Scaled-YOLOv4:CSP网络的缩放
Scaled-YOLOv4: Scaling Cross Stage Partial Network
原文: https://arxiv.org/pdf/2011.08036v1.pdf
项目地址: https://github.com/WongKinYiu/ScaledYOLOv4/tree/yolov4-csp
网络结构在第四节⭐️
手动翻译
文章目录
- Scaled-YOLOv4: Scaling Cross Stage Partial Network
-
- 0.Abstract
- 1.Introduction
- 2.Related work
-
- 2.1 Real-time object detction
- 2.2 Model scaling
- 3.Principles of model scaling
-
- 3.1 General principle of model scaling
- 3.2 Scaling Tiny Models for Low-End Devices
- 3.3 Scaling Large Models for High-End GPUs
- 4.Scaled-YOLOv4
-
- 4.1 CSP-ize YOLOv4
- 4.2 YOLOv4-tiny
- 4.3 YOLOv4-large
- 5.Experiments
-
- ~~pass~~
- 6.Conculsions
-
- ~~pass~~
- 7.Acknowledgements
-
- ~~pass~~

0.Abstract
我们表明,基于CSP方法的YOLOv4目标检测神经网络,在保持最佳速度和精度的前提下,既可以上下扩展,也适用于小型和大型网络。我们提出了一种网络缩放(scaling)方法,不仅修改了网络的深度、宽度、分辨率,还修改了网络的结构。YOLOv4-large模型实现了SOTA。在MS COCO数据集,Tesla V100上15 FPS的速度下,有55.4%的AP(73.3% AP50),而在测试时增强的情况下,YOLOv4-large实现了55.8%的AP(73.2 AP50)。据我们所知,这是目前已发表的工作中,在COCO数据集上的最高精度。YOLOv4-tiny模型在RTX 2080Ti上的速度达到了22.0% AP (42.0% AP50),在RTX 2080Ti上的速度为∼443 FPS,而通过使用TensorRT, b a t c h s i z e = 4 batch \ size=4 batch size=4和FP16精度,YOLOv4-tiny达到了1774 FPS。
1.Introduction
基于深度学习的物体检测技术在我们的日常生活中有很多应用。例如,医疗图像分析、自动驾驶汽车、商业分析、人脸识别等都依赖于目标检测。上述应用所需的计算设备可能是云计算设备、通用GPU、物联网集群,也可能是单个嵌入式设备。为了设计一个有效的对象检测器,模型缩放技术非常重要,因为它可以使目标检测器在各种类型的设备上实现高精度和实时推理。
yolov5也是可以通过配置文件缩放模型大小。
最常见的模型缩放技术是改变骨干的深度(CNN的卷积层数)和宽度(卷积层中卷积核的数量),然后训练适合不同设备的CNN。例如在ResNet系列中,ResNet-152和ResNet-101常用于云服务器GPU,ResNet-50和ResNet-34常用于个人计算机GPU,ResNet-18和ResNet-10可用于低端嵌入式系统中。
在1中,Cai等人尝试开发了只需训练一次就可以应用于各种设备网络架构的技术。他们利用解耦训练和搜索、知识蒸馏等技术,对多个子网进行解耦和训练,使整个网络和子网都能处理目标任务。Tan等2提出利用NAS技术在EfficientNet-B0上进行复合缩放,包括宽度、深度和分辨率的处理。他们利用这个初始网络在给定的计算量下寻找最佳的CNN架构,并将其设为EfficientNet-B1,然后利用线性扩展技术得到EfficientNetB2到EfficientNet-B7等架构。Radosavovic等3人从庞大的参数搜索空间AnyNet中总结并添加约束条件,然后设计了RegNet。在RegNet中,他们发现CNN的最佳深度为60左右。他们还发现当bottleneck ratio设置为1,cross-stage的宽度增加率设置为2.5时将收到最好的性能。 此外,最近还有专门针对物体检测提出的NAS和模型缩放方法,如SpineNet和EfficientDet。
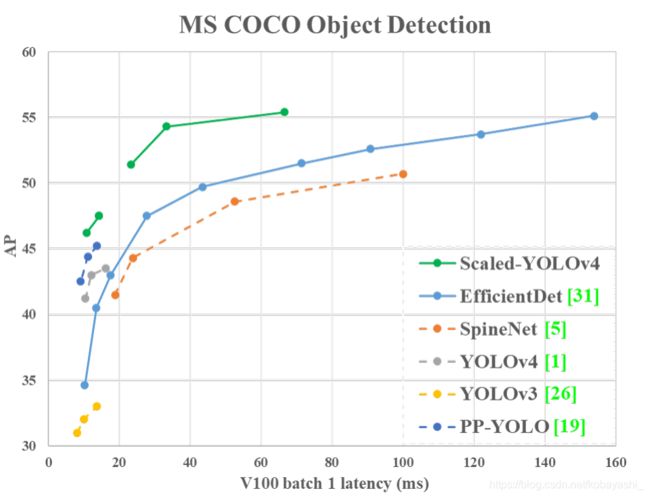
Figure 1:比较提出的YOLOv4和其他最先进的目标检测器。 虚线只表示模型推理的延迟,实线包括模型推理和后处理
通过对最先进的对象检测器的分析,我们发现作为YOLOv4骨干的CSPDarknet53几乎符合所有通过网络架构搜索技术得到的最优框架特征。CSPDarknet53的深度、瓶颈比、级间宽度增长比(bottleneck ratio, width growth ratio between stages )分别为65、1、2。因此,我们在YOLOv4的基础上开发了模型缩放技术,提出了scaled-YOLOv4。如图1所示,所提出的scaled-YOLOv4结果具有优异的性能。scaled-YOLOv4的设计过程如下。首先,我们对YOLOv4进行重新设计,提出YOLOv4-CSP,然后在YOLOv4-CSP的基础上开发出scaled-YOLOv4。在提出的scaled-YOLOv4中,我们讨论了线性放大/缩小模型的上界和下界,并分别分析了小模型和大模型在模型缩放中需要注意的问题。因此,我们能够系统地开发YOLOv4-large和YOLOv4-tiny模型。Scaled-YOLOv4可以实现速度和精度的最佳权衡,能够在15 fps、30 fps和60 fps的电影以及嵌入式系统上进行实时物体检测。
本文的贡献如下:(1)为小模型设计了一种强大的模型缩放方法,它可以系统地平衡浅层CNN地计算成本核内存带宽;(2)设计了一种简单而有效的缩放目标检测器的策略;(3)分析了所有模型缩放因子之间的关系,然后基于最好的组分开进行模型缩放;(4)实验证实了FPN结构是一种一劳永逸(once-for-all)的结构,然后(5)使用上面的方法设计了YOLOv4-tiny和YOLOv4-large。
2.Related work
2.1 Real-time object detction
目标检测器主要分为one-stage检测器和two-stage检测器。one-stage检测器的输出只需要经过一次CNN操作就可以得到结果。对于two-stage目标检测器,它通常将first-stage CNN得到的高得分候选区域输入给second-stage CNN进行最终预测。两种检测器得前向推理时间可以表达成 T o n e = T 1 s t T_{one}=T_{1st} Tone=T1st和 T t w o = T 1 s t + m T 2 n d T_{two}=T_{1st}+mT_{2nd} Ttwo=T1st+mT2nd, m m m是比阈值高得候选区域数量。换句话说,one-stage前向推理时间是常量,而two-stage的前向推理时间不是固定的。
可见,two-stage比one-stage速度慢,但是精度高。
所以,如果我们需要选择实时目标检测器,几乎一定是one-stage的。现有的one-stage目标检测分为两类:anchor-based和anchor-free。在所有的anchor-free方法中,CenterNet4非常流行,因为它不需要复杂的后处理,如NMS。现在,更精确的实时目标检测器是anchor-based EfficientDet,YOLOv4和PP-YOLO。在本文中,我们提出了基于YOLOv4的模型缩放方法。
