Flink原理解析
1.Flink是什么
Flink是新一代分布式流式计算引擎,用于对海量数据进行实时处理和计算,具备快速容错(支持每条消息恰好处理一次)、流批一体、低延时、支持数据乱序的特点。
Flink的主要应用场景如下:
- 数据分析场景:流式计算平台相对于传统的基于批的计算平台具备最大优点就是实时性,典型的应用场景就是淘宝的双十一大屏和一些实时性要求比较高的数据看班
- 事件驱动场景:相比于MetaQ或其他消息队列,Flink可以基于Flink Sql或者其他API进行一些复杂的计算或者过滤操作,比如基于用户行为触发风控报警等
- ETL场景:这个比较容易理解,相对于传统的ETL工具,blink更为灵活
2.设计原理
容错机制
分布式环境下的流式处理平台相对于批处理平台而言,一个非常重要的问题是如何保证分布式计算节点在发生故障并恢复后最终的计算结果是正确的。在批处理的模式下,数据有界,在任务开始前我们就可以得到需要计算的所有数据,如果节点出错,最坏的情况下只需要对数据集进行重新计算,但在流式处理模式下,数据是源源不断产生并且无界的,节点故障恢复后无法从头开始重新计算。
分布式快照
在网络服务中,快照是比较常用的一个容错机制,比如Redis中就有基于RDB进行数据恢复的策略,flink的快速容错机制也是基于快照的方式实现的。在单机环境下,保存快照比较简单,只需要在某个时间点暂停任务处理并将当前状态持久化即可,但在分布式系统中,由于没有一个全局时钟,想要同时对所有计算节点的状态进行保存是很难做到的(要详细了解可以参考附录:分布式系统中的时钟)。最简单的实现方式是通过类似2PC的方式将所有节点任务都停止并进行状态保存,最后统一上报,但这这种stop the world的方式会极大的增加计算延时和降低吞吐量。flink最终的解决方案是基于Chandy-Lamport算法改进而来的Asynchronous Barrier Snapshotting(异步屏障快照)算法
Chandy-Lamport
chandy-lamport算法的核心思想是将分布式系统抽象为一个有向图,每个分布式节点作为顶点,节点与节点之间的通信信道被抽象为图的有向边(input channel,output channel),在发起快照时,每个节点会记录自身状态和input channel的状态,最终可以得到一个全局一致的快照,下面用一个例子详细解释。
如下图所示,一个分布式系统中有两个节点P1和P2,两个节点分别有X,Y,Z三个状态,通过C12和C21两个信道可以互相发送消息
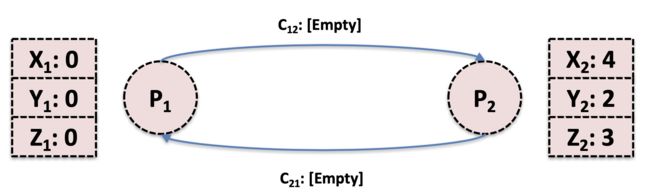
首先P1发起了一个快照操作(同时可以上报到一个全局的快照协调系统),他会先保存自身状态[X1:0,Y1:0,Z1:0],并向下游发送一个特殊消息marker,用于通知下游节点也进行快照操作,与此同时,P2通过C21向P1发送了一条业务消息

此时由于P1已经完成了快照,在P2节点未完成快照之前不可以进行消息处理,否则最后生成的全局快照会不一致,此时需要将它的输入信道C21中的所有消息(目前只有M1)也追加到快照中,与此同时P2接收到了P1过来的marker信息,同样进行了快照操作

最后P1接收到来自P2的marker信息,此时两个节点快照都保存完毕(同样可以上报到一个全局的快照协调系统,告知快照操作结束),可以认为全局快照生成成功

可以看到整体的算法还是比较简单易懂的,但要注意的是,此算法要求网络的传输是有序的,可靠的(很容易就会想到TCP协议),需要严格保证消息和marker是按发送顺序到达其他节点。
Asynchronous Barrier Snapshotting
Chandy-Lamport虽然理解起来不复杂,但存在两个比较大的问题。1是在进行快照时节点不仅需要保存自身状态,还要保存所有input channer中的消息,这会导致快照体积比较大,并且基于快照进行恢复时效率低,2是整个系统的运行效率取决于最慢的计算节点。flink基于Chandy-Lamport算法进行了改进,它的核心思想如下
每当需要生成全局快照时,流的source在产生的消息是插入一个带ID的特殊信息,称之为barrier(屏障),同时source会向快照协调者上报快照生成操作已启动,并记录自身offset(用于故障回复之后流的重放),这些屏障会将整个数据流切分为不同的数据集,当下游的处理节点处理到屏障时会在本地保存一份快照,并向更下游广播带有相同ID的屏障,最终当sink(流的输出端)也处理到屏障时,向协调者上报快照生成成功,还是以一个例子进行说明

