受到 由Stephen Toub 发布的关于 .NET 性能的博客的启发,我们正在写一篇类似的文章来强调ASP.NET Core 在6.0 中所做的性能改进。
基准设置
我们整个过程中大部分的实例使用的是BenchmarkDotNet。在https://github.com/BrennanConroy/BlogPost60Bench上提供了repo,其中包括本文中使用的大多数基准。
本文中的大多数基准测试结果都是通过以下命令行生成的:
dotnet run -c Release -f net48 --runtimes net48 netcoreapp3.1 net5.0 net6.0
然后从列表中选择要运行的特定基准。
这命令行给BenchmarkDotNet指令:
- 在发布配置中构建所有内容。
- 针对 .NET Framework 4.8 外围区域构建它。
- 在 .NET Framework 4.8、.NET Core 3.1、.NET 5 和 .NET 6 上运行每个基准测试。
- 对于某些基准测试,它们仅在 .NET 6 上运行(例如,如果比较同一版本上的编码的两种方式):
dotnet run -c Release-f net6.0--runtimes net6.0
对于其他人,只运行了版本的一个子集,例如dotnet run -c Release-f net5.0--runtimes net5.0 net6.0
我将包括用于运行每个基准测试的命令。
本文中的大多数结果都是在Windows上运行上述基准测试生成的,主要是为了将. NET Framework 4.8包含在结果集中。 但是,除非另有说明,一般来说,所有这些基准测试在Linux或macOS上运行时都显示出相当显著的改进。只需确保您已经安装了想要测量的每个运行时。这些基准测试使用的是.NET 6 RC1的构建,以及最新发布的.NET 5和.NET Core 3.1下载。
span< T >
自从在.NET 2.1中增加了Span< T >,之后的每一个版本我们都转换了更多的代码以在内部和作为公共API的一部分使用Span来提高性能。这次发布也不例外。
PR dotnet/aspnetcore#28855在添加两个 PathString 实例时删除了来自 string.SubString的 PathString 中的临时字符串分配,而是使用 Span\<char\> 作为临时字符串。在下面的基准测试中,我们使用一个短字符串和一个长字符串来显示避免使用临时字符串的性能差异。
dotnet run -c Release -f net48 --runtimes net48 net5.0 net6.0 --filter *PathStringBenchmark*
private PathString _first = new PathString("/first/");
private PathString _second = new PathString("/second/");
private PathString _long = new PathString("/longerpathstringtoshowsubstring/");
[Benchmark]
public PathString AddShortString()
{
return _first.Add(_second);
}
[Benchmark]
public PathString AddLongString()
{
return _first.Add(_long);
}| 方法 | 运行 | 工具链 | 平均分配 | 比率 | 已分配 |
|---|---|---|---|---|---|
| AddShortString | .NET Framework 4.8 | net48 | 23.51 ns | 1.00 | 96 B |
| AddShortString | .NET 5.0 | net5.0 | 22.73 ns | 0.97 | 96 B |
| AddShortString | .NET 6.0 | net6.0 | 14.92 ns | 0.64 | 56 B |
| AddLongString | .NET Framework 4.8 | net48 | 30.89 ns | 1.00 | 201 B |
| AddLongString | .NET 5.0 | net5.0 | 25.18 ns | 0.82 | 192 B |
| AddLongString | .NET 6.0 | net6.0 | 15.69 ns | 0.51 | 104 B |
dotnet/aspnetcore#34001引入了一个新的基于Span的API,用于枚举查询字符串,在没有编码字符的常见情况下,该查询字符串是分配空闲的,当查询字符串包含编码字符时,分配更低。
dotnet run -c Release -f net6.0 --runtimes net6.0 --filter *QueryEnumerableBenchmark*
#if NET6_0_OR_GREATER
public enum QueryEnum
{
Simple = 1,
Encoded,
}
[ParamsAllValues]
public QueryEnum QueryParam { get; set; }
private string SimpleQueryString = "?key1=value1&key2=value2";
private string QueryStringWithEncoding = "?key1=valu%20&key2=value%20";
[Benchmark(Baseline = true)]
public void QueryHelper()
{
var queryString = QueryParam == QueryEnum.Simple ? SimpleQueryString : QueryStringWithEncoding;
foreach (var queryParam in QueryHelpers.ParseQuery(queryString))
{
_ = queryParam.Key;
_ = queryParam.Value;
}
}
[Benchmark]
public void QueryEnumerable()
{
var queryString = QueryParam == QueryEnum.Simple ? SimpleQueryString : QueryStringWithEncoding;
