OCR所涉及的技术
OCR也叫作光学字符识别,主要用到了CNN来提取特征以及RNN来对序列进行分析相关性,这两者后来就结合而成了CRNN。然后还用CTC(Connectionist temporal classification)作为损失函数来解决对齐问题。
CNN简介
卷积神经网络里有一个概念叫做感受野。感受野是用来表示网络内部不同神经元对图像的感受范围,也就是在CNN中表示原图的区域大小,那是因为CNN关注局部像素的相关性比较强,而较远像素的相关性则比较弱,所以神经元的感受野越大,说明它能感受到全图的范围就越大,越小则说明它越关注局部和细节。随着层数的增多,深度神经网络可以提取比较复杂的图像特征。
RNN简介
RNN也叫循环神经网络,和CNN不同,RNN是一种以序列数据(比如一篇文章、一个人人说的话)为输入,然后在输出的方向上不断地递归往回循环。所以,RNN对那些具有序列特性的数据非常有效,比方说时间顺序,逻辑顺序,RNN都能挖掘其中的时序信息以及语义信息。
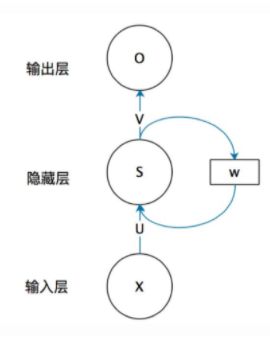
RNN与CNN的区别
那RNN和CNN有什么区别呢?CNN的主要应用是图片的特征提取、识别、分类;而RNN的主要应用是文本生成、情感分析、机器翻译等。
不同数据在CNN中的输出是相互独立的,比如图片分类中,人,狗,猫这些都是分开的;而在RNN中,因为输入的序列,也就是输入的内容上下文之间是有联系的,输出会依赖于之前的输入。我们也可以理解为当前时刻的输出是通过上一时刻的记忆以及当前时刻所共同决定的,即拥有记忆功能。
RNN结构与原理:
我们刚刚说了在t时刻RNN的输出是依赖于(t-1)时刻的,如下图表示:
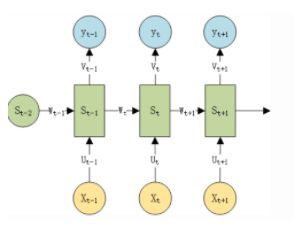
其中Ut−1、Ut、Ut+1Ut−1、Ut、Ut+1三者是同一个值,只是按着时刻称呼不一样而已,对应的W和V也是一样。
所对应的前向传播公式和对应的每个时刻的输出公式如下:

双向RNN
因为RNN是单向的,如果我们想要进行双向的传递就要使用另外的网络——双向RNN。在双向RNN中,假设当前t的输出不仅仅和之前的序列有关,并且还与之后的序列有关。那么,双向RNN通过增加从后往前传递信息的隐藏层来更灵活地处理这类信息。例如:预测一个语句中缺失的词语那么需要根据上下文进行预测;双向RNN是一个相对简单的RNN变形,由两个RNN上下叠加在一起组成,它的输出由这两个RNN的隐藏层的状态决定。
梯度消失与梯度爆炸
由于RNN受到短期记忆的影响,如果序列很长的话,RNN就难以将信息从较前发生的地方传送到较后的地方,就好比一个人讲了很长时间,你就可能忘记他开头讲了什么。这样的话,就存在梯度消失的问题了,那么在反向传播的时候,RNN传播的梯度就会越来越小,网络也就逐渐无法学习。
这就是梯度消失。
但是如果权重W太大,随着序列地传递,那么就存在着长期的依赖关系,就可能造成梯度爆炸而不是梯度消失了。当然权重过小的时候,也会出现梯度消失。
以上所说的梯度消失与梯度爆炸就和(0.010.8)的50次方趋近于零,而(990.8)的50次方将会很大是一样的道理。
激活函数和归一化操作
