import xml.etree.ElementTree as ET
#1.解析xml文件,返回ElementTree对象
tree = ET.parse('country_data.xml')
#2.获得根节点
root = tree.getroot()
#3.打印根节点标签名
print("coutry_data.xml的根节点:"+root.tag)
#4.打印出根节点的属性和属性值
print("根节点标签里的属性和属性值:"+str(root.attrib))
#5.通过遍历获取孩子节点的标签、属性和属性值
for child in root:
print(child.tag, child.attrib)
#6.获取country标签下的子标签的内容
print("排名:"+root[0][0].text,"国内生产总值:"+root[0][2].text,)
#7.把所有neighbor标签找出来,并打印出标签的属性和属性值。
for neighbor in root.iter('neighbor'):
print(neighbor.attrib)
#8.使用findall()方法把满足条件的标签找出来迭代。
for country in root.findall('country'):
rank = country.find('rank').text
name = country.get('name')
print(name,rank)
(2)对XML文件进行修改操作
import xml.etree.ElementTree as ET
#1.解析xml文件,返回ElementTree对象
tree = ET.parse('country_data.xml')
#2.获得根节点
root = tree.getroot()
#3.遍历修改标签(添加属性和属性值、修改属性值、删除标签)
for rank in root.iter("rank"):
new_rank=int(rank.text)+1
rank.text=str(new_rank)
rank.set("updated","yes")
#4.write()的作用:创建文件,并把xml写入新的文件
#5.指定写入内容的编码
tree.write("output.xml",encoding="utf-8")
>>>修改后的形式
22008141100520115990069201113600
(3)对XML进行删除
import xml.etree.ElementTree as ET
#1.解析xml文件,返回ElementTree对象
tree = ET.parse('country_data.xml')
#2.获得根节点
root = tree.getroot()
#3.通过遍历获得满足条件的元素,并使用remove()指定删除
for country in root.findall('country'):
rank=int(country.find("rank").text)
if rank>50:
root.remove(country)
#4.删除后再把数据保存到output.xml文件中
tree.write("output.xml",encoding="utf-8")
>>>
120081411004201159900
The Kvasir-SEG dataset (size 46.2 MB) contains 1000 polyp images and their corresponding ground truth from the Kvasir Dataset v2. The resolution of the images contained in Kvasir-SEG varies from 332x487 to 1920x1072 pixels. The images and its corresponding masks are stored in two separate folders with the same filename. The image files are encoded using JPEG compression, and online browsing is facilitated. The open-access dataset can be easily downloaded for research and educational purposes.
The bounding box (coordinate points) for the corresponding images are stored in a JSON file. This dataset is designed to push the state of the art solution for the polyp detection task.
GNU General Public License v2.0 - GNU Project - Free Software Foundation
#首先定义一个dicttoxml函数
#!/usr/bin/env python
# coding: utf-8
"""
Converts a Python dictionary or other native data type into a valid XML string.
Supports item (`int`, `float`, `long`, `decimal.Decimal`, `bool`, `str`, `unicode`, `datetime`, `none` and other number-like objects) and collection (`list`, `set`, `tuple` and `dict`, as well as iterable and dict-like objects) data types, with arbitrary nesting for the collections. Items with a `datetime` type are converted to ISO format strings. Items with a `None` type become empty XML elements.
This module works with both Python 2 and 3.
"""
from __future__ import unicode_literals
__version__ = '1.7.4'
version = __version__
from random import randint
import collections
import numbers
import logging
from xml.dom.minidom import parseString
LOG = logging.getLogger("dicttoxml")
# python 3 doesn't have a unicode type
try:
unicode
except:
unicode = str
# python 3 doesn't have a long type
try:
long
except:
long = int
def set_debug(debug=True, filename='dicttoxml.log'):
if debug:
import datetime
print('Debug mode is on. Events are logged at: %s' % (filename))
logging.basicConfig(filename=filename, level=logging.INFO)
LOG.info('\nLogging session starts: %s' % (
str(datetime.datetime.today()))
)
else:
logging.basicConfig(level=logging.WARNING)
print('Debug mode is off.')
def unicode_me(something):
"""Converts strings with non-ASCII characters to unicode for LOG.
Python 3 doesn't have a `unicode()` function, so `unicode()` is an alias
for `str()`, but `str()` doesn't take a second argument, hence this kludge.
