Kafka中消费者Consumer消息读取流程源码解析
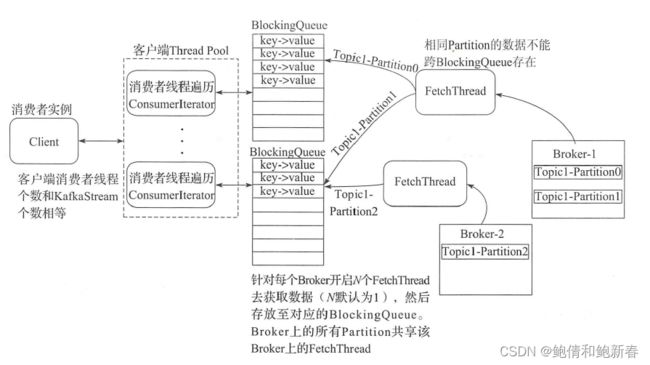
Kafka的消费者consumer是通过遍历KafkaStream的迭代器ConsumerIterator来消费消息的,其数据来源是分配给给KafkaStream的阻塞消息队列BlockingQueue,而BlockingQueue中的消息数据来自于针对每个Broker Server的FetchThread线程。FetchThread线程会将Broker Server上的部分partition数据发送给对应的阻塞消息队列BlockingQueue。其具体流程如下:
其中类kafka.consumer.ZookeeperConsumerConnector提供了所有的功能,具体的代码如下:
private[kafka] class ZookeeperConsumerConnector(
val config: ConsumerConfig,
val enableFetcher: Boolean) extends ConsumerConnector with Logging with KafkaMetricsGroup {
/*
*创建消息消费的数据流,topicCountMap告诉Kafka我们在Consumer中将用多少个线程来消费该topic。topicCountMap的key是topic name,value针对该topic是线程的数量
*/
def createMessageStreams[K,V](topicCountMap: Map[String,Int], keyDecoder: Decoder[K], valueDecoder: Decoder[V])
: Map[String, List[KafkaStream[K,V]]] = {
consume(topicCountMap, keyDecoder, valueDecoder)
}
def consume[K, V](
topicCountMap: scala.collection.Map[String,Int],
keyDecoder: Decoder[K],
valueDecoder: Decoder[V])
: Map[String,List[KafkaStream[K,V]]] = {
debug("entering consume ")
if (topicCountMap == null)
throw new RuntimeException("topicCountMap is null")
val topicCount = TopicCount.constructTopicCount(consumerIdString, topicCountMap)
val topicThreadIds = topicCount.getConsumerThreadIdsPerTopic
// make a list of (queue,stream) pairs, one pair for each threadId
val queuesAndStreams = topicThreadIds.values.map(threadIdSet =>
threadIdSet.map(_ => {
val queue = new LinkedBlockingQueue[FetchedDataChunk](config.queuedMaxMessages)
val stream = new KafkaStream[K,V](
queue, config.consumerTimeoutMs, keyDecoder, valueDecoder, config.clientId)
(queue, stream)
})
).flatten.toList
val dirs = new ZKGroupDirs(config.groupId)
registerConsumerInZK(dirs, consumerIdString, topicCount)
reinitializeConsumer(topicCount, queuesAndStreams)
loadBalancerListener.kafkaMessageAndMetadataStreams.asInstanceOf[Map[String, List[KafkaStream[K,V]]]]
}
}接下来主要讲解4个部分:
(1)、ConsumerThread和Partition的分配算法
(2)、FetchThread的启动过程
(3)、KafkaStream如何遍历BlockingQueue
(4)、KafkaStream的负载均衡流程
ConsumerThread和Partition的分配算法
ConsumerThread本质上就是客户端的消费线程,每一个消费者线程消费若干个Partition上的数据或者没有消费数据,并且ConsumerThread和BlockingQueue相互之间一一对应,只要确定了ConsumerThread和partition的对应关系,就确定了BlockingQueue和partition的对应关系。
kafka提供了两种ConsumerThread和partition的分配算法,分别为Range(范围分区分配)和RoundRobin(循环分区分配),分配算法由参数partition.assignment.strategy决定,默认为range
ConsumerFetchThread
一旦当前消费者实例的ConsumerThread和partition的关系确定以后,就需要启动ConsumerFetchThread消费Broker Server上的消息,ConsumerFetchThread会将获取到的partition数据转发至对应的BlockingQueue供ConsumerThread消费。
在消费消息前,客户端需要提前知道各个Partition的Leader Replica所在的Broker Server,因此需要发送TopicMetadataRequest询问Kafka集群相关Topic的元数据,这部分工作是由线程LeaderFinderThread完成的,该线程负责寻找Partition的Leader Replica所在的Broker Server,一旦找到后,就会向对应的ConsumerFetchThread下发拉取该Partition消息的命令。
在Kafka中,类ConsumerFetchManager负责对ConsumerFetchThread线程进行管理。
1、ConsumerFetchThread的启动
ConsumerFetchManager在启动时会创建线程LeaderFinderThread,其中ConsumerFetchManager内部的noLeaderPartitionSet保存了Leader Replica还没有明确的TopicAndPartition,LeaderFinderThread从noLeaderPartitionSet中获取对应的TopicAndPartition,然后遍历Broker Server发送元数据获取请求。具体代码如下:
private class LeaderFinderThread(name: String) extends ShutdownableThread(name) {
override def doWork() {
//保存TopicAndPartition的Leader Replica所在的Broker Server
val leaderForPartitionsMap = new HashMap[TopicAndPartition, Broker]
lock.lock()
try {
//如果当前没有待获取的,则等待
while (noLeaderPartitionSet.isEmpty) {
trace("No partition for leader election.")
