一,jieba的介绍
jieba 是目前表现较为不错的 Python 中文分词组件,它主要有以下特性:
支持四种分词模式:
- 精确模式
- 全模式
- 搜索引擎模式
- paddle模式
支持繁体分词
支持自定义词典
MIT 授权协议
二,安装和使用
1,安装
pip3 install jieba
2,使用
import jieba
三,主要分词功能
1,jieba.cut 和jieba.lcut
lcut 将返回的对象转化为list对象返回
传入参数解析:
def cut(self, sentence, cut_all=False, HMM=True, use_paddle=False): # sentence: 需要分词的字符串; # cut_all: 参数用来控制是否采用全模式; # HMM: 参数用来控制是否使用 HMM 模型; # use_paddle: 参数用来控制是否使用paddle模式下的分词模式,paddle模式采用延迟加载方式,通过enable_paddle接口安装paddlepaddle-tiny
1)精准模式(默认):
试图将句子最精确地切开,适合文本分析
seg_list = jieba.cut("我来到北京清华大学", cut_all=False)
print("精准模式: " + "/ ".join(seg_list)) # 精确模式
# -----output-----
精准模式: 我/ 来到/ 北京/ 清华大学
2)全模式:
把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;
seg_list = jieba.cut("我来到北京清华大学", cut_all=True)
print("全模式: " + "/ ".join(seg_list)) # 全模式
# -----output-----
全模式: 我/ 来到/ 北京/ 清华/ 清华大学/ 华大/ 大学
3)paddle模式
利用PaddlePaddle深度学习框架,训练序列标注(双向GRU)网络模型实现分词。同时支持词性标注。
paddle模式使用需安装paddlepaddle-tiny,pip install paddlepaddle-tiny==1.6.1。
目前paddle模式支持jieba v0.40及以上版本。
jieba v0.40以下版本,请升级jieba,pip installjieba --upgrade。 PaddlePaddle官网
import jieba
# 通过enable_paddle接口安装paddlepaddle-tiny,并且import相关代码;
jieba.enable_paddle() # 初次使用可以自动安装并导入代码
seg_list = jieba.cut(str, use_paddle=True)
print('Paddle模式: ' + '/'.join(list(seg_list)))
# -----output-----
Paddle enabled successfully......
Paddle模式: 我/来到/北京清华大学
2,jieba.cut_for_search 和 jieba.lcut_for_search
搜索引擎模式
在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词
seg_list = jieba.cut_for_search("小明硕士毕业于中国科学院计算所,后在日本京都大学深造") # 搜索引擎模式
print(", ".join(seg_list))
# -----output-----
小明, 硕士, 毕业, 于, 中国, 科学, 学院, 科学院, 中国科学院, 计算, 计算所, ,, 后, 在, 日本, 京都, 大学, 日本京都大学, 深造
3,jieba.Tokenizer(dictionary=DEFAULT_DICT)
新建自定义分词器,可用于同时使用不同词典。jieba.dt 为默认分词器,所有全局分词相关函数都是该分词器的映射。
import jieba
test_sent = "永和服装饰品有限公司"
result = jieba.tokenize(test_sent) ##Tokenize:返回词语在原文的起始位置
print(result)
for tk in result:
# print ("word %s\t\t start: %d \t\t end:%d" % (tk[0],tk[1],tk[2]) )
print (tk)
# -----output-----
('永和', 0, 2)
('服装', 2, 4)
('饰品', 4, 6)
('有限公司', 6, 10)
四,添加自定义词典
开发者可以指定自己自定义的词典,以便包含 jieba 词库里没有的词。虽然 jieba有新词识别能力,但是自行添加新词可以保证更高的正确率。
1,添加词典用法:
jieba.load_userdict(dict_path) # dict_path为文件类对象或自定义词典的路径。
2,其中自定义字典举例如下:
一个词占一行;每一行分三部分:词语、词频(可省略)、词性(可省略),用空格隔开,顺序不可颠倒。
创新办 3 i 云计算 5 凱特琳 nz 中信建投 投资公司
3,使用自定义词典示例:
1)使用自定义词典文件
import jieba
test_sent = "中信建投投资公司投资了一款游戏,中信也投资了一个游戏公司"
jieba.load_userdict("userdict.txt")
words = jieba.cut(test_sent)
print(list(words))
#-----output------
['中信建投', '投资公司', '投资', '了', '一款', '游戏', ',', '中信', '也', '投资', '了', '一个', '游戏', '公司']
2)使用 jieba 在程序中动态修改词典
import jieba
# 定义示例句子
test_sent = "中信建投投资公司投资了一款游戏,中信也投资了一个游戏公司"
#添加词
jieba.add_word('中信建投')
