python数据分析的一些基础性知识(二)
1、特征观察与处理
特征分为文本型特征和数值型特征,而数值型特征分为离散型数值特征和连续性数值特征。数值型特征一般可以直接用于构建模型,有时为了模型稳定和鲁棒性会对连续变量离散化,文本型特征往往是需要转换成数值型特征才能用于建模分析的。
(1)分箱操作(离散化处理)
cut()函数把数值分段,pandas.cut(x,bins,right=True,labels=None,...)
x:需要处理的数据,必须是1维的
bins:怎么分段,给他一个数字就是令其分成几段,比如令bins=5就是平均分成5段,如果要定义具体区间,就要给出一串数字,如[0, 1, 2, 3, 4, 5]。
right:区间是右闭还是右开,默认左开右闭,变成左闭右开即令right=False.
labels:给每一段取一个名字,默认是None(没有),labels=list(‘12345’)
qcut()函数,给一串数字按百分比分段,pandas.qcut(x,q,labels,...)
x:一段一维数据
q:自定义的百分比。如,[0, 0.25, 0.5, 0.75, 1]
labels:同上述labels
duplicates:默认为‘raise’,意为边缘唯一,如果运行程序报错:Bin edges must be unique,解决时只需把duplicates的唯一性去掉,在函数中令duplicates=drop即可。
(2)对文本变量进行转换
文本变量变成数值变量
①replace()函数,下面举一个例子来介绍一下replace()函数的用法,把性别即(男、女)转化成数值(1、2)Sex.replace(['male', 'female'], [1, 2], inplace = True)。
②如果要转换的变量比较多,可以调用sklearn.preprocessing包中的LabelEncoder函数LabelEncoder().fit_transform('要改变的列')可以直接将文本变量变成数字变量。如果这一列中既有文本变量又有数值变量,会产生错误,只需在列名后面加.astype(str)将其全部变为文本向量即可,如Cabin.astype(str)或LabelEncoder().fit_transform(Cabin.astype(str))。
文本变量变成one-hot编码
关于one-hot编码,这里不多做介绍,不懂的朋友可以移步链接: One-Hot 编码.
把文本数据变成one-hot编码,也非常简单,只需要用到pandas.get_dummies()函数。
data:需要处理的数据
prefix:列名的前缀
prefix_sep:列名的默认连接方式
这里扩展一个函数concat([x, y], axis = 1):把x与y按列拼接到一块
从纯文本特征中提取特征
pandas.Series.str.extract()函数
pat:提取出文本的规律
从name中提取title(即Mr、Miss、Mrs等)
title = name.str.extract('([A-Za-z]+)\.')。
2、数据重构
(1)数据合并
假设我们拥有四个csv文件,分别为left_up.csv、left_down.csv、right_up.csv、right_down.csv,导入后的数据名分别为left_up、left_down、right_up、right_down,以此为例开始描述一些数据合并方面的基础知识。
up = pandas.concat([left_up, right_up], axis=1):横向合并left_up和right_up,组成新的up数据。
同理可知down = pandas.concat([left_down, right_down], axis=1)
再纵向合并up和down成一个新的数据result:result = pandas.concat([up, down])
由上可知axis可控制两数据横向合并(1)或纵向合并(0),默认值为0.
还可以使用DataFrame自带的join()和append()。
join 列横向合并
append 行纵向合并
up = left_up.join(right_up)
down = left_down.join(right_down)
result = up.append(down)
此外还可以使用pandas中的merge()和DataFrame中的append().
up = pd.merge(left_up, right_up, left_index = True, right_index = True)
down = pd.merge(left_down, right_down, left_index = True, right_index = True)
result = up.append(down)
上述三种方法所得到的result是一样的,其中,append()和concat()默认是行纵向合并,join()和merge()是列横向合并merge()使用起来比较麻烦,要求较多,不建议使用,concat()函数较为通用,只需要改变axis的值就可以分别实现横向纵向合并。
数据变为Series类型:stack()函数。
(2)数据运用
使用GroupBy机制,对GroupBy的相关介绍.
