- 摘要
- 1、引言
- 2、提出的方法
- 2.1 CentroidTripletloss
- 2.2 聚合表示
- 3、实验
- 3.1 数据集
- 3.2 应用细节
- 3.3 Fashion检索结果
- 3.4 行人再识别结果
- 3.5 内存使用和推理时间
- 4、总结
论文地址:https://openaccess.thecvf.com/content/ICCV2021/html/Wong_Persistent_Homology_Based_Graph_Convolution_Network_for_Fine-Grained_3D_Shape_ICCV_2021_paper.html
代码:https://github.com/mikwieczorek/centroids-reid
摘要
图像检索任务包括从一组图库(数据库)图像中找到与查询图像相似的图像。这样的系统用于各种应用,例如行人重新识别(ReID)或视觉产品搜索。尽管检索模型正在积极发展,但它仍然是一项具有挑战性的任务,主要是由于视角、光照、背景杂波或遮挡的变化引起的类内方差大,而类间方差可能相对较低。当前的大部分研究都集中在创建更强大的特征和修改目标函数上,通常基于TripletLoss。一些作品尝试使用类的质心/代理表示来缓解与TripletLoss一起使用的计算速度和硬样本挖掘问题。然而,这些方法仅用于训练并在检索阶段被丢弃。在本文中,我们建议在训练和检索期间都使用平均质心表示。这种聚合表示对异常值更稳健,并确保更稳定的特征。由于每个类都由单个嵌入类质心表示-检索时间和存储需求都显着减少。由于减少了候选目标向量的数量,聚合多个嵌入导致搜索空间显着减少,这使得该方法特别适用于生产部署。在两个ReID和时尚检索数据集上进行的综合实验证明了我们的方法的有效性,它优于当前最先进的方法。我们建议将质心训练和检索作为时尚检索和ReID应用程序的可行方法。
1、引言
实例检索是将查询图像中的对象与画廊集中的图像表示的对象进行匹配的问题。检索系统的应用涵盖行人/车辆重新识别、人脸识别、视频监控、显式内容过滤、医学诊断和时尚检索。
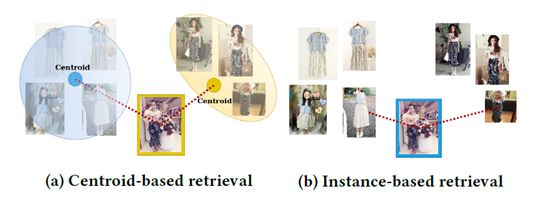
大多数现有的实例检索解决方案都使用深度度量学习方法[1,3,6,7,13,16],其中训练深度学习模型将图像转换为向量表示,以便来自同一类的样本接近彼此。在检索阶段,查询嵌入对所有图库嵌入进行评分,并返回最相似的嵌入。直到最近,很多工作都使用分类损失来训练检索模型[8,14,15,17,20]。目前大多数作品都使用comparative/ranking losses,而TripletLoss是最广泛使用的方法之一。然而,最先进的解决方案通常将比较损失与辅助损失(如分类或中心损失)结合起来[5、7、12、13、16]。
尽管TripletLoss优于大多数其他方法,但它存在许多工作[2,16,18,21]表明的问题:1)硬负采样是创建训练批次的主要方法,该批次中仅包含信息量大的三元组,但它可能会导致局部最小值不佳并阻止模型达到最佳性能[2,18];2)硬负采样计算量大,因为需要计算批次中所有样本之间的距离[2,16];3)TripletLoss由于硬负采样和点对点损失的性质而容易出现异常值和噪声标签[16,18]
为了缓解TripletLoss的点对点性质引起的问题,提出了point-to-set/point-to-centroid公式,其中测量样本和代表类的原型/质心之间的距离。质心是每个项目的多个表示的聚合。质心方法导致每个项目嵌入一个,从而降低内存和存储需求。有许多方法可以研究原型/质心公式,它们的主要优点如下:1)更低的计算成本[2,16],甚至是线性复杂度而不是三次[2];2)对异常值和噪声标签具有更高的鲁棒性[16,18];3)更快的训练[11];4)与标准点对点三元组损失相当或更好的性能[5,11,16]。
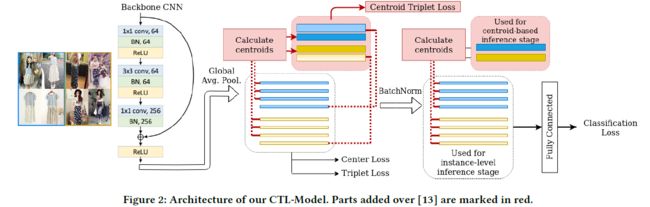
我们建议更进一步,使用基于质心的方法进行训练和推理,并将其应用于时尚检索和人员重新识别。我们通过使用我们称为CentroidTripletLoss的新损失函数来增强当前最先进的时尚检索模型[13]来实现我们的基于质心的模型。基线模型有许多同时优化的损失,它们解释了检索问题的各个方面。因此,可以很容易地添加一个额外的基于质心的损失,以修正一个反复出现的问题:对对象画廊的可变性缺乏鲁棒性。质心是通过对图像表示的简单平均来计算的。我们表明,这种简单的模型修正可以降低请求的延迟并降低基础设施成本,同时在各种评估协议、数据集和域中产生新的最先进的结果。我们还讨论了为什么与标准的基于图像的方法相比,这种检索问题的表述是可行和有利的。