2.2 Model scaling
传统的模型缩放技术是改变模型的深度,即增加卷积层数。比如, Simonyan等人设计的VGGNet,在不同的阶段堆叠额外的卷积层,并使用同样的概念设计VGG-11,VGG-13,VGG-16和VGG-19。随后的方法通常遵循相同的模型缩放方法。 对于He等人提出的ResNet,深度缩放可以构造非常深的网络,如ResNet-50、ResNet-101和ResNet-152。后来Zagoruyko等人考虑了网络的宽度,并改变了卷积层的核数以实现缩放。 因此,他们设计了wide ResNet(WRN),同时保持相同的精度。 虽然WRN比ResNet具有更高的参数量,但推理速度要快得多。 随后DenseNet和ResNeXt还设计了一个复合缩放版本,将深度和宽度考虑在内。至于图像金字塔推理,是一种在运行时进行增强的常用方法。它将一张输入图像进行各种不同的分辨率缩放,然后将这些不同的金字塔组合输入到一个训练好的CNN中。最后,网络将整合多组输出作为其最终结果。Redmon等人利用上述概念执行输入图像大小缩放。他们使用更高的输入图像分辨率来对训练好的Darknet53进行微调,执行这一步的目的是为了获得更高的精度。
这一段是机翻
最近几年,网络架构搜索(NAS)相关的研究得到了大力发展,NAS-FPN对特征金字塔的组合路径进行的搜索。我们可以把NAS-FPN看作是一种模型缩放技术,它主要在阶段级(stage level)执行。至于EfficientNet,它采用的是基于深度、宽度和输入大小的复合缩放搜索。EfficientDet的主要设计理念是将具有不同功能的对象检测器模块进行拆解,然后对图像大小、宽度、#BiFPN层、#box/class层进行缩放。另一个采用NAS概念的设计是SpineNet,主要针对网络架构搜索的鱼形(fish shaped)对象检测器的整体架构。这种设计理念最终可以产生一个尺度化的重新排列的结构。另一种采用NAS设计的网络是RegNet,主要是固定阶段数和输入分辨率,将每阶段的深度、宽度、瓶颈比和组宽等参数全部整合为深度、初始宽度、斜率、量化、瓶颈比和组宽。最后,他们利用这六个参数进行复合模型缩放搜索。以上方法都是很好的工作,但很少有人分析不同参数之间的关系。本文将根据物体检测的设计要求,尝试寻找一种协同复合缩放的方法。
3.Principles of model scaling
在对所提出的对象检测器进行模型缩放后,下一步就是处理将发生变化的定量因素,包括带有定性因素的参数数量。这些因素包括模型推理时间、平均精度等。根据所使用的设备或数据库的不同,定性因素会有不同的增益效果。我们将在3.1中对定量因素进行分析和设计。在3.2和3.3中,我们将分别设计与低端设备和高端GPU上运行的微小物体检测器相关的定性因子。
3.1 General principle of model scaling
当设计有效的模型缩放方法时,我们的主要原则是当缩放是up\down时,定量成本的increse\decrese应该是lower\higher越好。在这节中,我们将展示和分析各种的通用CNN模型,并尝试理解在面对(1)图片尺寸,(2)层数,(3)通道数变化时定量成本的变化。我们选择的CNN是ResNet,ResNeXt和DarkNet。
对于基础层通道为b的k层CNN,ResNet层的计算量为 k ∗ { c o n v 1 × 1 , b / 4 − c o n v 3 × 3 , b / 4 − c o n v 1 × 1 , b } k*\{conv 1\times1,b/4-conv3\times3,b/4-conv1\times1,b\} k∗{conv1×1,b/4−conv3×3,b/4−conv1×1,b} ,ResNext层是 k ∗ { c o n v 1 × 1 , b / 2 − g c o n v 3 × 3 / 32 , b / 2 − c o n v 1 × 1 , b } k*\{conv1\times1,b/2-gconv3\times3/32,b/2-conv1\times1,b\} k∗{conv1×1,b/2−gconv3×3/32,b/2−conv1×1,b},对于DarkNet层计算量是 k ∗ { c o n v 1 × 1 , b / 2 − c o n v 3 × 3 , b } k*\{conv1\times1,b/2-conv3\times3,b\} k∗{conv1×1,b/2−conv3×3,b}。