对于一个拥有Sex、Age、Fare、Pclass等列的数据test。
可以按sex将其分为group = test.groupby('Sex')。,就可以得到男性的数据和女性的数据。
男女平均花费:mean_fare_sex = test.groupby('Sex')['Fare'].mean()
男女生存人数:survived_sex = test.groupby('Sex')['Survived'].sum()
不同级别生存人数:test.groupby('Pclass')['Survived'].sum()
agg()函数:使用比较易懂,如不同级别生存人数:test.groupby('Pclass')['Survived'].agg(sum)与上述表达意思一致。
优点在于agg()函数可以同时改变多个变量:test.groupby('Age').agg({'Survived':'sum', 'Fare':'mean'}).rename(columns = {'Survived':'survived_sum', 'Fare':'fare_mean'})
上面用到了rename()函数,顾名思义,即为给其重命名。
3数据可视化
可视化即把数据转化成便于直接观察的图片,主要是使用matplotlib包中的pyplot()函数,将其简写为plt。
折线图:plot()
柱状图:plot.bar()
直方图:plt.hist()
给图象加标题:plt.title(‘标题’)
对于上述数据运用中的数据test,我们可以对其作出以下图:
男女生存人数(生存1 死亡0):
sex = df.groupby('Sex')['Survived'].sum()
sex.plot.bar()
plt.title('survived')
图象如图:

男女生存死亡人数(生存1 死亡0):
sex_survived = df.groupby(['Sex', 'Survived'])['Survived'].count().unstack()
sex_survived.plot.bar() # 图一
sex_survived.plot(kind = 'bar', stacked = 'True') # 图二
图一:

图二:
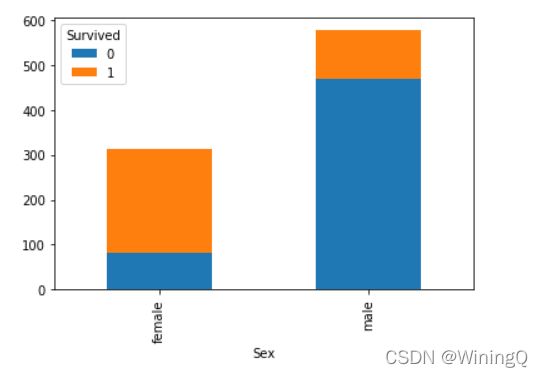
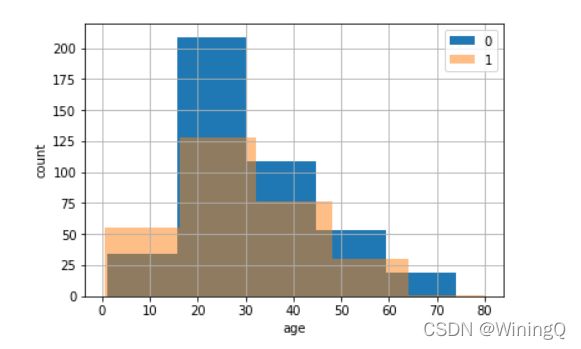
直方图:
test.Age[df.Survived == 0].hist(bins = 5, alpha = 1)
test.Age[df.Survived == 1].hist(bins = 5, alpha = 0.5)
plt.legend((0,1))
plt.xlabel('age')
plt.ylabel('count')
得出图象如图:
优化一下:
test.Age[df.Survived == 0].hist(bins = 5, alpha = 1, density = 1)
test.Age[df.Survived == 1].hist(bins = 5, alpha = 0.5, density = 1)
test.Age[df.Survived == 0].plot.density()
test.Age[df.Survived == 1].plot.density()
plt.legend((0,1))
plt.xlabel('age')
plt.ylabel('density')
图象如图:
