强化学习部分基础算法总结(Q-learning DQN PG AC DDPG TD3)
总结回顾一下近期学习的RL算法,并给部分实现算法整理了流程图、贴了代码。
1. value-based 基于价值的算法
基于价值算法是通过对agent所属的environment的状态或者状态动作对进行评分。对于已经训练好的模型,agent只需要根据价值函数对当前状态选择评分最高的动作即可;对于正在训练的模型,我们通常将目标值(真实行动带来的反馈)和价值函数的预测值的差距作为loss训练价值函数。
通常使用两种价值函数:
-
状态价值函数 V(s),策略为 π 的状态-值函数,即状态s下预计累计回报的期望值,满足:

-
状态行动价值函数 Q(s, a),策略为 π 的状态-动作值函数,即状态s下采取行动a预计累计回报的期望值,满足:

value-based通常和贪婪策略一起使用,网络输出动作的价值后选择最大价值的方法,当最优策略是随机策略(比如环境是剪刀石头布)时,往往效果不佳;同时由于需要输出奖励使得无法将动作映射到一个分布中,因此对于连续动作无能为力。
1.1 Q-learning
最经典的value-based算法,通过Q-learning可以很好地体验到基于价值方法的优缺点。使用Q table作为价值函数Q(s, a)的载体,算法模型如下:

Agent代码如下:
"""
Q-learning
"""
class Agent:
def __init__(self, actions, learning_rate, reward_decay, e_greedy):
self.actions = actions
self.lr = learning_rate
self.gamma = reward_decay
self.epsilon = e_greedy
self.q_table = pd.DataFrame(
columns=self.actions,
dtype=np.float
)
def choose_action(self, observation):
self.check_state_exist(observation)
if np.random.uniform() < self.epsilon:
state_actions = self.q_table.loc[observation, :]
action = np.random.choice(state_actions[state_actions == np.max(state_actions)].index)
else:
action = np.random.choice(self.actions)
return action
def learn(self, s, a, r, s_):
self.check_state_exist(s_)
q_predict = self.q_table.loc[s, a]
if s_ != 'end':
q_target = r + self.gamma * self.q_table.loc[s_, :].max()
else:
q_target = r
self.q_table.loc[s, a] += self.lr * (q_target - q_predict)
def check_state_exist(self, state):
if state not in self.q_table.index:
self.q_table = self.q_table.append(
pd.Series(
[0] * len(self.actions),
index=self.q_table.columns,
name=state
)
)
1.2 Sarsa
Sarsa大体于Q learning类似,不过在流程上在计算loss前先选择了下一步的动作next_action,然后再进行loss计算,这使得Sarsa学习的状态动作对都属于当前的轨迹,属于在线学习on-policy。

Q learning和Sarsa在测试时,效果相比起来:
- Q learning更强调该状态和目标点的距离远近,若距离较近,maxa’Q(s’, a’)则值很大,导致这个状态的所有动作的值都偏大;
- Sarsa更强调状态动作对,如果状态离目标点更近还不行,只有可以或者已经到达目标点的路径的值才会偏大。
所以Q learning的路径会比较激进,偏向于探索,因为如果该状态其中一个动作值较高,其他动作值也相应较高,而sarsa则比较保守,如果该状态其中一个动作值较高,会倾向于走那条值较高的道路,探索性较低。
优化版本Sarsa Lambda一次到达后同时更新多步,但是也更加保守了,因为多个状态动作对受影响。
Agent代码如下:
"""
Sarsa Lambda
"""
class Agent:
def __init__(self, actions, learning_rate, reward_decay, e_greedy, sarsa_lambda):
self.actions = actions
self.lr = learning_rate
self.gamma = reward_decay
self.epsilon = e_greedy
self.q_table = pd.DataFrame(
columns=self.actions,
dtype=np.float
)
self.lambda_ = sarsa_lambda
self.eligibility_trace = self.q_table.copy()
def choose_action(self, observation):
self.check_state_exist(observation)
if np.random.uniform() < self.epsilon:
state_actions = self.q_table.loc[observation, :]
action = np.random.choice(state_actions[state_actions == np.max(state_actions)].index)
else:
action = np.random.choice(self.actions)
return action
def learn(self, s, a, r, s_, a_):
self.check_state_exist(s_)
q_predict = self.q_table.loc[s, a]
if s_ != 'end':
q_target = r + self.gamma * self.q_table.loc[s_, a_]
else:
q_target = r
error = q_target - q_predict
self.eligibility_trace.loc[s, :] *= 0
self.eligibility_trace.loc[s, a] = 1
self.q_table += self.lr * error * self.eligibility_trace
self.eligibility_trace *= self.gamma * self.lambda_
def check_state_exist(self, state):
if state not in self.q_table.index:
to_be_append = pd.Series(
[0] * len(self.actions),
index=self.q_table.columns,
name=state
)
self.q_table = self.q_table.append(to_be_append)
self.eligibility_trace = self.eligibility_trace.append(to_be_append)
1.3 DQN(Deep Q-Network)及其优化版本
1.3.1 Nature DQN
在Q learning的基础上添加了三个新特性:
- 神经网络Q Network代替Q Table
- 记忆库用于经验回放
- Q Network和Target Q Network分离
算法如下:

DQN引入了神经网络,将Q table替换为Q Network,解决高维状态动作对带来的数据量过多Q table无法存储的问题。使用神经网络的思想,使输入的状态动作对和输出的Q值变成一个函数,通过训练来拟合。
DQN带来的新问题以及解决方法: - 神经网络的数据标记:使用了Q learning的思想,将目标值(真实行动带来的反馈)作为label。
- 分布需要独立:经验池回放 Experience Replay; 目标网络 Target Q Network 和预测网络 Q Network 分离(数据独立可以减小方差)
Q:为什么DQN需要隔一段时间后才更新目标网络?
