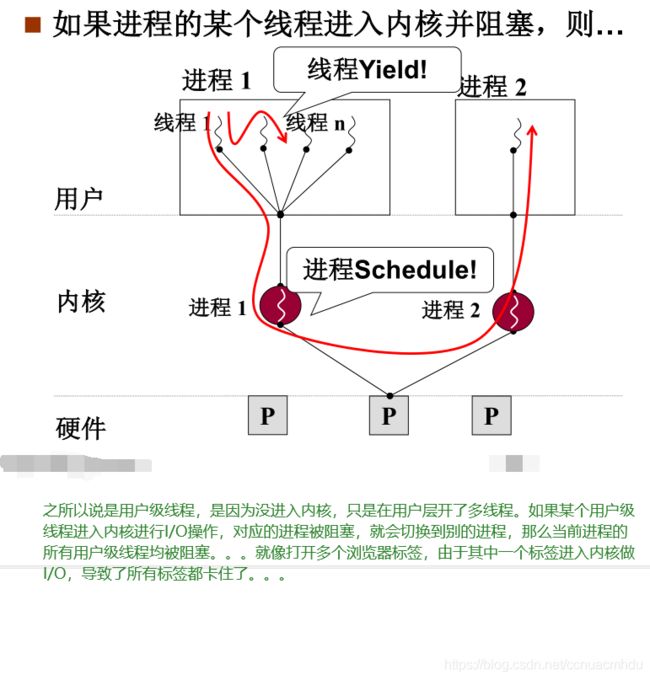
内核级线程
没有用户级进程这一说,进程就是内核管理的,只有内核才能为进程分配资源等。上面说了用户级线程,这里说内核级线程。

内核级多线程优势举例如下。

从用户级线程引出内核级线程,用户级线程不会进入内核,一个用户级线程只需要一个用户栈,但内核级线程可以在用户态和内核态运行,内核级线程需要两个栈,一个是内核态用的内核栈,另一个是用户态用的用户栈。
一段代码大部分是在用户态执行的,有时需要系统调用进入内核。通过中断(INT)可从用户态进入内核态,此时需要从用户栈切换到内核栈,为了从内核顺利返回到用户态,在进入内核之前需要把用户态下的SS/SP/EFLAGS/IP/CS等信息压入内核栈,等系统调用完成后(中断返回IRET),从内核栈中弹出信息,就可以顺利从之前的用户态执行到的地方继续执行,并且使用的是用户栈。
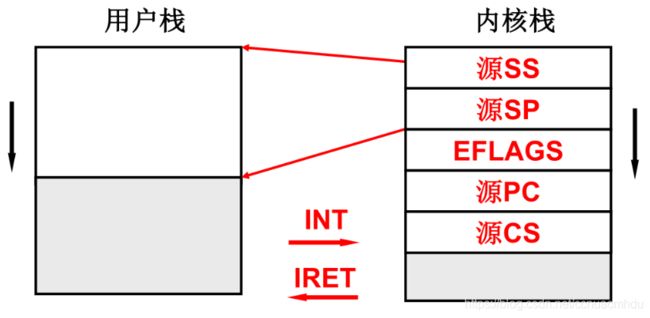
内核级线程切换(核心)
S线程,看下图,从100处执行用户程序,A()函数调用B()函数,104入栈,B()函数调用read()函数,204入栈,read()函数执行int 0x80中断,内核栈压入此时用户态的SS/SP/EFLAGS/IP/CS等(此时用户态的IP=304),然后进入内核程序,执行system_call处代码,调用sys_read函数,把1000压入内核栈,进入sys_read函数内执行。
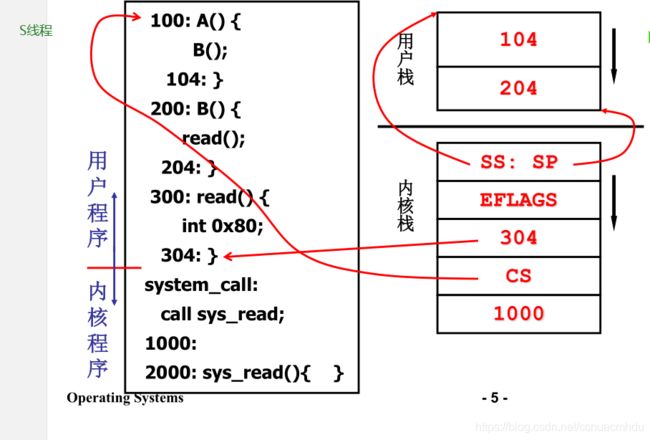
S线程在内核执行sys_read函数的时候,启动磁盘读,进行I/O操作,于是乎内核就进行调度switch_to(cur, next);(cur是S线程的TCB,next是T线程的TCB),把S线程使用的核分配给T线程,于是乎就要完成S线程切换到T线程,需要把S线程应该执行的下一个指令地址压入S线程的内核栈,并把S线程的现场保存到S线程的TCB中,然后使用T线程的TCB恢复T线程的现场,当然此时esp指向T线程的栈顶,而遇到switc_to函数的右大括号}时就会弹栈,弹出的就是T线程之前执行到的地址,于是乎T线程接着之前执行到的地方继续执行。而此时T线程在内核态执行一些代码后,势必还是会回到T线程的用户态的,那么会遇到IRET,返回到T线程的用户态,怎么返回到T线程的用户态呢?T线程内核栈中弹出之前压入的T线程的用户态对应的CS/IP/SP/SS等信息,恢复到T线程的用户态执行。

