金融风控实战——风控领域涉及到的算法和风控算法工程师需要具备的能力
一些简单的介绍
市面上算法相关的岗位,从大范围上分为两大类
1、研究驱动的算法工程师,这类算法工程师的门槛很高,分布在大型公司的研究院、创新实验室等部门,这类算法工程师主要是以研究新的算法或者是更好的优化方案或是算法的高性能实施等等为主,简单来说类似于高校的博士生,做研究,发paper;
2、业务驱动的算法工程师,这类算法工程师的占比相对来说高得多,目前我们在各大招聘网站上看到的绝大多数都是基于业务驱动的算法工程师,这类算法工程师主要以算法的应用并且为企业直接或间接带来利润为主要目的,也是我们大多数人关注的,想要入行的职位。
当然很多时候二者并不是完全独立的,即使基于业务驱动的算法工程师很多时候也要兼顾各种创新型的工作,研究驱动的算法也要了解一些业务知识
风控算法工程师的岗位基本上大部分是基于业务驱动的,但是实际上在风控算法工程师的领域还是有很多的细分,例如典型的信贷平台的各类评分卡,反欺诈;网络媒体的流量作弊检测;电商平台的刷单、买好评的黑产识别等等,这里主要针对金融领域的风控算法工程师进行展开,当然很多算法的理论是相通的,只是应用场景上有一些不同。
金融领域的风控整体来说相对于推荐、图像、nlp要好入门好转行;
风控领域的公司整体上的技术要求可能千差万别,有一些公司仅仅要求你对传统的机器学习那一套比较熟悉并且有一定的项目经验即可,而有一些待遇比较诱人的公司不仅需要你懂传统的ml,还要兼懂nlp、图算法、深度学习相关等等的领域,所以,入行不难,但是要深入成为优秀的风控算法工程师也是要走很多很多的弯路的,特别是头部公司的风控岗位,需要求职者对于机器学习、深度学习、大数据技术等都要有较为深入的理解与应用经验等。
我们戏称为“全栈算法工程师”
而风控算法的岗位分布的公司有:
1、银行、银行科技子公司等传统金融机构的算法部门,这类算法工程师面向的主要是银行业务的信贷、反欺诈等方向的建模工作;
2、互联网金融公司,例如拍拍贷、马上消费、趣店等以消费贷等信贷业务为主的互联网公司,这类公司自身是有信贷相关业务的,这类算法工程师面向的常见的业务之一是小额消费类贷款;
3、互联网科技公司,比较知名的例如猛犸、Datavisor以提供风控行业的解决方案——以产品或者人力或者二者兼有的方式,俗称乙方,这类公司一般没有自己的信贷业务,主要是以产品或者人力等形式为银行等大型机构提供相应的算法服务;
4、数据商,比如典型的百融,同盾,当然这类公司也常常有一些针对风控的场景设计的一些产品;
5、其它
当然实际情况会更复杂,可能同一个公司同时“身兼数职”,同时扮演多个角色。
不得不说,随着算法工程师行业的大量人才的涌入,算法岗的招聘标准越来越高,所需要掌握的算法知识也越来越广,在实际的业务中除了传统的一些常见的机器学习算法例如逻辑回归、gbdt等,许多场景下还需要我们熟悉更多领域的算法,包括了现在火热的图算法和图神经网络、知识图谱、迁移学习等等,下面大概介绍一下不同领域的算法在金融风控领域的一些应用以及这个领域需要具备的一些基本的技能。
可解释机器学习
特别是对于银业行来说,可解释性的需求是非常强烈的,毕竟是直接和白花花的银子打交道的,当然不仅仅是银行,很多时候我们都希望能够结合我们的先验知识与模型共同决策,业务对技术不熟悉,也不会单纯看模型的评估指标或者评估报告就回复“yes”,他们往往希望模型能够提供合理的逻辑上能够理解的解释,例如某个客户被A卡判定为不合格用户,我们需要知道具体是客户的哪些特征不符合模型的要求。
可解释性机器学习从早期的简单的feature importance,w权重等等逐渐过渡到了部份依赖图、shap等等更加先进的模型可解释的算法上,可以说,可解释机器学习已经成为了一个独立的研究领域。
下面列出一些常见的可解释机器学习的方法:
- feature importance
- 逻辑回归本身的权重
- 部分依赖图
- shap
- Lime
