Mediapipe入门——搭建姿态检测模型并实时输出人体关节点3d坐标
一. 引言
MediaPipe 是一款由 Google Research 开发并开源的多媒体机器学习模型应用框架。在谷歌,一系列重要产品,如 YouTube、Google Lens、ARCore、Google Home 以及 Nest,都已深度整合了 MediaPipe。MediaPipe大有用武之地,可以做物体检测、自拍分割、头发分割、人脸检测、手部检测、运动追踪,等等。基于此可以实现更高级的功能。
二. 怎么做
最近在学校做项目需要用到mediapipe,但网上没有很好的教程,于是根据官方文档自己尝试理解也有一些收获,在这里记录一下。
1.官方文档地址Mediapipe
2.实验环境
I.win10
II. Pycharm2021
III. Python3.8
IV. mediapipe0.89
3.我需要检测人体骨架和手部,那么先构建这样的检测模型。根据官网的例子,mediapipe.solutions下有我们需要的解决方案,来看看。
import mediapipe as mp
mp_holistic = mp.solutions.holistic
help(mp.solutions)
Help on package mediapipe.python.solutions in mediapipe.python:
NAME
mediapipe.python.solutions - MediaPipe Solutions Python API.
PACKAGE CONTENTS
download_utils
drawing_styles
drawing_utils
drawing_utils_test
face_detection
face_detection_test
face_mesh
face_mesh_connections
face_mesh_test
hands
hands_connections
hands_test
holistic
holistic_test
objectron
objectron_test
pose
pose_connections
pose_test
selfie_segmentation
selfie_segmentation_test
以上就是mediapipe提供的解决方案,其中drawing_utils是画图用的,drawing_styles应该是渲染风格,face_detection用于面部检测,face_mesh用于绘人脸面网,hands用于手部检测,holistic是整体的解决方案(包括人脸、骨架、手),pose是识别姿势,objectron用于目标检测,selfie_segmentation是自拍分割。
4. 有了方法,根据官网的例子,先导入必要的包,然后建立模型。
import cv2
import mediapipe as mp
mp_drawing = mp.solutions.drawing_utils #画图是必要的
mp_drawing_styles = mp.solutions.drawing_styles
#选择需要的解决方案,手部检测就mp_hands=mp.solutions.hands,其他类似
mp_holistic = mp.solutions.holistic
5.接着打开摄像头,并建立我们的类。
cap = cv2.VideoCapture(0)
with mp_holistic.Holistic(
min_detection_confidence=0.5,
min_tracking_confidence=0.5) as holistic:
while cap.isOpened():
success, image = cap.read()
if not success:
print("Ignoring empty camera frame.")
# 加载一个视频的话,把continue换成break
continue
先看看mp_holistic.Holistic下有什么参数
Methods defined here:
| __init__(self, static_image_mode=False, model_complexity=1,
smooth_landmarks=True, enable_segmentation=False,
smooth_segmentation=True, refine_face_landmarks=False,
min_detection_confidence=0.5, min_tracking_confidence=0.5)
官网解释如下:
static_image_mode
如果设置为false,则解决方案将输入图像视为视频流。它将尝试在第一张图像中检测最突出的人,并在成功检测后进一步定位姿势和其他地标。在随后的图像中,它只是简单地跟踪那些地标,而不会调用另一个检测,直到它失去跟踪,以减少计算和延迟。如果设置为true,则人物检测会运行每个输入图像,非常适合处理一批静态的、可能不相关的图像。默认为false.
model_complexity
姿势地标模型的复杂度:0,1或2。地标准确性以及推理延迟通常随模型复杂性而增加。默认为1.
smooth_landmarks
如果设置为true,解决方案过滤器会在不同的输入图像之间设置地标以减少抖动,但如果static_image_mode也设置为,则忽略true。默认为true.
enable_segmentation
如果设置为true,除了姿势、面部和手部地标之外,该解决方案还会生成分割掩码。默认为false.
