【认识 NVIDIA GPU】GPU相关基础概念介绍
系列文章目录
文章目录
- 系列文章目录
- 前言
- 基本概念
-
- CUDA(Compute Unified Device Architecture)
- SP(Stream Processor)
- SM(Streaming Multiprocessor)
- Warp
- CUDA Core
- Tensor Core
- RT Core
- SIMD、SIMT
- 总结
- 参考文献
前言
NVIDIA作为GPU这一概念的开创者,其GPU被广泛运用在娱乐、教育、医疗、边缘计算、数据分析等领域。本文针对N卡的入门相关概念进行介绍。
基本概念
CUDA(Compute Unified Device Architecture)
2006 年 11 月,NVIDIA 推出了 CUDA,这是一种通用并行计算平台和编程模型,它利用 NVIDIA GPU 中的并行计算引擎以比在 CPU 上更有效的方式解决许多复杂的计算问题。
GPU的架构变化频繁,每代之间通常都有改变,所以分发机器码很容易出现不兼容或者不优化的情况。需要开发一种能够透明地扩展其并行性以有效利用持续增加的处理器内核的应用软件。本质上来说,CUDA就是用来在GPU上跑通用计算的模型。
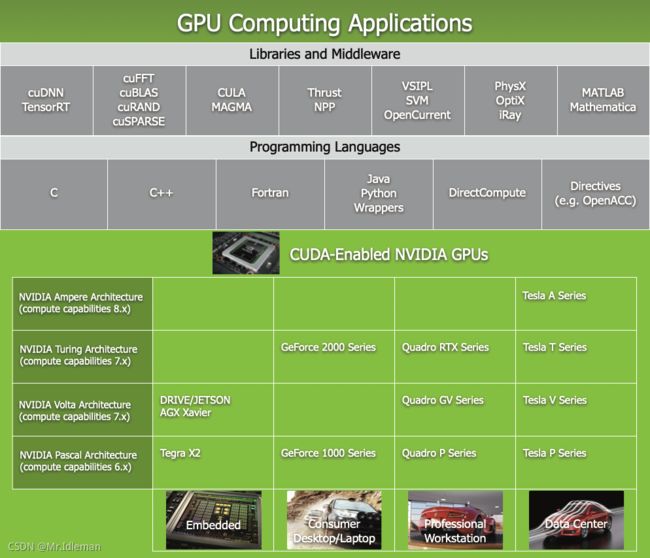
图1. GPU 计算应用实例
CUDA旨在成为支持各种语言和应用程序的编程接口
如图1所示,CUDA 并行编程模型作为一款通用接口,为熟悉 C 等标准编程语言的程序员保持较低的学习曲线。
CUDA将GPU架构建模为多核系统,它将GPU的并行线程抽象为层次化的线程结构(网格状的线程块)。这些抽象指导程序员将问题划分为独立线程块并行解决的子问题,并进一步将每个子问题划分为可以由块内的所有线程并行协作解决的部分。
这种分解通过允许线程在解决每个子问题时进行协作来保持语言表达能力,同时实现自动可扩展性。实际上,每个线程块都可以在 GPU 内的任何可用多处理器上以任何顺序进行调度,以便编译后的 CUDA 程序可以在任意数量的多处理器上执行,如图 2 所示。
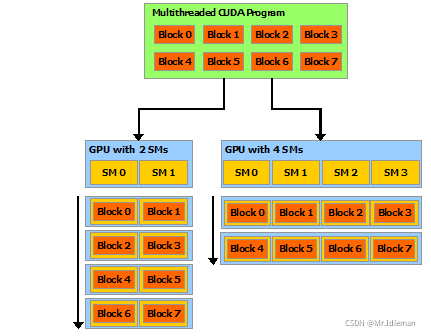
图2.实现自动可扩展性
SP(Stream Processor)
SP被称作流处理器,在G80时英文也曾称(Scalar Processors)、(Scalar Streaming Processors)。这种称呼主要因为之前SP单元是被当作标量的处理单元。在Fermi架构后,SP被改称为CUDA Core。所以对于现在的N卡架构来说,流处理器数量即CUDA Core数量。
SM(Streaming Multiprocessor)
SM是从G80时提出的概念,中文也称流多处理器,包含算术单元以及块和线程专用的其他资源(例如每个块共享内存和寄存器文件),组成了一套完整的线程运行系统。
现如今,SM一般包括:
- 向量运行单元
CUDA Core(FP32-FPU、FP64-DPU(Double Precision Unit)、INT32-ALU); - 张量运算单元
Tensor Core(Volta架构引入) - 特殊函数单元
SFU(Special Function Units,负责执行超越函数和数学函数,如反平方根、正弦、余弦以及单精度浮点乘法等); - 访问存储单元
LD/ST(Load/Store,负责数据处理); - 线程束调度器
Warp Scheduler; - 分配单元
Dispatch Unit; - 寄存器堆