假设缩放因子能够调整图片大小,层数,通道数。当这些缩放因子变化时,相应的对FLOPs的变化总结在表1中。
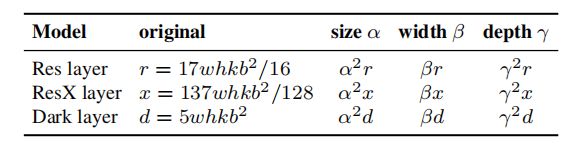
表1:不同模型的计算曾在不同的缩放因子下对应的FLOPs
表1有错误,应该是深度 β \beta β,宽度 γ \gamma γ.黄色标出的部分
https://github.com/WongKinYiu/ScaledYOLOv4/issues/24
表1可见,缩放大小,宽度,深度能够改变计算成本,分别是平方,线性,平方关系。
Wang等人提出的CSPNet可以应用于各种CNN架构,同时减少参数量和计算量。此外,它还提高了精度,减少了推理时间。我们将其应用于ResNet、ResNeXt和Darknet,观察计算量的变化,如表2所示。

表2:使用/未使用CSP后的不同计算层的FLOPs
CSP将原来的 N × k N\times k N×k拆分成了 3 4 + n × k \frac 3 4 + n\times k 43+n×k
从表2可以看出,将CNN转化成CSPNet,新的架构能够有效的减少计算量(FLOPs)。ResNet减少了23.5%,ResNeXt减少了46.7%,DarkNet减少了50%。因此,我们使用CSP化后的模型作为缩放的对象。
3.2 Scaling Tiny Models for Low-End Devices
对于低端设备来说,设计的模型的推理速度不仅受计算量和模型大小的影响,更重要的是必须考虑外围硬件资源的限制。因此,在进行小模型缩放时,我们还必须考虑内存带宽、内存访问成本(MAC)和DRAM流量等因素。为了考虑上述因素,我们的设计必须遵循以下原则:
将复杂度减少到 O ( w h k b 2 ) \mathcal{O(whkb^2)} O(whkb2)以下:轻量级模型不同于大型模型,其参数利用效率必须较高,才能以较少的计算量达到要求的精度。在进行模型缩放时,我们希望计算复杂度能够尽可能的低。在表3中,我们分析了参数利用效率高的网络,如DenseNet和OSANet5的计算负载。

表3:Dense层和OSA层的FLOPs
对于普通CNN, g , b , k g,b,k g,b,k的关系在表3中是 k < < g < b k<
最小化/平衡特征图的尺寸:为了在计算速度上得到最好的权衡,我们提出了一个新的概念,就是在CSPOSANet的计算块之间进行梯度截断。如果我们将原来的CSPNet设计应用到DenseNet或ResNet架构中,这两种架构由于第 j j j层的输出是第 1 s t 1^{st} 1st层至 ( j − 1 ) t h (j-1)^{th} (j−1)th层的输出的积分,所以我们必须将整个计算块作为一个整体来处理。由于OSANet的计算块属于PlainNet架构,所以从计算块的任何一层做CSPNet都可以达到梯度截断的效果。我们利用这一特点,将基础层的 b b b通道和计算块生成的 k g kg kg通道重新规划,分成通道数相等的两条路径,如表4所示。
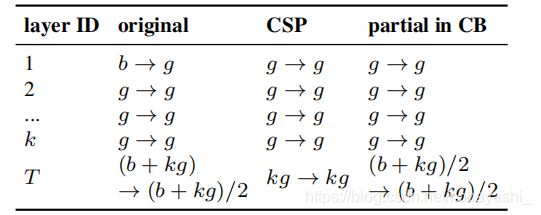
k k k:层数, b b b:base layer channels, g g g:增长率,来自4.2章
表4:Number of channel of OSANet,CSPOSANet,and CSPOSANet with PCB(?)