A:目标网络用来评价状态动作对,即相当于神经网络中的标签。如果每次更新当前网络的时候同时更新目标网络,相当于更新参数的同时,标签也改变了,这容易使得网络每次更新后相当于“重新训练”网络,收敛效果不好。
DQN的流程图如下:
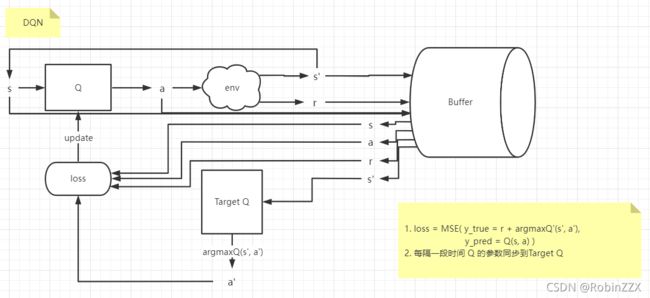
DQN算法代码如下:
"""
DQN
"""
class DQN:
def __init__(self, model, gamma=0.9, learning_rate=0.01):
self.model = model.model
self.target_model = model.target_model
self.gamma = gamma
self.lr = learning_rate
# --------------------------训练模型--------------------------- #
self.model.optimizer = tf.optimizers.Adam(learning_rate=self.lr)
self.model.loss_func = tf.losses.MeanSquaredError()
# self.model.train_loss = tf.metrics.Mean(name="train_loss")
# ------------------------------------------------------------ #
self.global_step = 0
self.update_target_steps = 200 # 每隔200个training steps再把model的参数复制到target_model中
self.loss_table = []
def predict(self, obs):
"""
使用self.model的value网络来获取 [Q(s,a1),Q(s,a2),...]
"""
return self.model.predict(obs)
def _train_step(self, action, features, labels):
"""
训练步骤
"""
with tf.GradientTape() as tape:
# 计算 Q(s,a) 与 target_Q的均方差,得到loss
predictions = self.model(features, training=True)
enum_action = list(enumerate(action))
pred_action_value = tf.gather_nd(predictions, indices=enum_action)
loss = self.model.loss_func(labels, pred_action_value)
self.loss_table.append(loss)
gradients = tape.gradient(loss, self.model.trainable_variables)
self.model.optimizer.apply_gradients(zip(gradients, self.model.trainable_variables))
# self.model.train_loss.update_state(loss)
def _train_model(self, action, features, labels, epochs=1):
"""
训练模型
"""
for epoch in tf.range(1, epochs+1):
self._train_step(action, features, labels)
def learn(self, obs, action, reward, next_obs, terminal):
"""
使用DQN算法更新self.model的value网络
"""
# 每隔200个training steps同步一次model和target_model的参数
if (self.global_step > 200) and (self.global_step % self.update_target_steps == 0):
self.replace_target()
# 从target_model中获取 max Q' 的值,用于计算target_Q
next_pred_value = self.model.predict(next_obs)
best_v = tf.reduce_max(next_pred_value, axis=1)
target = reward + self.gamma * best_v
# 训练模型
self._train_model(action, obs, target, epochs=1)
self.global_step += 1
def replace_target(self):
"""
预测模型权重更新到target模型权重
"""
self.target_model.get_layer(name='l1').set_weights(self.model.get_layer(name='l1').get_weights())
# self.target_model.get_layer(name='l2').set_weights(self.model.get_layer(name='l2').get_weights())
self.target_model.get_layer(name='l3').set_weights(self.model.get_layer(name='l3').get_weights())
DQN记忆库代码如下:
"""
ReplayMemory of Neture DQN
"""
class ReplayMemory:
def __init__(self,max_size):
self.buffer = collections.deque(maxlen=max_size)
def append(self,exp):
self.buffer.append(exp)
def sample(self, batch_size):
mini_batch = random.sample(self.buffer, batch_size)
obs_batch, action_batch, reward_batch, next_obs_batch, done_batch = [], [], [], [], []
for experience in mini_batch:
s, a, r, s_p, done = experience
obs_batch.append(s)
action_batch.append(a)
reward_batch.append(r)
next_obs_batch.append(s_p)
done_batch.append(done)
return np.array(obs_batch).astype('float32'), \
np.array(action_batch).astype('int32'), np.array(reward_batch).astype('float32'),\
np.array(next_obs_batch).astype('float32'), np.array(done_batch).astype('float32')
def __len__(self):
return len(self.buffer)
后续优化版本:
- Double DQN:通过改变target q的计算来优化
- Prioritized Replay DQN:通过改变经验回放的结构和方式来优化
- Dueling DQN:通过改变神经网络的结构来优化
1.3.2 Double Deep Q-Network
DDQN用于解决DQN中Q Network对于价值估计过高的问题,Target Q的选取仍然从目标网络中输出输入状态的所有动作的价值Q,但是选取哪一个动作不再是依照最大值,而是使用预测网络中输入状态的输出动作的最大值的索引来选取。DDQN中的Target Q如下:
![]()
1.3.3 Prioritized Experience Replay (DQN)
Prioritized Experience DQN将记忆库中的记录根据TD-error(Target Q - Q)进行排序,TD-error越大说明该记录越应该被学习。为此需要修改原来记忆库的数据结构,使用Jaromír Janisch提出的SumTree(一种完全二叉树)和对应的记忆库来存储。记忆都存储于叶子节点,非叶节点的值为子节点之和,这种结构在存储新节点时只需插入在末端并更新相应祖先节点即可,比其他排序算法计算的时间更少。
难点在于ISWeight的作用和计算:
Importance-Sampling Weights, 用来恢复被 Prioritized replay 打乱的抽样概率分布.
