k8s教程说明
prometheus全组件的教程
- 01_prometheus全组件配置使用、底层原理解析、高可用实战
- 02_prometheus-thanos使用和源码解读
- 03_kube-prometheus和prometheus-operator实战和原理介绍
- 04_prometheus源码讲解和二次开发
go语言课程
告警的ql
histogram_quantile(0.99, sum(rate(scheduler_e2e_scheduling_duration_seconds_bucket{job="kube-scheduler"}[5m])) without(instance, pod)) > 3 for 1m含义:调度耗时超过3秒
追踪这个 histogram的metrics
- 代码版本 v1.20
- 位置 D:\go_path\src\github.com\kubernetes\kubernetes\pkg\scheduler\metrics\metrics.go
- 追踪调用方,在observeScheduleAttemptAndLatency的封装中,位置 D:\go_path\src\github.com\kubernetes\kubernetes\pkg\scheduler\metrics\profile_metrics.go
- 这里可看到 调度的三种结果都会记录相关的耗时

追踪调用方
- 位置 D:\go_path\src\github.com\kubernetes\kubernetes\pkg\scheduler\scheduler.go + 608
- 在函数 Scheduler.scheduleOne中,用来记录调度每个pod的耗时
- 可以看到具体的调用点,在异步bind函数的底部
由此得出结论 e2e 是统计整个scheduleOne的耗时
go func() { err := sched.bind(bindingCycleCtx, fwk, assumedPod, scheduleResult.SuggestedHost, state) if err != nil { metrics.PodScheduleError(fwk.ProfileName(), metrics.SinceInSeconds(start)) // trigger un-reserve plugins to clean up state associated with the reserved Pod fwk.RunReservePluginsUnreserve(bindingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost) if err := sched.SchedulerCache.ForgetPod(assumedPod); err != nil { klog.Errorf("scheduler cache ForgetPod failed: %v", err) } sched.recordSchedulingFailure(fwk, assumedPodInfo, fmt.Errorf("binding rejected: %w", err), SchedulerError, "") } else { // Calculating nodeResourceString can be heavy. Avoid it if klog verbosity is below 2. if klog.V(2).Enabled() { klog.InfoS("Successfully bound pod to node", "pod", klog.KObj(pod), "node", scheduleResult.SuggestedHost, "evaluatedNodes", scheduleResult.EvaluatedNodes, "feasibleNodes", scheduleResult.FeasibleNodes) } metrics.PodScheduled(fwk.ProfileName(), metrics.SinceInSeconds(start)) metrics.PodSchedulingAttempts.Observe(float64(podInfo.Attempts)) metrics.PodSchedulingDuration.WithLabelValues(getAttemptsLabel(podInfo)).Observe(metrics.SinceInSeconds(podInfo.InitialAttemptTimestamp)) // Run "postbind" plugins. fwk.RunPostBindPlugins(bindingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost) } }
scheduleOne从上到下都包含哪几个过程
01 调度算法耗时
实例代码
// 调用调度算法给出结果 scheduleResult, err := sched.Algorithm.Schedule(schedulingCycleCtx, fwk, state, pod) // 处理错误 if err != nil{} // 记录调度算法耗时 metrics.SchedulingAlgorithmLatency.Observe(metrics.SinceInSeconds(start }))从上面可以看出主要分3个步骤
- 调用调度算法给出结果
- 处理错误
- 记录调度算法耗时
那么我们首先应该 算法的耗时,对应的histogram metrics为
histogram_quantile(0.99, sum(rate(scheduler_scheduling_algorithm_duration_seconds_bucket{job="kube-scheduler"}[5m])) by (le))- 将e2e和algorithm 99分位耗时再结合 告警时间的曲线发现吻合度较高
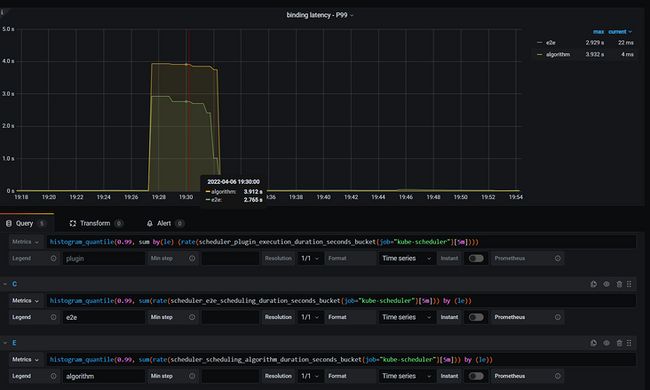
- 但是发现99分位下 algorithm > e2e ,但是按照e2e作为兜底来看,应该是e2e要更高,所以调整999分位发现2者差不多