如图所示,上游节点的快照已保存成功并且向图中的task节点输出了两个数据流,由于数据流1的处理速度较快,它的屏障N先到达了图中的task处,此时节点需要暂时停止处理数据流1的消息并将消息保存在本地缓冲中,等到数据流2的屏障N也到达task时,task会先保存本地状态(快照)同时向下游广播屏障N,这个操作被称之为屏障的对齐,最终sink(输出)也进行屏障对齐之后,会向快照协调者上报全局快照生成成功,此时整个分布式系统,包括图中的task节点和上游的节点保存的快照是一致的,即只包含对于屏障N之前的消息的处理状态,如果发生故障,各节点快照中读取状态,同时source屏障N的Offset处进行消息回放即可
Asynchronous Barrier Snapshotting算法解决了需要保存额外消息的问题,但和Chandy-Lamport算法一样,会导致整个分布式系统的计算效率受限于整个系统中最慢的节点(需要进行屏障对齐),所以Blink/Flink支持关闭屏障对齐,在这种模式下,如果数据流1的屏障先到达,task还是会继续处理数据流1的后续数据,只是在数据流2的屏障到达时,会将两个时间段内处理的消息一起保存在快照中。在Blink中,快照被称为Check Point
批处理和支持乱序
Flink中的时间和窗口
在Flink中,通过将批看作是有界的流实现了对批数据的处理(spark刚好相反,它将流看作是微形的批实现了流处理),而时间是用于将流转换为批的重要工具,在实时计算应用中有很多基于时间的计算场景,比如每隔一分钟统计最近五分钟内买家发消息数量等。在blink中,我们可以使用的时间有三种:
- Event Time(事件时间):表示事件在产生它的设备上发生的时间,在进入Blink计算平台时就已确定且不可修改,不受进入Blink的延时和不同计算节点的机器时间和计算效率的影响。它能准确反映事件发生的先后顺序。
- Process Time(处理时间):每个计算节点对事件进行处理的时间,因为每个节点所处的环境,性能的差异,在计算某个时间段内的数据时,计算结果是不稳定的。它反映的是事件在Blink中的处理先后顺序。
- Ingestion time(事件进入事件):指事件进入Blink的时间,在Source处产生,与Process Time相比它不受计算节点的环境影响,在事件进入Blink时就已确定。它反映的是事件进入Blink的先后顺序。
基于这三种时间,Flink为我们提供了以下时间窗口(暂时不讲CountWindow):
- 固定窗口:按固定时间点拆分的窗口,比如统计一天的数据
- 滑动窗口:按窗口大小和滑动周期定义,比如上面说到的每隔一分钟统计最近五分钟买家发消息数
- 会话窗口:在数据子集上捕捉一段时间内的活动,比如按超时时间定义。举个例子,用户登录30分钟无事件为超时,计算每次登录的发消息数
处理乱序数据
前面提到,Blink支持三种时间,其中在使用Ingestion time(事件进入时间)和EventTime(事件事件)进行计算时都可能会发生数据乱序的问题,即由于各节点所处的网络环境,硬件性能等,事件实际计算时间的先后顺序和事件实际发生或进入Blink时间的先后顺序可能是不一致的。
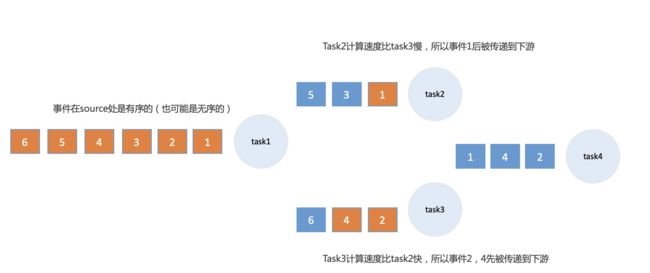
如图所示,图中的数字表示时间,对流数据按时间的奇偶进行了分组计算,在进行一次并行计算之后,由于不同节点计算速度不同,原本的顺序的数据在task4处也可能变为乱序。而在处理乱序数据时,基于窗口的计算结果很可能是错误的。原因是在数据流乱序的情况下,节点无法确认在时间窗口结束时是否还会有原本位于时间窗口内的数据到来。

如图所示,Flink无法确认在事件4到达之后是否还会有更早的事件到来,为了解决这个问题,Flink引入了Water Mark(水位线机制),简单来讲,Water Mark定义了Flink在数据乱序的情况下,是否需要等待更早的数据以及需要等待多久的问题,以上图的场景为例,节点可以选择在窗口时间结束之后等待一段时间再触发窗口计算,一定程度上防止更早数据未被处理。当然,水位线的选择必须要谨慎,如果等待的时间过长,遗漏更早事件的可能性虽然会减少,但需要缓存的事件和等待时间会增加,会导致延时和吞吐量降低,如果等待的时间过短,遗漏掉更早事件的概率可能更大。但无论如何,数据的遗漏是无法避免的,Blink把窗口计算结束后到来的,早于水位线的事件称为迟到事件,我们可以对迟到数据进行单独处理,Blink提供了如下三种策略:
- 重新激活已关闭的窗口并进行重新计算修正结果
- 将迟到事件收集起来单读处理
- 丢弃迟到事件
Flink默认处理方式为【丢弃迟到事件】
3.技术架构
在了解到Flink的两个核心原理之后,最后介绍一下整体的技术架构。Flink整体是基于主从模式,JobManager相当于Master,TaskManager是Slave。计算任务(基于StreamAPI或者其他API开发的代码)在客户端转化为JobGraph(多节点chain为一个节点,减少不同节点之间数据流动带来的性能损耗)后会提交到JobManager,JobManager将其转化为可执行的Execution Graph(主要是对JobGraph进行了并行化操作),最终通过Resource Manager将具体的执行任务调度到TaskManager上去执行。JobManager还负责触发checkPoint(就是前面说到的全局快照)

当然,这种模式下JobManager会存在单点问题,flink提供了两种高可用模式,第一种是Standalone,在这种模式下同时会启动多个JobManager并通过Zookeeper选举出一个Master,当JobManager发生故障时,会选举出新的Master。第二种是基于Yarn的模式,启动一个JobManger,当发生故障时会自动进行重启