![]()
SumTree以及记忆库代码如下:
"""
SumTree and memory in Prioritized Experience DQN
"""
class SumTree(object):
data_pointer = 0
def __init__(self, capacity):
# data_pointer即记忆data的索引,加上(self.capacity - 1)变为SumTree索引
self.capacity = capacity # 容量
self.tree = np.zeros(2 * capacity - 1) # SumTree,负责记录记忆的优先级,结构类似满二叉树?
self.data = np.zeros(capacity, dtype=object) # 叶子节点数据,负责记录记忆内容
def add(self, p, data):
# 猜测:data_pointer指向记忆数据末尾
tree_idx = self.data_pointer + self.capacity - 1 # tree_idx指向SumTree末尾
self.data[self.data_pointer] = data # 更新记忆数据
self.update(tree_idx, p) # 更新SumTree
self.data_pointer += 1
if self.data_pointer >= self.capacity:
self.data_pointer = 0
def update(self, tree_idx, p):
change = p - self.tree[tree_idx]
self.tree[tree_idx] = p
# 更新祖先节点
while tree_idx != 0:
tree_idx = (tree_idx - 1) // 2
self.tree[tree_idx] += change
def get_leaf(self, v):
"""
关于SumTree的记忆选取可查看一下文档:
https://zhuanlan.zhihu.com/p/165134346
"""
parent_idx = 0
while True: # while循环比论文代码快
cl_idx = 2 * parent_idx + 1 # 左子节点
cr_idx = cl_idx + 1 # 右子节点
if cl_idx >= len(self.tree):
leaf_idx = parent_idx
break
else:
if v <= self.tree[cl_idx]:
parent_idx = cl_idx
else:
v -= self.tree[cl_idx]
parent_idx = cr_idx
data_idx = leaf_idx - self.capacity + 1 # 转为记忆数据的索引
return leaf_idx, self.tree[leaf_idx], self.data[data_idx]
@property
def total_p(self):
return self.tree[0]
class ReplayMemory(object):
epsilon = 0.01 # 避免0优先级的最小优先级
alpha = 0.6 # [0~1] 将td-error转化为优先级
beta = 0.4 # ? importance-sampling, from initial value increasing to 1
beta_increment_per_sampling = 0.001 # ?
abs_err_upper = 1. # 初始化误差绝对值为1 clipped abs error
def __init__(self, capacity):
self.tree = SumTree(capacity)
def sample(self, n):
b_idx, b_memory, ISWeights = np.empty((n,), dtype=np.int32), np.empty((n, self.tree.data[0].size)), np.empty(
(n, 1))
pri_seg = self.tree.total_p / n # 分成batch个区间
# beta = 0.4 每次采样都会增大0.001,最大值为1
self.beta = np.min([1., self.beta + self.beta_increment_per_sampling])
# 最小优先级占所有优先级之和的比重,由于后面计算ISWeights
min_prob = np.min(self.tree.tree[-self.tree.capacity:]) / self.tree.total_p
# print('min of 优先级: ' + str(self.tree.tree[-self.tree.capacity:]))
# print('total_p: ' + str(self.tree.total_p))
print('min_prob: ' + str(min_prob))
for i in range(n):
a, b = pri_seg * i, pri_seg * (i + 1) # 每个区间的上下界
v = np.random.uniform(a, b) # 在该区间随机抽取一个数
idx, p, data = self.tree.get_leaf(v) # 该数对应的优先级
prob = p / self.tree.total_p # 当前优先级占所有优先级之和的比重
# 疑惑点:
# prob / min_prob 当前优先级和最小优先级之比
# ISWeights<=1 且仅当优先级最小时为1,优先级越大ISWeights越小,
# 而且随着采样次数增多,beta逐渐增大,而ISWeight逐渐减小
ISWeights[i, 0] = np.power(prob / min_prob, -self.beta)
b_idx[i], b_memory[i, :] = idx, data
return b_idx, b_memory, ISWeights
def store(self, transition):
max_p = np.max(self.tree.tree[-self.tree.capacity:])
if max_p == 0:
max_p = self.abs_err_upper
self.tree.add(max_p, transition)
def batch_update(self, tree_idx, abs_errors):
abs_errors += self.epsilon # 避免为0
"""
比较两个数组,将每个位置数值较小的值填入一个新数组并返回,
若两个数组其中一个是单个数字,使用广播机制扩充为相同尺寸的数组
self.abs_err_upper为1,因此下面语句是abs_errors中所有大于1的值化为1
以保证所有error<=1
"""
clipped_errors = np.minimum(abs_errors, self.abs_err_upper)
ps = np.power(clipped_errors, self.alpha) # td-error转化为优先级
for ti, p in zip(tree_idx, ps):
self.tree.update(ti, p)
1.3.4 Dueling DQN
Dueling DQN对DQN的神经网络进行了优化,将输出的状态动作价值Q(s, a)分为了状态价值V(s) 和优势Advantage(s, a)之和进行表示:
![]()
网络结构修改为:
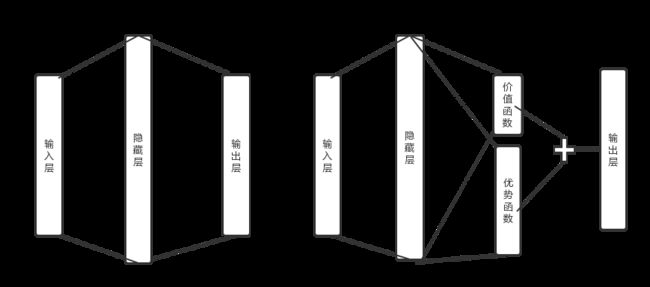