这项工作的贡献有四个:
•我们引入了CentroidTripletLoss-一种用于实例检索任务的新损失函数•我们建议在检索过程中使用类质心作为表示。
•我们通过彻底的实验表明,基于质心的方法在不同的数据集和领域(时尚检索和人员重新识别)中建立了新的最先进的结果。
•我们表明,与标准实例级方法相比,基于质心的检索任务方法可显着加快推理速度并节省存储空间。
2、提出的方法
图像检索任务旨在找到与查询图像最相似的对象。在时尚检索和人物重新识别中,它通常是在实例级别的基础上完成的:每个查询图像都针对图库中的所有图像进行评分。如果一个对象分配了多个图像(例如,在可变照明条件下来自多个视点的照片),则每个图像都被单独处理。因此,同一对象可能会在排名结果中出现多次。这样的协议可能是有益的,因为它允许匹配在类似情况下以类似角度拍摄的图像,描绘对象的相同部分或特写细节。另一方面,优势很容易变成劣势,因为完全不同对象的细节照片可能与查询图像中的细节相似,从而导致错误匹配。
我们建议使用所有可用样本的聚合项目表示。这种方法产生了一个鲁棒的表示,它不太容易受到单图像错误匹配的影响。使用聚合表示,每个项目由单个嵌入表示,从而显着减少搜索空间,节省内存并显着减少检索时间。除了在检索过程中计算效率更高之外,与非基于质心的方法相比,基于质心的方法还改善了检索结果。请注意,在基于质心的设置中训练模型不会将评估协议限制为仅质心评估,而且还改进了实例级评估的典型设置中的结果。
2.1 CentroidTripletloss
TripletLoss最初适用于锚图像、正(同一类)示例和属于另一个类的负示例。目标是最小化-之间的距离,同时推开样本。损失函数公式如下:
我们提出了CentroidTripletLoss(CTL)。CTL不是比较锚点图像与正例和负例的距离,而是测量和类质心和之间的距离,分别代表与锚相同的类或不同的类。因此,CTL被表述为:
2.2 聚合表示
在训练阶段,每个小批量包含不同的项目类,每个类有个样本,导致批量大小为×。让表示小批量中类别的一组样本,使得S={1,...,}其中表示第i个样本的嵌入,使得∈,是样本表示大小。为了进行有效的训练,来自S的每个样本都用作查询,其余-1个样本用于构建原型质心,可以表示为:
在评估期间,查询图像由查询集Q提供,每个类的质心在检索发生之前预先计算。为了构建这些质心,我们使用图库集G中的所有嵌入用于类。每个类的质心∈被计算为属于给定类的所有嵌入的平均值:
3、实验
3.1 数据集
DeepFashion(时尚检索)。该数据集由[6]引入,包含超过800,000张图像,分布在多个与时尚相关的任务中。我们使用的数据是Consumer-to-shop Clothes Retrieval子集,其中包含33,881种独特的服装产品和239,557张图像。
Street2Shop(FashionRetrieval):该数据集包含超过400,000张商店照片和20,357张街道照片。数据集中总共有204,795件不同的服装。它是第一个现代大规模时尚数据集之一,由[4]引入。
Market1501(PersonRe-identification):它于2015年在[19]中引入,包含1501个类别/身份,分散在32,668个边界框中,由清华大学的6个摄像头捕获。751个类用于训练,750个带干扰项用于评估。
DukeMTMC-reID(PersonRe-identification):它是DukeMTMC数据集[9]的一个子集。它包含1,404个类/身份,702个用于训练,702个和408个干扰身份用于评估。
3.2 应用细节
我们在当前的时尚检索最先进模型[13]之上实现了基于质心的解决方案,该模型本身基于得分最高的ReID模型[7]。我们在ImageNet上预训练的各种基于Resnet的主干上训练我们的模型,并报告时尚检索和行人重新识别任务的结果。我们在基于质心和基于实例的设置中评估模型。基于实例的设置意味着评估成对的图像,与[13]的评估设置相同。我们使用上述论文中提出的相同训练协议(例如随机擦除增强、标签平滑),而不引入任何额外的步骤。
特征提取器:我们测试了两个CNN:Resnet-50和Resnet50IBN-A,以比较我们在这两个网络上的结果。像[7,13]一样,我们使用=1作为最后一个卷积层和Resnet-50原生2048维嵌入大小。