"""
try:
return unicode(something, 'utf-8')
except:
return unicode(something)
ids = [] # initialize list of unique ids
def make_id(element, start=100000, end=999999):
"""Returns a random integer"""
return '%s_%s' % (element, randint(start, end))
def get_unique_id(element):
"""Returns a unique id for a given element"""
this_id = make_id(element)
dup = True
while dup:
if this_id not in ids:
dup = False
ids.append(this_id)
else:
this_id = make_id(element)
return ids[-1]
def get_xml_type(val):
"""Returns the data type for the xml type attribute"""
if type(val).__name__ in ('str', 'unicode'):
return 'str'
if type(val).__name__ in ('int', 'long'):
return 'int'
if type(val).__name__ == 'float':
return 'float'
if type(val).__name__ == 'bool':
return 'bool'
if isinstance(val, numbers.Number):
return 'number'
if type(val).__name__ == 'NoneType':
return 'null'
if isinstance(val, dict):
return 'dict'
if isinstance(val, collections.Iterable):
return 'list'
return type(val).__name__
def escape_xml(s):
if type(s) in (str, unicode):
s = unicode_me(s) # avoid UnicodeDecodeError
s = s.replace('&', '&')
s = s.replace('"', '"')
s = s.replace('\'', ''')
s = s.replace('<', '<')
s = s.replace('>', '>')
return s
def make_attrstring(attr):
"""Returns an attribute string in the form key="val" """
attrstring = ' '.join(['%s="%s"' % (k, v) for k, v in attr.items()])
return '%s%s' % (' ' if attrstring != '' else '', attrstring)
def key_is_valid_xml(key):
"""Checks that a key is a valid XML name"""
LOG.info('Inside key_is_valid_xml(). Testing "%s"' % (unicode_me(key)))
test_xml = '<%s>foo' % (key, key)
try:
parseString(test_xml)
return True
except Exception: # minidom does not implement exceptions well
return False
def make_valid_xml_name(key, attr):
"""Tests an XML name and fixes it if invalid"""
LOG.info('Inside make_valid_xml_name(). Testing key "%s" with attr "%s"' % (
unicode_me(key), unicode_me(attr))
)
key = escape_xml(key)
attr = escape_xml(attr)
# pass through if key is already valid
if key_is_valid_xml(key):
return key, attr
# prepend a lowercase n if the key is numeric
if key.isdigit():
return 'n%s' % (key), attr
# replace spaces with underscores if that fixes the problem
if key_is_valid_xml(key.replace(' ', '_')):
return key.replace(' ', '_'), attr
# key is still invalid - move it into a name attribute
attr['name'] = key
key = 'key'
return key, attr
def wrap_cdata(s):
"""Wraps a string into CDATA sections"""
s = unicode_me(s).replace(']]>', ']]]]>')
return ''
def default_item_func(parent):
return 'item'
def convert(obj, ids, attr_type, item_func, cdata, parent='root'):
"""Routes the elements of an object to the right function to convert them
based on their data type"""
LOG.info('Inside convert(). obj type is: "%s", obj="%s"' % (type(obj).__name__, unicode_me(obj)))
item_name = item_func(parent)
if isinstance(obj, numbers.Number) or type(obj) in (str, unicode):
return convert_kv(item_name, obj, attr_type, cdata)
if hasattr(obj, 'isoformat'):
return convert_kv(item_name, obj.isoformat(), attr_type, cdata)
if type(obj) == bool:
return convert_bool(item_name, obj, attr_type, cdata)
if obj is None:
return convert_none(item_name, '', attr_type, cdata)
if isinstance(obj, dict):
return convert_dict(obj, ids, parent, attr_type, item_func, cdata)
if isinstance(obj, collections.Iterable):
return convert_list(obj, ids, parent, attr_type, item_func, cdata)
raise TypeError('Unsupported data type: %s (%s)' % (obj, type(obj).__name__))
def convert_dict(obj, ids, parent, attr_type, item_func, cdata):
"""Converts a dict into an XML string."""
LOG.info('Inside convert_dict(): obj type is: "%s", obj="%s"' % (
type(obj).__name__, unicode_me(obj))
)
output = []
addline = output.append
item_name = item_func(parent)
for key, val in obj.items():
LOG.info('Looping inside convert_dict(): key="%s", val="%s", type(val)="%s"' % (
unicode_me(key), unicode_me(val), type(val).__name__)
)
attr = {} if not ids else {'id': '%s' % (get_unique_id(parent)) }
key, attr = make_valid_xml_name(key, attr)
if isinstance(val, numbers.Number) or type(val) in (str, unicode):
addline(convert_kv(key, val, attr_type, attr, cdata))
elif hasattr(val, 'isoformat'): # datetime
addline(convert_kv(key, val.isoformat(), attr_type, attr, cdata))
elif type(val) == bool:
addline(convert_bool(key, val, attr_type, attr, cdata))
elif isinstance(val, dict):
if attr_type:
attr['type'] = get_xml_type(val)
addline('<%s%s>%s' % (
key, make_attrstring(attr),
convert_dict(val, ids, key, attr_type, item_func, cdata),
key
)
)
elif isinstance(val, collections.Iterable):
if attr_type:
attr['type'] = get_xml_type(val)
addline('<%s%s>%s' % (
key,
make_attrstring(attr),
convert_list(val, ids, key, attr_type, item_func, cdata),
key
)
)
elif val is None:
addline(convert_none(key, val, attr_type, attr, cdata))
else:
raise TypeError('Unsupported data type: %s (%s)' % (
val, type(val).__name__)
)
return ''.join(output)
def convert_list(items, ids, parent, attr_type, item_func, cdata):
"""Converts a list into an XML string."""