smooth_segmentation
如果设置为true,该解决方案会过滤不同输入图像的分割掩码以减少抖动。如果enable_segmentation为false或static_image_mode为 ,则忽略true。默认为true.
refine_face_landmarks
是否进一步细化眼睛和嘴唇周围的地标坐标,并在虹膜周围输出额外的地标。默认为false.
min_detection_confidence
[0.0, 1.0]来自人员检测模型的最小置信值 ( ),用于将检测视为成功。默认为0.5.
min_tracking_confidence
[0.0, 1.0]来自地标跟踪模型的最小置信值(将其设置为更高的值可以提高解决方案的稳健性,但代价是更高的延迟。如果static_image_mode是true,则忽略,其中人员检测仅在每个图像上运行。默认为0.5.
6.有了这些解释,就比较好理解了。然后对输入的视频流做一些预处理。
image.flags.writeable = False
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) #BGR图转RGB
results = holistic.process(image) #处理三通道彩色图
image.flags.writeable = True
image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR) #RGB转BGR
比较重要的是这一步results = holistic.process(image),前面建立了整体检测的类,类下方法process()会处理图片并返回我们要的坐标,来help看一看。
Help on function process in module mediapipe.python.solutions.holistic:
process(self, image: numpy.ndarray) -> <class 'NamedTuple'>
Processes an RGB image and returns the pose landmarks, left and right hand landmarks, and face landmarks on the most prominent person detected.
Args:
image: An RGB image represented as a numpy ndarray.
Raises:
RuntimeError: If the underlying graph throws any error.
ValueError: If the input image is not three channel RGB.
Returns:
A NamedTuple with fields describing the landmarks on the most prominate
person detected:
1) "pose_landmarks" field that contains the pose landmarks.
2) "pose_world_landmarks" field that contains the pose landmarks in
real-world 3D coordinates that are in meters with the origin at the
center between hips.
3) "left_hand_landmarks" field that contains the left-hand landmarks.
4) "right_hand_landmarks" field that contains the right-hand landmarks.
5) "face_landmarks" field that contains the face landmarks.
6) "segmentation_mask" field that contains the segmentation mask if
"enable_segmentation" is set to true.
7.可以看到Returns下左右手、姿势、脸部的地标都能返回,待会我就从这获取坐标。处理完图片,就需要在人体关节点上渲染。
#在关节点渲染
mp_drawing.draw_landmarks(
image,
results.face_landmarks, #画脸
mp_holistic.FACEMESH_CONTOURS,
landmark_drawing_spec=None,
connection_drawing_spec=mp_drawing_styles
.get_default_face_mesh_contours_style())
mp_drawing.draw_landmarks(
image,
results.pose_landmarks, #画人体骨架
mp_holistic.POSE_CONNECTIONS,
landmark_drawing_spec=mp_drawing_styles
.get_default_pose_landmarks_style())
#下两行是我加的,官网的例子并没有画左右手
mp_drawing.draw_landmarks(image, results.left_hand_landmarks, mp_holistic.HAND_CONNECTIONS)
mp_drawing.draw_landmarks(image, results.right_hand_landmarks, mp_holistic.HAND_CONNECTIONS)
前面mp_drawing=mp.solutions.drawing_utils,draw_landmarks()参数比较多,我挑几个重要的翻译出来。
draw_landmarks参数:
image:表示为 numpy ndarray 的三通道 RGB 图像。
地标列表:要在其上注释的规范化地标列表原始消息
图片。
connections:地标索引元组列表,指定地标如何
在图中连接。
Landmark_drawing_spec:DrawingSpec 对象或来自的映射
将地标传递给指定地标绘图的 DrawingSpecs
颜色、线条粗细和圆半径等设置。
如果此参数明确设置为 None,则不会绘制任何地标。
connection_drawing_spec:DrawingSpec 对象或来自的映射
到 DrawingSpecs 的手连接,它指定了
连接的绘图设置,例如颜色和线条粗细。
如果此参数明确设置为 None,则没有地标连接
被画下来。
8.接下来获取右手的21个节点坐标,如下图,来自官网。

前面说到results = holistic.process(image)返回了结点坐标,现在来获取它。
if results.right_hand_landmarks:
for index, landmarks in enumerate(results.right_hand_landmarks.landmark):
print(index,landmarks )
解释一下,index是索引,即上图里每个手指节点的索引0,1,2,3等等,landmarks 是结点地标(x,y,z),是真实世界的3d坐标,原点位于手的近似几何中心。最后打开窗口,就可以愉快地使用mediapipe了
cv2.imshow('MediaPipe Holistic', cv2.flip(image, 1))
if cv2.waitKey(5) & 0xFF == 27:
break
cap.release()
三. 运行结果
还是挺成功的,只要我右手出现在摄像头里,坐标就会输出,右手放下去就没有输出。
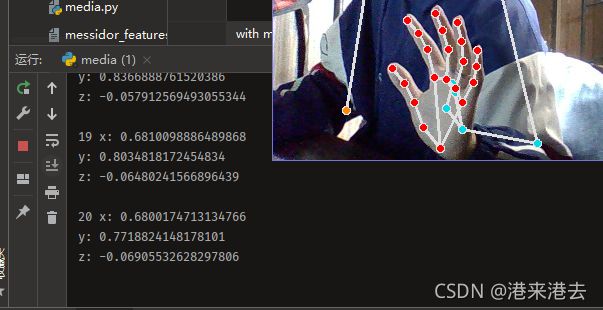
如上图演示结果,19,20是结点索引index,对应上文二. 8 ,坐标是小手指最上面两个坐标。运行起来,会连续地一次性输出21个坐标。再来看看蔡老师的演示结果。

当然,如果想输出左手,甚至是嘴唇、鼻子、肩膀等地的坐标都是可以的。
print(results.pose_landmarks.landmark[mp_holistic.PoseLandmark.NOSE])
#可以自己选择

四. 完整代码
import cv2
import mediapipe as mp
mp_drawing = mp.solutions.drawing_utils
mp_drawing_styles = mp.solutions.drawing_styles
mp_holistic = mp.solutions.holistic
cap = cv2.VideoCapture(0)
with mp_holistic.Holistic(
min_detection_confidence=0.5,
min_tracking_confidence=0.5) as holistic:
while cap.isOpened():
success, image = cap.read()
if not success:
print("Ignoring empty camera frame.")
# If loading a video, use 'break' instead of 'continue'.
continue
image.flags.writeable = False
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
results = holistic.process(image)
#画图
image.flags.writeable = True
image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR)
mp_drawing.draw_landmarks(
image,
results.face_landmarks,
mp_holistic.FACEMESH_CONTOURS,
landmark_drawing_spec=None,
connection_drawing_spec=mp_drawing_styles
.get_default_face_mesh_contours_style())
mp_drawing.draw_landmarks(
image,
results.pose_landmarks,
mp_holistic.POSE_CONNECTIONS,
landmark_drawing_spec=mp_drawing_styles
.get_default_pose_landmarks_style())
mp_drawing.draw_landmarks(image, results.left_hand_landmarks, mp_holistic.HAND_CONNECTIONS)
mp_drawing.draw_landmarks(image, results.right_hand_landmarks, mp_holistic.HAND_CONNECTIONS)
#右手21个节点坐标
if results.right_hand_landmarks:
for index, landmarks in enumerate(results.right_hand_landmarks.landmark):
print(index,landmarks )
#鼻子坐标
#print(results.pose_landmarks.landmark[mp_holistic.PoseLandmark.NOSE])
cv2.imshow('MediaPipe Holistic', cv2.flip(image, 1))
if cv2.waitKey(5) & 0xFF == 27:
break
cap.release()
六. 未完待续,欢迎讨论,赐教