神经网络模型的代码如下:
"""
Network of Dueling DQN
"""
class Model:
def __init__(self, obs_n, act_dim):
self.obs_n = obs_n
self.act_dim = act_dim
self._build_model()
def _build_layers(self):
dense_size1 = 30
dense_size2 = 16
dense_size2 = 40
# 定义输入层
input_node = Input(shape=self.obs_n)
input_layer = input_node
# 第一层
layer1 = layers.Dense(
dense_size1,
kernel_initializer=tf.random_normal_initializer(0., 0.3),
bias_initializer=tf.constant_initializer(0.1),
# activation='relu',
activation=layers.LeakyReLU(alpha=0.05),
name='l1'
)(input_layer)
# 计算状态价值
state_value = layers.Dense(
dense_size2,
kernel_initializer=tf.random_normal_initializer(0., 0.3),
bias_initializer=tf.constant_initializer(0.1),
activation=layers.LeakyReLU(alpha=0.05),
name='state_value_1'
)(layer1)
state_value = layers.Dense(
1,
kernel_initializer=tf.random_normal_initializer(0., 0.3),
bias_initializer=tf.constant_initializer(0.1),
activation=layers.LeakyReLU(alpha=0.05),
name='state_value_2'
)(state_value)
# 计算行动优势
action_advantage = layers.Dense(
dense_size2,
kernel_initializer=tf.random_normal_initializer(0., 0.3),
bias_initializer=tf.constant_initializer(0.1),
activation=layers.LeakyReLU(alpha=0.05),
name='action_advantage_1'
)(layer1)
action_advantage = layers.Dense(
self.act_dim,
kernel_initializer=tf.random_normal_initializer(0., 0.3),
bias_initializer=tf.constant_initializer(0.1),
activation=layers.LeakyReLU(alpha=0.05),
name='action_advantage_2'
)(action_advantage)
# 计算Q值
q = layers.add([state_value, action_advantage])
# 定义模型
model = tf.keras.Model(inputs=input_node, outputs=q)
model.summary()
return model
def _build_model(self):
self.model = self._build_layers()
self.target_model = self._build_layers()
2. policy-based 基于策略的算法
基于策略算法不使用价值函数而是使用策略函数来输出动作的概率,不会使用固定的动作选择,最大的特点是将动作使用概率表示,因此所有动作都有可能被选到,而且得益于概率表示,可以将动作映射到分布中,因此可以设置高位的动作和连续动作。
Policy Gradient这种基于策略算法要做的,就是最大化奖励期望`Rθ;而像dqn这种基于价值要做的,是最大化奖励 Rθ 。policy-based流程如下:
更新网络参数θ – 如何更新使得期望最大化 – 朝梯度上升方向更新
Policy Gradient算法可以根据更新方式分为两大类:
MC更新方法:Reinfoce算法;
TD更新方法:Actor-Critic算法;
2.1 REINFORCE
与value-based方法的区别:
- 使用动作概率表示:在目标网络最后一层输出使用softmax,用动作概率而不是动作价值来表示
- 回合更新:在一个回合结束之后才学习,而不像dqn一样几步一学习。回合更新的优点是准确。对于深度强化学习来说,前期的标签可能具有欺骗性?这时的过早学习可能会误导网络的参数,使用回合更新可以使这种趋势减小;回合更新的缺点是相对耗时。对于一些需要长步数的回合,需要较长时间才可以学习到新的参数。
细节:
- 使用梯度上升来反向传播,并且直接使用奖励而不是计算误差来作为反向传播的输入。
- 减弱drl中标签欺骗性的方法:对于上面讲到的深度强化学习的标签的欺骗性(标签是真实的动作,并不是正确的动作),Policy Gradient使用一个方法来减少这个趋势:将标签和输出的差距乘以回报,用回报来评价这个误差的重要性,如果回报是正数而且数值很大,则这个loss的权重很大,若数值很小甚至为负值(不清楚是否可以为负值),则说明这个loss权重很小甚至起反效果。
- Policy Gradient的网络输出是动作概率而不是动作价值,问题类似于分类问题,即对于输入的图像(state)判断属于某种类型(要使用某种action)的概率,因此构造的网络的输出函数可以用分类问题常用的softmax
优点:
- 因为使用动作概率,所以可以适用于随机性问题
- 对于不好计算价值的模型更适用
- 对于连续的动作空间(高维)更适用
缺点:
- 容易局部最优
优化:
-
奖励基准值:对于奖励总为正的环境,难以判断某些轨迹是否真正有帮助,对奖励设置一个基准值(一般设置为所有轨迹的总奖励的平均数),用轨迹的奖励减去基准值来判断。

-
动作评分:轨迹中并不是每一个动作都对于最终的分数有正确作用,但是在计算期望的时候,每个动作的权重都是使用轨迹的总奖励,因此可以对每个动作分别设置权重,用这个动作开始后的奖励之和来反映这个动作的价值(权重)。
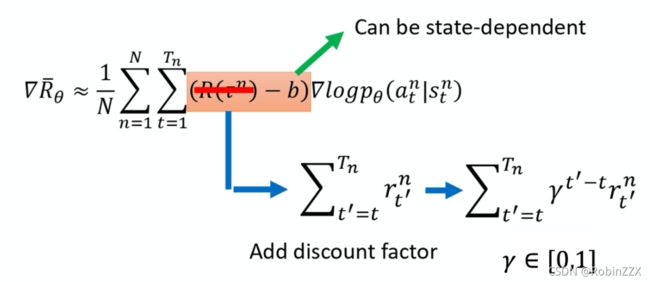
代码如下:
"""
Policy Gradient
"""
class PolicyGradient:
def __init__(self,
n_action,
shape_state,
n_layers,
size,
reward_decay=0.99,
learning_rate=0.01,
batch_size=1,
max_t_length=500
):
if size is None:
size = [64]
self.n_action = n_action
self.shape_state = shape_state
self.n_layers = n_layers
self.size = size
self.reward_decay = reward_decay
self.learning_rate = learning_rate
self.batch_size = batch_size
self.max_t_length = max_t_length
self.model = self._build_net()
