卷积神经网络与LeNet的应用——MNIST手写数字识别
1. 神经网络三要素
- 模型结构,eg: 深度学习的网络结构(DLNet)。
- 测试数据,寻找到合适的数据集即可。
- 误差调整(损失函数),eg: Relu(校正的线性单元)、PRelu(前面的改进版)。两个函数都可减少sigmod函数导致的水波现象。
2. 卷积神经网络
卷积神经网络(Convolutional Neural Network,CNN),在此简单的介绍一下 自己的理解。卷积神经网络与普通神经网络的区别在于:
卷积神经网络比神经网络多包含了一个由卷积层和子采样层构成的特征抽取器。在卷积神经网络的卷积层中,一个神经元只与部分邻层神经元连接。
在CNN的一个卷积层中,通常包含若干个特征平面(featureMap),每个特征平面由一些矩形排列的的神经元组成,同一特征平面的神经元共享权值,这里共享的权值就是卷积核。卷积核一般以随机小数矩阵的形式初始化,在网络的训练过程中卷积核将学习得到合理的权值。共享权值(卷积核)带来的直接好处是减少网络各层之间的连接,同时又降低了过拟合的风险。子采样也叫做池化(pooling),通常有均值子采样(mean pooling)和最大值子采样(max pooling)两种形式。子采样可以看作一种特殊的卷积过程。卷积和子采样大大简化了模型复杂度,减少了模型的参数。 以上就是卷积神经网络的简单介绍。
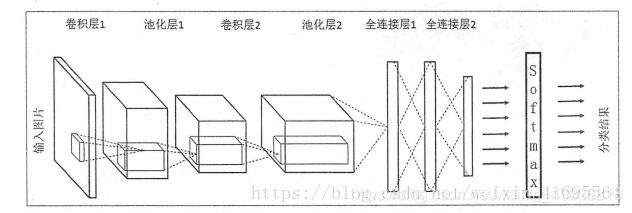
(图片来源于网络)
在CNN的前几层中,每一层的节点都被组织成一个三维矩阵。比如处理 Cifar-10数据集中的图片时,可以将输入层组织成一个32323的三维矩阵。图中虚线部分展示了卷积神经网络的一个连接示意图,从图中可以看出卷积神经网络中前几层中每一个节点只和上一层中部分的节点相连。一个卷积神经网络主要由以下5种结构组成:
1. 输入层
输入层是整个神经网络的输入,在处理图像的卷积神经网络中,它一般代表了一张图片的像素矩阵。比如在上图中,最左侧的三维矩阵就可以代表一张图片。其中三维矩阵的长和宽代表了图像的大小,而三维矩阵的深度代表了图像的色彩通道 (channel)。比如黑白图片的深度为1,而在RGB色彩模式下,图像的深度为3。从输入层开始,卷积神经网络通过不同的神经网络结构将上一层的三维矩阵转化为下一层的三维矩阵,直到最后的全连接层。
2. 卷积层
从名字就可以看出,卷积层是一个卷积神经网络中最为重要的部分。和传统全连接层不同,卷积层中每一个节点的输入只是上一层神经网络的一小块,这个小块常用的大小有3*3或者5*5。卷积层试图将神经网络中的每一小块进行更加深入地分析从而得到抽象程度更高的特征。一般来说,通过卷积层处理过的节点矩阵会变得更深,所以在上图中可以看到经过卷积层之后的节点矩阵的深度会增加。
3. 池化层
池化层神经网络不会改变三维矩阵的深度,但是它可以缩小矩阵的大小。池化操作可以认为是将一张分辨率较高的图片转化为分辨率较低的图片。通过池化层,可以进一步缩小最后全连接层中节点的个数,从而达到减少整个神经网络中参数的目的。
4. 全连接层
在经过多轮卷积层和池化层的处理之后,在卷积神经网络的最后一般会是由1到2个全连接层来给出最后的分类结果。经过几轮卷积层和池化层 的处理之后,可以认为图像中的信息己经被抽象成了信息含量更高的特征。我们可以将卷积层和池化层看成自动图像特征提取的过程。在特征提取完成之后,仍然需要使用全连接层来完成分类任务。
5. Softmax层
Softmax层主要用于分类问题。通过Softmax 层,可以得到当前样例属于不同种类的概率分布情况。
当我们的图片(黑白图片厚度为1 ,彩色图片厚度为3)输入到神经网络后,我门会通过卷积神经网络将图片的长和宽进行压缩,然后把厚度增加。最后就变成了一个长宽很小,厚度很高的像素块。然后结果放入普通的神经网络中处理,最后链接一个分类器,从而分辨出图片是什么。

(图片来源于网络)
3. LeNet字符识别网络
LeNet模型是 Yann LeCun 教授于 1998年在论文 Gradient-based learning applied to document中提出的,它是第一个成功应用于数字识别问题的卷积神经网络。在MNIST数据集上,LeNet模型可以达到大约99.2%的正确率。LeNet模型总共有7层,下图展示了LeNet模型的架构:
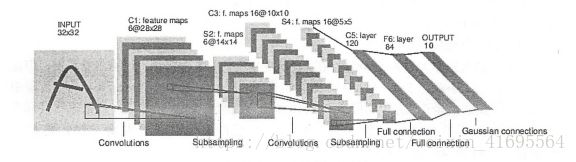
(图片来源于网络)
接下来将介绍LeNet模型每一层的结构:
(1)第一层:卷积层
这一层的输入就是原始的图像像素,LeNet模型接受的输入层大小为32*32*1。第一个卷积层过滤器的尺寸为5*5,深度为6,不使用全0填充,步长为1。因为没有使用全0填充,所以这一层的输出的尺寸为32-5+1=28,深度为6。这一个卷积层总共有 5*5*1*6+6=156个参数,其中6个为偏置项参数。因为下一层的节点矩阵有28*28*6=4704个节点,每个节点和5*5=25个当前层节点相连,所以本层卷积层总共有4704 * (25+1)=122304连接。
(2)第二层:池化层
这一层的输入为第一层的输出,是一个28x28x6的节点矩阵。本层采用的过滤器大小为2x2,长和宽的步长均为2,所以本层的输出矩阵的大小为14*14*6。
(3)第三层:卷积层
本层的输入矩阵大小为14*14*6,使用的过滤器大小为5x5,深度为16。本层不使用全0填充,步长为1。本层的输出矩阵大小为10*10*16。按照标准的卷积层,本层应该有 5*5*6*16+16=2416个参数,10*10*16* (25+1) =41600个连接。
(4)第四层:池化层
本层的输入矩阵大小为10*10*16,采用的过滤器大小为2x2,步长为2。本层的输出矩阵大小为5*5*16。
(5)第五层:全连接层
本层的输入矩阵大小为5x5x16,在LeNet模型的论文中将这一层称为卷积层,但是 因为过滤器的大小就是5x5,所以和全连接层没有区别,在之后的TensorFlow程序实现中也会将这一层看成全连接层。本层的输出节点个数为120,总共有 5*5*16*120+120=48120个参数。
