「4」「======」cvpr2020论文学习
文章目录
-
-
- HRDNet: High-resolution Detection Network for Small Objects
-
- High-Resolution Detection Network
- Experiments
- MultiResolution Attention Extractor for Small Object Detection
- Stitcher: Feedback-driven Data Provider for Object Detection
-
-
- Stitcher
-
- Augmentation for small object detection
- Small Object Detection using Context and Attention
- MultiResolution Attention Extractor for Small Object Detection
- (cvpr2019) ScratchDet: Training Single-Shot Object Detectors from Scratch
-
-
- ScratchDet
-
- IPG-Net: Image Pyramid Guidance Network for Small Object Detection
- **3. Image Pyramid Guidance Network(IPGNet)**
-
- **3.1 Challenges to be solved**
-
-
- **Overall Structure**
- **3.2 IPG转换模块**
- **3.4 Backbone Network**
-
- **3.5 IPG Fusion Module**
- **4. Experiments**
-
- **4.1 Experiments Details**
- **4.2 MS COCO**
-
- LayoutLM: Pre-training of Text and Layout for Document Image Understanding
-
- 1. Introduction
-
- 2.1 The BERT Model
- 2.2 The LayoutLM Model
- 2.3 Model Architecture
- 2.4 Pre-training LayoutLM
- 2.5 Fine-tuning LayoutLM
- 3. EXPERIMENTS
-
- **3.1 Pre-training Dataset**
- **3.2 Fine-tuning Dataset**
- 3.3 Document Pre-processing
- 3.4 Model Pre-training
- 3.5 Task-specific Fine-tuning
-
前言 最近需要汇报小目标检测相关的论文,开坑记录下。
HRDNet: High-resolution Detection Network for Small Objects
论文地址
摘要 随着网络逐渐加深,小目标检测问题成为一个具有挑战性的问题。通常来说增大输入图片的分辨率能够有效缓解这个问题。单纯的扩大分辨率极大的增加了模型的运算量,为了避免这些问题,本文提出了HRDNet模型。
High-Resolution Detection Network
模型包括Multi-Depth Image Pyramid Network (MD-IPN) and Multi-Scale Feature Pyramid Network (MS-FPN) 两个部分。MD-IPN通过使用多深度主干模型保持位置信息,即将高分辨率输入馈入到浅层网络,保持了更多位置信息同时降低了计算量;将低层的卷积输入馈入到深层网络中来提出更多语义信息。通过从高到低的卷积层提取小目标不同的特征来提升小目标的表现,同时维持中大物体的识别效果。MS-FPN这部分用来对齐和融合由MD-IPN生成的多尺度特征图,减少多尺度多深度特征之间的信息不平衡。
HRDNet的主要思想是用深层主干网络处理低分辨率的图像,浅层神经网络处理高分辨率图像。已经有文献[Fast tiny object detection in large-scale remote sensing images]证明了使用浅而小的神经网络对高分辨率图像进行提取的优势。MD-IPN可以看作有多个输入流的图像金字塔网络的变体,MD-IPN在处理大型、小型对象之间的权衡,以及高性能和低性能计算复杂性。使用浅层网络从高分辨率图像中提取特征,但浅层网络的语义表达能力较弱,所以需要给深层的骨干网络输入低分辨率图像来获得语义特征,因此MD-IPN的输入形成了一个以固定比例 α \alpha α递减的图像金字塔,MD-IPN网络的输出是一系列多尺度特征要素组,每个组包含多层次的特征图。
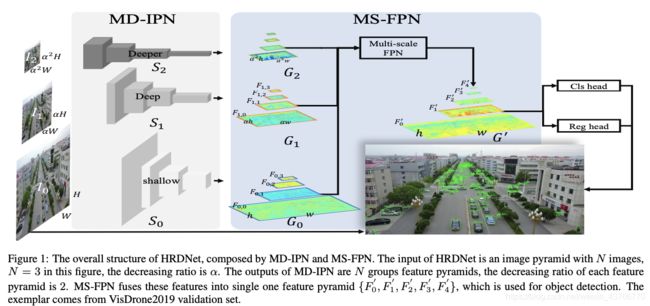
MD-IPN部分产生多分辨率、多尺度的特征图,与FPN不同,语义信息不仅从高级特征传播到低级特征,而且从低分辨率图像传递到高分辨率图像,因此,多尺度FPN的计算分为两个方向,多尺度FPN的基本操作与传统FPN相同。最高分辨率的特征 F 0 , 0 F_{0,0} F0,0不仅保持用于检测小物体的高分辨率,还结合了多尺度流的强语义特征。

本文提出的MS-FPN结构可以公式化为:Up表示2x up-sampling,卷积Conv()表示为1x1卷积。