LOG.info('Inside convert_list()')
output = []
addline = output.append
item_name = item_func(parent)
if ids:
this_id = get_unique_id(parent)
for i, item in enumerate(items):
LOG.info('Looping inside convert_list(): item="%s", item_name="%s", type="%s"' % (
unicode_me(item), item_name, type(item).__name__)
)
attr = {} if not ids else { 'id': '%s_%s' % (this_id, i+1) }
if isinstance(item, numbers.Number) or type(item) in (str, unicode):
addline(convert_kv(item_name, item, attr_type, attr, cdata))
elif hasattr(item, 'isoformat'): # datetime
addline(convert_kv(item_name, item.isoformat(), attr_type, attr, cdata))
elif type(item) == bool:
addline(convert_bool(item_name, item, attr_type, attr, cdata))
elif isinstance(item, dict):
if not attr_type:
addline('<%s>%s' % (
item_name,
convert_dict(item, ids, parent, attr_type, item_func, cdata),
item_name,
)
)
else:
addline('<%s type="dict">%s' % (
item_name,
convert_dict(item, ids, parent, attr_type, item_func, cdata),
item_name,
)
)
elif isinstance(item, collections.Iterable):
if not attr_type:
addline('<%s %s>%s' % (
item_name, make_attrstring(attr),
convert_list(item, ids, item_name, attr_type, item_func, cdata),
item_name,
)
)
else:
addline('<%s type="list"%s>%s' % (
item_name, make_attrstring(attr),
convert_list(item, ids, item_name, attr_type, item_func, cdata),
item_name,
)
)
elif item is None:
addline(convert_none(item_name, None, attr_type, attr, cdata))
else:
raise TypeError('Unsupported data type: %s (%s)' % (
item, type(item).__name__)
)
return ''.join(output)
def convert_kv(key, val, attr_type, attr={}, cdata=False):
"""Converts a number or string into an XML element"""
LOG.info('Inside convert_kv(): key="%s", val="%s", type(val) is: "%s"' % (
unicode_me(key), unicode_me(val), type(val).__name__)
)
key, attr = make_valid_xml_name(key, attr)
if attr_type:
attr['type'] = get_xml_type(val)
attrstring = make_attrstring(attr)
return '<%s%s>%s' % (
key, attrstring,
wrap_cdata(val) if cdata == True else escape_xml(val),
key
)
def convert_bool(key, val, attr_type, attr={}, cdata=False):
"""Converts a boolean into an XML element"""
LOG.info('Inside convert_bool(): key="%s", val="%s", type(val) is: "%s"' % (
unicode_me(key), unicode_me(val), type(val).__name__)
)
key, attr = make_valid_xml_name(key, attr)
if attr_type:
attr['type'] = get_xml_type(val)
attrstring = make_attrstring(attr)
return '<%s%s>%s' % (key, attrstring, unicode(val).lower(), key)
def convert_none(key, val, attr_type, attr={}, cdata=False):
"""Converts a null value into an XML element"""
LOG.info('Inside convert_none(): key="%s"' % (unicode_me(key)))
key, attr = make_valid_xml_name(key, attr)
if attr_type:
attr['type'] = get_xml_type(val)
attrstring = make_attrstring(attr)
return '<%s%s>' % (key, attrstring, key)
def dicttoxml(obj, root=True, custom_root='root', ids=False, attr_type=True,
item_func=default_item_func, cdata=False):
"""Converts a python object into XML.
Arguments:
- root specifies whether the output is wrapped in an XML root element
Default is True
- custom_root allows you to specify a custom root element.
Default is 'root'
- ids specifies whether elements get unique ids.
Default is False
- attr_type specifies whether elements get a data type attribute.
Default is True
- item_func specifies what function should generate the element name for
items in a list.
Default is 'item'
- cdata specifies whether string values should be wrapped in CDATA sections.