Register File; - 缓存
Cache(L0/L1 Instruction Cache、L1 Data Cache & Shared Memory)
Warp
Warp也称线程束。逻辑上,所有Thread是并行的,但是,从硬件的角度来说,并不是所有的Thread能够在同一时刻执行,这里就需要Warp的引入。
Warp是SM的基本执行单元。在现在的Nvidia GPU里,一个Warp包含32个并行Thread(即warp_size=32),这32个Thread执行于SIMT(Single-Instruction Multiple-Thread)模式。也就是说所有Thread以锁步的方式执行同一条指令,但每个Thread会使用各自的Data执行指令分支。如果在Warp中没有32个Thread需要工作,那么Warp虽然还是作为一个整体运行,但这部分Thread是处于非激活状态的。
可以说,Thread是最小的逻辑单位,Warp是最小的硬件执行单位。
CUDA Core
CUDA Core在Fermi架构里提出,是最小的运算执行单元。
在Fermi架构中,一个SM中包含了有2组各16个CUDA Core,每个CUDA Core 包含了一个整数运算单元ALU (Integer Arithmetic Logic Unit) 和一个浮点运算单元FPU (Floating Point Unit) 。然后,CUDA Core能进行FMA (fused multiply-add) 的操作,通俗一点就是可以在不掉精度的情况下,单指令完成乘加操作,并且这个是支持32-bit精度。
图3.Fermi架构每个 SM 内部结构
更通俗一点,就是深度学习里面的操作变快了,你是否还记得如下的一个公式:
z = w ∗ x + b z=w*x+b z=w∗x+b 在深度学习中,这样的运算太多啦。如果是常规的运算器,会怎么处理呢? 先把寄存器里面的数据送入乘法器,然后把结果送回寄存器,然后再把寄存器的数据送入加法器。当然实际的操作取决于硬件,至少cpu中,一般情况下要多个操作指令。
而CUDA Core可以单指令完成! 这些CUDA Core在显卡里面是并行运算,就是说大家分工计算。CUDA Core越多,算力就越强,于是,我们看到了接来的几代Kepler -> Maxwell -> Pascal,这些CUDA Core肉眼可见的增长。
但是到了Volta架构的时候,CUDA Core又和Fermi架构时期发生了变化。从这里开始就没有以前的CUDA Core了,而是变成了单独的FP32的FPU和INT32的ALU,只不过因为FP32:INT32是1:1,所以还是很方便把它们合并成原来的CUDA Core去称呼。这样做的好处是每个SM现在支持FP32和INT32的并发执行。
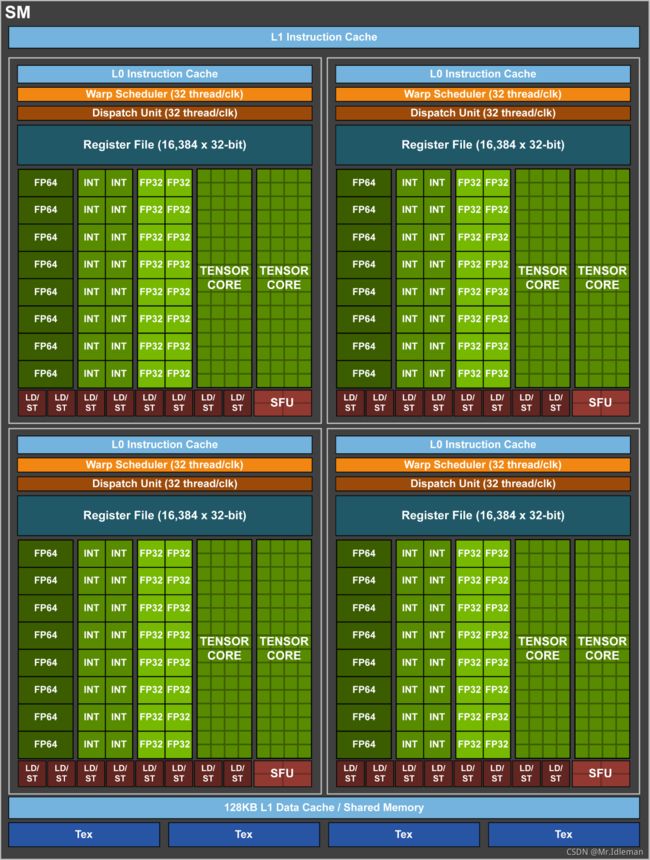
图4. Volta GV100 GPU 每个 SM 内部结构
Unlike Pascal GPUs, which could not execute FP32 and INT32 instructions simultaneously, the Volta GV100 SM includes separate FP32 and INT32 cores, allowing simultaneous execution of FP32 and INT32 operations at full throughput, while also increasing instruction issue throughput.