- permutation importance
- null importance
- 等等
不同的可解释性算法从不同的角度对模型进行解释,例如shap基于shap values的思想,可以实现样本粒度的解释;部份依赖图通过固定特征,在单个特征上进行随机取值从而对特征贡献度进行解释;permutation importance基于特征随机排列对预测结果的影响对特征进行解释等等
图算法与图神经网络
理论上来说,当用户之间存在一定的社交关系,我们都可以通过图算法或者图神经网络对用户的社交关系进行特征提取与表示,例如最简单的,通过对社交网络的一些统计特征的计算,比如用户的度,用户所处社区的数量,用户的边数量等来对原始的特征进行补充,或者典型的deepwalk和node2vec对于用户隐式的社交关系的提取;page rank计算用户的“热门”程度;社区发现算法用于发现用户的团体关系等等
当然,图系列算法的功能不仅如此,在反欺诈、失联模型等图算法都有可以应用的地方;
下面简单罗列一些相关的算法:
- pagerank
- 标签传播
- Louvain Modularity
- graph embedding系列包括deepwalk node2vec sdne等
- GNN系列例如现在常常听到的GCN,Graphsage等
迁移学习
迁移学习分为浅层迁移学习与深度迁移学习,深度迁移学习已经在nlp和cv领域得到了非常广泛的应用,但是在传统的tabuar数据领域,迁移学习并没有取得那么辉煌的成就,但是实际上很多浅层的迁移学习算法对于特征分布偏移、项目的冷启动等问题都提供了不错的解决方案
下面简单罗列一些相关的算法:
- kmm
- tradaboost
- kliep
- 基于模型推断样本权重的方法
- 对抗性验证
- 子空间映射的一系列降维算法,包括典型的自编码器
- fine tuning
- 多任务学习
表征学习
当原始数据中存在大量关联性高的文本特征,我们需要一些nlp领域的知识来妥善的处理,这里实际上涉及到很多自然语言处理的基本知识,包括文本的预处理的流程,正则化的灵活应用,常见的文本特征的表达等等等
这里简单列举一些相关的算法:
- tfidf
- 主题模型系列lsi、lda
- word2vec,glove、doc2vec
- lda2vec
- bert,xlnet等
google上有很好的正则表达式的练习网站,感兴趣的可以去练练手
自动化机器学习
广义上来说,项目最终都需要落到自动化上,例如典型的场景,模型上线之后,特征工程的加工过程需要固化成代码,便于新数据到来的自动加工处理,除此之外,如何快速有效的完成繁琐重复的建模流程对于企业来说是比较重要的,自动化机器学习目前比较常见的分支有automl和autodl,automl和风控算法的相关性较大,包括自动化的特征衍生、自动化特征选择、自动化模型调参等等
这里简单列举一些相关的框架或算法
- featuretools
- gplearn
- tsfresh
- 贝叶斯优化家族包括基于高斯过程、基于随机森林、基于gbdt的贝叶斯优化以及tpe(hyperot的核心)
- 前后项特征消除、rfe、boruta等
- 一些完整的大型的框架比如 automl、tpot等等
- 遗传算法系列
半监督学习
在拒绝推断中常常使用到半监督学习的思想,典型的场景A卡不断的筛选掉坏客户使得最终的用户样本集中基本都是好客户,后续的模型无法继续有效的迭代,因为坏客户基本“死光了”,从而导致新模型没有充分的坏客户数据进行训练,泛化性能越来越差。
除此之外,对于一些缺少足够标签的企业来说,半监督学习也是一种解决问题的思路,通过一些特定的方法来利用无标签数据。
这里简单列举一些相关的算法:
- 伪标签技术
- pu learning系列算法
- co training
序列模型
在B卡中较为常见,B卡中常常会有用户的消费数据,这些数据常常具有一定的序列相关性,除此之外,反欺诈场景中也会有用户的一些消费序列数据,我们可以使用序列模型例如LSTM或者attention的机制来对序列特征进行特征抽取作为原始特征的有力补充从而提高最终模型的泛化能力。