损失函数:[7,13]使用由三部分组成的损失函数:(1)在原始嵌入上计算的三重损失,(2)中心损失[12]作为辅助损失,(3)在批量归一化嵌入上计算的分类损失。为了基于质心训练我们的模型,我们使用相同的三个损失并添加CTL,它是在查询向量和类质心之间计算的。中心损失的权重为5−4,所有其他损失的权重为1。
我们的时尚检索参数配置与[13]中的相同。我们使用基础学习率为1−4的Adam优化器和多步学习率调度器,在第40和第70轮后将学习率降低10倍。就像在[7,13]中一样,中心损失由SGD优化器单独优化,=0.5。每个模型训练3次,每次训练120个epoch。对于人员重新识别,配置与[7]中的配置相同。基础学习率为3.5−4,在第40和第70epoch衰减。每个模型都训练了120个epoch。
重采样:对于TripletLoss,每个类有足够的正样本很重要,但有些类可能只有很少的样本。
因此,如果|S|<定义目标样本大小并重新采样类实例,这是一种常见的做法。,导致小批量中的重复图像。我们凭经验验证,在我们的场景中省略重采样过程是有益的。由于重采样将噪声引入类质心,因此我们仅使用可用的唯一类实例。
检索程序:我们遵循[7]和[13]在推理阶段利用批归一化向量。同样,我们使用余弦相似度作为距离度量。对于ReID数据集,我们使用跨视图匹配设置,该设置在其他ReID论文[7,10]中使用。该协议确保对于每个查询,其由同一相机捕获的图库样本在检索过程中被排除在外。
3.3 Fashion检索结果
表 1:时尚检索结果。型号名称中的S或L表示输入图像尺寸,小(256x128)或大(320x320)。R50或R50IBN后缀表示使用了哪个主干CNN,分别是Resnet50或Resnet50-IBN-A。模型名称末尾的“CE”表示基于质心的评估。
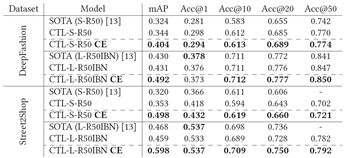
我们在表1中展示了时尚检索的评估结果。我们评估了两个模型:SOTA表示[13]中提出的模型,CTL-我们基于质心的模型。每个模型都以两种模式进行评估:1)基于每个图像的标准实例级评估(对于SOTA和CTL模型),以及2)基于质心的评估,(在表1中用CE表示):CTL模型的评估在每个对象的基础上,每个类的所有图像都用于构建类质心,检索是在质心域中完成的。
我们的CTL模型在所有测试数据集的大多数指标上都比当前的最佳状态表现更好。特别值得注意的是mAP指标的激增,这可以通过使用质心减少搜索空间的事实来解释。使用基于质心的评估减少搜索空间的同时减少了正实例的数量(从几个减少到一个)。另一方面,Accuracy@K指标不受搜索空间变化的影响。
3.4 行人再识别结果

我们在表3中展示了人员重新识别的评估结果。与时尚检索类似,我们评估以下模型:SOTA表示ReID[10]中的当前最先进的模型,CTL-我们基于质心的模型模型。我们只报告CTL模型的基于质心的评估结果,因为以前的方法经常任意限制搜索空间。例如,[10](两个ReID测试数据集上的当前SOTA)在检索期间通过空间和时间约束减少搜索空间,以通过消除人不可能在搜索中移动一定距离的情况来减少候选者的数量给定的时间。他们的方法需要数据集中的额外信息和构建过滤规则所需的世界知识,而不仅仅是图像理解。尽管仅依赖图像匹配,但我们基于质心的搜索空间缩减在两个数据集的所有指标上都取得了几乎相同甚至更好的结果,在大多数指标上都优于[10],并建立了新的最先进的结果。
3.5 内存使用和推理时间
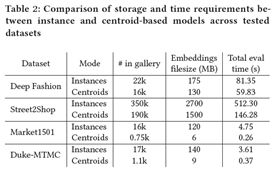
为了测试我们的基于质心的方法与标准的基于图像的检索相比的内存和计算效率,我们比较了评估所有测试数据集所需的挂钟时间和保存所有嵌入所需的存储空间。表2显示了实例级和基于质心场景的所有数据集的统计数据。可以看出,基于质心的方法显着减少了检索时间和存储嵌入所需的磁盘空间。减少的原因是每个类通常有几个图像,因此用质心表示一整组对象图像将成功检索所需的向量数量减少到一个。
4、总结
我们介绍了CentroidTripletLoss-一种用于实例检索任务的新损失函数。我们凭经验证实它显着提高了检索模型的准确性。除了新的损失函数外,我们还建议在检索推理期间使用类质心,进一步提高检索任务的准确度指标。我们的方法在来自两个不同领域的四个数据集上进行了评估:人员重新识别和时尚检索,并在所有数据集上建立了新的最先进的结果。除了提高准确性之外,我们还表明基于质心的推理可以显着提高计算速度并降低内存需求。更高的准确性与更快的推理和更低的资源需求相结合,使我们的方法在应用工业环境中特别有用,例如实例检索。