foreach (var queryParam in new QueryStringEnumerable(queryString))
{
_ = queryParam.DecodeName();
_ = queryParam.DecodeValue();
}
}
#endif| 方法 | 查询参数 | 平均分配 | 比率 | 已分配 |
|---|---|---|---|---|
| QueryHelper | Simple | 243.13 ns | 1.00 | 360 B |
| QueryEnumerable | Simple | 91.43 ns | 0.38 | – |
| QueryHelper | Encoded | 351.25 ns | 1.00 | 432 B |
| QueryEnumerable | Encoded | 197.59 ns | 0.56 | 152 B |
需要注意的是,天下没有免费的午餐。在新的QueryStringEnumerable API的情况下,如果您计划多次枚举查询字符串值,它实际上可能比使用 QueryHelpers.ParseQuery 并存储已解析查询字符串值的字典更昂贵。
@paulomorgado的 dotnet/aspnetcore#29448使用 string.Create方法,如果您知道字符串的最终大小,则该方法允许在创建字符串后对其进行初始化。这是用来移除UriHelper.BuildAbsolute中的一些临时字符串分配。
dotnet run -c Release -f netcoreapp3.1 --runtimes netcoreapp3.1 net6.0 --filter *UriHelperBenchmark*
#if NETCOREAPP
[Benchmark]
public void BuildAbsolute()
{
_ = UriHelper.BuildAbsolute("https", new HostString("localhost"));
}
#endif| 方法 | 运行 | 工具链 | 平均分配 | 比率 | 已分配 |
|---|---|---|---|---|---|
| BuildAbsolute | .NET Core 3.1 | netcoreapp3.1 | 92.87 ns | 1.00 | 176 B |
| BuildAbsolute | .NET 6.0 | net6.0 | 52.88 ns | 0.57 | 64 B |
PR dotnet/aspnetcore#31267将 ContentDispositionHeaderValue 中的一些解析逻辑转换为使用基于 Span\<T\> 的 API,以避免在常见情况下出现临时字符串和临时 byte[]。
dotnet run -c Release -f net48 --runtimes net48 netcoreapp3.1 net5.0 net6.0 --filter *ContentDispositionBenchmark*
[Benchmark]
public void ParseContentDispositionHeader()
{
var contentDisposition = new ContentDispositionHeaderValue("inline");
contentDisposition.FileName = "FileÃName.bat";
}| 方法 | 运行 | 工具链 | 平均 | 比例 | 已分配 |
|---|---|---|---|---|---|
| ContentDispositionHeader | .NET Framework 4.8 | net48 | 654.9 ns | 1.00 | 570 B |
| ContentDispositionHeader | .NET Core 3.1 | netcoreapp3.1 | 581.5 ns | 0.89 | 536 B |
| ContentDispositionHeader | .NET 5.0 | net5.0 | 519.2 ns | 0.79 | 536 B |
| ContentDispositionHeader | .NET 6.0 | net6.0 | 295.4 ns | 0.45 | 312 B |
空闲连接
ASP.NET Core 的主要组件之一是托管服务器,它带来了许多不同的问题需要去优化。我们将重点关注6.0中空闲连接的改进,在其中我们做了许多更改,以减少连接等待数据时所使用的内存量。
我们进行了三种不同类型的更改,一种是减少连接使用的对象的大小,这包括System.IO.Pipelines、SocketConnections 和 SocketSenders。第二种类型的更改是将常用访问的对象池化,这样我们就可以重用旧实例并节省分配。第三种类型的改变是利用所谓的"零字节读取"。在这里,我们尝试用一个零字节缓冲区从连接中读取数据,如果有可用的数据,,读取将返回没有数据,但我们知道现在有可用的数据,可以提供一个缓冲区来立即读取该数据。这避免了为将来可能完成的读取预先分配一个缓冲区,所以在知道数据可用之前,我们可以避免大量的分配。
dotnet/runtime#49270将 System.IO.Pipelines 的大小从 ~560 字节减少到 ~368 字节,减少了34%,每个连接至少有2个管道,所以这是一个巨大的胜利。
dotnet/aspnetcore#31308重构了Kestrel的Socket层,以避免一些异步状态机,并减少剩余状态机的大小,从而为每个连接节省33%的分配。
dotnet/aspnetcore#30769删除了每个连接的PipeOptions分配,并将该分配移动到连接工厂,因此我们只分配一个服务器的整个生命周期,并为每个连接重用相同的选项。来自@benaadams的 dotnet/aspnetcore#31311将 WebSocket 请求中众所周知的标头值替换为内部字符串,这允许在头解析过程中分配的字符串被垃圾回收,减少了长期存在的WebSocket连接的内存使用。dotnet/aspnetcore#30771重构了 Kestrel 中的 Sockets 层,首先避免分配SocketReceiver对象+ SocketAwaitableEventArgs,并将其合并为单个对象,这节省了几个字节,并导致每个连接分配的对象较少。该 PR 还汇集了 SocketSender 类,因此您现在平均拥有多个核心 SocketSender,而不是为每个连接创建一个。因此,在下面的基准测试中,当我们有10,000个连接时,在我的机器上只分配了16个连接,而不是10,000个,这节省了~ 46mb !
