计网第三章笔记----传输层
文章整理自西安交通大学软件学院朱利老师的课堂讲解,仅供复习参考使用,请勿转载
文章目录
- 传输层服务
-
- 复用和解复用
- UDP
-
- 特征
- 典型应用
- UDP段格式
-
- checksum
- TCP
-
- 四个技术
- 特征
- TCP段格式
- 1/4 可靠性控制算法
-
- TCP的确认号和段序号
- 算法
- 快速重传
- 伪代码描述发送端TCP可靠性控制算法
- 接收端确认产生算法
- 2/4流量控制
- 计时器间隔设置
-
- 方法:使用实际测量的RTT值
- 3/4 TCP连接管理
-
- TCP连接建立
- TCP连接关闭
- 4/4 拥塞控制
-
- 情况一:假设缓存无限大
- 情况二:有限缓存
- 情况三:多个路由器
- ATM针对ABR的拥塞控制
- TCP拥塞控制
-
- 两个重要变量:
- 慢启动的伪代码
- Tahoe算法
- Reno算法
- 有限机描述
- 平均窗口大小
- AIMD算法
传输层服务
- 为运行在不同主机上的应用进程提供逻辑通信
- 提供复用/解复用服务
- 可靠性的控制:检错、丢包重传
TCP,UDP:
-
这两个协议都不能保证实时性和可用带宽
-
都使用错误检查方法,但UDP并不会校正
-
UDP协议几乎与下一层的IP协议是一样的,都是尽力而为,所以UDP的段有时候会叫数据报
复用和解复用
**解复用:**将接受到的段传输给正确的应用层进程(依据端口号,所以不会送错)
**复用:**从多个应用层进程收集数据,用标头封装数据以创建段,并将段传递给IP层
复用和解复用都基于源IP地址,源端口号,目的IP地址,目的端口号
用户使用的端口号最好在1024-65525(16位二进制)
通常,应用程序的端口号可以动态分配,服务器端的端口号通常需要指定
每个客户端程序都通过端口号指向服务器上的一个套接字
UDP
User Datagram Protocol,用户报协议
功能
- 复用和解复用
- 差错检查,但不校正,均送到应用层
- 传输:应用层几乎直接与IP层交互
IP协议提供的是best effort服务,UDP提供的也是best effort服务
UDP的段与段之间是没有关系的,TCP的段与段之间是有依赖关系的
不需要握手,不需要建立连接,不需要开辟缓存
特征
要记一下
- 比较简单
- 段头小(8个字节),small segment header,源、目的端口号就占了四个字节
- 速度比较快:相比TCP来说速度更快一点
典型应用
- NFS,远程文件服务器
- Streaming multimedia,流媒体,典型的是音频视频
- Internet telephony,Internet电话
- Network management,使用的应用层协议是SNMP(简单网络管理协议),一般在局域网使用,对时间要求比较高,所以下一层使用的是UDP
- Routing information protocol(RIP)路由信息协议
- Name translation(DNS)
- Multicasting,多波通信
- Real-time involved apps(RTP),对实时性要求很高
- TFTP,简单FTP
- DHCP,是工作在应用层的协议,自动获取IP地址
UDP段格式
八个字节的头
- 源端口号 2个字节
- 目的端口号 2个字节
- 长度(包括头的总长度)
- checksum:校验核,是一种差错的检测算法
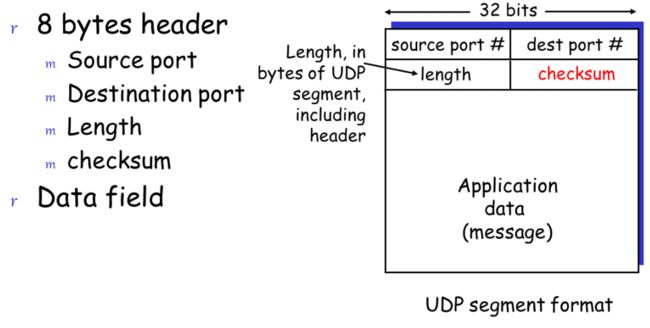
checksum
检测发送的段中有没有位出现错误
只检测,不校正,所以这个字段没什么用
过程:
- 发送端将所有的信息分成若干个16位的组,然后加起来得到一个16位数(溢出的丢掉),然后按位取反得到校验核
- 接收端把得到的所有的信息也分成16位的组,加起来然后再加上校验核,如果结果不是全部为1则代表着至少有一位错误
TCP
这里没有讲
Principles of Reliable data transfer,大约40页
四个技术
三控一管
- 连接管理
- 可靠性控制(最具代表性)
- 流量控制
- 拥塞控制
特征
- 是一个点对点的协议,不支持一点发送,多点接收
- 可靠的、字节有序的、流水式的发送、没有报文的边界
- 通信时先建立连接、开辟缓存、设置变量、交换初始序列号
- 全双工的通信(当然UDP也是全双工的通信)
- MSS:最大的段大小,最大的段大小限制为536字节,如果超过就会封装成两个段,使得传输效率变低
TCP段格式
记一下,考试容易考
段头一共五行,Options不一定有几行,但是从来没用过,一般说的段头都是上面的五行,每行4个字节,一共20个字节
- 源端口号,目的端口号,都是16位的
- 序列号,32位长,$0-(2^{31}-1) $,在通信的时候可以循环使用
- 确认号,32位,接收端返回的信息,期待收到的段序号(ACK)
- head len,头长,4位,可以丢掉
- not used,6位,没有使用
- UAPRSF
- U:一般都是0,urgent(不管是1还是0,一般都是赶紧送),一般不用
- A:A=1是确认段,A=0是数据段
- P:Push,P=1表示是一个紧急的数据,赶紧送给网络层,一般不用
- R:restart,重新建立链接
- S:同步,S=1表示建立链接的一个同步头
- F:finish=1,关闭连接
- receiver window size:16位,接收端的缓存大小还有多少空间,反馈到发送端
- ckecksum:检验核,对UDP没用,对TCP来说也是没用的,但目前还在用
- pointer urgent data:从哪里开始是紧急数据,从来不用