这段话有这么几个要点:
- Pascal的FP32和INT32不能同时执行
- Volta的FP32和INT32可以同时执行
- Volta的FP32和INT32可以满吞吐运行
首先第一点说明,Pascal以及更早的CUDA Core存在一个问题,虽然内部具有独立的FPU和ALU,却不能同时运行(这种缺陷是真没想到)。第二点说明Volta分离FPU和ALU后它们就可以同时运行了。
但是同时运行不代表着同时开始运行,前面说到过ALU都是流水线化的,分几个阶段,两者虽然同时运行,但依旧可能处在不同阶段。
继续看第三点了,满吞吐运行说明流水线被塞满,那两条流水线里总能找到对应的一组操作处于同一个阶段,这意味着两个操作同时开始。但是Volta又没有dual issue,这是怎么做到的呢?
再看看SM架构图,单个block里FP32减半的原因就找到了。对于1个warp共32个线程,交给16个单元去执行的话,要像G80等架构提到的那样占用连续的两个周期来完成issue。不过在第二个周期,dispatch unit可以继续发射指令到其他单元,比如INT32。两者交错起来,就正好能达到满吞吐。
然而虽然CUDA Core可以分工干活,但是对于一些场景,比如混合精度的矩阵操作,CUDA Core就似乎不是那么高效了,于是NVIDIA就开始琢磨专门针对Tensor的硬件单元了。
Tensor Core
Tensor Core是在Volta架构上推出,专为深度学习而设计的,在最近推出的Turing和Ampere架构上不断演进。Tensor Core作为混合精度张量核心,在矩阵运算场景下的加速效果是非常明显的。
从图5可以看出,拥有Tensor Core的V100较P100,单精度矩阵运算速度提高了1.8倍,混合精度矩阵运算速度提高了9倍:
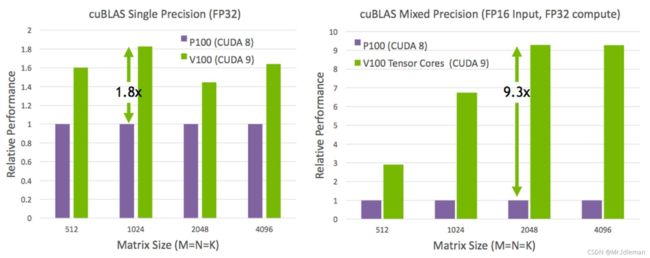
图5. Pascal和Volta架构cuBLAS单精度和混合精度计算对比
Tensor核心及其关联的数据路径经自定义设计,可以较高能效大幅增加浮点计算吞吐量。每个Tensor核心都在4x4矩阵中运行,并执行以下运算:
D = A × B + C D = A \times B + C D=A×B+C 其中,A、B、C和D为4x4矩阵(图6)。矩阵乘积输入A和B为FP16矩阵,而累加矩阵C和D可以是FP16或FP32矩阵(图6)
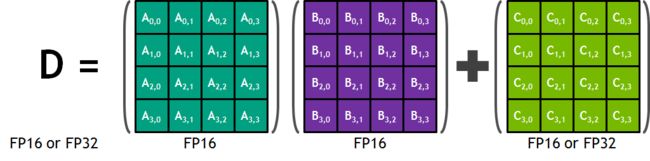
图6. Tensor Core 4x4 矩阵乘积累加运算
Tensor核心在FP16输入数据和FP32累加运算时都会发挥作用。使用FP16乘积得出全精度乘积,然后使用FP32累加将该乘积与其他中间乘积相加,从而得到4x4x4矩阵乘积(请参见图7)。事实上,Tensor 核心会用于执行更大型的二维或更高维度的矩阵运算,这种运算都由这些较小元素构建而成。
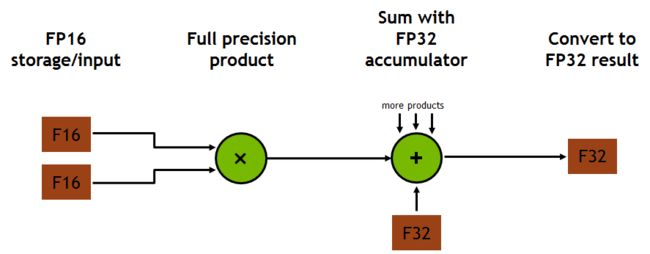
图7. GV100 Tensor Core混合精度乘积累加运算
图8展示的是4x4矩阵乘法(使用立方体外部的双源4x4矩阵)需要进行64次运算才能生成4x4输出矩阵(如立方体下方所示)。配备Tensor Core的Volta V100加速器执行此类计算的速度可比Pascal 架构的 Tesla P100 快12倍。
图8. Pascal和Volta 4X4 矩阵乘法运算
随着Nvidia GPU架构的不断发展,目前的Ampere架构上Tensor Core已经发展到了第三代,而其支持的数据类型也已经从原本的FP16扩展到几乎所有常用的数据类型,加速范围进一步提升。
| NVIDIA A100 | NVIDIA Turing | NVIDIA Volta | |
|---|---|---|---|
| Supported Tensor Core Precisions | FP64, TF32, bfloat16, FP16, INT8, INT4, INT1 | FP16, INT8, INT4, INT1 | FP16 |