RNN一般是使用tanh来当做激活函数,tanh在特征相差比较明显的时候效果会很好,在循环的过程中会不断地扩大特征效果。并且它是饱和函数,即在函数的两端梯度变化是很小的,而在中心区域,梯度变化就比较敏感。所以,我们也会使用归一化的操作让数据集中在敏感的区域,让特征变化更加明显。
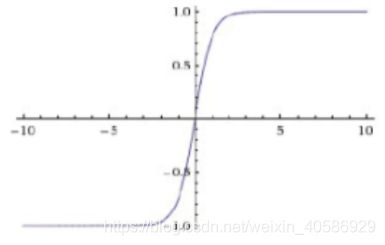
传统的处理方法为:
a.去均化:将输入的数据减去他们的均值,将各个维度的中心归零。
(x-min )/ max - min
b.归一化:将各个维度的幅度归一化到一定的范围内。
(x - mean ) / var
此外,标准化后的数据在0-1范围,不会造成像上一层的数值大小为255,而这一层却仅仅为15这样小的结果,从而造成数据相差过大的现象(因为这样产生的数据差别过大现象会造成梯度爆炸,从而使训练失效)。这样一来,因为数据都已经固定在一定的范围内了,所以也可以允许网络使用较大的学习率,来加快收敛的速度。
需要注意的是:虽然BN层可以使梯度传递的更加流畅,但是随着网络的加深,模型训练速度会变慢。
LSTM与GRU
上述说了,当数据越来越长的时候,RNN会忘记它在较长序列中看到的内容,因此只有短期记忆。所以这时就LSTM和GRU就应运而生了。现有的基于RNN的几乎所有技术结果都是通过LSTM和GRU这两个网络实现的。
LSTM也叫长短期记忆,它的出现是为了解决RNN在训练过程中梯度消失的问题。LSTM 中的细胞状态(即长期记忆)仅仅需要进行线性求和运算就可以通过隐藏层,让梯度得以保存并轻松地在网络间移动,而不会衰减。LSTM 还可以使神经网络在记忆最近的信息和很久以前的信息之间进行切换,让数据自己决定哪些信息要保留,哪些要忘记。
LSTM的结构由三部分组成,即输入门,遗忘门,输出门,以及隐藏的记忆细胞(用来记录额外的信息)。
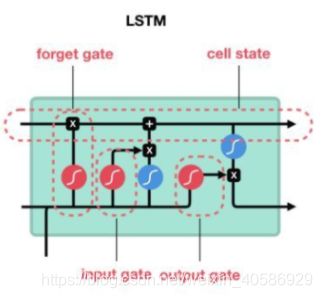
与RNN将所有数据都保存下来传递下去相比,LSTM显现了它的挑选能力,LSTM的这些门可以决定哪一些数据、重要的特征需要保存下来,而哪一些数据需要丢弃,这样就可以将相关的信息传递到较远的神经元结点中了。
上面提到三个门:
1.输入门,在每一时刻从输入层输入的信息会首先经过输入门,输入门的开关会决定这一时刻是否会有信息输入到记忆细胞。
2.输出门,每一时刻是否有信息从记忆细胞输出取决于这一道门。
3.遗忘门,每一时刻记忆细胞里的值都会经历一个是否被遗忘的过程,就是由该门控制的,如果需要遗忘,那么将会把记忆细胞里的值清除。
在LSTM中,除了使用tanh作为激活函数,还使用sigmoid进行激活,但是它的值域不是在-1到1,而是从0到1,这有助于进行更新或者遗忘数据。因为任何数字乘以0都是0,使值消失或者说被“遗忘”,而任何数字乘以1都是相同的值,因此值保持相同。那么这样描述每个部分有多少可以通过。
LSTM工作流程:
第一步就决定细胞需要丢弃哪一些信息,保存哪些信息,这个操作通常是由遗忘门完成的,该层读取当前输入x和前神经元信息h,由sigmoid来决定更新的信息,同时也会丢弃不需要的信息。
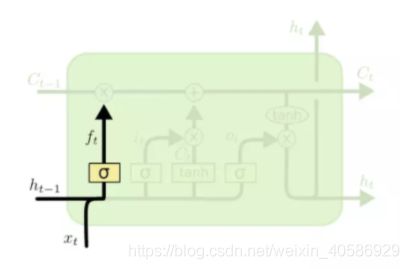
然后会确定细胞状态所存放的新信息,首先通过sigmoid层作为“输入门层”,决定我们将要更新的值i,以及更新的程度,再根据tanh层来创建一个新的候选值向量~Ct加入到状态中。