self.optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate)
self.transitions = self.reset_transition()
self.p_transitions = -1
def _build_net(self):
kernel_init = 'he_normal' # 正态分布
bias_init = tf.constant_initializer(0.01) # 常数
model = tf.keras.Sequential()
for i in range(self.n_layers):
model.add(layers.Dense(self.size[i],
activation=tf.nn.tanh,
kernel_initializer=kernel_init,
bias_initializer=bias_init))
model.add(layers.Dense(self.n_action,
activation=tf.nn.tanh,
kernel_initializer=kernel_init,
bias_initializer=bias_init))
return model
def add_store_t(self):
self.transitions.append([[], [], []])
self.p_transitions += 1
def store_transition(self, s, a, r):
self.transitions[self.p_transitions][0].append(s)
self.transitions[self.p_transitions][1].append(a)
self.transitions[self.p_transitions][2].append(r)
def reset_transition(self):
self.p_transitions = -1
return []
def choose_action(self, state):
# 转换state格式,(state_dim,) => (batch, state_dim) 此时 batch=1
state = state[np.newaxis, :]
state = tf.convert_to_tensor(state, dtype=tf.float32)
# 得到每个动作概率,由于每个网络最后的输出函数是tanh,需要再加一个softmax
p_actions = self.model(state)
p_actions = tf.nn.softmax(p_actions)
# 按概率选择
action = np.random.choice(np.arange(self.n_action), p=p_actions.numpy()[0])
# print('查看p_actions格式: ' + str(p_actions))
return action
def sum_of_rewards(self):
res = []
for t in range(len(self.transitions)):
tmp = 0
t_rewards = self.transitions[t][2]
t_rewards_to_go = np.zeros_like(t_rewards)
for i in reversed(range(0, len(t_rewards))):
tmp = tmp * self.reward_decay + t_rewards[i]
t_rewards_to_go[i] = tmp
res.append(t_rewards_to_go)
return np.concatenate(res)
def learn(self):
tmp = np.array(self.transitions[0][0])
print(tmp.shape)
print(np.array([t[0] for t in self.transitions]))
obs = np.concatenate([t[0] for t in self.transitions])
acs = np.concatenate([t[1] for t in self.transitions])
res = self.sum_of_rewards()
with tf.GradientTape() as tape:
# 预测值
pred_p_actions = self.model(obs)
pred_p_actions = tf.nn.softmax(pred_p_actions)
neg_log_prob = tf.reduce_sum(-tf.math.log(pred_p_actions) * tf.one_hot(acs, depth=self.n_action), axis=1)
loss = tf.reduce_sum(neg_log_prob * res) / self.batch_size
grads = tape.gradient(loss, self.model.trainable_variables)
self.optimizer.apply_gradients(zip(grads, self.model.trainable_variables))
def train(self, env, seed, n_episodes):
np.random.seed(seed)
tf.random.set_seed(seed)
env.seed(seed)
for i_episode in range(n_episodes):
state = env.reset()
self.add_store_t()
steps = 0
while True:
env.render()
action = self.choose_action(state)
next_state, reward, done, info = env.step(action)
self.store_transition(state, action, reward)
state = next_state
# 这里使用了回合更新,而且是单回合更新,从理论上说,越多回合作为一个batch越好
if done or steps > self.max_t_length:
print('done: ' + str(done) + ' steps: ' + str(steps))
if i_episode % self.batch_size == 0:
self.learn()
self.transitions = self.reset_transition()
break
3. Actor-Critic 结构的算法
3.1 Actor-Critic(AC)
使用TD-error方法改进REINFORCE从回合更新改为单步更新。用 TD 比较稳,用 MC 比较精确。
Q:为什么说 REINFORCE 方差大?
A:受知乎答案启发 强化学习,方差比较大是说什么的方差大,为啥方差比较大? - 知乎,方差大指的是同样的策略下,输出的回报变化很大(有点过拟合的意思)。在 REINFORCE 中一次只采集一个或几个完整轨迹(多了采集时间久)进行学习,导致了方差较大。(Following from 第九章 演员-评论家算法)假设我们可以采样足够的次数,在每次更新参数之前,我们都可以采样足够的次数,那其实没有什么问题。但问题就是我们每次做 policy gradient,每次更新参数之前都要做一些采样,这个采样的次数其实是不可能太多的,我们只能够做非常少量的采样。如果你正好采样到差的结果,比如说你采样到 G = 100,采样到 G = -10,那显然你的结果会是很差的。
Q:怎么拿期望值代替采样的值呢?