1/4 可靠性控制算法
一定要会
发送端算法+接收端算法
核心:丢包重传(段)
TCP的可靠性是牺牲时间换来的,所以实时性很差
需要把传输层发送的TCP的段在确认接收到之前都放在缓存中存起来,这个缓存需要三个变量来维护
- send_base:指向发送缓存(发送窗口)的最左侧
- Sequence number:下一个序列号
- window size:窗口大小
- 如果Sequence number - send_base = n,则说明缓冲区已经满了
- 绿色:已经确认收到
- 黄色:已经发出去,但不确认是否已经收到
- 蓝色:还有这么多空间的可以发

如何确认段是否丢了:
- 收到接收端的丢失信息(收到三次一样的ACK确认段)轻度拥塞
- 计时器超时 重度拥塞
如何确认哪个段丢了:通过段头的确认号:acknowledgement number
累积确认:返回的确认段是期待的段序号
- rcv_base:期待的段的段序号
- window size:窗口大小
- 灰色:期待收到的段,没收到的
- 红色:已经收到的段,rcv_base指到时才送给应用层,不然会发生乱序
- 蓝色:还没有用的段
接收端始终对期待的段进行确认

TCP的可靠性:没丢,没错,没乱
TCP的确认号和段序号
第一个段的段序号是随机选的,0-65535之间的整型值
后一个段的段序号等于前一个段的段序号加数据域的长度(单位:字节),不是加1
如果收到比期待的段序号高的段会缓存起来,留着以后使用

算法
使用有限状态机(FSM)来描述可靠性控制算法
是一个简化的可靠性控制算法,先考虑半双工,发送端只发送,接收端确认,不考虑流量和拥塞控制
上面表示条件,下面表示动作