接下来就是更新旧细胞的状态,我们现在知道了上一层细胞经过遗忘门后的信息,将Ct-1更新为Ct。我们把旧状态与ft相乘,丢弃掉我们确定需要丢弃的信息。接着加上it* ~Ct。这就是新的候选值,根据我们决定更新每个状态的程度进行变化。在语言模型的例子中,这就是我们实际根据前面确定的目标,丢弃旧代词的信息并添加新的信息的地方。

最后一步就是确定输出了,这个输出将会基于我们的细胞状态,但是也是一个过滤后的版本。首先,我们运行一个 sigmoid 层来确定细胞状态的哪些部分会进行输出。接着,我们把细胞状态通过tanh进行处理(得到一个在 -1 到 1 之间的值),并将下一层与sigmoid的输出相乘,最终我们仅仅会输出我们想输出的那部分。
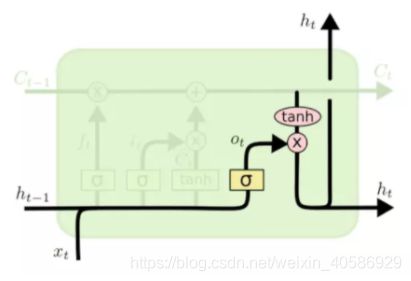
和RNN一样,LSTM 也是单向的,它只使用过去的信息。然而,在基于图像的序列中,两个方向的上下文是相互有用且互补的。将两个LSTM,一个向前和一个向后组合到一个双向LSTM中。此外,可以堆叠多层双向LSTM,深层结构允许比浅层抽象更高层次的抽象。
GRU
所以现在我们知道LSTM是如何工作的,让我们简单地看一下GRU。GRU是新一代RNN,与LSTM非常相似。GRU不使用单元状态,而是使用隐藏状态来传输信息。它也只有两个门,一个重置门和一个更新门。
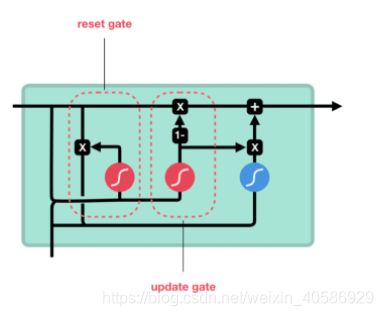
更新门
更新门的作用类似于LSTM的遗忘和输入门。它决定要丢弃哪些信息和要添加哪些新信息。
重置门是另一个用来决定要忘记多少过去的信息的门。
这就是GRU。GRU的张量操作较少;因此,他们的训练速度要比LSTM快一些。但还说不清哪个更好。研究人员和工程师通常都会尝试,以确定哪一个更适合他们的用例。
CRNN
CRNN 全称为 Convolutional Recurrent Neural Network,主要用于端到端地对不定长文本序列进行识别,不用先对单个文字进行切割,而是将文本识别转化为时序依赖的序列学习问题,就是基于图像的序列识别。预测过程中,先使用标准的CNN网络提取文本图像的特征,再利用双向LSTM将特征向量进行融合以提取字符序列的上下文特征,然后得到每列特征的概率分布,最后通过转录层(CTC)进行预测得到文本序列。
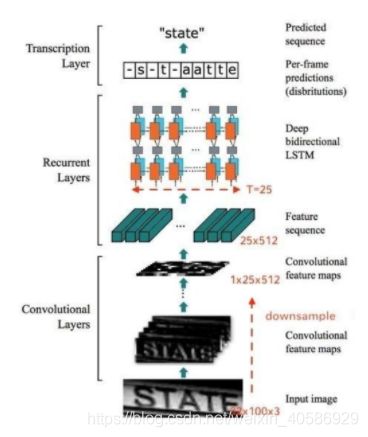
CRNN还引入了BN模块来加速模型的收敛,注意这里池化层的参数:它在高度上的方向上进行了四次的缩小,而在宽度方向上只进行了两次。因为这样的长宽比是比较契合文字的。所以在模型中,图片的输入必须为32的倍数。

文字识别相当于文字的分类,根据分类的思想,比较常见的就是softmax,每一列都会被预测出某个字符,那么训练的时候就需要标注出每一个字符的位置,然后通过CNN感受野来获取这一列标签是什么,来进行特征的对齐。
在实际情况中,标记这种对齐样本非常困难(除了标记字符,还要标记每个字符的位置),工作量非常大。另外,由于每张样本的字符数量不同,字体样式不同,字体大小不同,导致每列输出并不一定能与每个字符一一对应。
当然这种问题同样存在于语音识别领域。例如有人说话快,有人说话慢,那么如何进行语音帧对齐,是一直以来困扰语音识别的巨大难题。
