【评价指标】分割、检测网络评价指标(待补完)
参考:
深度学习图像语义分割常见评价指标详解(原创: gloomyfish/OpenCV学堂)
FP,FN,TP,TN与精确率(Precision),召回率(Recall),准确率(Accuracy)
TP、TN、FP、FN、Recall、Miss Rate、MCC、F1 Score 等指标计算
0. 基本
对于二分类问题,模型的输出不外乎以下4种情况:
TP(true positives)数据:
模型输出结果正确(True);输入数据类别实际为正实例(postives),模型判断数据类型为正实例(postives)。
TP(true negtives)数据:
模型输出结果正确(True);输入数据类别实际为负实例(negtives),模型判断数据类型为负实例(negtives)。
FP(false positives)数据:
模型输出结果错误(False);输入数据类别实际为负实例(negtives),模型判断数据类型为正实例(postives)。
FN(false negtives)数据:
模型输出结果错误(False);输入数据类别实际为正实例(positives),模型判断数据类型为负实例(negtives)。
因此,在模型的测试结果中:
1. 数据总数:TP + TN + FP + FN;
2. 模型判断正确的数据:TP + TN(均为true);
3. 正实例数据的数量:TP + FN ;(本为正例,判为正例 + 本为正例,判为负例);
4. 负实例数据的数量:TN + FP;(本为负例,判为负例 + 本为负例,判为正例);
1. 语义分割网络
1.1 执行时间
1.2 内存占用
1.3 精度(Accuracy)
假设总计有k+1分类(标记为L0到Lk,其中包含一个背景类别)。
对于多类别分类(分割也是一种),则可以视为一种二分类:即分为当前类别i 以及其他类别(对所有类别进行循环,即可完成逐个二分类的TP/FP/FN计算)。
Pij表示类别为i的像素被预测为类别为j的数目,则有:
Pii:表示TP(true positives),实际为类别i,模型输出判断也为类别i(只要分对了就是True,也不存在什么正实例负实例);
Pij:表示FP(false positives),Pij表示类别为i的像素被预测为类别为j的数目;(称为FN或许更合适?)
Pji:表示FN(false negatives),Pji表示类别为j的像素被预测为类别为i的数目;(称为FP或许更合适?)
因此,对于类别i,类别i对应的实际像素数目应为:TP + FP
1.3.1 像素精度(Pixel Accuracy:PA)
最简单的度量计算,总的像素跟预测正确像素的比率:
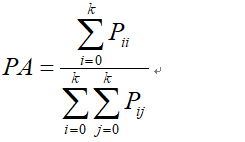
1.3.2 平均像素精度(Mean Pixel Accuracy:MPA)
基于每个类别正确的像素总数与每个类别像素总数比率求和得到的均值:

1.4 IOU(Intersection over Union)
1) 平均交并比(MIoU)
IoU是基于每个类别(一共k类,i表示当前类)计算,然后再求均值。公式如下:
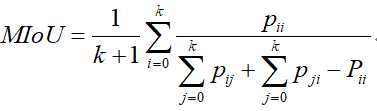
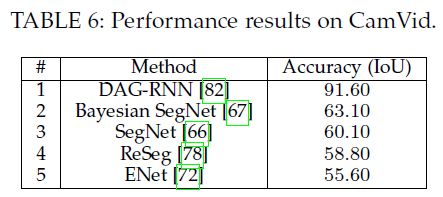
上述四种精度计算方法,MIoU是各种基准数据集最常用的标准之一,绝大数的图像语义分割论文中模型评估比较都以此作为主要技术指标。常见如下:

2)频率权重交并比(FWIoU)
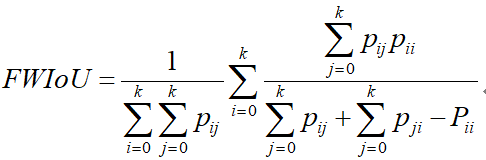
2. 检测网络
2.1 准确率(Accuracy)
最直观的评价标准,模型判断正确的数据(TP+TN)占总数据的比例。
模型判断正确的数据:TP + TN(对于二分类)。如果是多分类的话,个人感觉一个TP就够了,或者是某一类的TP,对其求和。
![]()
个人认为精确率和准确率都需要和具体类别进行对应才有意义。
精确率和准确率的分子相同:就是某一类检测对的数据;
分母不同:
精确率的分母为模型输出某一类数据的数量(这些数据里面还包括了误检的数量,因此精确率可以体现某一类数据检测结果输出的精确程度(等于白说),也就是说精确率越高,某一类的检测结果就越好,其占该类所有检测结果(TP)的比例越高,该类的错误检测结果比例(FP)就越少);
召回率的分母为实际的某一类数据在该数据集中的数量,所以召回率也可以叫查全率(表示这一类数据是否查找的全)。
一般来说,召回率和精确率并不能保证都很高。
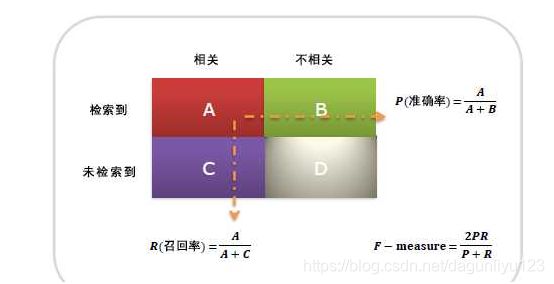
2.2 召回率(Recall)
针对某一类别的分析才有意义,说召回率的话应该指的是判断这一类数据时的召回率;
针对数据中某一类/正实例,如对第i类/正实例的所有数据而言,模型能正确判断出的第i类/正实例数据数量:TP,占数据集中第i类数量的比例。
FN为模型判断错误,但实际上是第i类/正实例的数量,因此数据中第i类/正实例的数量为:TP + FN。
![]()
召回率也叫查全率,以物体检测(有物体+背景二分类)为例,我们往往把图片中的物体作为正例,此时召回率高代表着模型可以找出图片中更多的物体!
2.3 精确率(Precision)
如第i类,模型能判断出的所有第i类/正实例的数据数量为:TP + FP。(正确判断出是第i类/正实例,以及误判为第i类/正实例)
其中能真正为第i类/正实例的数据数量为:TP。则精确率:
![]()
还是以物体检测为例(有物体+背景二分类),精确率高表示模型检测出的物体中大部分确实是物体,只有少量不是物体的对象被当成物体
区分好召回率和精确率的关键在于:针对的数据不同,召回率针对的是数据集中的所有正例,精确率针对的是模型判断出的所有正例
3. Others
3.1 ROC曲线
精确率与召回率,RoC曲线与PR曲线
精确率、召回率、准确率与ROC曲线
如何理解机器学习和统计中的AUC?
nice:Charles's Homepage(github):机器学习性能评估指标