另一个类似的大小变化是dotnet/runtime#49123,它增加了对SslStream中零字节读取的支持,这样我们的10,000个空闲连接从SslStream分配的~ 46mb到~2.3 MB。dotnet/runtime#49117在 StreamPipeReader 上添加了对零字节读取的支持,然后 Kestrel 在 dotnet/aspnetcore#30863中使用它开始在 SslStream 中使用零字节读取。
所有这些变化的最终结果是大量减少空闲连接的内存使用。
下面的数字不是来自于BenchmarkDotNet应用程序,因为它测量空闲连接,而且更容易用客户机和服务器应用程序进行设置。
控制台和 WebApplication 代码粘贴在以下要点中:
https://gist.github.com/BrennanConroy/02e8459d63305b4acaa0a021686f54c7
下面是10000个空闲的安全WebSocket连接(WSS)在不同框架上占用服务器的内存。
| 框架 | 内存 |
|---|---|
| net48 | 665.4 MB |
| net5.0 | 603.1 MB |
| net6.0 | 160.8 MB |
这比 net5 减少了近 4 倍的内存。
实体框架核心
EF Core在6.0版本中做了大量的改进,查询执行速度提高了31%,TechEmpower fortune的基准运行时间更新、优化基准和EF的改进提高了70%。
这些改进来自于对象池的改进,智能检查是否启用了遥测技术,以及添加一个选项,当你知道你的应用程序安全地使用DbContext时,可以选择退出线程安全检查。
请参阅发布实体框架核心6.0预览版4:性能版的博客文章,其中详细强调了许多改进。
Blazor
本机 byte[] 互操作
Blazor现在在执行JavaScript互操作时对字节数组有了有效的支持。以前,发送到和从JavaScript的字节数组是Base64编码的,因此它们可以被序列化为JSON,这增加了传输大小和CPU负载。Base64编码现在已经在.NET6中进行了优化,允许用户透明地使用.NET中的byte[]和JavaScript中的Uint8Array。说明如何将此特性用于JavaScript到.NET和.NET到JavaScript。
让我们看一个快速的基准测试,看看byte[]互操作在.NET 5和.NET 6中的区别。以下Razor代码创建了一个22 kB的字节[],并将其发送给JavaScript的receiveAndReturnBytes函数,该函数立即返回字节[]。这种数据往返重复了10,000次,时间数据被打印到屏幕上。这段代码对于.NET 5和.NET 6是相同的。
@Message
@code {
public string Message { get; set; } = "Press button to benchmark";
private async Task RoundtripData()
{
var bytes = new byte[1024*22];
List timeForInterop = new List();
var testTime = DateTime.Now;
for (var i = 0; i < 10_000; i++)
{
var interopTime = DateTime.Now;
var result = await JSRuntime.InvokeAsync("receiveAndReturnBytes", bytes);
timeForInterop.Add(DateTime.Now.Subtract(interopTime).TotalMilliseconds);
}
Message = $"Round-tripped: {bytes.Length / 1024d} kB 10,000 times and it took on average {timeForInterop.Average():F3}ms, and in total {DateTime.Now.Subtract(testTime).TotalMilliseconds:F1}ms";
}
} 接下来我们来看一下receiveAndReturnBytes JavaScript函数。在.NET 5。我们必须首先将Base64编码的字节数组解码为Uint8Array,以便它可以在应用程序代码中使用。然后,在将数据返回给服务器之前,我们必须将其重新编码为Base64。
function receiveAndReturnBytes(bytesReceivedBase64Encoded) {
const bytesReceived = base64ToArrayBuffer(bytesReceivedBase64Encoded);
// Use Uint8Array data in application
const bytesToSendBase64Encoded = base64EncodeByteArray(bytesReceived);
if (bytesReceivedBase64Encoded != bytesToSendBase64Encoded) {
throw new Error("Expected input/output to match.")