上面搞懂之后,可以发现,内核级线程切换其实必须在内核中切换,用户态根本就不可能发生切换!
Linux0.11不支持线程,全是进程,并且是通过PCB找到TSS再利用TSS(TSS是PCB的一部分)完成进程切换的(把所有现场全部恢复,消耗大),没有采用上述线程切换所说的压栈弹栈的方式(消耗小)。李老师的实验4就是让我们把切换方式改成基于TCB及压栈弹栈的方式。
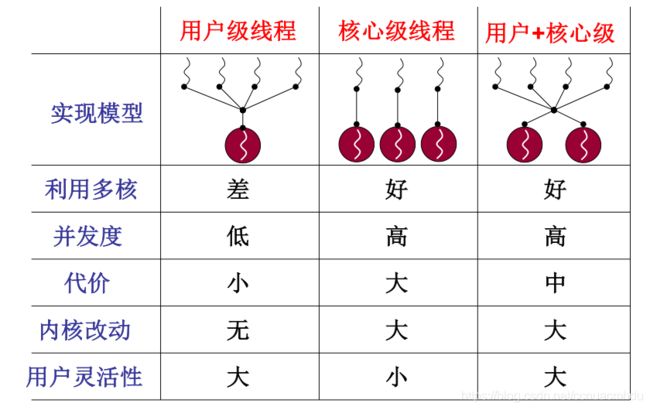
用户级线程和内核级线程对比
进程调度策略
Linus在Linux 0.11中调度进程的算法非常巧妙,只维护一个变量counter(时间片数)就综合考虑了多种调度策略,神啊!
信号量
进程合作示例
生产者-消费者问题



临界区:一次只允许一个进程进入的那一段代码。自然,只有被多个进程共享才是临界区。不存在共享就不存在竞争,不可能因竞争出错,不是临界区。
保护临界区资源,最低要求是互斥,最好还能满足有空让进(若干进程要求进入空闲临界区时,应尽快使一进程进入临界区)和有限等待(从进程发出进入请求到允许进入,不能无限等待等)。
硬件方法一:可以在进入临界区之前关闭中断,从临界区出来再打开中断。没有中断就不会发生进程调度,自然不存在多进程竞争临界区资源的情况,但多核不适用,关闭一个核中断,其他核的线程依然可以访问临界区资源。
硬件方法二:可以使用硬件提供的原子指令法,就是几条指令的执行是原子性的,要么不执行,要么全部执行。
软件方法一:轮转法。

软件方法二:Peterson算法。


软件方法三:面包店算法(略)。
死锁
死锁的四个必要条件

银行家算法
用来死锁避免。
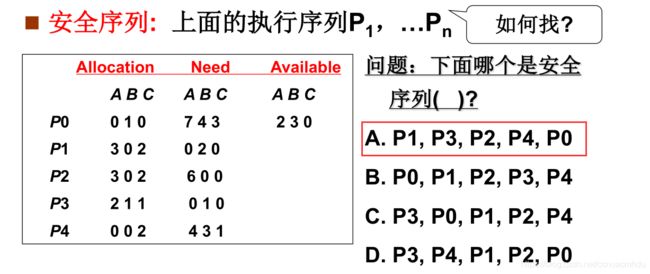
算法复杂度高,每个计算机有很多进程和资源,如果每个进程每次申请资源就得跑一遍银行家算法,这样搞的话,计算机卡死了!
死锁预防就要破坏死锁出现的条件,编程特别困难;死锁避免比如银行家算法,耗时太久;死锁检测及恢复,恢复太难;死锁忽略就是啥都不干。大多数非专门的操作系统(Unix/Linux/Windows)都是死锁忽略的,因为死锁出现的概率小,并且还可以通过重启解决死锁,也可以查看任务管理器消耗大的进程杀死。
参考资料
[1] 中国大学MOOC《操作系统》李治军 哈尔滨工业大学
[2] 《Linux内核完全注释》赵炯
[3] BIOS中断大全
[4] 汇编语言最全指令表
[5] 《x86汇编语言:从实模式到保护模式》李忠 著
[6] https://blog.csdn.net/ccnuacmhdu/article/details/104946213