A:这边就需要引入基于价值的(value-based)的方法。基于价值的方法就是 Q-learning。Q-learning 有两种函数,有两种 critics。
- 第一种 critic 是 Vπ(s),它的意思是说,假设 actor 是 π,拿 π 去跟环境做互动,当我们看到状态 s 的时候,接下来累积奖励 的期望值有多少。
- 还有一个 critic 是 Qπ(s,a)。Qπ(s,a) 把 s 跟 a 当作输入,它的意思是说,在状态 s 采取动作 a,接下来都用 actor π 来跟环境进行互动,累积奖励的期望值是多少。

在Policy Gradient中的梯度更新为:

Actor-Critic在Policy Gradient的基础上引入了value-based方法中值函数的概念来预测 Gt 的期望值,将Policy Gradient的梯度更新中的 Gt 转为 Q(s, a) 函数,baseline 转为 V(s) 函数,
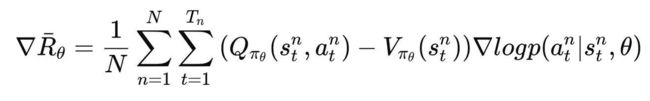
3.2 Advantage Actor-Critic(A2C)
名称中的 Advantage 代表 advantage function 优势函数,将 Q(s, a) 用 r + V(s) 代替,从而将Q函数简化,使只需要训练一个 V(s) 函数的网络而不用训练 Q(s, a) 函数网络

为什么可以用 r + V(s) 的形式代替 Q(s, a) 呢,首先Q函数本身可以写成:
![]()
在这里我们将期望去掉即变成 r+v(s, a)形式 ,虽然增加了随机性、增大了方差,但是相对于 Gt 的方差小了很多,可以去掉期望还算合理。

至于为什么两种都行(使用q v和只是用v的两种)而选择使用后者呢?原始的 A3C paper 试了各种方法,最后做出来就是这个最好。233
在实际操作的时候,虽然理论上需要两个网络: policy 网络和 V(s) 网络。但是这两个网络的输入都是 s ,只是输出不同(动作的分布和 s 的价值),所以这两个网络可以共用前面的层,用来将 s 抽象成高级的信息。
A2C流程图如下:

A2C代码如下:
"""
Advantage Actor-Critic
"""
class ActorCritic:
def __init__(self,
env, # 环境
action_space, # 动作类型:连续/离散
n_action, # 动作维度(连续)/数量(离散)
obs_space, # 观察类型:连续/离散
n_obs, # 状态维度(连续)/数量(离散)
max_steps_per_episodes, # 每回合最大步数
learning_rate, # 学习率
reward_decay, # 奖励衰减
n_batch # 定义一组学习数组大小
):
self.action_space = action_space
self.n_action = n_action
self.obs_space = obs_space
self.n_obs = n_obs
self.max_steps_per_episodes = max_steps_per_episodes
self.learning_rate = learning_rate
self.reward_decay = reward_decay
self.n_batch = n_batch
self.n_layers = 2 # 中间隐藏层数量,不包括输出层
self.n_units = 128
self.activation = 'relu'
self.kernel_initializer = 'he_normal' # 默认正太分布
self.bias_initializer = tf.constant_initializer(0.01) # 常数
self.policy_model, self.critic_model = self._build_net()
self.policy_model.compile(optimizer=optimizers.Adam(self.learning_rate),
loss=self._policy_loss)
self.critic_model.compile(optimizer=optimizers.Adam(self.learning_rate),
loss=self._critic_loss)
self.learning_times = 0
self.output_env_info = False
self.transitions = {
'obs': np.empty((self.n_batch,) + env.observation_space.shape),
'acs': np.empty((self.n_batch,), dtype=np.int32),
'res': np.empty((self.n_batch,)),
'done': np.empty((self.n_batch,))
}
def _build_net(self):
policy_model = tf.keras.Sequential() # 策略网络
for i in range(self.n_layers):
name = 'layer' + str(i)
policy_model.add(layers.Dense(self.n_units,
activation=self.activation,
kernel_initializer=self.kernel_initializer,
bias_initializer=self.bias_initializer,
name=name))
policy_model.add(layers.Dense(self.n_action,
activation=tf.nn.softmax,
kernel_initializer=self.kernel_initializer,
bias_initializer=self.bias_initializer,
name='layer' + str(self.n_layers)))
critic_model = tf.keras.Sequential() # 评价网络
for i in range(self.n_layers):
name = 'layer' + str(i)
critic_model.add(layers.Dense(self.n_units,
activation=tf.nn.softmax,
kernel_initializer=self.kernel_initializer,
bias_initializer=self.bias_initializer,
name=name))
critic_model.add(layers.Dense(1,
activation=self.activation,
kernel_initializer=self.kernel_initializer,
bias_initializer=self.bias_initializer,
name='layer' + str(self.n_layers)))
return policy_model, critic_model
def _policy_loss(self, y_true, y_pred):
actions, advantages = tf.split(y_true, 2, axis=-1)
loss_function = losses.SparseCategoricalCrossentropy(from_logits=True)
actions = tf.cast(actions, tf.int32)
loss = loss_function(actions, y_pred, sample_weight=advantages)
return loss
def _critic_loss(self, y_true, y_pred):
return losses.mean_squared_error(y_true, y_pred)
def choose_action(self, obs):
# 转为列向量,表示每个输入都是一维的,使用行向量会导致所有obs作为一个输入
obs = obs[np.newaxis, :]
obs = tf.convert_to_tensor(obs)
p_actions = self.policy_model.predict_on_batch(obs)
# print(p_actions)
action = np.random.choice(np.arange(self.n_action), p=np.array(p_actions)[0])
return action
def learn(self):
obs = self.transitions['obs']
actions = self.transitions['acs']
rewards = self.transitions['res']
done = self.transitions['done']
values = tf.squeeze(self.critic_model(obs[np.newaxis, :]))
td_error = np.append(np.zeros_like(rewards), [values[-1]], axis=-1)
# td_error = np.append(np.zeros_like(rewards), [], axis=-1)
for t in reversed(range(rewards.shape[0])):
td_error[t] = rewards[t] + td_error[t + 1] * done[t]
td_error = td_error[:-1]
advantages = td_error - values
actions_and_advantages = np.concatenate([actions[:, None], advantages[:, None]], axis=-1)
self.policy_model.train_on_batch(obs, actions_and_advantages) # arg1 input; arg2 label
self.critic_model.train_on_batch(obs, td_error)
self.transitions = {
'obs': np.empty((self.n_batch,) + env.observation_space.shape),
'acs': np.empty((self.n_batch,), dtype=np.int32),
'res': np.empty((self.n_batch,)),
'done': np.empty((self.n_batch,))
} # 清空数组
def store_transition(self, index, obs, action, reward, done):
self.transitions['obs'][index] = obs.copy()
self.transitions['acs'][index] = action
self.transitions['res'][index] = reward
self.transitions['done'][index] = done
def train(self, env, n_episodes, render=False):
reward_history = []
total_steps = 0
# 尝试将 n_episodes 当作学习次数
obs_ = env.reset()
reward_history = [0.]