(6)第六层:全连接层
本层的输入节点个数为120个,输出节点个数为84个,总共参数为120*84+84=10164 个。
(7)第七层:全连接层
本层的输入节点个数为84个,输出节点个数为10个,总共参数为84*10+10=850个。
4. MNIST手写数字识别
上面介绍了LeNet模型每一层结构和设置,下面给出一个TensorFlow的程序来实现一个类似LeNet模型的卷积神经网络来解决MNIST数字识别问题。通过TensorFlow训练卷积神经网络的过程和训练全连接神经网络是完全一样的。唯一的区别在于因为卷积神经网络的输入层为一个三维矩阵,所以需要调整一下输入数据的格式。
4.1 代码演示
#coding:utf8
import os
import cv2
import numpy as np
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets('MNIST_data/', one_hot=True) # 导入数据集
sess = tf.InteractiveSession()
iterNum = 10 # 隐含层数
batch_size=64 # 图像大小
def getTrain():
train=[[],[]] # 指定训练集的格式,一维为输入数据,一维为其标签
# 读取所有训练图像,作为训练集
train_root="mnist_train"
labels = os.listdir(train_root)
for label in labels:
imgpaths = os.listdir(os.path.join(train_root,label))
for imgname in imgpaths:
img = cv2.imread(os.path.join(train_root,label,imgname),0)
array = np.array(img).flatten() # 将二维图像平铺为一维图像
array=MaxMinNormalization(array)
train[0].append(array)
label_ = [0,0,0,0,0,0,0,0,0,0]
label_[int(label)] = 1
train[1].append(label_)
train = shuff(train)
return train
def getTest():
test=[[],[]] # 指定训练集的格式,一维为输入数据,一维为其标签
# 读取所有训练图像,作为训练集
test_root="mnist_test"
labels = os.listdir(test_root)
for label in labels:
imgpaths = os.listdir(os.path.join(test_root,label))
for imgname in imgpaths:
img = cv2.imread(os.path.join(test_root,label,imgname),0)
array = np.array(img).flatten() # 将二维图像平铺为一维图像
array=MaxMinNormalization(array)
test[0].append(array)
label_ = [0,0,0,0,0,0,0,0,0,0]
label_[int(label)] = 1
test[1].append(label_)
test = shuff(test)
return test[0],test[1]
def shuff(data):
temp=[]
for i in range(len(data[0])):
temp.append([data[0][i],data[1][i]])
import random
random.shuffle(temp)
data=[[],[]]
for tt in temp:
data[0].append(tt[0])
data[1].append(tt[1])
return data
count = 0
def getBatchNum(batch_size,maxNum):
global count
if count ==0:
count=count+batch_size
return 0,min(batch_size,maxNum)
else:
temp = count
count=count+batch_size
if min(count,maxNum)==maxNum:
count=0
return getBatchNum(batch_size,maxNum)
return temp,min(count,maxNum)
def MaxMinNormalization(x):
x = (x - np.min(x)) / (np.max(x) - np.min(x))
return x
# 1、权重初始化,偏置初始化
# 为了创建这个模型,我们需要创建大量的权重和偏置项
# 为了不在建立模型的时候反复操作,定义两个函数用于初始化
def weight_variable(shape):
initial = tf.truncated_normal(shape,stddev=0.1)#正太分布的标准差设为0.1
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant(0.1,shape=shape)
return tf.Variable(initial)