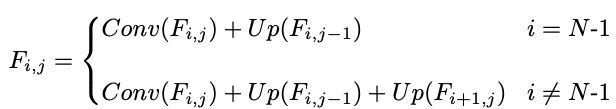
最终的输出为 F i ′ = C o n v ( F 0 , i ) F_i^{'}=Conv(F_{0,i}) Fi′=Conv(F0,i)
Experiments
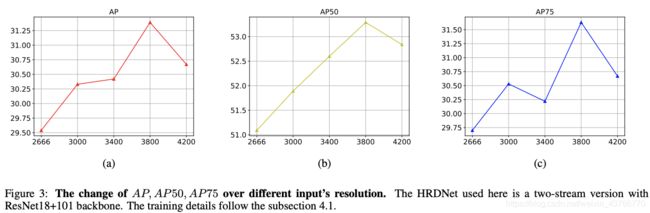
表1对比了Cascade R-CNN和不同分辨率输入的HRDNet。

图像分辨率对于小物体检测很重要,在一定程度上提高分辨率能够带来更好的性能。实验探究不同分辨率对物体检测的影响,下图显示不同分辨率下AP精度的变化,最后发现分辨率为3800x2800时,HRDNet性能最好。
MultiResolution Attention Extractor for Small Object Detection
论文地址
摘要
Stitcher: Feedback-driven Data Provider for Object Detection
论文地址
摘要 目标检测器的性能与物体大小有较大关系,本文研究发现在大多数训练过程中,小物体对于训练产生的损失几乎没有作用,产生的不平衡优化导致性能变差。基于此发现,提出了含有反馈驱动的数据provider—Stitcher。在Stitcher,图像被resize为更小的分量,然后将其stitche成与regular images相同的尺寸。Stitched images包含了smaller object,利用loss作为反馈来进行迭代更新。通过对各种检测器,backbones、datasets等进行实验后发现,Stitcher稳定地大幅度提高了性能,同时在训练和inference阶段没有增加额外的计算量。

以Resnet50和FPN为组件的Faster RCNN模型为例,研究在迭代过程中不同规模的损失分布。将objects按照小、中和大scales进行定义。具体地,在t次迭代中,小物体的损失函数为 L s t L_s^t Lst, r s t r_s^t rst表示小目标的损失函数占总体损失函数的比例。从图中发现,超过50%的iterations,小目标损失函数的占比小于0.1,对小目标信息的缺乏导致了整体较差的性能。
在Stitcher中,提出了一个反馈驱动的data provider,通过以反馈的形式利用训练损失来提升目标检测的性能。核心思想是利用当前iteration的损耗信息作为反馈来自适应的决定下一个iteration的输入。如图3所示,如果当前iteration中小目标损失占比过小时,t+1次迭代的输入就是Stitched images,其中小物体更加丰富。否则输入则仍保持为regular images. 图像拼接能够缓解原始数据分布上输入特征空间的图像级别不平衡,反馈的方式也能够减轻不平衡方向的优化。

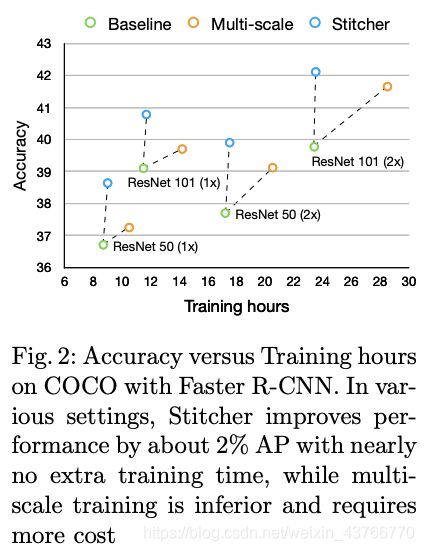
本文验证了Stitcher在不同的frameworks, backbones, datasets甚至实例分割上的有效性,在所有的设置当中,我们的方法有极大的优势,特别在小物体检测中。Stitcher包含了multi scale的图像,所以可以将其与multi-scale training相比较,后者训练时间更长但表现也不佳,Stitcher可以轻松的集成到任何检测器中。
Stitcher
Stitcher看作是一个数据provider,视penalization信号来决定输出regular images还是stitched images。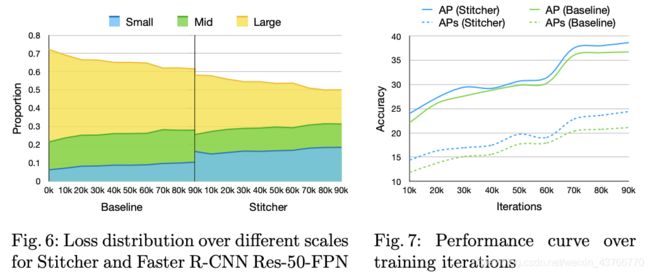
- Training Level Module - Selection Paradigm
按照以下步骤计算小目标物体损失函数的占比,物体属于哪种规模应由其面积决定,但是在检测任务重,实例物体的ground truth是无法得到的,所以采用box area进行代替。 - Time Complexity
只有在训练的过程中会用到Stitcher,因此对于inference的时间不会产生负担。Stitcher包括图片拼接和模式选择两个部分,图片拼接时使用最近邻插值方式缩小图像,在迭代过程中采用拼接图像会超出普通运算0.02s,入训练Resnet50-FPN的RCNN模型需要8.7个小时,添加了Stitcher后时间会延长一刻钟。
Augmentation for small object detection
论文地址
摘要 最近目标检测取得了较好的进展,但是在检测小目标时的准确率仍较低。本文通过对小目标进行过采样来尝试解决这个问题。
Small Object Detection using Context and Attention
摘要 本文提出一种使用上下文的物体检测方法来提高小目标检测的准确性,所提的方法结合不同层的的特征作为上下文信息,还提出了带有注意力机制的目标检测,能够包含来自目标层的上下文信息。

单看图像无法分辨出天空中的小目标是鸟,但通过结合上下文作为额外信息可以识别出鸟。首先,为提供有关小对象的足够信息,利用了小目标周围的像素信息。通过将小物体的特征与上下文的特征结合起来,可以增加小物体的信息以便更好的检测物体;其次,在早起使用了注意力机制来关注小物体,这有助于较少来自背景的不必要的浅层信息。
本文的基模型选择了baseline SSD,然后使用提高小对象探测能力的组件。首先,SSD与特征融合结合起来得到上下文信息,成为F-SSD;然后,SSD与attention模块结合起来让网络将注意力集中到重要的部分,成为A-SSD了;最后,将注意力模块与特征融合模块结合在一起,成为FA-SSD.