最左侧的虚线箭头表示开始,此时 send_base = nextseqnum = initial_sequence number
顺时针方向依次介绍各事件:
- 条件:从应用层接收到了数据;动作:①检查发送窗口满不满 ②创建、发送段 ③启动计时器
- 条件:计时器超时;动作:①哪个段超时,重传哪个段 ②重新计算超时间隔 ③重启计时器
- 条件:收到了3个相同的ACK确认段(大概率丢了);动作:快速重传(超时之前重传)②重启计时器
- 条件:y之前所有的段都收到了;动作:整个窗口右移,send_base指向y TCP是滑动窗口协议
快速重传
主机A发送x1,接收端接收之后返回想要接收x2,然后主机A发送x2,但是在x2到达之前x3x4x5已经到达了,并且在x3x4x5已经返回主机A了,x2还没有收到,这时候主机A收到三个重复的ACK信号,这时候哪怕还没有超时也会重传x2(此时x2大概率丢掉了)

伪代码描述发送端TCP可靠性控制算法
需要背
sendbase和nextseqnum开始时候是重合的,表示缓冲区是空的
第一个event,这里少了一句,检查窗口满不满,不满才发,满了就拒绝发送,一定要加!,如果没满,就创建一个段,每发一个段就要启动一个计时器,计时器的值可以是一个RTT,启动之后把这个段传送到IP层,然后修改nextseqnum的指向
第二个event,计时器超时
发出去了但是确认信息没回来,这时候超时了,此时要重传,这里需要重新计算计时器的超时间隔(是一个新的小算法),重新计时
第三个event,收到了ACK
如果y>sendbase(y是ACK),说明发送窗口内y之前的所有段都已经收到了,此时可以取消段y之前的所有计时器,然后将sendbase指向y
else表示y=sendbase,记接收到y的段序号的计数器+1,如果加到3了,此时直接重传段y,然后重新启动计时器
计时器的初始值为RTT

接收端确认产生算法
没有用有限状态机描述,为了清晰起见,使用表来描述
只有在窗口里面才会返回ACK,在窗口的左边不会返回ACK,更不会送给应用层(在左边表示这个段是重复的)
ACK中的号是期待的段的段序号
- 有序到达一个段,中间没有任何间隙,前面所有的东西都已经确认过了
- 动作:对ACK做了一个延时,等待下一个段(500ms),如果下一个段没来,直接返回
- 这样是为了少返回一个ACK
- 有序到达一个段,没有间隙,但是前面的段正在做500ms的delay
- 动作:立即发送一个ACK,ACK为当前收到的段的下一个段的段序号
- 一切都很完美的情况下最多等待500ms
- 乱序到达,比期待的段序号要高
- 动作:立即发送一个ACK,序号是期待的段的段序号(rcv_base指向的段)
- 到达了一个段 部分或完全的填充了接收端中的gap
- 如果是rcv_base指向的段,就会变成红色,连着身后的红色送给应用层,rcv_base指向下一个非红色(也就是没有收到)的段,并返回rcv_base移动后指向的段序号
- 如果不是rcv_base指向的,则把这个标记为红色的,返回一个ACK,段序号为rcv_base指针指向的段
- 若收到的段序号位于send_base指针的左侧,则忽略(这个是额外加的,教材和ppt没有,上课讲到的)
- 直接丢掉,不用返回ACK
- 原因是ACK返回的途中被路由器丢掉了

这里没考虑500ms的delay
重传情况1,2

重传情况3

2/4流量控制
避免接收端在传输层丢包,控制流量,不要发太快
发送端的发送速度和接收端的接受速度要匹配,尽量一致
RcvWindow(接收窗口):接收缓冲中的空闲空间(与可靠性算法中的接收窗口不同)
RcvBuffer(接收缓存):TCP接收缓存的总大小
发送端的发送流量不让接受窗口变满就不会导致丢包