# 2、卷积层和池化层也是接下来要重复使用的,因此也为它们定义创建函数
# tf.nn.conv2d是Tensorflow中的二维卷积函数,参数x是输入,w是卷积的参数
# strides代表卷积模块移动的步长,都是1代表会不遗漏地划过图片的每一个点,padding代表边界的处理方式
# padding = 'SAME',表示padding后卷积的图与原图尺寸一致,激活函数relu()
# tf.nn.max_pool是Tensorflow中的最大池化函数,这里使用2 * 2 的最大池化,即将2 * 2 的像素降为1 * 1的像素
# 最大池化会保留原像素块中灰度值最高的那一个像素,即保留最显著的特征,因为希望整体缩小图片尺寸
# ksize:池化窗口的大小,取一个四维向量,一般是[1,height,width,1]
# 因为我们不想再batch和channel上做池化,一般也是[1,stride,stride,1]
def conv2d(x, w):
return tf.nn.conv2d(x, w, strides=[1,1,1,1],padding='SAME') # 保证输出和输入是同样大小
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1,2,2,1], strides=[1,2,2,1],padding='SAME')
train=getTrain()
test0,test1=getTest()
# 3、参数
# 这里的x,y_并不是特定的值,它们只是一个占位符,可以在TensorFlow运行某一计算时根据该占位符输入具体的值
# 输入图片x是一个2维的浮点数张量,这里分配给它的shape为[None, 784],784是一张展平的MNIST图片的维度
# None 表示其值的大小不定,在这里作为第1个维度值,用以指代batch的大小,means x 的数量不定
# 输出类别y_也是一个2维张量,其中每一行为一个10维的one_hot向量,用于代表某一MNIST图片的类别
x = tf.placeholder(tf.float32, [None,784], name="x-input")
y_ = tf.placeholder(tf.float32,[None,10]) # 10列
# 4、第一层卷积,它由一个卷积接一个max pooling完成
# 张量形状[5,5,1,32]代表卷积核尺寸为5 * 5,1个颜色通道,32个通道数目
w_conv1 = weight_variable([5,5,1,32])
b_conv1 = bias_variable([32]) # 每个输出通道都有一个对应的偏置量
# 我们把x变成一个4d 向量其第2、第3维对应图片的宽、高,最后一维代表图片的颜色通道数(灰度图的通道数为1,如果是RGB彩色图,则为3)
x_image = tf.reshape(x,[-1,28,28,1])
# 因为只有一个颜色通道,故最终尺寸为[-1,28,28,1],前面的-1代表样本数量不固定,最后的1代表颜色通道数量
h_conv1 = tf.nn.relu(conv2d(x_image, w_conv1) + b_conv1) # 使用conv2d函数进行卷积操作,非线性处理
h_pool1 = max_pool_2x2(h_conv1) # 对卷积的输出结果进行池化操作
# 5、第二个和第一个一样,是为了构建一个更深的网络,把几个类似的堆叠起来
# 第二层中,每个5 * 5 的卷积核会得到64个特征
w_conv2 = weight_variable([5,5,32,64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, w_conv2) + b_conv2)# 输入的是第一层池化的结果
h_pool2 = max_pool_2x2(h_conv2)
# 6、密集连接层
# 图片尺寸减小到7 * 7,加入一个有1024个神经元的全连接层,
# 把池化层输出的张量reshape(此函数可以重新调整矩阵的行、列、维数)成一些向量,加上偏置,然后对其使用Relu激活函数
w_fc1 = weight_variable([7 * 7 * 64, 1024])
b_fc1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2, [-1,7 * 7 * 64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, w_fc1) + b_fc1)
# 7、使用dropout,防止过度拟合
# dropout是在神经网络里面使用的方法,以此来防止过拟合
# 用一个placeholder来代表一个神经元的输出
# tf.nn.dropout操作除了可以屏蔽神经元的输出外,
# 还会自动处理神经元输出值的scale,所以用dropout的时候可以不用考虑scale
keep_prob = tf.placeholder(tf.float32, name="keep_prob")# placeholder是占位符
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
# 8、输出层,最后添加一个softmax层
w_fc2 = weight_variable([1024,10])
b_fc2 = bias_variable([10])
y_conv = tf.nn.softmax(tf.matmul(h_fc1_drop, w_fc2) + b_fc2, name="y-pred")
# 9、训练和评估模型
# 损失函数是目标类别和预测类别之间的交叉熵
# 参数keep_prob控制dropout比例,然后每100次迭代输出一次日志
cross_entropy = tf.reduce_sum(-tf.reduce_sum(y_ * tf.log(y_conv),reduction_indices=[1]))
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
# 预测结果与真实值的一致性,这里产生的是一个bool型的向量
correct_prediction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(y_, 1))