-
F-SSD: SSD with context by feature fusion
为了对给定的feature map提供上下文信息,我们将其与来自深层的feature maps进行融合。由于特征图有不同的空间大小,因此我们提出了如图4的融合方法。在进行特征concate之前,对上下文特征进行卷积,让其与目标特征有相同的空间尺寸,将上下文特征通道设置为目标通道的一半。仅对于F-SSD,我们还向目标要素添加了一个额外的卷积层,不改变通道的空间大小和数量。而在特征concate之前,需要对每一个feature map进行normalization。因此,我们对每层进行batch normalization 和Relu。最后,将target features 和context features进行concate。 -
A-SSD: SSD with attention module
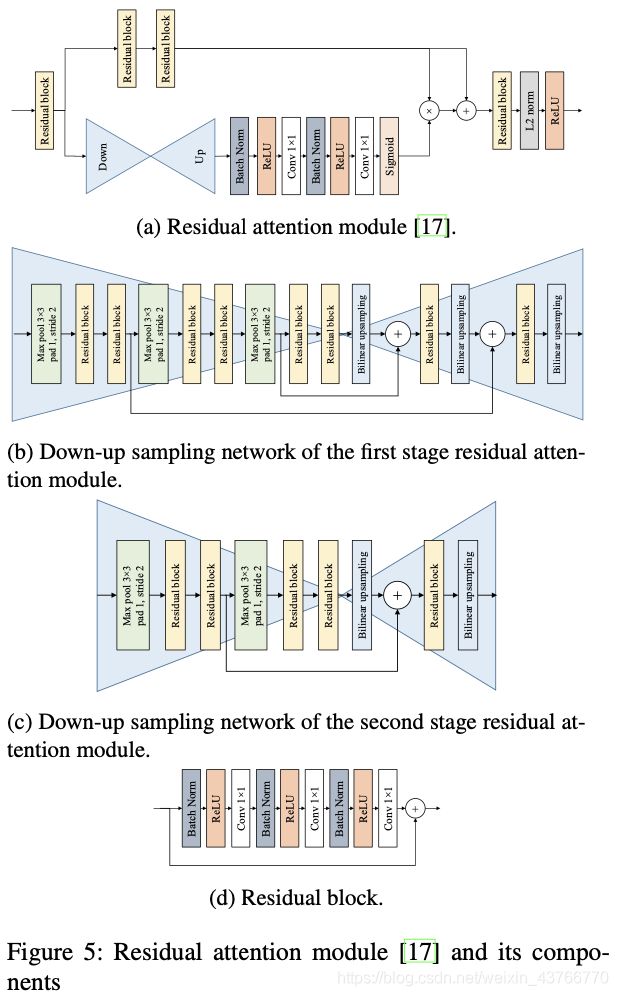
如图在conv4_3和conv7后面添加了two-stage attention模块,attention stage的结构如图5所示。
-
Experiments
本文采用基于VGG16作为backbone的SSD模型,对于FA-SSD,对conv4_3和conv7进行特征融合,将conv4_3作为target,将conv7和conv8_2用作上下文layers;将conv7作为target,conv8_2和conv9_2作为context layers。在用于小物体检测的浅2层应用attention module,attention module的输出与目标特征有相同的size。 -
Inference time
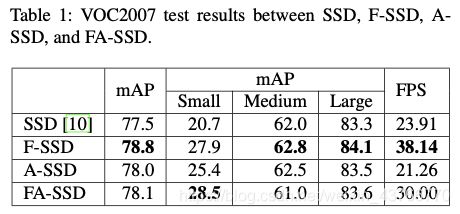
对比了SSD,F-SSD, A-SSD,FA-SSD的表现,如表1,发现后三种方式都比SSD效果好,意味着每个组件都可以改善基准。FA-SSD整体的性能没有F-SSD好,但是FA-SSD在小物体检测方面表现出最佳的性能和显著的改进。
-
为了对attention模块更加理解,对来自FA-SSD的attention mask进行可视化,attention mask是从sigmoid function之后取得,conv4_3有512channels,conv7有1024channels,每个channel集中在不同的对象上,可视化其中一部分如图8。

MultiResolution Attention Extractor for Small Object Detection
摘要 小物体由于分辨率小和尺寸小而难检测,现存的小物体检测方法主要集中在数据预处理或者降低大小物体之间的差异。受到人类视觉注意力机制的启发,本文提出了两种特征提取方法来挖掘小物体最有用的信息。
选择Faster-RCNN作为基础探测器,将特征提取器替换为本文提出的MRAE来探测小物体。MRAE使用方便,与现有的四种基于特征的方法相比,MRAE因为注意力权重在特征融合方面更有效。MRAE方法凸显除了Resnet的多级别上最有用的特征图,还进行了特征融合来进一步强调重要信息。几个级别的特征图进行加权和,其中注意力权重通过小型网络学习(卷积层、全连接层)然后跟随一个softmax层。
-
Related Work
为了解决这个问题,使用传统的图像金字塔和filter 金字塔方法来检测金字塔结构中的小物体。 -
Soft attention
本文提出的MRAE突出了ResNet网络中多个级别的游泳的特征图,进而进行特征融合来进一步增强有用的信息。通过小型网路学习出各级别特征图的权重,然后经过softmax层。
本文提出的两个模块:首先提出的软注意力模块使用max-pooling层来产生注意力值,第二个方法用于设计基于注意力的特征交互小网络,其中定义了模版特征级别,根据模版与其他特征级别之间的余弦相似度生成最终的attention maps。在ResNets中,特征提取网络有四个levels,其中一个级别由带有相同大小的特征图的多个conv层组成,其中conv2,conv3,conv4, conv5分别表示为C1,C2,C3,C4。Conv5用于模拟VGG16网络中的全连接层功能,使用C1,C2,C3来生成注意力图。
我们附上一个小网络来获得attention权重,注意力权重定义为每个级别要素生成最终的attention map的权重。这个小型网络包含1x1转换层和一个max-pooling层,1x1conv层用于降低维度,它等于深度方向上的总和。将卷积层的输出维度设置为1,global max pooling层用于提取特征图的最大值来获得最值得关注的特征像素,到目前位置得到的三个指连接到softmax层中获得一组归一化后的值。
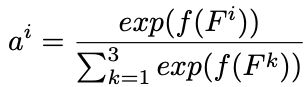
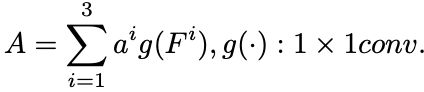
- Attention-based feature interaction MRAE
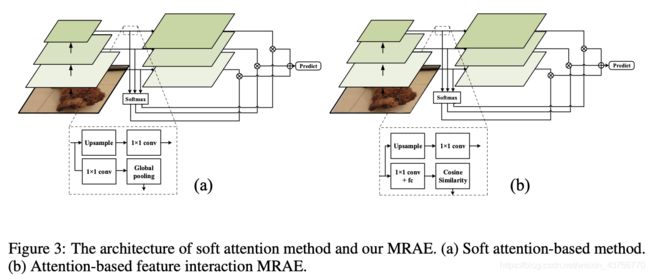
如果将 C t C_t Ct输出作为模版,分别计算 C i ( i ! = t ) , i = 1 , 2 , 3 C_{i(i!=t)}, i=1,2,3 Ci(i!=t),i=1,2,3的输出与模版的余弦相似度,如果将 C 1 C_1 C1作为模板,增加一个由1x1conv layer和全连接层组成的小型网络来映射出一个vector进行相似度计算,余弦相似度表示为: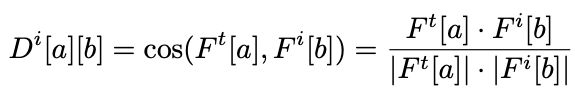
D 2 , D 3 分 别 表 示 C 2 和 C 3 的 a t t e n t i o n d e g r e e , 将 D^2, D^3分别表示C2和C3的attention degree,将 D2,D3分别表示C2和C3的attentiondegree,将{D^1=1, D^2, D^3}$输入到softmax层中,得到注意力权重。
(cvpr2019) ScratchDet: Training Single-Shot Object Detectors from Scratch