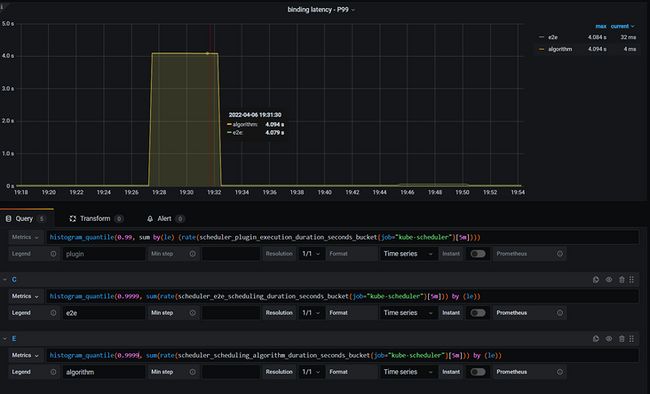
- 造成上述问题的原因跟prometheus histogram线性插值法的误差有关系,具体可以看我的文章 histogram线性插值法原理
Algorithm.Schedule具体流程
在Schedule中可以看到两个主要的函数调用
feasibleNodes, filteredNodesStatuses, err := g.findNodesThatFitPod(ctx, fwk, state, pod) priorityList, err := g.prioritizeNodes(ctx, fwk, state, pod, feasibleNodes)其中 findNodesThatFitPod 对应的是filter流程,对应的metrics有 scheduler_framework_extension_point_duration_seconds_bucket
histogram_quantile(0.999, sum by(extension_point,le) (rate(scheduler_framework_extension_point_duration_seconds_bucket{job="kube-scheduler"}[5m])))- 相关的截图可以看到

prioritizeNodes对应的是score流程,对应的metrics有
histogram_quantile(0.99, sum by(plugin,le) (rate(scheduler_plugin_execution_duration_seconds_bucket{job="kube-scheduler"}[5m])))- 相关的截图可以看到
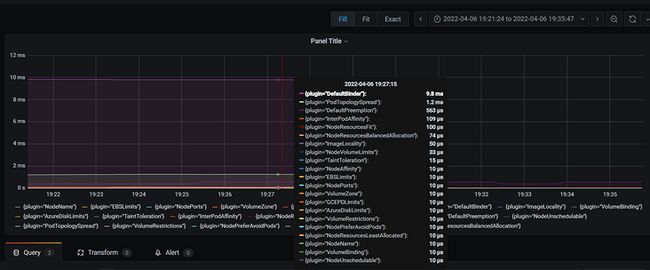
- 上述具体的算法流程可以和官方文档给出的流程图对得上

02 调度算法耗时
- 再回过头来看bind的过程
其中的核心就在bind这里
err := sched.bind(bindingCycleCtx, fwk, assumedPod, scheduleResult.SuggestedHost, state)可以看到在bind函数内部是单独计时的
func (sched *Scheduler) bind(ctx context.Context, fwk framework.Framework, assumed *v1.Pod, targetNode string, state *framework.CycleState) (err error) { start := time.Now() defer func() { sched.finishBinding(fwk, assumed, targetNode, start, err) }() bound, err := sched.extendersBinding(assumed, targetNode) if bound { return err } bindStatus := fwk.RunBindPlugins(ctx, state, assumed, targetNode) if bindStatus.IsSuccess() { return nil } if bindStatus.Code() == framework.Error { return bindStatus.AsError() } return fmt.Errorf("bind status: %s, %v", bindStatus.Code().String(), bindStatus.Message()) }对应的metric为
histogram_quantile(0.999, sum by(le) (rate(scheduler_binding_duration_seconds_bucket{job="kube-scheduler"}[5m])))- 这里我们对比e2e和bind的999分位值

- 发现相比于alg,bind和e2e吻合度更高
- 同时发现bind内部主要两个流程 sched.extendersBinding执行外部binding插件
- fwk.RunBindPlugins 执行内部的绑定插件
内部绑定插件
代码如下,主要流程就是执行绑定插件
// RunBindPlugins runs the set of configured bind plugins until one returns a non `Skip` status. func (f *frameworkImpl) RunBindPlugins(ctx context.Context, state *framework.CycleState, pod *v1.Pod, nodeName string) (status *framework.Status) { startTime := time.Now() defer func() { metrics.FrameworkExtensionPointDuration.WithLabelValues(bind, status.Code().String(), f.profileName).Observe(metrics.SinceInSeconds(startTime)) }() if len(f.bindPlugins) == 0 { return framework.NewStatus(framework.Skip, "") } for _, bp := range f.bindPlugins { status = f.runBindPlugin(ctx, bp, state, pod, nodeName) if status != nil && status.Code() == framework.Skip { continue } if !status.IsSuccess() { err := status.AsError() klog.ErrorS(err, "Failed running Bind plugin", "plugin", bp.Name(), "pod", klog.KObj(pod)) return framework.AsStatus(fmt.Errorf("running Bind plugin %q: %w", bp.Name(), err)) } return status } return status }那么默认的绑定插件为调用 pod的bind方法绑定到指定的node上,binding是pods的子资源