下面列举一些相关的算法:
- 最简单的时间窗统计;
- LSTM GRU
- 引入attention机制的RNN
不均衡学习
类别分布不平衡是风控领域非常常见的问题,针对于类别分布不平衡我们需要使用一些不均衡学习的手段来妥善处理,大体上分为采样、损失函数的修改以及二者的结合,当然如果本身分类问题比较简单属于易分类问题我们也不太需要引入不均衡学习
简单列举一些常见的算法:
- 上下采样的方法,smote,adasyn,聚类采样,随机下采样;
- 集成采样,smoteboost,easysemble,cusboost等;
- 各种魔改损失函数,比如经典的二分类和多分类focal loss
我们需要知道,类别不均衡并不是模型效果不好的本质原因,分类问题的难度大例如类别分布重叠,子类别分布的情况,换句话说即使类别均衡的分布如果是困难的分类问题模型效果一样会比较渣。只不过类别不平衡的情况下更容易出现分类困难的问题
传统的机器学习算法
目前来说,评分卡而言常用的算法主要是两种,一个是逻辑回归,一个是gbdt系列的包括了xgb和lgb
除此之外还有一些其它的知识需要掌握,例如分箱系列的算法,包括决策树分箱、卡方分箱、自动分箱、等频分箱等,以及特征编码 woe编码,特征的过滤式指标,IV值,模型的评估指标ks auc psi等等
特征工程
在表格数据的建模项目中,特征工程占据了我们绝大部分的时间,这里包括了原始数据的特征清理,表关联等等前期需要做的准备工作,无论是工作中还是比赛里,结构化数据的重点往往是围绕着特征工程的好坏展开的,好的特征常常要好过各种各样前沿的算法,特征工程方面的技术太多了,这里简单列举一部分:
- 特征编码技术
- 特征交叉
- 过滤式、包裹式、嵌入式、混合式特征选择
- 缺失值处理技术包括了常值插补,极限值插补,多重插补等等
- 时间特征的展开,基于时间窗的各种统计
- 地理特征的经纬度编码
- 周期特征的cycle编码等
pu learning
pu learning,作为半监督学习的重要分支,主要解决one class的问题——即只有正类而没有反类或者说反类的数量极其稀少的情况,具体的应用场景和上面提到的半监督学习的应用场景类似,简单列举部分算法:
- spy;
- 伪标签技术(和半监督的伪标签类似)
- pu bagging
集成学习
集成学习的分类除了我们熟悉的同质和异质,实际上还有很多实现方式,包括了模型的多次随机初始化平均,nn的典型的snapshot算法,不同参数下训练的同质学习器的简单平均等,一般最为常用的就是简单平均的方法了。
当一个评分卡存在多个评分子模型的时候可能会使用到一些集成的方法
简单列举一些常见的集成方法
- bagging
- stacking
- blending
- voting
- nn的snapshot
深度学习
目前比较少见使用深度学习来制作评分卡,但是在金融风控的其它领域,深度学习的地位还是很重要的,同时前面提到的lstm,表征学习中的word2vec都是典型的神经网络结构,如果对深度学习没有一个较好的了解,在理解一些nn相关的知识会比较困难,因此,对于深度学习还是需要掌握其基础知识的。
关于深度学习列举一些需要了解的:
- BP;
- sgd以及各类魔改的一阶优化算法,比如adam,rmsprop等;
- 梯度消失与梯度爆炸问题;
- bn层;
- dropout
- 三大网络架构,DNN、CNN、RNN以及经典的attention机制
对于应用来说,很多时候我们关注nn结构的前向传播过程足够,反向传播交给tf或者torch底层的自动微分框架完成即可
异常检测