TCP段头中有个字段表示接收端缓存的空间大小,接收端把当前的RcvWindow发给发送端。
发送的数据量一定小于等于这个空闲的空间
半双工通信:数据可以双向传输,但不能同时进行。 比如集线器就是半双工通信。
全双工通信:数据不仅可以双向传输,并且可以同时进行。 比如交换机就是全双工通信。
-
主机B必须保证:
-
**接收窗口大小 = 接受缓存大小 -(缓存中最后一个字节的编号 - 被读走的最后一个字节的编号):**RcvWindow=RcVBuffer-[LastByteRcvd-LastByteRead]
- RcvWindow:接收窗口,即该接收方还有多少可用的缓存空间
- RcVBuffer:接收缓存的大小
- LastByteRcvd:已放入接收缓存中的数据流的最后一个字节的编号
- LastByteRead:被读走的,应用进程从缓存读出的数据流的最后一个字节的编号
- [LastByteRcvd-LastByteRead]:待在缓存里未送到应用层的数据大小
接收端:显式地通知发送者(动态改变)可用缓冲区空间的数量
-
-
主机A必须保证:
-
LastByteSent-LastByteAcked<=RcvWindow
发送端:主机A已经发送但未被确认的数据量少于最近一次收到的RcvWindow
-
当最近一次收到的RcvWindow=0时,发送端仍然要发送小的段,数据域只有1个字节,(总共21个字节,头是20字节),如果接收端有空间,就会有ACK传回来,就知道目前有多大的剩余空间,哪怕接收端无剩余空间,把这个段丢掉,也会返回一个ACK回来,这样就可以得知目前有多大的空间
有点问题是, t 1 t_1 t1是发送的数据的数据量是根据 t 0 t_0 t0时刻的容量决定的,但是到达接受端的时候是 t 2 t_2 t2时刻,此时(至少经过了一个RTT)已经处理了很多数据,所以发的容量比较实际应发的数据量会少,可以采用预测的方法解决这个小问题

计时器间隔设置
计时器的间隔反映的是未来的网络状况,需要能够与未来网络的繁忙情况匹配
最好比一个RTT大一点
注意:RTT会变化
如果太短一定会超时
如果太长,真的丢包了会导致TCP通信效率会非常低
采用预测算法预测未来的RTT是多大
方法:使用实际测量的RTT值
实际测量的RTT值叫做SampleRTT,通过记录每一次的RTT,然后预测未来的RTT
![]()
RTT的预测值 =(1- α \alpha α)* 曾经的值 + α \alpha α *上一次的实际值
名字:指数性的加权运动平均(也叫低通滤波器),是一个预测公式,比实际的采样值平稳很多
指数体现在 α \alpha α的取值上,典型的 α \alpha α的值是0.125(2的-3次方,可以直接右移计算)
例子:

预测值得到之后还需要加一点余量(safety margin)
预测时间加4倍的偏差值
![]()
偏差值计算:
估算的值与实际的值, β \beta β的取值一般为0.25
偏差值反映网络的忙闲情况,波动大的时候偏差大,波动小的时候偏差小

流量控制的流量也可以使用这个公式计算
3/4 TCP连接管理
TCP连接建立
3次握手
- 客户端发连接请求(TCP的段头),S位为1表示这是一个同步段,把自己选的随机序列号也放进去
- 由于S位为一,接收端就知道这是连接请求,会返回一个ACK,确认号是接收到的序列号+1,段头中的S位也为1
- 返回之后服务器端就会开辟缓存,初始化一些变量
- 客户端对服务器端的ACK进行确认,此时S位为0,序列号为自己的序列号+1,确认号是服务器端返回的序列号+1
- 放回之后客户端也会开辟缓存,初始化一些变量
- 这里数据域可以不为空,向服务器端发出资源请求
本质就是交换初始序列号
有些攻击在发完请求之后就不再回复,服务器一直开辟空间,占用CPU时间,这种叫做半连接攻击(是一种
DoS攻击, deny of service,拒绝服务攻击)(DDos,分布式拒绝服务攻击)

TCP连接关闭
关闭基本上是两次握手
客户端找服务器,然后服务器找客户端
- 发送请求,设置段头中的F位为1
- 服务器发送ACK响应

ppt72页,有限状态机这里不用看
4/4 拥塞控制
Congestion Control
为了缓解路由器的拥塞,从拥塞回到不拥塞,防止其丢包
最好是工作在转发效率高并且队列没有满,这样效率非常高
让其传输的每个数据包都是有效的数据包
这里听明白就行了,不用仔细看
情况一:假设缓存无限大