当通道是 b + k g b+kg b+kg时,如果想要将这些通道分为2个路径, 最好的分法是将它分为2个等分。当我们实际考虑硬件的带宽 τ τ τ时,如果不考虑软件优化,最佳值为 c e i l ( ( b + k g ) / 2 τ ) × τ ceil((b+kg)/2τ ) × τ ceil((b+kg)/2τ)×τ . 我们设计的CSPOSANet可以动态调整通道分配。
卷积后保持相同的通道数:为了评估低端设备的计算成本,我们还必须考虑功耗,影响功耗的最大因素是内存访问成本(MAC)。 通常卷积运算的MAC计算方法如下:
M A C = h w ( C i n + C o u t ) + K C i n C o u t MAC=hw(C_{in}+C_{out})+KC_{in}C_{out} MAC=hw(Cin+Cout)+KCinCout
h , w , C i n , C o u t , K h,w,C_{in},C_{out},K h,w,Cin,Cout,K分别代表特征图的高,宽,输入通道,输出通道和卷积核大小。通过计算集合不等式,我们可以到导出 C i n = C o u t C_{in}=C_{out} Cin=Cout时最小的MAC。
最小化卷积输入/输出(CIO):CIO是一个可以衡量DRAM IO状态的指标。表5列出了OSA、CSP和我们设计的CSPOSANet的CIO。

表5:OSANet,CSPOSANet,和CSPOSANet with PCB的CIO
当kg>b/2时,所提出的CSPOSANet可以获得最好的CIO。
3.3 Scaling Large Models for High-End GPUs
由于我们希望在对CNN模型进行缩放后,能够提高准确率并保持实时推理速度,所以在进行复合缩放时,我们必须在目标检测器的众多缩放因子中找到最佳组合。通常,我们可以调整目标检测器的输入、backbone和neck的缩放因子。可以调整的潜在缩放因子汇总如表6。

表6:目标检测器的不同部分的缩放因子
目标检测和图像分类最大的不同是前者只需识别出图像中最大分量的类别,但后者需要预测图像中每个对象的位置和大小。在one-stage目标检测器中,每个位置的对应的特征向量用于预测该位置的对象的类别和大小6。在CNN的架构中,于感受野直接相关的是stage数,并且特征金子塔(FPN)告诉架构告诉我们,更高的stage更适合预测大目标。 在表7中,我们说明了感受野与几个参数之间的关系。

表7:不同的缩放因子对感受野的影响
从表7可以看出,宽度缩放可以独立进行。当输入图像大小增加时,如果想对大目标有更好的效果,必须增加网络的深度和stage数。在表7列出的参数中, { s i z e i n p u t , # s t a g e } \{size^{input},\#stage\} {sizeinput,#stage}的结合有最好的影响。因此在使用缩放时,我们首先在 s i z e i n p u t size^{input} sizeinput, # s t a g e \#stage #stage执行,然后根据实时要求,分别对深度和宽度进行缩放。
yolov5的s,m,l,x是深度和宽度。通过调整depth_multiple(stage的个数)和width_multiple(通道数)调整。stage好像倒是没变的
4.Scaled-YOLOv4