论文地址
代码地址
摘要 目前的目标检测器大多从分类数据集ImageNet上预训练的现成网络中通过微调得到的,这可能会引起两个问题:1),分类和检测网络对平移变换的敏感性不同,分类任务倾向于平移不变性,因此需要下采样操作来获取更好的性能,但对象检测更注重局部的纹理信息,因此谨慎使用下采样操作;2)一般检测器都是采用在ImageNet上预训练过的网络作为backbone,如果需要更改网络架构,还需要在大型数据集上进行预训练,成本比较高。
从零开始训练检测器是一种解决方案,但一般从零开始的检测器通常比预训练的检测器性能差,可能会带来训练中的收敛问题。在这篇文章中尝试从头开始训练目标检测器,通过分析先前的优化工作,发现从零开始训练检测器中被忽略的一点是BatchNorm。利用BatchNorm带来的稳定的、可预测的梯度,可以稳定地从头开始训练检测器,同时保持独立于网络结构的良好性能。利用这个优势,我们能够探索各种类型的对象检测网络,而不会产生不收敛。通过对下采样因子的广泛采用和分析提出了Root-Resnet骨干网络,该网络充分利用了原始图像的信息。
我们从头训练一个网络至少要达到两个条件:解放任何类型网络的架构限制,同时保证训练的收敛性;训练出来的模型效果比预训练的模型效果近似或者更好。在论文[30]中,认为从零开始训练检测器中缺少BatchNorm是导致收敛性较差的主要原因。因此本文将BatchNorm集成到骨干网和检测头子网中,发现BatchNorm帮助检测器以任何形式的网络中很好的收敛,超出预训练baseline的准确性。因此,我们能够自由修改体系结构,而不受预训练模型的限制。通过利用这一优势,我们分析各种配置的基于Resnet和VGGnet的SSD检测器的性能,发现第一卷积层的采样步幅对检测性能有较大的影响。基于这一点,我们通过引入新的模块来重新设计检测器的体系结构,此结构保留了检测特征图的大量信息,并从根本上提升检测器的准确性,特别是针对小物体。
DSOD首先从头训练了一阶对象检测器,并提出了一系列能产生良好性能的远离。GRP-DSOD通过应用门控循环特征金字塔改进了DSOD算法。
ScratchDet
-
BatchNorm for train-from-scratch
不失一般性地,考虑采用Batch-Norm在SSD中,SSD由主干子网和检测头子网组成,原始的SSD框架中没有BatchNorm。BatchNorm让优化过程更加平滑,允许网络有更大的搜索空间和更快的收敛速度。DSOD成功的从零开始训练检测器,但是,它将结果归因于DenseNet的深入监督,而没有强调BatchNorm的作用。作者认为有必要强调BatchNorm对训练检测器的影响。为了证明我们的论点,作者从头训练不含有BatchNorm的SSD,batchsize设置为128,如表1中显示在VOC2007数据集上为67.6%的mAP。

-
BatchNorm in the backbone subnetwork
我们在backone的每一个卷积层中增加Batch-Norm,然后从头开始训练,从表中可以看出增加BatchNorm后mAP提升了5.2%。更重要的,在backbone中增加BatchNorm能够平滑优化过程。因此,可以使用更大的学习率来进一步提高性能,她们的表现都优于在预训练的VGG16模型中微调的SSD。表明在backbone中增加BatchNorm是从头训练SSD的关键问题之一。 -
BatchNorm in the detection head subnetwork
为了分析BatchNorm在检测头子网中的作用,我们绘制了训练损失值,梯度的L2范数和梯度的L2范数对训练steps的波动。在图1(b)和图1©中的蓝色曲线,默认学习率为0.001从头开始训练SSD时,L2梯度范数有较大的波动,特别在训练的初期,这导致损失值突然变化并收敛到一个不好的局部最小值。这个结果有助于解释以下现象:使用大学习率从头开始或通过预训练的网络训练SSD时,可能会导致梯度爆炸、稳定性差等。
如果将BatchNorm集成到检测头子网中能够让损耗情况更加平滑,如图1中的红色曲线,mAP从67.6%上升到71%。在平滑的landscape下可以设置更大的学习率,带来更大的搜索空间和更快的收敛速度,mAP从71%上升到75.6%。使用BatchNorm,即使采取了较大的学习率有助于跳出局部最小值来产生稳定的梯度。
-
BatchNorm in the whole network
作者研究了在骨干网络和检测头子网中使用BatchNorm的检测器性能。在整个探测器网络使用BatchNorm后,再采用较大的学习率进行检测器训练,与预训练的VGG16主干初始化的探测器相比,该探测器的mAP升高1.5%。 -
Performance analysis of ResNet and VGGNet 截断的VGG16和ResNet-101是SSD中使用的两个流行的骨干网络。ResNet101产生比VGG16更好的分类结果。但是在DSSD所示,基于VGG16的SSD优于基于ResNet101的SSD,作者认为是优于ResNet101的第一个卷积层中的下采样操作引起的,这个操作会严重影响检测精度,特别针对小物体。在删除ResNet18的conv1中的下采样操作已形成图3©中的结构,检测性能从73.1%提升到77.6%,再删除第二个下采样操作来形成图(b)的结构,结果改进较小。总而言之,第一卷积层中的下采样对检测精度有不良影响,特别是对小物体。
-
Backbone network redesign for object detection为了克服基于ResNet的骨干网进行对象检测的缺点,同时保留其强大的分类能力,作者设计了一种Root-ResNet的新体系结构,删除第一卷积层中的下采样操作,用3x3卷积替代7x7的卷积核。有了大量的输入,Root-ResNet能够图像中的更多信息,从而提取出强大的特征进行小物体检测。将四个卷积块替换成四个残差块直到Root-Resnet的末端。每个残差块由两个分支组成,一个分支是由步长为2的1x1卷积层,另一个分支是步长为2的3x3卷积层和步幅为1的3x3卷积层。每个卷积层的输出通道设置为128。这些残差块能提高计算效率,不降低性能。