}
return bytesToSendBase64Encoded;
}
// https://stackoverflow.com/a/21797381
function base64ToArrayBuffer(base64) {
const binaryString = atob(base64);
const length = binaryString.length;
const result = new Uint8Array(length);
for (let i = 0; i < length; i++) {
result[i] = binaryString.charCodeAt(i);
}
return result;
}
function base64EncodeByteArray(data) {
const charBytes = new Array(data.length);
for (var i = 0; i < data.length; i++) {
charBytes[i] = String.fromCharCode(data[i]);
}
const dataBase64Encoded = btoa(charBytes.join(''));
return dataBase64Encoded;
}编码/解码在客户机和服务器上都增加了巨大的开销,同时还需要大量的样板代码。那么在.NET 6中如何实现呢? 嗯,它相当简单:
function receiveAndReturnBytes(bytesReceived) {
// bytesReceived comes as a Uint8Array ready for use
// and can be used by the application or immediately returned.
return bytesReceived;
}因此,编写它肯定更容易,但它的性能如何呢?分别在.NET 5和.NET 6的blazorserver模板中运行这些代码片段,在Release配置下,我们看到.NET 6在byte[]互操作方面有78%的性能提升!
请注意,流式互操作支持还可以有效下载(大)文件,有关更多详细信息,请参阅文档。
InputFile 组件已升级为通过 dotnet/aspnetcore#33900 使用流式传输。
| —————– | .NET 6 (ms) | .NET 5 (ms) | 提升 |
|---|---|---|---|
| 总时间 | 5273 | 24463 | 78% |
此外,这个字节数组互操作支持在框架中被用来支持JavaScript和.NET之间的双向流互操作。用户现在能够传输任意二进制数据。有关从 .NET 流式传输到 JavaScript的文档可在此处获得,JavaScript 到 .NET 文档可在此处获得。
输入文件
使用上面提到的Blazor Streaming Interop,我们现在支持通过InputFile组件上传大文件(以前的上传限制在2GB左右)。由于使用了本地byte[]流,而不是使用Base64编码,该组件的速度也有了显著提高。例如,例如,与.NET 5相比,一个100mb文件的上传速度要快77%。
| .NET 6 (ms) | .NET 5 (ms) | 百分比 |
|---|---|---|
| 2591 | 10504 | 75% |
| 2607 | 11764 | 78% |
| 2632 | 11821 | 78% |
| Average: | 77% |
请注意,流式互操作支持还可以有效下载(大)文件,有关更多详细信息,请参阅文档。
InputFile 组件已升级为通过 dotnet/aspnetcore#33900使用流式传输。
大杂烩
来自@benaadams的 dotnet/aspnetcore#30320对我们的 Typescript 库进行了现代化改造并对其进行了优化,因此网站加载速度更快。signalr.min.js 文件从 36.8 kB 压缩和 132 kB 未压缩变为 16.1 kB 压缩和 42.2 kB 未压缩。blazor.server.js 文件压缩后为 86.7 kB,未压缩时为 276 kB,压缩后为 43.9 kB,未压缩时为 130 kB。
@benaadams的 dotnet/aspnetcore#31322在从连接功能集合中获取常用功能时删除了一些不必要的强制转换。这在访问集合中的常见特征时提供了约 50% 的改进。不幸的是,在基准测试中看到性能改进是不可能的,因为它需要一堆内部类型,所以我将在此处包含来自 PR 的数字,如果您有兴趣运行它们,PR 包括可以运行的基准反对内部代码。
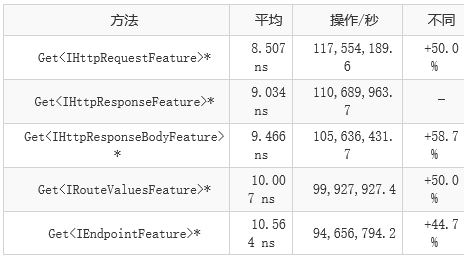
dotnet/aspnetcore#31519也来自@benaadams,将默认接口方法添加到 IHeaderDictionary 类型,以通过以标头名称命名的属性访问公共标头。访问标题字典时不再输入错误的常见标题!这篇博客文章中更有趣的是,这个改变允许服务器实现返回一个自定义标头字典,以更优化地实现这些新的接口方法。例如,服务器可能会将标头值直接存储在一个字段中,并直接返回该字段,而不是在内部字典中查询标头值,这需要对键进行哈希并查找条目。在某些情况下,当获取或设置标头值时,此更改可带来高达480%的改进。再一次,为了正确地对这个变化进行基准测试,以显示它需要使用内部类型进行设置,所以我将包括来自PR的数字,对于那些有兴趣尝试它的人来说,PR包含在内部代码上运行的基准测试。
| 方法 | 分支 | 类型 | 平均 | 操作/秒 | Delta |
|---|---|---|---|---|---|
| GetHeaders | before | Plaintext | 25.793 ns | 38,770,569.6 | – |
| GetHeaders | after | Plaintext | 12.775 ns | 78,279,480.0 | +101.9% |
| GetHeaders | before | Common | 121.355 ns | 8,240,299.3 | – |