| Supported CUDA® Core Precisions | FP64, FP32, FP16, bfloat16, INT8 | FP64, FP32, FP16, INT8 | FP64, FP32, FP16, INT8 |
在最新的A100 GPU上,FP32精度的加速效果相较初代的Tensor Core又提升了20倍:
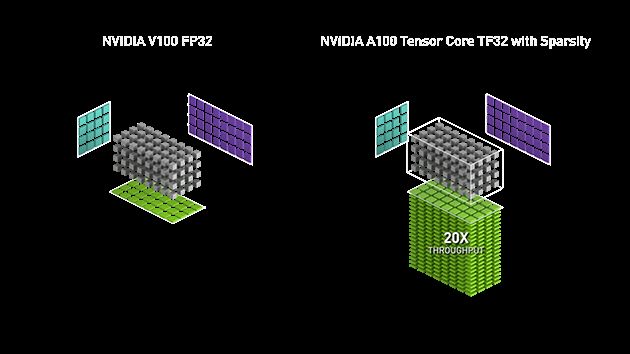 |
图9. A100与V100相比Tensor Core在FP32的加速效果
具体目前的最新进展,可以查看Nvidia官网主页:NVIDIA TENSOR CORES,里面有很详细的介绍。
RT Core
RT Core在Turing架构里被引入,主要用来做三角形与光线的求交,并通过BVH结构加速三角形的遍历。由于布置在block之外,相对于普通ALU计算来说是异步的(和Tex单元类似)。里面分成两个部分,一部分检测碰撞盒来剔除面片,另一部分做真正的相交测试。
由于RT Core只用来处理相交,实际shading还是靠灵活的图形API代码,所以阴影、AO、反射、动态模糊都可以派上用场。
RT Core虽然强,离完全实时光追渲染还是有挺大距离的。不过因为CPU端的光追已经发展很久了(各种软件渲染器),为了弥补性能缺陷也提出了很多降噪算法。正好Turing还有Tensor Core,适合跑降噪的模型(虽然很多降噪算法并不依赖ML),搭配起来就实现了对前代产品的完全碾压。
SIMD、SIMT
SIMD(Single-Instruction Multiple-Data)表示单指令多数据架构。通过采用一个控制器来控制多个处理器,同时对一组数据(又称“数据向量”)中的每一个分别执行相同的操作从而实现空间上的并行性。
SIMT(Single-Instruction Multiple-Thread)表示单指令多线程架构。通过采用SIMT方式运行的程序,每个Warp块以锁步方式执行相同的指令,但允许线程束内每个线程分别分支。
SIMD一般用来在CPU处理矢量数据,而SIMT架构类似于SIMD的向量组织方法,主要使用在GPU。两者的共同之处是使用单指令来控制多个处理元素。一项主要差别在于SIMD向量组织方法会向软件公开 SIMD宽度,而SIMT指令指定单一线程的执行和分支行为。
另外一个重要不同是SIMD中的向量中的元素相互之间可以自由通信,因为它们存在于相同的地址空间(例如,都在CPU的同一寄存器中),而SIMT中的每个线程的寄存器都是私有的,线程之间只能通过shared memory和同步机制进行通信。
在SIMT编程模型中如果需要控制单个线程的行为,必须使用分支,这会大大的降低效率。因此,程序员在开发CUDA程序时应尽量避免分支,并尽量做到warp内不分支,否则将会导致性能急剧下降。
总结
本文对Nvidia GPU 相关概念进行了解释,对于Nvidia GPU的运行原理以及使用CUDA进行GPU编程有了相关的基础认识。
参考文献
- Demystifying GPU Microarchitecture through Microbenchmarking
- Nvidia:NVIDIA Fermi Compute Architecture Whitepaper
- Nvidia:Inside Volta: The World’s Most Advanced Data Center GPU
- Nvidia:Cuda C Programming Guide
- Nvidia:questions about sp and sm
- 知乎:NVIDIA GPU的一些解析(一)
- 知乎:请问英伟达GPU的tensor core和cuda core是什么区别?
- CSDN:CUDA学习笔记(五)Warp
- CSDN:SIMT和SIMD
- SIMT和SIMD之总结篇
另有部分图片来自网络,如有重复请联系我及时删除。
如有疑问或错误,欢迎和我私信交流指正。
版权所有,未经授权,请勿转载!
Copyright © 2021 by YuxiChen. All rights reserved.