IPG-Net: Image Pyramid Guidance Network for Small Object Detection
论文链接
摘要 对基于传统神经网络的目标检测器,存在一个典型的难题:空间信息被保留在浅层中,但浅层网络又没有足够的语义信息,相反地,较高层中有足够的语义信息,但丢失了很多空间信息,导致了严重的信息失衡现象。为了在浅层获取足够的语义信息,FPN用来构建一个从上到下的传播途径。本文除了从上到下结合浅层信息,还提出了IPG-Net来确保每一层的空间信息和语义信息的丰富性。本文提出的IPGNet包含两个主要部分:图像金字塔转换模块和图像金字塔融合模块,我们的主要思想是将图像金字塔导引到主干流中,来缓解信息不均衡问题,减少小物体特征的消失。IPG转换模块确保了即使在网络的最深层,仍有足够的空间信息能够进行bounding box的分类和回归。此外,本文设计了一个有效的金字塔融合模块来融合图像金字塔和backbone流中的特征。
好的特征提取器应该具备两个特征:浅层图像信息用来进行边界框回归,因为目标检测是典型的回归任务;足够的语义信息用于分类,意味着输出的特征来自深层网络。本文设计的IPG-Net通过更好的解决信息失衡问题来提取更好的特征。
深层卷积网络随着网络加深会引起位置信息或者空间信息的丢失,对于分类问题,这个属性带来的问题不大,但bounding box回归对于检测任务是很重要的。这样空间信息丢失会导致目标检测中的特征未对齐(未对齐表示在anchors和卷积特征之间的距离)。除了空间信息的丢失之外,在更深的卷积层中小物体更容易丢失。我们认为,这些对象检测问题都是由于现有的卷积网络结构的局限性导致的,无法通过修改典型网络架构来解决。
图像金字塔用于为骨干网的特征金字塔的每一阶提供更多的空间信息,对于骨干网络的每个stage,计算其在特征金字塔相应level的图像金字塔特征。图像金字塔特征通过浅而轻的IPG转换模块计算得到,与深层主干相比有更丰富的空间信息。然后设计一个IPG融合模块来将新的图像金字塔功能融合到backbone网络中。
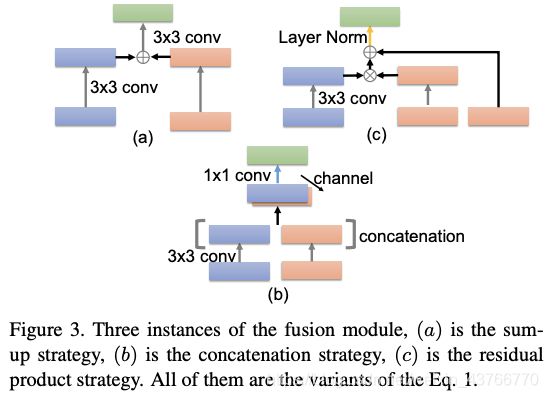
融合模块执行两个步骤来融合两种功能,首先,将原始特征进行转换后对齐数据大小,将其投影到隐藏空间中;其次,使用常见的数学运算来结合两个特征。加、乘和级联都用于我们的实验中,并获得了不停程度的改进。
3. Image Pyramid Guidance Network(IPGNet)
3.1 Challenges to be solved
Anchor Misalignment 虽然更深的CNN可以更好的提取特征,但也会模糊这些特征。深层特征中的对象位置不总是与这些对象在原始图片的位置对齐。但是基于anchor的检测程序遵循以下假设:对象在任何特征层的位置都与相应原始图像中的位置对齐。因此,在anchor和卷积特征之间存在着未对准。这种现象随着CNN深度的增加变得更加严重。
- FPN Misalignment特征金字塔网络将深层特征与浅层特征进行融合来缓解信息失衡问题,然而,由于深层CNN主干已经引起了anchor未对齐,因此,FPN的融合不能实现深层特征与相应的浅层特征之间正确的对齐。例如,没有图像金字塔的指导,由于特征R2与特征R1之间已经存在未对齐问题,因此特征P1=upsample(P2)+conv(R1)也有未对齐问题。
- Feature Vanishment for Small Objects较深的CNN相对于初始图像尺寸来说跨度大了32,因此在分类问题上有较好的性能。然而,大stride也导致了输入图像详细信息的缺失。小对象检测取决于详细信息,因此,我们通常使用浅层特征检测小物体,但浅层特征缺乏语义信息。使用FPN建立一个从上到下的路径来为浅层特征提供语义信息是至关重要的。虽然FPN在一定程度上提高了浅层的检测难度,但小物体的信息仍严重丢失。由于小物体的细节信息在深层的CNN backbone中已经大大破坏。这也是为什么我们建议使用图像金字塔guidance向浅层提供浅层信息的原因。
Overall Structure
IPG-Net的整体结构如图1,由常用的如ResNet的backbone 网络改造得到,能够给现有的方法提供公平的对比。IPG-Net包含两个主要部分:IPG transformation module,IPG fusion module。前者从图像金字塔中接收一组不同分辨率的图像,从中提取特征来进行融合。IPG转换模块的功能是提取浅层特征来提供空间信息和详细信息,图金字塔特征用于guide主干网络来保留空间信息和小物体特征。此外,使用融合模块进行指导,IPG融合模块的功能是融合骨干网的深层功能和IPG转换模块的浅层功能。IPG融合模块的思想是首先对两种类型的特征进行转换,然后将它们融合在一起,来实现物体检测的增强效果。
3.2 IPG转换模块
由于CNN缺乏尺度不变能力,因此图像金字塔用来获取多级特征来降低图像尺度的影响。通常,大部分模型的表现能够通过这种方式显著提高,但在训练阶段的成本较高。与传统方法不同,本文使用图像金字塔来指导骨干网络,以减少信息不平衡问题并学习更好的检测特征。更好的特征意味着则这些不同尺度的特征有丰富的空间信息和足够的语义信息,即没有严重的特征不对齐或者信息失衡。
IPG转换模块的输入是图像金字塔集合 I P s e t = I i , i ∈ [ 0 , N ) IP set={I_i}, i \in [0, N) IPset=Ii,i∈[0,N). 在IPset中的图分辨率降低2倍。第一个图像是具有HxW分辨率的 I 0 I_0 I0,与物体检测的常用图像分辨率相同。N表示图像金字塔的级数。
下面介绍IPG转换模块的典型结构,如图2。IPG转换模块由两部分组成,一个是7x7卷积后面接上2x2 maxpooling模块,另一部分是一个残差块设计。残差块接收相同尺寸的特征但输出不同维度的特征,特征图的输出维度与主干网的尺寸对齐。使用浅层子网络提取图像金字塔特征的主要原因有两个:一方面,浅层网络能够保留更多的空间/详细信息,而deep CNN将会破坏空间信息。另一方面,由于浅层设计,计算成本和网络参数的数量不会增加太多。