// Bind binds pods to nodes using the k8s client. func (b DefaultBinder) Bind(ctx context.Context, state *framework.CycleState, p *v1.Pod, nodeName string) *framework.Status { klog.V(3).Infof("Attempting to bind %v/%v to %v", p.Namespace, p.Name, nodeName) binding := &v1.Binding{ ObjectMeta: metav1.ObjectMeta{Namespace: p.Namespace, Name: p.Name, UID: p.UID}, Target: v1.ObjectReference{Kind: "Node", Name: nodeName}, } err := b.handle.ClientSet().CoreV1().Pods(binding.Namespace).Bind(ctx, binding, metav1.CreateOptions{}) if err != nil { return framework.AsStatus(err) } return nil }执行绑定动作也有相关的metrics统计耗时,
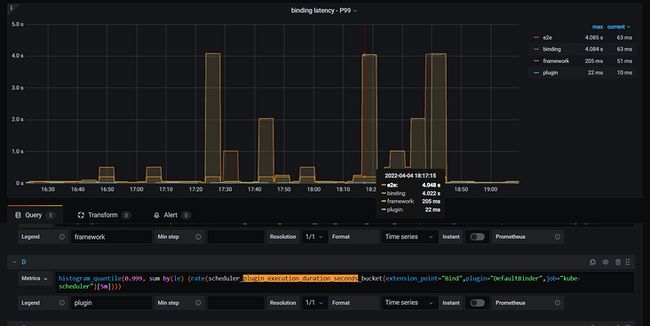
histogram_quantile(0.999, sum by(le) (rate(scheduler_plugin_execution_duration_seconds_bucket{extension_point="Bind",plugin="DefaultBinder",job="kube-scheduler"}[5m])))同时在 RunBindPlugins中也有defer func负责统计耗时
histogram_quantile(0.9999, sum by(le) (rate(scheduler_framework_extension_point_duration_seconds_bucket{extension_point="Bind",job="kube-scheduler"}[5m])))- 从上面两个metrics看,内部的插件耗时都很低
extendersBinding 外部插件
代码如下,遍历Algorithm的Extenders,判断是bind类型的,然后执行extender.Bind
// TODO(#87159): Move this to a Plugin. func (sched *Scheduler) extendersBinding(pod *v1.Pod, node string) (bool, error) { for _, extender := range sched.Algorithm.Extenders() { if !extender.IsBinder() || !extender.IsInterested(pod) { continue } return true, extender.Bind(&v1.Binding{ ObjectMeta: metav1.ObjectMeta{Namespace: pod.Namespace, Name: pod.Name, UID: pod.UID}, Target: v1.ObjectReference{Kind: "Node", Name: node}, }) } return false, nil }extender.Bind对应就是通过http发往外部的 调度器
// Bind delegates the action of binding a pod to a node to the extender. func (h *HTTPExtender) Bind(binding *v1.Binding) error { var result extenderv1.ExtenderBindingResult if !h.IsBinder() { // This shouldn't happen as this extender wouldn't have become a Binder. return fmt.Errorf("unexpected empty bindVerb in extender") } req := &extenderv1.ExtenderBindingArgs{ PodName: binding.Name, PodNamespace: binding.Namespace, PodUID: binding.UID, Node: binding.Target.Name, } if err := h.send(h.bindVerb, req, &result); err != nil { return err } if result.Error != "" { return fmt.Errorf(result.Error) } return nil }- 很遗憾的是这里并没有相关的metrics统计耗时
- 目前猜测遍历 sched.Algorithm.Extenders 执行的耗时
- 这里sched.Algorithm.Extenders来自于 KubeSchedulerConfiguration 中的配置
- 也就是编写配置文件,并将其路径传给 kube-scheduler 的命令行参数,定制 kube-scheduler 的行为,目前并没有看到
总结
scheduler 调度过程
单个pod的调度主要分为3个步骤:
- 根据Predict和Priority两个阶段,调用各自的算法插件,选择最优的Node
- Assume这个Pod被调度到对应的Node,保存到cache
- 用extender和plugins进行验证,如果通过则绑定
e2e 耗时主要来自bind
- 但目前看到bind执行耗时并没有很长
- 待续