大体上常见的有outliter detection和novelty detection,outlier detetion,outlier detection 分为global 和 local两种思想,global衡量全局异常性,即从全量数据上考虑样本的异常程度,例如GMM算法,isolation forest,local则衡量的是局部异常性,典型的如lof,之前做过一些简单的测试,可见:https://zhuanlan.zhihu.com/p/93779599 常见于一些缺乏标签或者是分类定义不明确且标签稀少的数据场景。
简单列举一些常见的算法
- lof
- 聚类家族
- 高斯家族
- isolation forest
- onclass svm
- 自编码器
- xgbod
- 集成异常检测
异常检测算法大都比较依赖于特征工程的设计,也就是我们常说的比较“吃特征”,
联邦学习
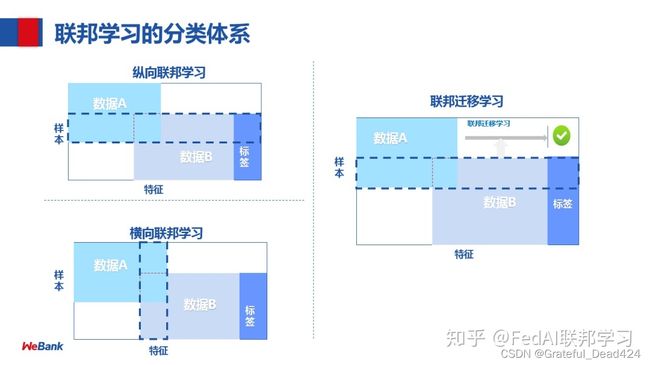
听起来思路挺简单,实现起来复杂,落地更复杂的领域。算法的原理大体上是变化不大的,主要是算法训练的过程中,包括了梯度的传输、数据的传输等都涉及到复杂的加密技术,并且需要有一定的基础设施的条件才有实现的可能,除此之外,金融数据的敏感与数据方的不信任等问题,目前要大面积推广还是存在比较多的困难。
一些流程性的工作介绍
从一个项目的角度来说,建模在整个项目的流程中只占据了一小部分,下面大概介绍一下评分卡A卡的整个项目的大体流程。
- 项目的确定:并不是所有公司都有足够的资源去构建评分卡的,缺少数据与标签是最主要的问题,除此之外,特征字段是否丰富,内部数据的产生是否稳定等都是前期需要考虑的重要问题;
- 数据的接入,除了公司自身所拥有的一些数据例如申请人的基本申请信息,很多机构往往还会选择购买一些第三方数据商的数据,尤其是早期的一些规模不大的公司本身就没多少历史数据,非常依赖于第三方的数据,例如典型的用户的多头借贷数据,运营商信息等等
- 样本的清理: 一批新的申请人,并不是所有人都能进入评分卡模型的构建中,一般 命中黑名单规则、法院记录、反欺诈引擎或者是机构或国家规定的一些硬性规定(例如用户的年龄太大或太小)的用户后续是不会纳入建模体系中的。
- 特征的清理,关联率低,业务认为无效的特征,数据来源不稳定的特征,偏移太大的特征等等,初期都会进行一些粗筛的工作;
- 确定标签,如果公司本身内部就拥有比较充足的标签用户,这一步很快就能完成,如果缺乏,则需要考虑一些别的方法例如购买其它机构的信用评级分,或者初期考虑先人审,积累足够数据之后再建模;
- 确定观察期和表现期,常见的vintage分析和滚动率分析来确定其时间长短,当然,并不绝对,一些公司直接使用固定的时间跨度来定义观察期与表现期;
- 构建A卡,数据挖掘,特征工程,模型构建,调参,测试,oot test,模型的解释性。。。。。这一部的整个过程和竞赛类似,特征工程和模型构建之间是不断交互进行的。
- 模型构建完毕,达到上线标准,准备上线,特征工程的规则的固化,预测用的api的撰写,不同机构采用的上线方式不尽相同,目前使用的方式是平台+api,java工程师传入数据,我们提供python的api接口,在api中完成特征转换与模型预测,最后将结果输出传回,模型以pkl的形式保存和读取;
- 模型监控,检测模型预测的好坏客户的分布变化情况,模型的ks auc的变动情况,预测结果的psi反应模型的稳定性,以及各种各样的调试与修改,比如常见的特征转换的bug,模型衰减等等,如果模型的效果衰减的比较厉害就要考虑rebuild了
python的熟练使用
pandas numpy
基本的pandas numpy 要熟练使用,算法工程师的工作过程中也会涉及到许多小型的开发工作,这个时候如何高效的写出高性能的代码就比较重要了,下面列举一些常用的方法:
-
数据类型的简化,object的内存占用要远大于category数据类型,float64远大于float16,一般来说float32的数据类型足够了,这样不但能大大减轻数据的内存占用,也能提高模型运算的效率;
-