IPG转换模块输出的每个组件 I P F s e t = F i , i ∈ [ 0 , N ) IPF set={F_i},i\in [0,N) IPFset=Fi,i∈[0,N)被表示为 F i = f ( I i ) , i ∈ [ 0 , N ) F_i = f(I_i), i\in [0,N) Fi=f(Ii),i∈[0,N)。其中 f ( . ) f(.) f(.)表示IPG转换模块, F i F_i Fi表示第i个level的图像金字塔特征。这些来自不同level的特征形成了新的图像金字塔特征。
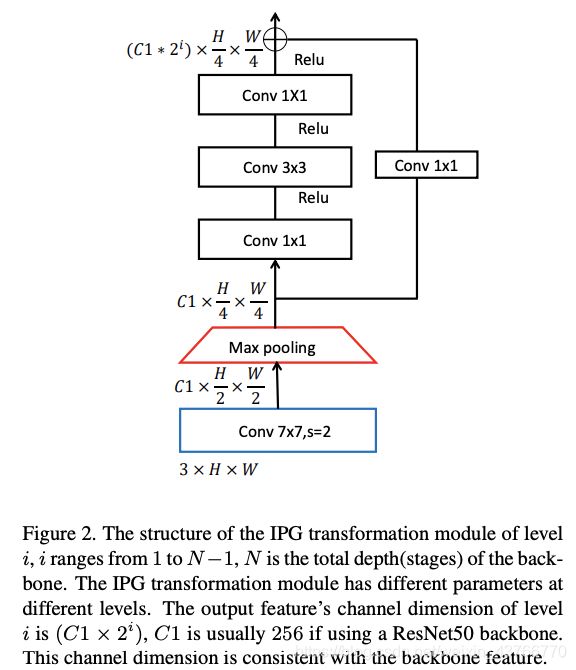
3.4 Backbone Network
IPG-Net的主干网修改于标准的ResNet。这篇文章在标准ResNet的尾部增加了新的stage,每个stage包含了两个与ResNet相同的Bottleneck模块。Ablation研究表明,增加一个new stage能够比其他情况表现更好,太深的backbone网络对检测也有害,网络太深也会加大训练难度。使用比标准ResNet更深的卷积网络的原因是,IPG转换模块提供足够的空间信息给backbone Network,这保证了在没有太多信息失衡的情况下训练deep CNN。Deeper骨干网络使我们产生更好的语义信息,这对分类是有利的,并可以覆盖更大范围的对象。
3.5 IPG Fusion Module
-
3.5.1 Formulation
IPG融合模块是一个比较灵活的模块, f ( ) f() f()和 g ( ) g() g()分别对应IPG转换模块的网络和backbone network。方程 β \beta β可以在不同版本中灵活使用。 O i O_i Oi表示第i个level的融合模块输出。 I 0 I_0 I0和 I i I_i Ii分别表示在level0和leveli的图像。 β \beta β表示融合模块的基本融合方程。 f i f_i fi表示第i个level下,IPG转换模块的输出, g i g_i gi表示第i个level下,backbone的网络输出。
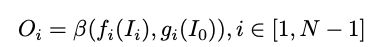
在IPG-Net中IPG融合模块的位置如图1,每个融合模块包括两个输入。本文在融合模块提出了Sum、Product和Concatenation三种融合方式,其他类型的设计也表现的较好,但在这篇文章中没有进行讨论。 -
3.5.2 Element-wise Sum
此版本将图像金字塔信息作为附加信息,因此将 F i F_i Fi和 R i R_i Ri相加。首先,需要调整这两类特征的通道尺寸,使用通道线性插值来进行通道转换。
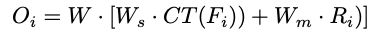
其中W表示不同的线性变化情况。 -
3.5.3 Residual Product
这部分使用 W s × C T ( F i ) ∗ W m ∗ R i W_s \times CT(F_i)*W_m *R_i Ws×CT(Fi)∗Wm∗Ri来表示骨干特征中丢失的信息。增加了骨干网络丢失的信息之后,执行LN(layer norm)操作对融合特征进行标准化处理。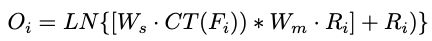
-
3.5.4 Concatenation
将图像金字塔特征和主干网特征进行级联
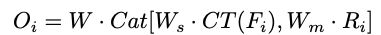
4. Experiments
4.1 Experiments Details
Datasets 在MS COCO和Pascal VOC数据集上进行实验。
4.2 MS COCO
- which fusing strategy is better
这篇论文针对图像金字塔和backbone网络特征融合提出了三种策略,为对比这三种方式的有效性和差异,在相同的基准上执行不同的策略,分别记录大、中和小物体的AP。三个版本的小对象的结果相似,但大、中型物体有所差异。从表中结果发现SUM策略对于IPG融合的效果最好。

-
How deep is better for the IPG-Net
表3表示了mAP不随网络深度的增加而增加,提升主要来自于大物体,小物体对应的指标有所降低。这个发现与本文的观点一致,浅层网络特征对小物体来说更重要。本文还研究了保持最后3个阶段的空间大小的效果,结果表明,小物体和中型物体略有改善,mAP的改善不明显。5stages的深度对于IPG-Net来说是性能最好的。
-
The position of the IPG fusion
这部分使用IPG-Net和4stages的ResNet进行实验,首先增加一个图像金字塔特征到骨干网络中,然后增加image pyramid的level来判断增加level是不是更好。表4发现,具有不同配置的IPG-Net相比ResNet实现了轻微的改善。IPG-Net对IPG Fusion的位置不敏感。 -
The effect on deep layers
图像金字的指导功能是将小物体的空间信息和图像细节信息提供给深层特征,实验证明IPG在深层中的有效性。IPG-Net和ResNet的深度是7stages,但仅使用后面4个stages的输出。
表5显示了IPG-Net几乎在所有指标上实现了比ResNet主干更好的表现。表5表明IPG-Net可以很好的用作RetinaNet的特征提取器。
LayoutLM: Pre-training of Text and Layout for Document Image Understanding
摘要 本文中,我们提出了LayoutLM来对跨扫描文档图像的文本和布局信息之间的交互进行联合建模,这对于大量实际文档图像理解任务(例如从扫描文档中提取信息)很有帮助。而且,我们利用图像特征将单词的视觉信息整合到LayoutLM模型中。
1. Introduction
本文提出了layoutLM模型,这是一种用于文档图像理解任务的简单而有效的文本和布局预训练方法。受到Bert模型的启发,Bert模型的输入主要包括文档嵌入和位置嵌入,LayoutLM进一步增加了两种类型的输入嵌入:(1) 2-D position embedding,表示文档中token的相对位置;(2) 扫描文档中的token的image embedding.
2.1 The BERT Model
BERT模型是一种基于注意力的双向语言建模方法。 也已证明,BERT模型可从具有大规模训练数据的自我监督任务中显示有效的知识转移。 BERT的体系结构基本上是多层双向转换编码器。 它接受令牌序列并堆叠多层以产生最终表示。 详细地,给定使用WordPiece处理的一组令牌,通过将相应的单词嵌入,位置嵌入和片段嵌入相加来计算输入嵌入。 然后,这些输入嵌入将通过多层双向转换器传递,该转换器可以使用自适应注意机制生成上下文表示。
BERT框架中有两个步骤:预训练和微调。 在预训练期间,该模型使用两个目标来学习语言表示:屏蔽语言建模(MLM)和下一句预测(NSP),其中MLM随机屏蔽一些输入令牌,目标是恢复这些屏蔽令牌,以及NSP 是一个二进制分类任务,将一对句子作为输入并对它们是否是两个连续的句子进行分类。 在微调任务中,使用特定于任务的数据集以端到端的方式更新所有参数。 BERT模型已成功应用于一系列NLP任务。
2.2 The LayoutLM Model
尽管类似BERT的模型已成为一些具有挑战性的NLP任务的最新技术,但它们通常仅将文本信息用于任何类型的输入。 当涉及到视觉上丰富的文档时,可以将更多信息编码进预训练模型。 因此,我们利用来自文档版面丰富的视觉信息,并将其与输入文本对齐。
有两种类型的功能可以显著改善视觉信息丰富的文档中的语言表示,它们是:
- 文档布局信息显然,文档中单词的相对位置对语义表示起了很大的作用。 以表单理解为例,给定表单中的密钥(例如“ Passport ID:”),则其对应值更可能在其右侧或下方而不是左侧或上方。 因此,我们可以将这些相对位置信息嵌入为二维位置表示。 基于Transformer中的self-attention机制,将2-D位置特征嵌入到语言表示中会更好地使布局信息与语义表示对齐。
- 视觉信息与文本信息相比,视觉信息是文档表示中另一个重要的重要功能。 通常,文档包含一些视觉信号以显示文档段的重要性和优先级。 视觉信息可以由图像特征表示,并可以有效地用于文档表示中。 对于文档级视觉特征,整个图像可以展示文档布局,这是文档图像分类的基本功能。 对于单词级的视觉特征,粗体,下划线和斜体等样式也是序列标记任务的重要提示。 因此,我们认为将图像特征与传统文本表示形式相结合可以为文档带来更丰富的语义表示形式。
2.3 Model Architecture
为了利用现有的预训练模型并适应文档图像理解任务,我们使用BERT架构作为主干并添加了两个新的输入嵌入:2-D位置嵌入和图像嵌入。
- 2-D Position Embedding与在序列中对单词位置进行建模的位置嵌入不同,2-D Position Embedding旨在对文档中的相对空间位置进行建模。 为了表示元素在扫描文档图像中的空间位置,我们将文档页面视为具有左上角原点的坐标系。在此坐标系下,bounding box精确的表示为 (x0, y0, x1, y1),(x0, y0)代表回归框的左上角,(x1, y1)代表回归框的右下角。我们添加具有两个嵌入表的四个位置嵌入层,其中代表相同尺寸的嵌入层共享相同的嵌入表。 这意味着我们在嵌入表X中查找x0和x1的位置嵌入,并在表Y中查找y0和y1。
- Image Embedding为了利用文档的图像特征并使图像特征与文本对齐,我们添加了图像嵌入层以用语言表示来表示图像特征。 更详细地讲,使用OCR结果中每个单词的边界框,我们将图像分为几部分,并且它们与单词具有一对一的对应关系。我们使用Faster R-CNN模型中的这些图像作为令牌图像嵌入来生成图像区域特征。对于[CLS]令牌,我们还使用Faster R-CNN模型使用整个扫描的文档图像作为关注区域(ROI)来生成嵌入,以使需要[CLS]令牌表示形式的下游任务受益。
2.4 Pre-training LayoutLM
- Task #1 : Masked Visual-Language Model 受masked语言模型的启发,我们提出Masked Visual-language Model(MVLM),以学习带有2-D position embeddings和text embeddings线索的语言表示。 在预训练期间,我们随机掩盖一些输入标记,但保留相应的2-D position embeddings,然后训练模型以在给定上下文的情况下预测掩盖标记。 这样,LayoutLM模型不仅可以理解语言上下文,而且可以利用相应的2-D位置信息,从而弥合了视觉和语言模态之间的鸿沟。
- Task #2: Multi-label Document Classification 为了理解文档图像,许多任务要求模型生成高质量的文档级表示形式。 由于IIT-CDIP测试模块针对每个文档图像都包含多个标签,因此在预训练阶段,我们还使用多标签文档分类(MDC)损失函数。 给定一组扫描的文档,我们使用文档标签来监督预训练过程,以便该模型可以聚集来自不同领域的知识并生成更好的文档级表示形式。 由于MDC损失函数需要每个文档图像的标签,而对于较大的数据集可能不存在该标签,因此在预训练期间它是可选的,将来可能不会用于预训练较大的模型。 将在第3节中比较MVLM和MVLM + MDC的性能。
2.5 Fine-tuning LayoutLM
预训练的LayoutLM模型在三个文档图像理解任务上进行了微调,包括表单理解任务,收据理解任务以及文档图像分类任务。 对于表单和收据的任务,LayoutLM会为每个token预测{B,I,E,S,O}标签,并使用顺序标签来检测数据集中的每种实体。 对于文档图像分类任务,LayoutLM使用[CLS] token的表示形式预测类标签。
3. EXPERIMENTS
3.1 Pre-training Dataset