为了解决这一问题,CRNN就引入了CTC。
CTC LOSS
CRNN在转录层中使用到了CTC,CTC,全名叫做Connectionist Temporal Classification,中文叫做连接主义时间分类。因为引入了RNN的原因,所以在识别的时候肯定是存在冗余的现象,比如出现了在连续的位置上出现了重复的字符。当进行预测的时候,除了像abcd这种作为target需要识别的字符外,CTC还考虑到有的位置没有字符,因此引入了空白格的符号。
Pytorch中的CTCLoss接口使用说明
1.获取CTCLoss()对象
ctc_loss = nn.CTCLoss(blank=len(CHARS)-1, reduction=‘mean’)
其中:
blank:空白标签所在的label值,默认为0,需要根据实际的标签定义进行设定;
reduction:处理output losses的方式,string类型,可选’none’ 、 ‘mean’ 及 ‘sum’,'none’表示对output losses不做任何处理,‘mean’ 则对output losses取平均值处理,‘sum’则是对output losses求和处理,默认为’mean’ 。
2.在迭代中调用CTCLoss()对象计算损失值
loss = ctc_loss(log_probs, targets, input_lengths, target_lengths)
log_probs:shape为(T, N, C)的模型输出张量,其中,T表示CTCLoss的输入长度也即输出序列长度,输出序列长度T尽量在模型设计时就要考虑到模型需要预测的最长序列,如需要预测的最长序列其长度为I,则理论上T应大于等于2I+1,这是因为CTCLoss假设在最坏情况下每个真实标签前后都至少有一个空白标签进行隔开以区分重复项,N表示训练的batch size长度,C则表示包含有空白标签的所有要预测的字符集总长度;
log_probs一般需要经过torch.nn.functional.log_softmax处理后再送入到CTCLoss中;
targets:shape为(N, S) 或(sum(target_lengths))的张量,其中第一种类型,N表示训练的batch size长度,S则为标签长度,第二种类型,则为所有标签长度之和,但是需要注意的是targets不能包含有空白标签;
targets建议将其shape设为(sum(target_lengths)),然后再由target_lengths进行输入序列长度指定就好了,这是因为如果设定为(N, S),则因为S的标签长度如果是可变的,那么我们输出出来的二维张量的第一维度的长度仅为min(S)将损失一部分标签值(多维数组每行的长度必须一致),这就导致模型无法预测较长长度的标签,如果扩展标签长度为最长的那一个,这样又会影响标注内容的准确性了;
input_lengths:shape为(N)的张量或元组,但每一个元素的长度必须等于T即输出序列长度,一般来说模型输出序列固定后则该张量或元组的元素值均相同;
target_lengths:shape为(N)的张量或元组,其每一个元素指示每个训练输入序列的标签长度,但标签长度是可以变化的,target_lengths元素数量的不同则表示了标签可变长。
举个例子:
比如我们需要预测的字符集如下,其中’-'表示空白标签:
CHARS = [‘京’, ‘沪’, ‘津’, ‘渝’, ‘冀’, ‘晋’, ‘蒙’, ‘辽’, ‘吉’, ‘黑’, ‘苏’, ‘浙’, ‘皖’, ‘闽’, ‘赣’, ‘鲁’, ‘豫’, ‘鄂’, ‘湘’, ‘粤’,‘桂’, ‘琼’, ‘川’, ‘贵’, ‘云’, ‘藏’, ‘陕’, ‘甘’, ‘青’, ‘宁’,‘新’, ‘0’, ‘1’, ‘2’, ‘3’, ‘4’, ‘5’, ‘6’, ‘7’, ‘8’, ‘9’,‘A’, ‘B’, ‘C’, ‘D’, ‘E’, ‘F’, ‘G’, ‘H’, ‘J’, ‘K’, ‘L’, ‘M’, ‘N’, ‘P’, ‘Q’, ‘R’, ‘S’, ‘T’, ‘U’, ‘V’, ‘W’, ‘X’, ‘Y’, ‘Z’, ‘I’, ‘O’, ‘-’]
因为空白标签所在的位置为len(CHARS)-1,而我们需要处理CTCLoss output losses的方式为‘mean’,则需要按照如下方式初始化CTCLoss类:
ctc_loss = nn.CTCLoss(blank=len(CHARS)-1, reduction=‘mean’)
我们设定输出序列长度T为18,训练批大小N为4且训练数据集仅有4张车牌(为了方便说明)如下,总的字符集长度C如上面CHARS所示为68:
1)log_probs由于数值比较多且为神经网络前向输出结果,我们仅打印其shape出来,如下:
torch.Size([18, 4, 68])
2)打印targets如下,表示这四张车牌的训练标签,根据target_lengths划分标签后可分别表示这四张车牌:
tensor([18, 45, 33, 37, 40, 49, 63, 4, 54, 51, 34, 53, 37, 38, 22, 56, 37, 38,33, 39, 34, 46, 2, 41, 44, 37, 39, 35, 33, 40])
3)打印target_lengths如下,每个元素分别指定了按序取targets多少个元素来表示一个车牌即标签:(7, 7, 8, 8)
我们划分targets后得到如下标签:
18, 45, 33, 37, 40, 49, 63 -->> 车牌 “湘E269JY”
4, 54, 51, 34, 53, 37, 38 -->> 车牌 “冀PL3N67”
22, 56, 37, 38,33, 39, 34, 46 -->> 车牌 “川R67283F”
2, 41, 44, 37, 39, 35, 33, 40 -->> 车牌 “津AD68429”
CTC的思想
CTC loss本质上使所有路径的概率和最大。

这是什么意思呢?相同的文本标签可以有多个不同的字符对齐组合,例如映射为“aa-b”和“aabb”以及“-abb”都代表相同的文本(“ab”),但是与图像的对齐方式不同。更总结地说,一个文本标签存在一条或多条的路径。比方说我们识别到了图片中的文字为: helllllo,可是我们知道实际上这个预测结果是错误的,因为出现了冗余的信息,因为现实生活中出现hello的概率比较大,这是ctc根据梯度修改LSTM中的权重,最后将其改为hello。这个解码过程是首先对字符序列删除连续重复的字符,然后删除所有的空白字符。