cond.await()
}
//从zookeeper中获取所有的brokers
val brokers = getAllBrokersInCluster(zkClient)
/*
* 遍历brokers 查找noLeaderPartitionSet中的topic元数据,如果没有找到就抛出异常
*/
val topicsMetadata = ClientUtils.fetchTopicMetadata(
noLeaderPartitionSet.map(m => m.topic).toSet,
brokers,
config.clientId,
config.socketTimeoutMs,
correlationId.getAndIncrement).topicsMetadata
//
topicsMetadata.foreach { tmd =>
val topic = tmd.topic
tmd.partitionsMetadata.foreach { pmd =>
val topicAndPartition = TopicAndPartition(topic, pmd.partitionId)
if(pmd.leader.isDefined && noLeaderPartitionSet.contains(topicAndPartition))
{
val leaderBroker = pmd.leader.get
//更新leaderForPartitionsMap
leaderForPartitionsMap.put(topicAndPartition, leaderBroker)
//剔除topicAndPartition
noLeaderPartitionSet -= topicAndPartition
}
}
}
} catch {
case t: Throwable => {
if (!isRunning.get())
throw t /* If this thread is stopped, propagate this exception to kill the thread. */
else
warn("Failed to find leader for %s".format(noLeaderPartitionSet), t)
}
} finally {
lock.unlock()
}
try {
//将topicAndPartition添加至对应的ConsumerFetchThread,如果不存在,则创建
addFetcherForPartitions(leaderForPartitionsMap.map{
case (topicAndPartition, broker) =>
topicAndPartition -> BrokerAndInitialOffset(broker, partitionMap(topicAndPartition).getFetchOffset())}
)
} catch {
case t: Throwable => {
if (!isRunning.get())
throw t /* If this thread is stopped, propagate this exception to kill the thread. */
else {
warn("Failed to add leader for partitions %s; will retry".format(leaderForPartitionsMap.keySet.mkString(",")), t)
lock.lock()
noLeaderPartitionSet ++= leaderForPartitionsMap.keySet
lock.unlock()
}
}
}
shutdownIdleFetcherThreads()
Thread.sleep(config.refreshLeaderBackoffMs)
}
}其中addFetcherForPartitions会负责启动ConsumerFetchThread,如果已经启动则会利用topicAndPartition和offset更新ConsumerFetchThread内部的partitionMap,partitionMap保存了topicAndPartition和对应的偏移量offset。
def addFetcherForPartitions(partitionAndOffsets: Map[TopicAndPartition, BrokerAndInitialOffset]) {
mapLock synchronized {
//将partitionAndOffsets按照BrokerAndFetcherId分组
val partitionsPerFetcher = partitionAndOffsets.groupBy{ case(topicAndPartition, brokerAndInitialOffset) =>
BrokerAndFetcherId(brokerAndInitialOffset.broker, getFetcherId(topicAndPartition.topic, topicAndPartition.partition))}
for ((brokerAndFetcherId, partitionAndOffsets) <- partitionsPerFetcher) {
var fetcherThread: AbstractFetcherThread = null
//fetcherThreadMap保存了brokerAndFetcherId和ConsumerFetchThread的映射关系
fetcherThreadMap.get(brokerAndFetcherId) match {
case Some(f) => fetcherThread = f
//如果不存在,则创建ConsumerFetcherThread
case None =>
fetcherThread = createFetcherThread(brokerAndFetcherId.fetcherId, brokerAndFetcherId.broker)
fetcherThreadMap.put(brokerAndFetcherId, fetcherThread)
fetcherThread.start
}
fetcherThreadMap(brokerAndFetcherId).addPartitions(partitionAndOffsets.map { case (topicAndPartition, brokerAndInitOffset) =>
topicAndPartition -> brokerAndInitOffset.initOffset
})
}
}
info("Added fetcher for partitions %s".format(partitionAndOffsets.map{ case (topicAndPartition, brokerAndInitialOffset) =>
"[" + topicAndPartition + ", initOffset " + brokerAndInitialOffset.initOffset + " to broker " + brokerAndInitialOffset.broker + "] "}))
}2、ConsumerFetcherThread的执行逻辑
ConsumerFetcherThread会遍历其内部的partitionMap,消费partitionMap中包含的TopicAndPartition,然后将消费的数据发送至BlockingQueue。
ConsumerFetcherThread继承自AbstractFetcherThread,AbstractFetcherThread内部的doWork流程负责提取partitionMap中的topicAndPartition和offset,向Broker Server发送FetchRequest请求,然后更新partitionMap中的offset。最后利用ConsumerFetcherThread的processPartittionData函数来处理获取到的分区数据。具体流程如下:
override def doWork() {
inLock(partitionMapLock) {
//如果partitionMap为空,则等待
if (partitionMap.isEmpty)