情况二:有限缓存
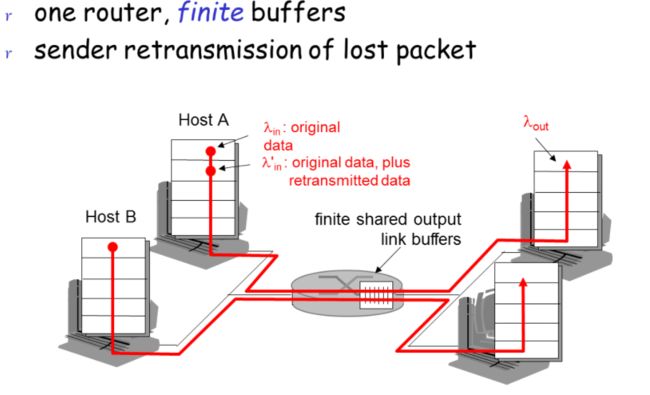

情况三:多个路由器

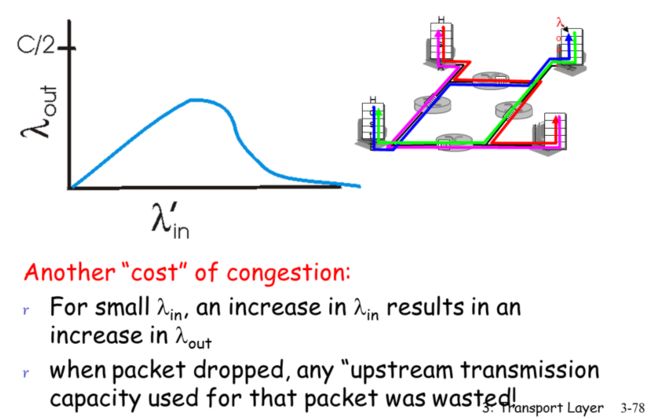
ATM针对ABR的拥塞控制
发送端发现路由器拥塞了则降低发送速率
ATM这里不需要硬记,理解就行
ATM的内核不叫路由器, 叫做ATM交换机,一旦发现拥塞会告诉发送端自己拥塞了,然后发送端会降低发送速率,一段时间后交换机就恢复正常了,这种叫做网络帮助的拥塞控制方法
ATM提供四种业务,四种在开始通信前都要建立一个连接,建立之后发送端和接收端才能通信,路途中的交换机会为他们预留资源,后面三种都不进行拥塞控制
- ABR(avaliable bit rate 有效位率),保证最小带宽,会出现丢包,这种方式需要进行拥塞控制
- CBR(constant bit rate 恒定位率),用于实时语音通信,绝对不丢包
- VBR(variable bit rate 可变位率),用于传输视频,绝对不丢包
- UBR(unspecified 未指定的),有资源就用,没资源就丢掉了
cell:信元,传输实时语音包时总共53个字节,头有5字节,数据部分48个字节,头部有些位用来存放网络拥塞情况
信元分为两种:数据信元和资源管理信元
data cells:数据信元
RM cells:资源管理信元,用来存放一些控制信息,几十个数据信元过后会有一个资源管理信元