jieba.add_word('投资公司')
# 删除词
jieba.del_word('中信建投')
words = jieba.cut(test_sent)
print(list(words))
#-----output------
['中信', '建投', '投资公司', '投资', '了', '一款', '游戏', ',', '中信', '也', '投资', '了', '一个', '游戏', '公司']
五,关键词提取
1,基于TF-IDF算法的关键词提取
1)TF-IDF接口和示例
import jieba.analyse
- jieba.analyse.extract_tags(sentence, topK=20, withWeight=False,allowPOS=())
其中需要说明的是:- 1.sentence 为待提取的文本
- 2.topK 为返回几个 TF/IDF 权重最大的关键词,默认值为 20
- 3.withWeight 为是否一并返回关键词权重值,默认值为 False
- 4.allowPOS 仅包括指定词性的词,默认值为空,即不筛选
- jieba.analyse.TFIDF(idf_path=None) 新建 TFIDF 实例,idf_path 为 IDF 频率文件
import jieba
import jieba.analyse
#读取文件,返回一个字符串,使用utf-8编码方式读取,该文档位于此python同以及目录下
content = open('data.txt','r',encoding='utf-8').read()
tags = jieba.analyse.extract_tags(content,topK=10,withWeight=True,allowPOS=("nr"))
print(tags)
# ----output-------
[('虚竹', 0.20382572423643955), ('丐帮', 0.07839419568792882), ('什么', 0.07287469641815765), ('自己', 0.05838617200768695), ('师父', 0.05459680087740782), ('内力', 0.05353758008018405), ('大理', 0.04885277765801372), ('咱们', 0.04458784837687502), ('星宿', 0.04412126568280158), ('少林', 0.04207588649463058)]
2)关键词提取所使用逆向文件频率(IDF)文本语料库可以切换成自定义语料库的路径
用法:jieba.analyse.set_idf_path(file_name) # file_name为自定义语料库的路径
自定义语料库示例:
劳动防护 13.900677652 勞動防護 13.900677652 生化学 13.900677652 生化學 13.900677652 奥萨贝尔 13.900677652 奧薩貝爾 13.900677652 考察队员 13.900677652 考察隊員 13.900677652 岗上 11.5027823792 崗上 11.5027823792 倒车档 12.2912397395 倒車檔 12.2912397395 编译 9.21854642485 編譯 9.21854642485 蝶泳 11.1926274509 外委 11.8212361103
3)关键词提取所使用停止词(Stop Words)文本语料库可以切换成自定义语料库的路径
- 用法: jieba.analyse.set_stop_words(file_name) # file_name为自定义语料库的路径
- 自定义语料库示例:
import jieba
import jieba.analyse
#读取文件,返回一个字符串,使用utf-8编码方式读取,该文档位于此python同以及目录下
content = open(u'data.txt','r',encoding='utf-8').read()
jieba.analyse.set_stop_words("stopwords.txt")
tags = jieba.analyse.extract_tags(content, topK=10)
print(",".join(tags))
4)关键词一并返回关键词权重值示例
import jieba
import jieba.analyse
#读取文件,返回一个字符串,使用utf-8编码方式读取,该文档位于此python同以及目录下
content = open(u'data.txt','r',encoding='utf-8').read()
jieba.analyse.set_stop_words("stopwords.txt")
tags = jieba.analyse.extract_tags(content, topK=10,withWeight=True)
print(tags)
2,词性标注
- jieba.posseg.POSTokenizer(tokenizer=None) 新建自定义分词器,tokenizer参数可指定内部使用的 jieba.Tokenizer 分词器。 jieba.posseg.dt 为默认词性标注分词器。
- 标注句子分词后每个词的词性,采用和 ictclas 兼容的标记法。
- 用法示例
import jieba.posseg as pseg
words = pseg.cut("我爱北京天安门")
for word, flag in words:
print('%s %s' % (word, flag))
# ----output--------
我 r
爱 v
北京 ns
天安门 ns
词性对照表
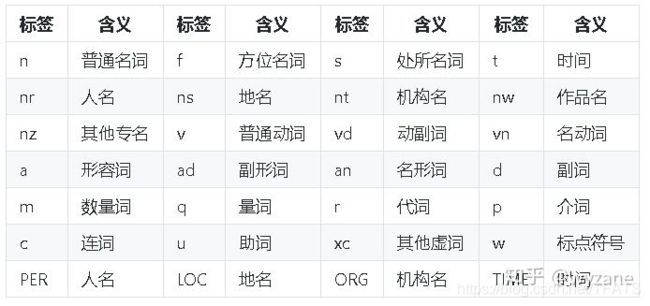
3,并行分词
将目标文本按行分隔后,把各行文本分配到多个 Python 进程并行分词,然后归并结果,从而获得分词速度的可观提升。用法:
- jieba.enable_parallel(4):开启并行分词模式,参数为并行进程数