partitionMapCond.await(200L, TimeUnit.MILLISECONDS)
//遍历partitionMap,组装FetchRequest请求参数
partitionMap.foreach {
case((topicAndPartition, offset)) =>
fetchRequestBuilder.addFetch(topicAndPartition.topic, topicAndPartition.partition,
offset, fetchSize)
}
}
val fetchRequest = fetchRequestBuilder.build()
if (!fetchRequest.requestInfo.isEmpty)
//处理FetchRequest请求
processFetchRequest(fetchRequest)
}
private def processFetchRequest(fetchRequest: FetchRequest) {
val partitionsWithError = new mutable.HashSet[TopicAndPartition]
var response: FetchResponse = null
try {
//向Broker Server发送FetchRequest请求
response = simpleConsumer.fetch(fetchRequest)
} catch {
case t: Throwable =>
if (isRunning.get) {
partitionMapLock synchronized {
//发送异常,记录partitionsWithError
partitionsWithError ++= partitionMap.keys
}
}
}
//记录发送频率
fetcherStats.requestRate.mark()
if (response != null) {
// process fetched data
inLock(partitionMapLock) {
//遍历FetchResponse
response.data.foreach {
case(topicAndPartition, partitionData) =>
val (topic, partitionId) = topicAndPartition.asTuple
val currentOffset = partitionMap.get(topicAndPartition)
// 检验partitionMap中的偏移量和FetchRequest中的偏移量,一致则说明有效
if (currentOffset.isDefined && fetchRequest.requestInfo(topicAndPartition).offset == currentOffset.get) {
partitionData.error match {
//响应成功
case ErrorMapping.NoError =>
try {
//获取该topicAndPartition对应的ByteBufferMessageSet
val messages = partitionData.messages.asInstanceOf[ByteBufferMessageSet]
//获取ByteBufferMessageSet的有效的字节数
val validBytes = messages.validBytes
//获取ByteBufferMessageSet的有下一个偏移量
val newOffset = messages.shallowIterator.toSeq.lastOption match {
case Some(m: MessageAndOffset) => m.nextOffset
case None => currentOffset.get
}
//更新partitionMap
partitionMap.put(topicAndPartition, newOffset)
fetcherLagStats.getFetcherLagStats(topic, partitionId).lag = partitionData.hw - newOffset
fetcherStats.byteRate.mark(validBytes)
/* 调用ConsumerFetcherThread的processPartitionData流程,
* 本质上就是将partitionData发送至BlockingQueue
*/
processPartitionData(topicAndPartition, currentOffset.get, partitionData)
} catch {
......
}
case ErrorMapping.OffsetOutOfRangeCode =>
try {
//偏移量越界,重置偏移量
val newOffset = handleOffsetOutOfRange(topicAndPartition)
partitionMap.put(topicAndPartition, newOffset)
error("Current offset %d for partition [%s,%d] out of range; reset offset to %d"
.format(currentOffset.get, topic, partitionId, newOffset))
} catch {
case e: Throwable =>
error("Error getting offset for partition [%s,%d] to broker %d".format(topic, partitionId, sourceBroker.id), e)
partitionsWithError += topicAndPartition
}
case _ =>
if (isRunning.get) {
error("Error for partition [%s,%d] to broker %d:%s".format(topic, partitionId, sourceBroker.id,
ErrorMapping.exceptionFor(partitionData.error).getClass))
partitionsWithError += topicAndPartition
}
}
}
}
}
}ConsumerFetcherThread中的partitionMap参数保存了TopicAndPartition和PartitionTopicInfo的映射关系,PartitionTopicInfo中的chunkQueue参数指定了该TopicAndPartition对应的BlockingQueue。processPartitionData负责从PartitionTopicInfo中获取ChunkQueue,然后将消息集合放入ChunkQueue。其实现过程如下:
def processPartitionData(
topicAndPartition: TopicAndPartition,
fetchOffset: Long,
partitionData: FetchResponsePartitionData) {
//获取PartitionTopicInfo
val pti = partitionMap(topicAndPartition)
//校验前后的fetchOffset是否一致
if (pti.getFetchOffset != fetchOffset)
throw new RuntimeException("Offset doesn't match for partition [%s,%d] pti offset: %d fetch offset: %d"
.format(topicAndPartition.topic, topicAndPartition.partition, pti.getFetchOffset, fetchOffset))
/*
* 调用PartitionTopicInfo的enqueue函数
* 1)将消息写入BlockingQueue
* 2)更新PartitionTopicInfo中的fetchOffset
*/
pti.enqueue(partitionData.messages.asInstanceOf[ByteBufferMessageSet])
}可见BlockingQueue中的元素就是一定偏移量范围内的消息集合。