for i in range(n_episodes):
for step in range(self.n_batch):
if render:
env.render()
obs = obs_.copy()
action = self.choose_action(obs)
obs_, reward, done, info = env.step(action)
self.store_transition(step, obs, action, reward, done)
reward_history[-1] += reward
if done:
obs_ = env.reset()
print('#' + str(i) + ' reward: ' + str(reward_history[-1]))
reward_history.append(0.)
self.learn()
return reward_history
def test(self, env, n_episodes, render=False):
total_reward = 0
reward_history = []
for i in n_episodes:
obs = env.reset()
while True:
if render:
env.render()
action = self.choose_action(obs)
obs_, reward, done, info = env.step(action)
total_reward += reward
obs = obs_
if done:
break
print('average reward is ' + str(total_reward / n_episodes))
3.3 Asynchronous Advantage Actor-Critic(A3C)
加入了异步操作,解决难收敛问题。具体是借助dqn中经验回放experience replay的思想并加以改进,在使用多个线程同时与环境交互,并更新公共网络。

3.4 Deep Deterministic Policy Gradient(DDPG)
再次回到Q learning,前面我们针对高维状态动作对带来的数据量过多问题其引入了神经网络,带来了DQN,现在针对DQN无法拓展到连续动作引入了策略网络,组成AC结构,在此基础上保留了DQN的优化方法:经验回放和目标网络,形成了DDPFG。
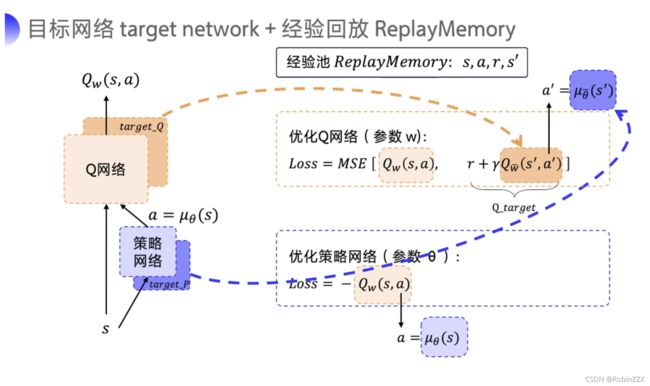
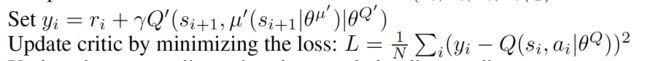
DDPG算法流程如下:

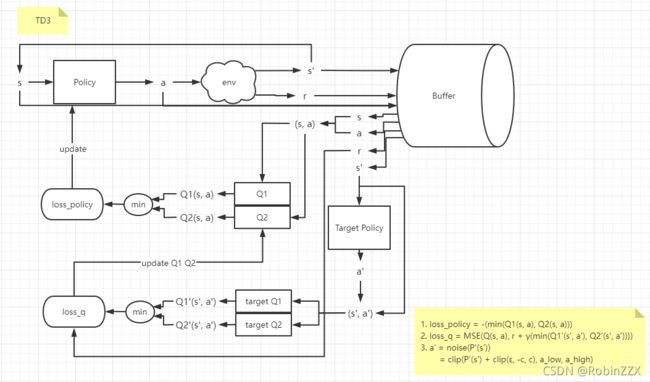
3.5 Twin Delayed DDPG(TD3)
DDPG 常见的问题是已经学习好的 Q 函数开始显著地高估 Q 值,然后导致策略被破坏了,因为它利用了 Q 函数中的误差。为了解决这个问题,TD3的作者使用了三个技巧来优化:
-
截断的双 Q 学习(Clipped Dobule Q-learning) 。TD3 学习两个 Q-function(因此名字中有 “twin”)。TD3 通过最小化均方差来同时学习两个 Q-function:Q1 和 Q2。两个 Q-function 都使用一个目标,两个 Q-function 中给出较小的值会被作为如下的 Q-target:
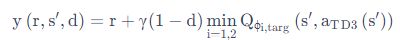
-
延迟的策略更新(“Delayed” Policy Updates) 。相关实验结果表明,同步训练动作网络和评价网络,却不使用目标网络,会导致训练过程不稳定;但是仅固定动作网络时,评价网络往往能够收敛到正确的结果。因此 TD3 算法以较低的频率更新动作网络,较高频率更新评价网络,通常每更新两次评价网络就更新一次策略。
-
目标策略平滑(Target Policy smoothing) 。TD3 引入了 smoothing 的思想。TD3 在目标动作中加入噪音,通过平滑 Q 沿动作的变化,使策略更难利用 Q 函数的误差。
算法流程如下:
TD3 代码如下(我的TD3实验效果不好,这里放出原作者的代码,带一点注释):
"""
TD3
"""
class TD3:
def __init__(
self, state_dim, action_dim, action_range, hidden_dim, replay_buffer, policy_target_update_interval=1,
q_lr=3e-4, policy_lr=3e-4
):
self.replay_buffer = replay_buffer
# initialize all networks
self.q_net1 = QNetwork(state_dim, action_dim, hidden_dim)
self.q_net2 = QNetwork(state_dim, action_dim, hidden_dim)
self.target_q_net1 = QNetwork(state_dim, action_dim, hidden_dim)
self.target_q_net2 = QNetwork(state_dim, action_dim, hidden_dim)
self.policy_net = PolicyNetwork(state_dim, action_dim, hidden_dim, action_range)
self.target_policy_net = PolicyNetwork(state_dim, action_dim, hidden_dim, action_range)
print('Q Network (1,2): ', self.q_net1)
print('Policy Network: ', self.policy_net)
# initialize weights of target networks
self.target_q_net1 = self.target_ini(self.q_net1, self.target_q_net1)
self.target_q_net2 = self.target_ini(self.q_net2, self.target_q_net2)
self.target_policy_net = self.target_ini(self.policy_net, self.target_policy_net)
# set train mode
self.q_net1.train()
self.q_net2.train()
self.target_q_net1.eval()
self.target_q_net2.eval()
self.policy_net.train()
self.target_policy_net.eval()
self.update_cnt = 0
self.policy_target_update_interval = policy_target_update_interval
self.q_optimizer1 = tf.optimizers.Adam(q_lr)
self.q_optimizer2 = tf.optimizers.Adam(q_lr)
self.policy_optimizer = tf.optimizers.Adam(policy_lr)
def target_ini(self, net, target_net):
""" hard-copy update for initializing target networks """
for target_param, param in zip(target_net.trainable_weights, net.trainable_weights):
target_param.assign(param)
return target_net
def target_soft_update(self, net, target_net, soft_tau):
""" soft update the target net with Polyak averaging """
for target_param, param in zip(target_net.trainable_weights, net.trainable_weights):
target_param.assign( # copy weight value into target parameters
target_param * (1.0 - soft_tau) + param * soft_tau
)
return target_net
def update(self, batch_size, eval_noise_scale, reward_scale=10., gamma=0.9, soft_tau=1e-2):
""" update all networks in TD3 """