预训练模型的性能在很大程度上取决于数据集的规模和质量。 因此,我们需要大规模的扫描文档图像数据集来预训练LayoutLM模型。 我们的模型在IIT-CDIP Test Collection 1.0上进行了预训练,该模型包含600万以上的文档,以及1100万以上的扫描文档图像。 此外,每个文档在XML文件中都有其对应的文本和元数据。 文本是通过将OCR应用于文档图像而产生的内容。 元数据描述了文档的属性,例如唯一标识和文档标签。 尽管元数据包含错误且不一致的标签,但是在此大规模数据集中扫描的文档图像非常适合进行模型预训练。
3.2 Fine-tuning Dataset
- FUNSD Dataset 我们对FUNSD数据集评估我们的方法,以学习复杂扫描文档中的表单。 该数据集包括199个real,完全注释的扫描表单,其中包含9,707个句子和31,485个单词。 这些表单被看作相互链接的句子的列表。 每个句子包括唯一标识符,标签(即,问题,答案,标题或其他),边界框,与其他实体的链接的列表以及单词的列表。 数据集分为149个训练样本和50个测试样本。 我们采用词级F1-score作为评估指标。
- The SROIE Dataset 我们也在收据信息提取数据集SROIE上评估了我们的模型。SROIE数据集包括626个训练数据和347个测试数据。每个收据单被看作带有bounding boxes的文本行列表,每个收据被标注为{公司,日期,地址,总数},评估指标是F1-score。
- The RVL-CDIP Dataset
3.3 Document Pre-processing
要利用每个文档的版面信息,我们需要获得每个token的位置信息。但是,预训练数据集(IIT-CDIP测试集合)仅包含纯文本,而缺少其相应的bounding boxes。 在这种情况下,我们重新处理扫描的文档图像以获得必要的布局信息。 像IIT-CDIP Test Collection中的原始预处理一样,我们通过将OCR应用于文档图像来类似地处理数据集。 不同之处在于,我们同时获得了识别的单词及其在文档图像中的对应位置。 借助开源OCR引擎Tesseract6,我们可以轻松地获得识别以及二维位置。 我们以hOCR格式存储OCR结果,hOCR格式是一种标准规范格式,它使用层次结构表示法清楚地定义了一个文档图像的OCR结果。
3.4 Model Pre-training
我们使用预训练的BERT模型参数初始化LayoutLM模型参数。具体来说,我们的BASE model有同样的结构:a 12-layer Transfromer with 768 hidden sizes,12 attention heads,其中包含113M 参数。因此,我们使用BERT base model来初始化我们模型中的所有模块,除了2-D位置嵌入层。对于LARGE设置,我们的模型有一个24-layer 带有1024hidden sizes 和16 attention heads,也是由预训练的BERT LARGE model进行初始化,其中包含343M 的参数。我们选择15%的input tokens用作预测, 我们在80%的时间内用 [MASK]tokens 替换这些令牌,在10%的时间内替换了随机tokens,并在10%的时间内替换了不变的tokens。 然后,模型使用交叉熵损失预测相应的tokens。
此外,我们增加了带有四个嵌入元素(x0, y0, x1, y1)的2-D位置嵌入层,其中(x0, y0)代表bounding box的左上角,(x1, y1)代表bounding box的右下角。考虑到文档布局在不同页面大小下有所不同,因此将实际坐标scale到0~1000。此外,在Faster-RCNN模型中也使用ResNet101作为backbone网络,此模型在Visual Genome dataset的基础上预训练得到。
3.5 Task-specific Fine-tuning
我们在三个文档图像理解任务上评估LayoutLM模型:表单理解,收据理解和文档图像分类。 我们遵循典型的微调策略,并以端到端的方式在特定于任务的数据集上更新所有参数。
-
Form Understanding此任务需要提取和构造表单的文本内容。 它旨在从扫描的表单图像中提取键值对。 更详细地,此任务包括两个子任务:语义标记和语义链接。 语义标记是将单词聚合为语义实体并为其分配预定义标签的任务。语义链接是预测语句之间关系的任务。在这项任务中,我们关注语义标注任务,语义链接任务是超出范围的。在这个任务上进行LayoutLM finetune,将语义标注任务看作序列标注问题。我们将最终的表示传递到一个线性层,然后接到softmax层来预测每个token的label.
-
Receipt Understanding 该任务需要根据扫描的收据图像填充几个预定义的语义槽。 例如,给定一组收据,我们需要填写特定的位置(例如公司,地址,日期和总计)。 与需要标记所有匹配的实体和键值对的形式理解任务不同,语义槽的数量由预定义的键固定。 因此,该模型仅需要使用序列标记方法来预测相应的值。
-
Document Image Classification 给出一个视觉丰富的文档,这个任务的目的是预测每个文档图像的相应种类。与现有的基于图像的方法不同,我们的模型不仅包括图像表示形式,而且还包括使用LayoutLM中的多模式体系结构的文本和布局信息。 因此,我们的模型可以更有效地结合文本,布局和图像信息。 为了在此任务上微调我们的模型,我们将LayoutLM模型的输出与整个图像嵌入连接在一起,然后是用于类别预测的softmax层。 我们对模型进行了30个时期的微调,批量大小为40,学习率为2e-5。