高性能内置函数的使用,python的高性能编程拥有与C媲美的速度,使用上也比较简约,更人性化的是,很多运算的高效实现也做了很好的封装,例如pandas的eval和query,numpy的矢量化方法vector以及numexpr。
-
第三方数据处理框架的使用,如果有足够的gpu资源,并且涉及到非常多的矩阵运算,使用cudf和cupy可以非常高效快速的进行处理;
-
并行,multiprocessing和joblib,ppserver的官方文档太少,貌似很久没人维护,常用是这两种,joblib是skleran默认使用的并行库。
-
编译的层面进行优化,通过基于llvm的numba和编译成C的cython等,numba和cython本身也有并行功能;
-
python的各种高效的内置方法,包括列表解析,lambda,eval,不定参数,低内存占用的tuple,尽量避免深拷贝,使用查询而不是切片出子数据的方法来对dataframe进行操作、灵活的使用矩阵运算代替循环等等等等
基本的大数据框架的api的使用
hive使用的频率较多,hive本身的api的使用不难,和sql的语句差不多,这个看看工具书,自己试用一下就可以了;pyspark引入了dataframe之后使用的难度也很低了,常用pandas的很快能上手,这些东西难在工程优化和环境搭建的麻烦上。当然如果要深入高效的做一些开发性质的工作还是需要深入学习的。
数据库的基本操作
增删查改基本功,这些就不用多说了,google上有sql的训练教程,没事儿可以刷一刷,这个基本是必备技能;
主流框架的熟练应用
sklearn xgboost lightgbm torch tensorflow 不仅仅会简单的跑一些demo,xgb的自定义损失函数,各类参数的常用范围,各类参数的使用效果,sklearn api的开发等等,考虑到现在招聘的难度越来越大,torch或tf的使用也要熟悉熟悉,包括自定义层,自定义损失函数,灵活的网络结构的设计等等,项目的落地需要代码,好的代码需要大量的编程实践和api的熟悉。
一些学习方法的介绍
-
写blog,把学习的过程记录下来,经典的费曼学习法,非常有效;
-
打比赛,经常逛kaggle,kaggle最好的地方就是开源的kernel特别多,数据大都是工业的真实数据,kernel里的各种baline也有非常强的借鉴意义,tabular比赛中基本上常用的解决业务问题的思路都会有相应的代码实现;另外datawhale的公众号做的很不错,还有kaggle竞赛宝典,github上的各种top solution的代码,对于转行的人来说,没有数据,没有项目练手,比赛是最直接方便的,而且比赛的名次对于个人学习欲望的驱动是很强的,初期如果有大佬带能少走很多弯路。
-
看综述,最快的入门某个领域的方法,现有整体性的把握,然后再逐个击破或者研究某一个与自己相关的领域就行,比如序列模型的范围本身是很广的,有一个系统全面的认识,然后再去仔细研究其中的某个能用上的领域。
-
有空刷刷leetcode,用python或者C来刷,虽然很多传统的数据结构与算法python都已经封装的很好了,但是对于编程能力的提高,leetcode是非常简单快速暴力的
-
知乎上的各种大佬的专栏,houye、陈泽、浅梦、砍手豪等等,就搜索来说,国内的知乎基本上是机器学习相关知识最好的获取处之一,除此之外就是一些大佬的blog比如刘建平博客园和苏剑林的科学空间等等,谷歌上的towardscience,quora,StackOverflow等等,GitHub上的问答区等等
-
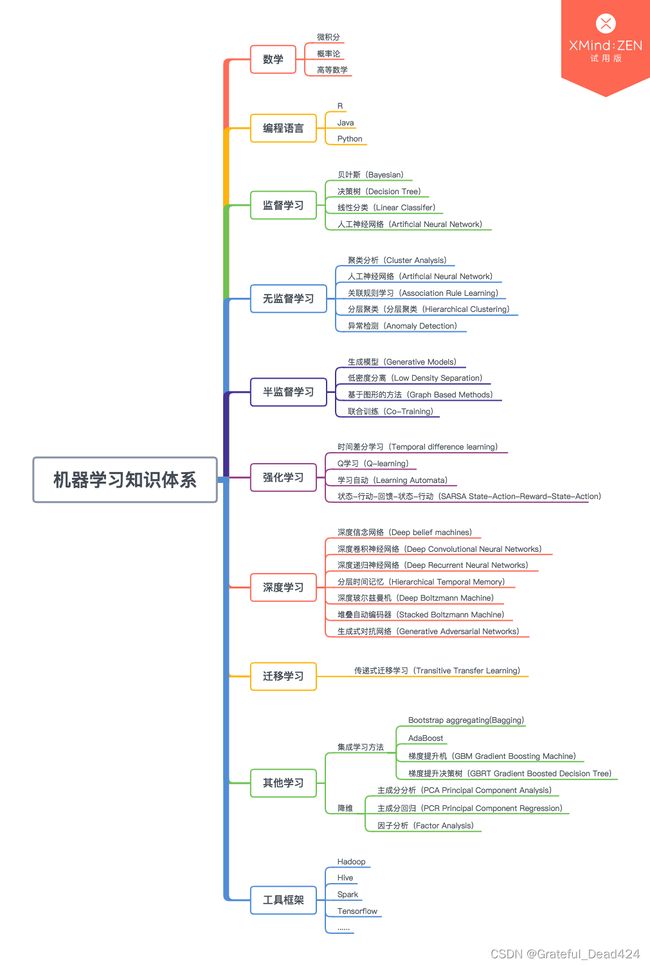
构建完善的知识体系——通过思维导图的方式
-
基本的数学基础,边缘概率分布、联合概率分布、条件概率分布等,微积分,偏导、梯度下降法等等,当然不需要太过深入的去研究,主要目的是算法的推导能看懂,自己能够理解的推导出来就可以了,《程序员的数学》系列是一个不错的选择,还有一些网络课程会系统性的教授这些基础。