| GetHeaders | after | Common | 37.598 ns | 26,597,474.6 | +222.8% |
| GetHeaders | before | Unknown | 366.456 ns | 2,728,840.7 | – |
| GetHeaders | after | Unknown | 223.472 ns | 4,474,824.0 | +64.0% |
| SetHeaders | before | Plaintext | 49.324 ns | 20,273,931.8 | – |
| SetHeaders | after | Plaintext | 34.996 ns | 28,574,778.8 | +40.9% |
| SetHeaders | before | Common | 635.060 ns | 1,574,654.3 | – |
| SetHeaders | after | Common | 108.041 ns | 9,255,723.7 | +487.7% |
| SetHeaders | before | Unknown | 1,439.945 ns | 694,470.8 | – |
| SetHeaders | after | Unknown | 517.067 ns | 1,933,985.7 | +178.4% |
dotnet/aspnetcore#31466使用 .NET 6 中引入的新 CancellationTokenSource.TryReset() 方法在连接关闭但未取消的情况下重用 CancellationTokenSource。下面的数字是通过运行bombardier对Kestrel的125个连接收集的,它运行了大约10万个请求。
| 分支 | 类型 | 分配 | 字节数 |
|---|---|---|---|
| Before | CancellationTokenSource | 98,314 | 4,719,072 |
| After | CancellationTokenSource | 125 | 6,000 |
dotnet/aspnetcore#31528和dotnet/aspnetcore#34075分别对重用HTTPS握手和HTTP3流的CancellationTokenSource做了类似的更改。
dotnet/aspnetcore#31660通过在SignalR中为整个流重用分配的StreamItem对象,而不是为每个流项分配一个,提高了服务器对客户端流的性能。而dotnet/aspnetcore#31661将HubCallerClients对象存储在SignalR连接上,而不是为每个Hub方法调用分配它。
@ShreyasJejurkar的 dotnet/aspnetcore#31506重构了WebSocket握手的内部结构,以避免临时List分配。@gfoidl中的 dotnet/aspnetcore#32829重构QueryCollection以减少分配和向量化一些代码。@benaadams的 dotnet/aspnetcore#32234删除了 HttpRequestHeaders 枚举中未使用的字段,该字段通过不再为每个枚举的标头分配字段来提高性能。
来自 martincostello的 dotnet/aspnetcore#31333将 Http.Sys 转换为使用 LoggerMessage.Define,这是高性能日志记录 API。这避免了不必要的值类型装箱、日志格式字符串的解析,并且在某些情况下避免了在日志级别未启用时分配字符串或对象。
dotnet/aspnetcore#31784添加了一个新的 IApplicationBuilder。使用重载来注册中间件,以避免在运行中间件时进行一些不必要的按请求分配。旧代码如下所示:
app.Use(async (context, next) =>
{
await next();
});新代码如下:
app.Use(async (context, next) =>
{
await next(context);
});下面的基准测试模拟中间件管道,而不需要设置服务器来展示改进。使用int代替HttpContext用于请求,中间件返回一个完成的任务。
dotnet run -c Release -f net6.0 --runtimes net6.0 --filter *UseMiddlewareBenchmark*
static private Func, Func> UseOld(Func, Task> middleware)
{
return next =>
{
return context =>
{
Func simpleNext = () => next(context);
return middleware(context, simpleNext);
};
};
}
static private Func, Func> UseNew(Func, Task> middleware)
{
return next => context => middleware(context, next);
}
Func Middleware = UseOld((c, n) => n())(i => Task.CompletedTask);
Func NewMiddleware = UseNew((c, n) => n(c))(i => Task.CompletedTask);
[Benchmark(Baseline = true)]
public Task Use()
{
return Middleware(10);
}
[Benchmark]
public Task UseNew()
{
return NewMiddleware(10);
} | 方法 | 平均 | 比率 | 已分配 |
|---|---|---|---|
| Use | 15.832 ns | 1.00 | 96 B |
| UseNew | 2.592 ns | 0.16 | – |
总结
希望您喜欢阅读 ASP.NET Core 6.0 中的一些改进!我鼓励你去看看.NET 6博客中关于运行时性能改进的文章。