Default is False
"""
LOG.info('Inside dicttoxml(): type(obj) is: "%s", obj="%s"' % (type(obj).__name__, unicode_me(obj)))
output = []
addline = output.append
if root == True:
addline('')
addline('<%s>%s' % (
custom_root,
convert(obj, ids, attr_type, item_func, cdata, parent=custom_root),
custom_root,
)
)
else:
addline(convert(obj, ids, attr_type, item_func, cdata, parent=''))
return ''.join(output).encode('utf-8')
*在调试代码的时候出现了红线,结果发现是使用了中文括号
定义完成后使用下面的代码:
import json
import urllib
import dicttoxml
#page = urllib.urlopen(r'D:\pythonProject1\json\annotation.json')
#print(page)
def load_josn(path):
lines = []
with open(path) as f:
for row in f.readlines():
if row.strip().startswith("//"):
continue
lines.append(row)
return json.loads("\n".join(lines))
if __name__ == "__main__":
obj = load_josn(r"D:\pythonProject1\json\annotation.json")
#print(obj)
xml = dicttoxml.dicttoxml(obj)
print(xml)
quandyfactory/dicttoxml: Simple library to convert a Python dictionary or other native data type into a valid XML string. (github.com)https://github.com/quandyfactory/dicttoxml
我们都晓得java实现线程2种方式,一个是继承Thread,另一个是实现Runnable。
模拟窗口买票,第一例子继承thread,代码如下
package thread;
public class ThreadTest {
public static void main(String[] args) {
Thread1 t1 = new Thread1(
#include<iostream>
using namespace std;
//辅助函数,交换两数之值
template<class T>
void mySwap(T &x, T &y){
T temp = x;
x = y;
y = temp;
}
const int size = 10;
//一、用直接插入排
对日期类型的数据进行序列化和反序列化时,需要考虑如下问题:
1. 序列化时,Date对象序列化的字符串日期格式如何
2. 反序列化时,把日期字符串序列化为Date对象,也需要考虑日期格式问题
3. Date A -> str -> Date B,A和B对象是否equals
默认序列化和反序列化
import com
1. DStream的类说明文档:
/**
* A Discretized Stream (DStream), the basic abstraction in Spark Streaming, is a continuous
* sequence of RDDs (of the same type) representing a continuous st
ReplayingDecoder是FrameDecoder的子类,不熟悉FrameDecoder的,可以先看看
http://bylijinnan.iteye.com/blog/1982618
API说,ReplayingDecoder简化了操作,比如:
FrameDecoder在decode时,需要判断数据是否接收完全:
public class IntegerH
1.js中用正则表达式 过滤特殊字符, 校验所有输入域是否含有特殊符号function stripscript(s) { var pattern = new RegExp("[`~!@#$^&*()=|{}':;',\\[\\].<>/?~!@#¥……&*()——|{}【】‘;:”“'。,、?]"
经常在写shell脚本时,会碰到要以另外一个用户来执行相关命令,其方法简单记下:
1、执行单个命令:su - user -c "command"
如:下面命令是以test用户在/data目录下创建test123目录
[root@slave19 /data]# su - test -c "mkdir /data/test123"
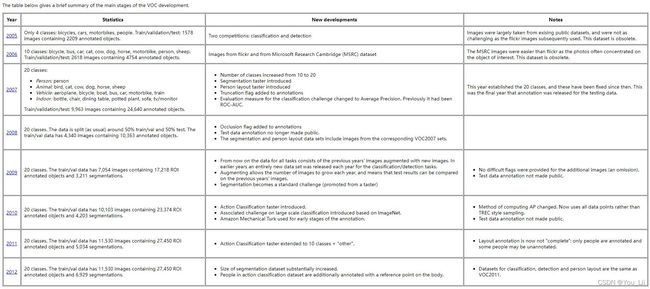
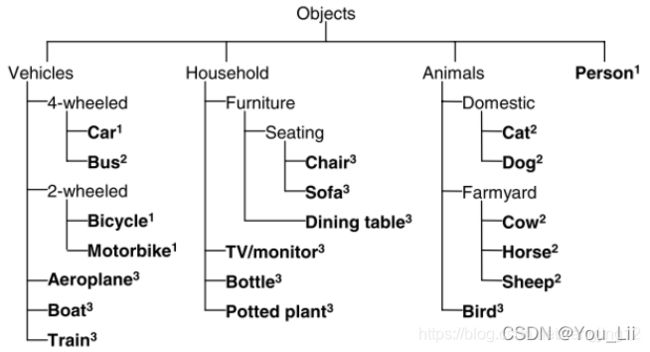

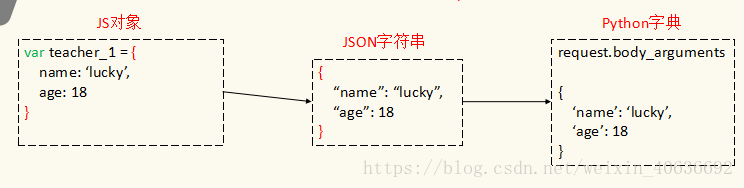

 https://blog.csdn.net/weixin_42782150/article/details/106219001
https://blog.csdn.net/weixin_42782150/article/details/106219001