self.update_cnt += 1
state, action, reward, next_state, done = self.replay_buffer.sample(batch_size)
reward = reward[:, np.newaxis] # expand dim
done = done[:, np.newaxis]
new_next_action = self.target_policy_net.evaluate(
next_state, eval_noise_scale=eval_noise_scale
) # clipped normal noise
reward = reward_scale * (reward - np.mean(reward, axis=0)) / (
np.std(reward, axis=0) + 1e-6
) # normalize with batch mean and std; plus a small number to prevent numerical problem
# Training Q Function
target_q_input = tf.concat([next_state, new_next_action], 1) # the dim 0 is number of samples
target_q_min = tf.minimum(self.target_q_net1(target_q_input), self.target_q_net2(target_q_input))
target_q_value = reward + (1 - done) * gamma * target_q_min # if done==1, only reward
q_input = tf.concat([state, action], 1) # input of q_net
with tf.GradientTape() as q1_tape:
predicted_q_value1 = self.q_net1(q_input)
q_value_loss1 = tf.reduce_mean(tf.square(predicted_q_value1 - target_q_value))
q1_grad = q1_tape.gradient(q_value_loss1, self.q_net1.trainable_weights)
self.q_optimizer1.apply_gradients(zip(q1_grad, self.q_net1.trainable_weights))
with tf.GradientTape() as q2_tape:
predicted_q_value2 = self.q_net2(q_input)
q_value_loss2 = tf.reduce_mean(tf.square(predicted_q_value2 - target_q_value))
q2_grad = q2_tape.gradient(q_value_loss2, self.q_net2.trainable_weights)
self.q_optimizer2.apply_gradients(zip(q2_grad, self.q_net2.trainable_weights))
# Training Policy Function
if self.update_cnt % self.policy_target_update_interval == 0:
with tf.GradientTape() as p_tape:
# 更新actor的时候,我们不需要加上noise,这里是希望actor能够寻着最大值。加上noise并没有任何意义
new_action = self.policy_net.evaluate(
state, eval_noise_scale=0.0
) # no noise, deterministic policy gradients
new_q_input = tf.concat([state, new_action], 1)
# """ implementation 1 """
# predicted_new_q_value = tf.minimum(self.q_net1(new_q_input),self.q_net2(new_q_input))
""" implementation 2 """
predicted_new_q_value = self.q_net1(new_q_input)
policy_loss = -tf.reduce_mean(predicted_new_q_value)
p_grad = p_tape.gradient(policy_loss, self.policy_net.trainable_weights)
self.policy_optimizer.apply_gradients(zip(p_grad, self.policy_net.trainable_weights))
# Soft update the target nets
self.target_q_net1 = self.target_soft_update(self.q_net1, self.target_q_net1, soft_tau)
self.target_q_net2 = self.target_soft_update(self.q_net2, self.target_q_net2, soft_tau)
self.target_policy_net = self.target_soft_update(self.policy_net, self.target_policy_net, soft_tau)
def save(self): # save trained weights
path = os.path.join('model', '_'.join([ALG_NAME, ENV_ID]))
if not os.path.exists(path):
os.makedirs(path)
extend_path = lambda s: os.path.join(path, s)
tl.files.save_npz(self.q_net1.trainable_weights, extend_path('model_q_net1.npz'))
tl.files.save_npz(self.q_net2.trainable_weights, extend_path('model_q_net2.npz'))
tl.files.save_npz(self.target_q_net1.trainable_weights, extend_path('model_target_q_net1.npz'))
tl.files.save_npz(self.target_q_net2.trainable_weights, extend_path('model_target_q_net2.npz'))
tl.files.save_npz(self.policy_net.trainable_weights, extend_path('model_policy_net.npz'))
tl.files.save_npz(self.target_policy_net.trainable_weights, extend_path('model_target_policy_net.npz'))
def load(self): # load trained weights
path = os.path.join('model', '_'.join([ALG_NAME, ENV_ID]))
extend_path = lambda s: os.path.join(path, s)
tl.files.load_and_assign_npz(extend_path('model_q_net1.npz'), self.q_net1)
tl.files.load_and_assign_npz(extend_path('model_q_net2.npz'), self.q_net2)
tl.files.load_and_assign_npz(extend_path('model_target_q_net1.npz'), self.target_q_net1)
tl.files.load_and_assign_npz(extend_path('model_target_q_net2.npz'), self.target_q_net2)
tl.files.load_and_assign_npz(extend_path('model_policy_net.npz'), self.policy_net)
tl.files.load_and_assign_npz(extend_path('model_target_policy_net.npz'), self.target_policy_net)