在本节中,我们将重点放在为普通GPU、低端GPU和高端GPU设计缩放的YOLOv4上。
4.1 CSP-ize YOLOv4
YOLOv4是为通用GPU上的实时目标检测而设计的。 在本节中,我们将YOLOv4重新设计为YOLOv4-CSP,以获得最佳的速度-精度权衡。
Backbone:CSPDarknet53的设计中,跨级过程(cross-stage)下采样卷积的计算不包括在残差块中7。 因此,我们可以推导出每个CSPDarknet阶段的计算量为 w h b 2 ( 9 / 4 + 3 / 4 + 5 k / 2 ) whb^2(9/4+3/4+5k/2) whb2(9/4+3/4+5k/2)。从上面推到的公式中,我们可以得只有当 k > 1 k>1 k>1时,CSPDarkNet stage才会有更好的算力优势。在CSPDarkNet53中,每个stage拥有的残差层的个数分别为 1 − 2 − 8 − 8 − 4 1-2-8-8-4 1−2−8−8−4。为了获得更好的速度-精度权衡,我们将第一个CSP stage变为原始的DarkNet残差层。
Neck:为了有效的减少计算量,我们在YOLOv4中的PAN进行了CSP化。PAN的结构的计算如图2(a)。它主要集成来自不同的特征金字塔的特征图,然后通过两组反向DarkNet,没有短接的残差层。在CSP化后,新的计算方式在图2(b),这个新的改进有效地减少了40%地计算量。
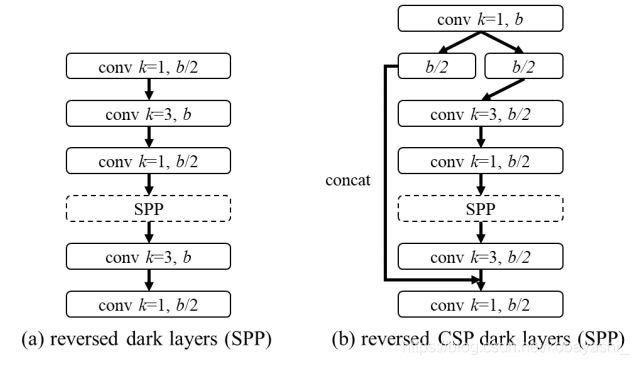
图2:反向Dark layer(SPP)和反向CSP dark layer(SPP)
反向是指瓶颈结构的反向,ksize顺序由1-3变为了3-1。不过开始和结束都是使用ksize=1做通道融合
SPP:SPP模块最初是插入在Neck的第一个计算组中8,因此,我们在CSPPAN的同样的位置插入SPP。
4.2 YOLOv4-tiny
YOLOv4-tiny是为低端设备设计的,遵循3.2节的设计原则。
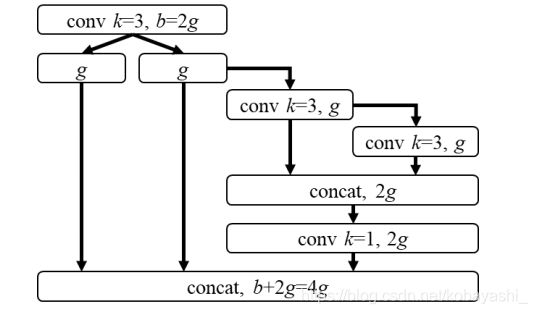
图3:YOLOv4-tiny的计算块
我们将使用带有PCB结构的CSPOSANet来组成YOLOv4的主干。我们将增长率设为 g = b / 2 g=b/2 g=b/2,在最后增长到 b / 2 + k g = 2 b b/2+kg=2b b/2+kg=2b。通过计算,我们推导出 k = 3 k=3 k=3,结构在图3中。至于每个stage上的通道数和Neck部分,我们遵循YOLOv3-tiny。
4.3 YOLOv4-large
YOLOv4-large是为云GPU设计的,主要目标是实现高精度目标检测。我们设计了一个完全CSP化的YOLOV4-P5模型,然后放大到YOLOv4-P6和YOLOv4-P7。
图4显示了YOLOv4-P5,YOLOv4-P6,YOLOv4-P7的结构。我们设计了 s i z e i n p u t , # s t a g e size^{input},\#stage sizeinput,#stage的复合缩放。我们将每个stage的深度设置为 2 d s i 2^{d_{s_i}} 2dsi, d s 为 [ 1 , 3 , 15 , 15 , 7 , 7 , 7 ] d_s为[1,3,15,15,7,7,7] ds为[1,3,15,15,7,7,7]。最后,我们使用推理时间作为约束来进行宽度缩放。 我们的实验表明,当宽度缩放因子等于1时,YOLOv4-P6可以在30fps视频中达到实时性能。 对于YOLOv4-P7,当宽度缩放因子等于1.25时,它可以在15fps视频中达到实时性能。