- jieba.disable_parallel() :关闭并行分词模式
可参考 test_file.py
注意:基于 python 自带的 multiprocessing 模块,目前暂不支持 Windows
4,Tokenize:返回词语在原文的起止位置
1)默认模式
注意,输入参数只接受 unicode
import jieba
import jieba.analyse
result = jieba.tokenize(u'永和服装饰品有限公司')
for tk in result:
print("word %s\t\t start: %d \t\t end:%d" % (tk[0],tk[1],tk[2]))
# ----output-------
word 永和 start: 0 end:2
word 服装 start: 2 end:4
word 饰品 start: 4 end:6
word 有限公司 start: 6 end:10
2)搜索模式
import jieba
import jieba.analyse
result = jieba.tokenize(u'永和服装饰品有限公司', mode='search')
for tk in result:
print("word %s\t\t start: %d \t\t end:%d" % (tk[0],tk[1],tk[2]))
# ----output-------
word 永和 start: 0 end:2
word 服装 start: 2 end:4
word 饰品 start: 4 end:6
word 有限 start: 6 end:8
word 公司 start: 8 end:10
word 有限公司 start: 6 end:10
5,搜索引擎ChineseAnalyzer for Whoosh
使用 jieba 和 whoosh 可以实现搜索引擎功能。
whoosh 是由python实现的一款全文搜索工具包,可以使用 pip 安装它:
pip install whoosh
介绍 jieba + whoosh 实现搜索之前,你可以先看下文 whoosh 的简单介绍。
下面看一个简单的搜索引擎的例子:
import os
import shutil
from whoosh.fields import *
from whoosh.index import create_in
from whoosh.qparser import QueryParser
from jieba.analyse import ChineseAnalyzer
analyzer = ChineseAnalyzer()
schema = Schema(title=TEXT(stored=True),
path=ID(stored=True),
content=TEXT(stored=True,
analyzer=analyzer))
if not os.path.exists("test"):
os.mkdir("test")
else:
# 递归删除目录
shutil.rmtree("test")
os.mkdir("test")
idx = create_in("test", schema)
writer = idx.writer()
writer.add_document(
title=u"document1",
path="/tmp1",
content=u"Tracy McGrady is a famous basketball player, the elegant basketball style of him attract me")
writer.add_document(
title=u"document2",
path="/tmp2",
content=u"Kobe Bryant is a famous basketball player too , the tenacious spirit of him also attract me")
writer.add_document(
title=u"document3",
path="/tmp3",
content=u"LeBron James is the player i do not like")
writer.commit()
searcher = idx.searcher()
parser = QueryParser("content", schema=idx.schema)
for keyword in ("basketball", "elegant"):
print("searched keyword ",keyword)
query= parser.parse(keyword)
print(query,'------')
results = searcher.search(query)
for hit in results:
print(hit.highlights("content"))
print("="*50)
六,延迟加载
ieba 采用延迟加载,import jieba 和 jieba.Tokenizer() 不会立即触发词典的加载,一旦有必要才开始加载词典构建前缀字典。如果你想手工初始 jieba,也可以手动初始化。
import jieba jieba.initialize() # 手动初始化(可选)
上面代码中,使用 add_document() 把一个文档添加到了 index 中。在这些文档中,搜索含有 “basketball”和 “elegant” 的文档。
七,其他词典
1,占用内存较小的词典文件 https://github.com/fxsjy/jieba/raw/master/extra_dict/dict.txt.small
2,支持繁体分词更好的词典文件 https://github.com/fxsjy/jieba/raw/master/extra_dict/dict.txt.big
下载你所需要的词典,然后覆盖 jieba/dict.txt 即可;或者用
jieba.set_dictionary('data/dict.txt.big')
更多关于Python中文分词的文章请查看下面的相关链接