# 将bool型转换成float型,然后求平均值,即正确的比例
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
# 初始化所有变量,在2017年3月2号以后,用 tf.global_variables_initializer()替代tf.initialize_all_variables()
sess.run(tf.global_variables_initializer())
# 保存最后一个模型
saver = tf.train.Saver(max_to_keep=1)
for i in range(iterNum):
for j in range(int(len(train[1])/batch_size)):
imagesNum=getBatchNum(batch_size,len(train[1]))
batch = [train[0][imagesNum[0]:imagesNum[1]],train[1][imagesNum[0]:imagesNum[1]]]
train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})
if i % 2 == 0:
train_accuracy = accuracy.eval(feed_dict={x: batch[0], y_: batch[1],keep_prob: 1.0})
print("Step %d ,training accuracy %g" % (i, train_accuracy))
print("test accuracy %f " % accuracy.eval(feed_dict={x: test0, y_:test1, keep_prob: 1.0}))
# 保存模型于文件夹
saver.save(sess,"save/model")
运行程序,最后得到LeNet模型,进入所在的文件夹,如下:

准确率:![]()
接下来可在可视化的界面上测试数据了。
代码如下:
import tensorflow as tf
import numpy as np
import tkinter as tk
from tkinter import filedialog
from PIL import Image, ImageTk
from tkinter import filedialog
import time
def creat_windows():
win = tk.Tk() # 创建窗口
sw = win.winfo_screenwidth()
sh = win.winfo_screenheight()
ww, wh = 400, 450
x, y = (sw-ww)/2, (sh-wh)/2
win.geometry("%dx%d+%d+%d"%(ww, wh, x, y-40)) # 居中放置窗口
win.title('手写体识别') # 窗口命名
bg1_open = Image.open("timg.jpg").resize((300, 300))
bg1 = ImageTk.PhotoImage(bg1_open)
canvas = tk.Label(win, image=bg1)
canvas.pack()
var = tk.StringVar() # 创建变量文字
var.set('')
tk.Label(win, textvariable=var, bg='#C1FFC1', font=('宋体', 21), width=20, height=2).pack()
tk.Button(win, text='选择图片', width=20, height=2, bg='#FF8C00', command=lambda:main(var, canvas), font=('圆体', 10)).pack()
win.mainloop()
def main(var, canvas):
file_path = filedialog.askopenfilename()
bg1_open = Image.open(file_path).resize((28, 28))
pic = np.array(bg1_open).reshape(784,)
bg1_resize = bg1_open.resize((300, 300))
bg1 = ImageTk.PhotoImage(bg1_resize)
canvas.configure(image=bg1)
canvas.image = bg1
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
saver = tf.train.import_meta_graph('save/model.meta') # 载入模型结构
saver.restore(sess, 'save/model') # 载入模型参数
graph = tf.get_default_graph() # 加载计算图
x = graph.get_tensor_by_name("x-input:0") # 从模型中读取占位符变量
keep_prob = graph.get_tensor_by_name("keep_prob:0")
y_conv = graph.get_tensor_by_name("y-pred:0") # 关键的一句 从模型中读取占位符变量
prediction = tf.argmax(y_conv, 1)
predint = prediction.eval(feed_dict={x: [pic], keep_prob: 1.0}, session=sess) # feed_dict输入数据给placeholder占位符
answer = str(predint[0])
var.set("预测的结果是:" + answer)
if __name__ == "__main__":
creat_windows()
测试结果:
