一文搞懂MySQL事务和索引所有知识点
文章目录
- 事务
-
-
- 1.什么是事务
- 2.事务的目的
- 3..事务的基本特性
- 3.1什么是原子性?什么是原子性操作?回滚又是什么?
- 3.2什么是一致性?
- 3.3什么是持久性?
- 3.4什么是隔离性
- 3.5数据库资源并发访问时可能出现的情况问题有?
- 3.6何为脏读?何为不可重复读?何为幻读?
-
-
-
- ✨事务面试题
-
-
- 索引
-
- 1.索引是什么
- 2,索引的优势和劣势
- 3.和索引相关的一些sql
- ✨索引面试题
-
事务
1.什么是事务
数据库的事务是指一组sql语句组成的数据库逻辑处理单元,在这组的sql操作中,要么全部执行成功,要么全部执行失败
举个例子:
A想要从自己的帐户中转1000块钱到B的帐户里。那个从A开始转帐,到转帐结束的这一个过程,称之为一个事务。
2.事务的目的
事务诞生的目的: 为了把若干个独立的操作打包成一个整体
3…事务的基本特性
3.1什么是原子性?什么是原子性操作?回滚又是什么?
举个例子:
A想要从自己的帐户中转1000块钱到B的帐户里。那个从A开始转帐,到转帐结束的这一个过程,称之为一个事务。在这个事务里,要做如下操作:
- 从A的帐户中减去1000块钱。如果A的帐户原来有3000块钱,现在就变成2000块钱了。
- 在B的帐户里加1000块钱。如果B的帐户如果原来有2000块钱,现在则变成3000块钱了。
如果在A的帐户已经减去了1000块钱的时候,忽然发生了意外,比如停电什么的,导致转帐事务意外终止了,而此时B的帐户里还没有增加1000块钱。那么,我们称这个操作失败了,要进行回滚。回滚就是回到事务开始之前的状态,也就是回到A的帐户还没减1000块的状态,B的帐户的原来的状态。此时A的帐户仍然有3000块,B的帐户仍然有2000块。
我们把这种要么一起成功(A帐户成功减少1000,同时B帐户成功增加1000),要么一起失败(A帐户回到原来状态,B帐户也回到原来状态)的操作叫原子性操作。
如果把一个事务可看作是一个程序,它要么完整的被执行,要么完全不执行。这种特性就叫原子性。
3.2什么是一致性?
在事务执行之前,和执行之后,数据库中的数据都是合理合法的,数据库不会因事务执行而遭到破坏
这里相比事务的其他特性而言,有点难以理解,因此我举几个列子方便大家理解.
我们来考虑这样的一个场景:你买一瓶可乐,然后倒了100ml到杯子里面。那么你的杯子里面必然是从原来一滴可乐都没的状态变成装有100ml可乐的状态,而你的可乐瓶子里面必然是少了100ml可乐。这是毋庸置疑的,因为在自然界中,我们必须遵循“质量守恒定律”。
我们再考虑一个场景:你上班挤地铁的时候,口袋里装了1000块现金,不料被小偷偷了300块钱。那么你将损失了300,而小偷收入300,这是必然的。
3.3什么是持久性?
事务一旦提交了之后,数据就会持久化的存储起来,数据写入到硬盘中
3.4什么是隔离性
隔离性是针对数据资源的
并发访问,规定了各个事务之间相互影响的程度。
什么是并发?
并发简单的来说就是 “一心二用”,并发编程是当下最主要的一个编程方式
注意:数据资源并发访问时可能出现的问题有:脏读,幻读,不可重复读
3.5数据库资源并发访问时可能出现的情况问题有?
数据资源并发访问时可能出现的问题有:脏读,幻读,不可重复读
3.6何为脏读?何为不可重复读?何为幻读?
事务的隔离性可以分为4种类型的隔离级别:Read Uncommitted,Read Committed, Repeatable Read和Serilization。这4个类型的隔离级别在应对数据资源并发访问可能出现的问题时的要求不一样。数据资源并发访问时可能出现的问题有:
-
脏读:如果一个事务A对数据进行了更改,但是还没有提交,而另一个事务B就可以读到事务A尚未提交的更新结果。这样,当事务A进行回滚时,那么事务B开始读到的数据就是一笔脏数据。
-
不可重复读:同一个事务在事务过程中,对同一个数据进行读取操作,读取到的结果不同。例如,事务B在事务A的更新操作前读到的数据,跟在事务A提交此更新操作后读到的数据,可能不同。
-
幻读:同样一个查询在整个事务中多次执行,查询所得的结果不同。例如,事务A对全部记录做了更新操作,尚未提交前,事务B又插入了一条记录,那么事务A再次读取数据库时,会发现还有一条记录(即事务B新插入的记录)没有做更新。
也可以理解成:
要避免脏读,需要控制在事务没有提交更新前,其他事务无法看到此事务的更新结果。
要避免幻读,需要将整张表都锁住了。(串化)对于隔离级别:
Read Uncommitted:最低的隔离级别。一个事务可以读取另一个事务没有提交的更新结果。
Read Committed:一个事务的更新操作只有在提交了之后,才会被另一个事务读取到同一笔数据更新后的结果
Repeatable Read:在整个事务中,对同一笔数据的读取结果是相同的,不管其他事务是否同时在对这笔数据进行更新,也不管这笔更新是否提交。
Serilizable:所有的事务操作都必须串行操作。这种隔离级别最高,但是牺牲了系统的并发性。通常会使用其他的隔离级别加上相应的并发锁机制来控制对数据的访问。
✨事务面试题
谈谈对事物的理解
事物是把多个 SQL 打包成 一个,要么就全都执行,要么就都不执行
事物的应用场景,典型就是转账
事物是如何保证要么都执行没要么都不执行机制?核心是回滚
事物的几个基本特性:1.原子性 2.一致性 3.持久性 4.隔离性
索引
1.索引是什么
官方介绍索引是帮助MySQL高效获取数据的数据结构。更通俗的说,数据库索引好比是一本书前面的目录,能加快数据库的查询速度。
一般来说索引本身也很大,不可能全部存储在内存中,因此索引往往是存储在磁盘上的文件中的(可能存储在单独的索引文件中,也可能和数据一起存储在数据文件中)。
我们通常所说的索引,包括聚集索引、覆盖索引、组合索引、前缀索引、唯一索引等,没有特别说明,默认都是使用B+树结构组织(多路搜索树,并不一定是二叉的)的索引。
2,索引的优势和劣势
优势:
1.可以提高数据检索的效率,降低数据库的IO成本,类似于书的目录。
2.通过索引列对数据进行排序,降低数据排序的成本,降低了CPU的消耗。
被索引的列会自动进行排序,包括【单列索引】和【组合索引】,只是组合索引的排序要复杂一些。
如果按照索引列的顺序进行排序,对应order by语句来说,效率就会提高很多。
劣势:
1.索引会占据磁盘空间
2.索引虽然会提高查询效率,但是会降低更新表的效率。比如每次对表进行增删改操作,MySQL不仅要保存数据,还有保存或者更新对应的索引文件。
3.和索引相关的一些sql
1.查看索引
show index from 表名;
查看一个表上都有哪些索引

2.给一个表中的列来创建索引
create index 索引名字 on 表名(列名);

创建索引这件事是一个非常低效的事情,尤其是当前表里面已经有很多数据的时候.
3.删除索引
drop index 索引名字 on 表名;
删除索引和创建索引一样,都是非常低效的事情,容易把数据库搞gua掉!
✨索引面试题
索引背后的数据结构: B+ 树
问题1.除了B+树其他结构行不行?
二叉搜索树(AVL数 红黑树) 不太行,原因: 树的高度太高,导致IO访问次数更多
哈希表 也不太行,原因: 不能支持范围查找,哈希表只针对"相等"进行判断,不能对"大于小于",以及范围查找进行判断
堆 更不适合作为索引 , 堆只能找大小堆
最适合做索引的,还得是树形结构,只不过就不再是二叉树
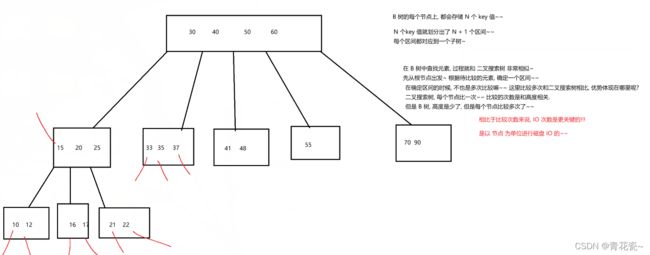
首先我们先来理解一下 B + 树 的前身 B 树(有的资料上也写作 B - 树)
N叉搜索树,每个节点上包含了N个记录,N个记录就分成了N+1个区间,对应N+1个子树,就可以通过这样的方式快速确定要查找的值在那个区间,进一步进行快速筛选
B + 树
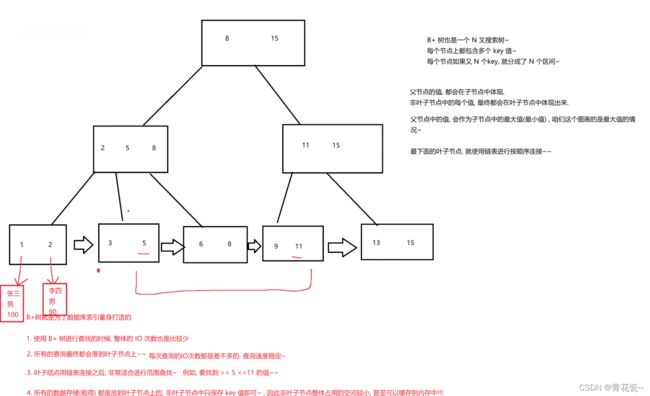
B + 树 又在B树的基础上做出改进
首先,每个节点包含N个key,N个key分成N个区间
其次,每个节点上的值,都会在子节点上体现(子节点上就包含了所有数据的全集)
再次,叶子结点再通过链表的形式进行首位相连
最大的好处:一方面,可以更高效的进行范围查找,另一方面,因为叶子节点是数据的全集,非叶子节点就只保存key即可,占用空间少,可以在内存中缓存,进一步减少了IO次数