CI和NI位,可以认为是轻度拥塞,每32个数据信元中插入一个资源管理信元
- CI: congestion indication,如果拥塞了把CI位置一,表示现在拥塞了
- NI: no increase,告诉发送端不要增加发送速率,保持当前速率即可
ER setting:明确速率设置,交换机根据当前可用带宽在资源管理信元头一个地方(两个字节)明确写上可以使用多少带宽,多个交换机可能都会填值,最后里面存的是最小的值,会返回到发送端,发送端根据这个值去设置速率,即最拥塞的路由器的值
EFCI:明确转发拥塞指示(explicit forward congestion indication),数据信元中的一位,如果拥塞就置1,接收端在一段时间中大部分数据包都被置1,就会派遣一个资源管理信元到发送端,告诉发送端降低发送速率
TCP拥塞控制
一种是拥塞信息直接反馈到发送端;另一种是消息反馈到接收端,接收端再发送给发送端
但是我们的互联网是瘦内核,胖端系统,路由器仅仅保持了最基础的转发功能,剔除了复杂的功能
通过判断是否丢包来判断当前网络状况,无法通过端到端的延时判断,因为这个与实际传输距离有关
- 超时(重度拥塞)
- 收到三个一样的确认段(网络进入轻度拥塞)
这两种情况都会降低发送速率,其他情况都会加快发送速率
建立好连接后不知道是否拥塞,这时候先发一个段尝试一下,如果正常返回来了,则下一次发两个段,如果还正常,就发四个段,每次发送的段以二的倍数增加,经过若干个RTT之后,就不能乘2了,这时候发送窗口就太大了,所以到了一定程度之后,就不再以二得倍数增大,改为每次加一去增大发送窗口
下面两个方法加起来是TCP的拥塞控制方法,称为两阶段法
- 慢启动(slow start),从一个段开始,以二的倍数增加
- 拥塞避免(congestion avoidance),到达1024时,每次都加一,避免网络拥塞
两个重要变量:
threshold:阈值,初始值可以根据经验设定,后面会根据网络的实际情况自动改变
拥塞窗口的大小:开始为1,然后一直乘2,到达阈值之后加1
慢启动的伪代码
每接收到一个ACK之后,自+1,这样每一波发送完了之后都会翻倍
这里的代码都要记住

Tahoe算法
每确认w个段窗口窗口大小才加一,w为上一次窗口大小
如果有丢包发生,则设置阈值为当前窗口大小的一半,并且把窗口的大小改为1,然后跳到慢启动阶段,重新开始
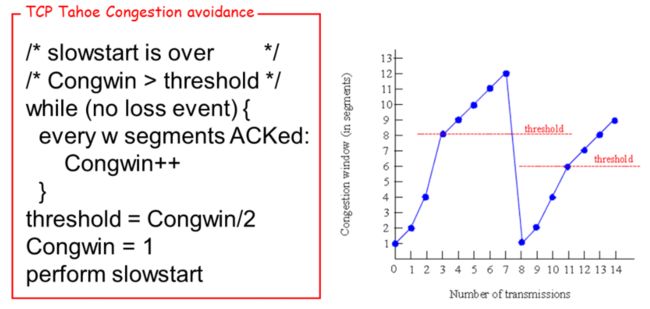
上面这个算法直接全部降到一有点过度了,对于轻度拥塞网络没必要
Reno算法
分为轻度拥塞和重度拥塞
如果是超时造成的丢包,此时是重度拥塞,窗口大小置为1
如果是三次收到重复的ACK,此时是轻度拥塞,窗口大小置为当前大小的一半

有限机描述
只有超时了才会回到慢启动阶段,收到三个重复的ACK时会到快速恢复阶段
还缺个东西没有处理
快速恢复阶段发了之后又收到三个重复的确认段,在图上没有体现出来,应该有一个指向自己的箭头

两种算法的比较,Tahoe算法的吞吐率比Reno算法的吞吐率低,并且震荡更大一点

- 当拥塞窗口小于阈值时候是慢启动阶段,以二的倍数增加
- 当大于阈值时候是线性增
- 收到三个重复的确认段时是轻度拥塞,阈值和窗口都降为当前窗口的一半
- 当发生了超时时,阈值降为窗口的一半,窗口大小置为1个MSS
平均窗口大小
MSS:最大的段大小


AIMD算法
加性增乘性减(线性增指数降)
TCP四个特性,这个必须记下,ppt上面没有
- 有效性(Effectiveness)
- 收敛性(Astringency)
- 公正性(Fairness)
- TCP共享资源时候,每个网络用户使用的带宽大致是一样的
- 如果N个TCP会话共享一个瓶颈链路,最终每个用户得到的资源是1/N
- 友好性(Friendliness)
- 假设上面TCP,下面UDP
- UDP上来就发数据,TCP慢启动线性增
- 如果二者之和相加超过阈值了,二者都会降一半,刚降了就会被UDP占用掉,时间久了之后会导致TCP只能发送一个段
- TCP对UDP友好,资源全给了UDP了

在这个世界上没有绝对的公平