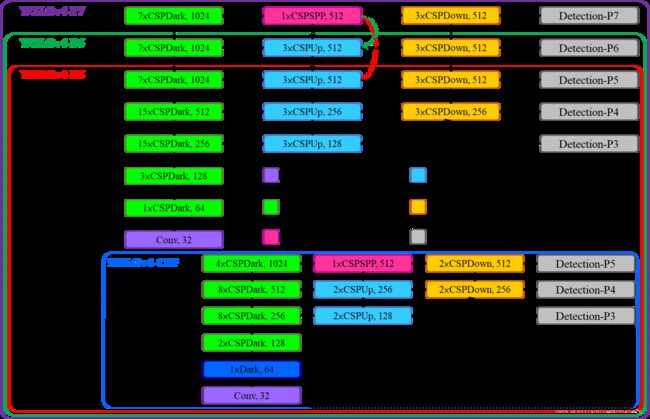
图4:YOLOV4-large的结构,包括YOLOv4-P5,YOLOv4-P6和YOLOv4-P7。虚线箭头表示使用CSPSPP块替换相应的CSPUp块9
将原文的配图换成了项目的配图;原文的yolov4-large指的是P5,P6,P7,即上部分
5.Experiments
我们使用MSCOCO2017对象检测数据集来验证所提出的scaled-YOLOv4。 我们不使用Image Net预训练的模型,所有的scaled-YOLOv4模型都是从零开始训练的,所采用的工具是SGD优化器。 用于训练YOLOv4-Tiny的时间为600个epoch,用于训练YOLOv4-CSP的时间为300个epoch。 对于YOLOv4-large,我们首先执行300个epoch,然后使用更强的数据增强方法来训练150个epoch。 对于拉格朗日乘数的超参数,如学习速率的anchor,不同数据增强方法的程度,我们使用k-means和遗传算法。 所有与超参数相关的细节都在附录中详细说明。
pass
1.做了CSP化后的消融实验,证明了CSP化能够显著减少参数量和计算量(30%左右,精度还能提高1%左右,Mish激活函数也能够提高AP值);
2.YOLOv4-tiny的消融实验
3.YOLOv4-large的消融实验
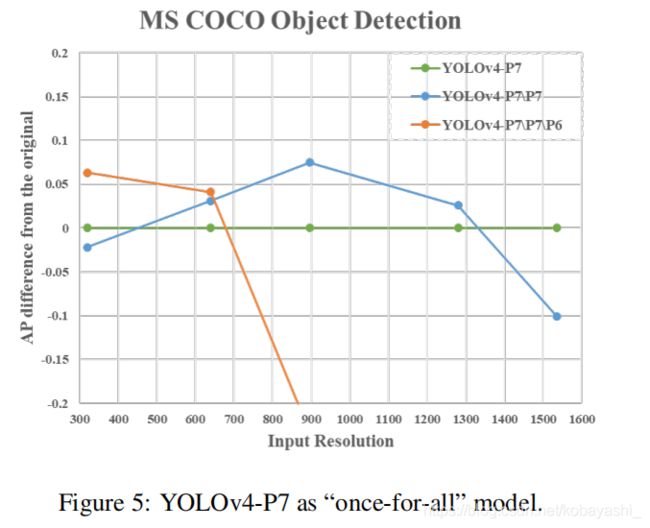
绿线:YOLOv4-P7
蓝线:YOLOv4-P7\P7意思是YOLOv4-P7移除了P7 stage
橙线:YOLOv4-P7\P7\P6意思是YOLOv4-P7移除了P7,P7 stage
6.Conculsions
pass
7.Acknowledgements
pass
Once-for-All: Train One Network and Specialize it for Efficient Deployment; ↩︎
EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks,使用了NAS(神经网路架构搜索)进行炼丹 ↩︎
Designing Network Design Spaces,⭐️ ↩︎
https://arxiv.org/pdf/1904.07850.pdf;回归3个点,左上,右下,中心点 ↩︎
VoVNet里面的,OSA:one-shot aggregation(只聚合一次)。简单来说就是不同stage的特征图只在最后加在一起。参考 ↩︎
想想yolo的输出形状 ↩︎
想想CSP的结构,参考脚注9 ↩︎
yolov5的SPP模块的位置 ↩︎
YOLOv3,YOLOv4的结构,文章:深入浅出Yolo系列之Yolov3&Yolov4&Yolov5核心基础知识完整讲解 - 知乎 (zhihu.com)。Backbone的激活函数用Mish,neck用LeakyReLU(为什么?)。图4的“虚线箭头表示使用CSPSPP块替换相应的CSPUp块”意思是P5,P6,P7top-down的结构的最高层是CSPSPP块,就如YOLOv4-CSP结构那样 ↩︎ ↩︎