gan 5小时速成
名词解释
多模态学习:每一种信息的来源或者形式,都可以称为一种模态;多模态机器学习,旨在通过机器学习的方法实现处理和理解多源模态信息的能力;比较热门的研究方向是图像、视频、音频、语义之间的多模态学习
图像标记:用词语对图像中不同内容进行多维度表述
图像描述:把一幅图片翻译为一段描述文字获取图像的标记词语理解图像标记之间的关系
生成人类可读的句子
词向量模型:Word2Vec是从大量文本语料中以无监督的方式学习语义知识的一种模型
通过词的上下文得到词的向量化表示,使得语义上相似的单词在向量空间内距离也很近
来源于2013年的论文《Efficient Estimation of Word Representation in Vector Space》
有两种方法:CBOW(通过附近词预测中心词)和SKIp-gram(通过中心词预测附近的词)
结构loss
图像建模的结构化损失图像到图像的转换问题通常被表述为逐像素分类或回归。这些公式将输出空间视为“非结构化”,因为在给定输入图像的情况下,每个输出像素都被认为有条件地独立于所有其他像素。有条件的gan相反地学习一个结构损失,结构损失惩罚输出的联合配置。
Structured losses for image modeling Image-to-image translation problems are often formulated as per-pixel classification or regression. These formulations treat the output space as "unstructured" in the sense that each output pixel is considered conditionally independent from all others given the input image. Conditional GANs instead learn a structured loss, Stryctured losses penalize the joint configuration of the output.
unet
基于经典的Encoder-decoder结构在很多图像翻译任务中,输出和输出图像外观看起来不同,但结构信息是相同的在Encode过程中,feature map的尺寸不断减小,低级特征将会丢失
在第1层与第n-i层间加入skip-connection,把i层的特征直接传到第n-i层
patchgan
PatchGAN像素级的1 loss能很好的捕捉到图像中的低频信息,GAN的判别器只需要关注高频信息把图像切成N"N的patch,其中N显著小于图像尺寸假设在大于N时,像素之间是相互独立的,从而可以把图像建模成马尔科夫随机场把判别器在所有patch上的推断结果,求平均来作为最终输出可以把PatchGAN理解为对图像纹理/style损失的计算PatchGAN具有较少的参数,运行得更快,并且可以应用于任意大的图像
前置知识
1.数字图像:
有什么用:最早海底电缆传输图像,数字图像可以加快传输
是什么:用矩阵表示图像
怎么形成数字图像: 物体发送电磁波被设备接收形成数字图像
例子:x射线成像
人体密度高的地方(骨头)对x射线吸收多 吸收的能量多,就发白
人体密度低的地方,x射线直接穿透,就发黑
紫外线波段 成像
展示细胞
可见光波段成像:物体反射可见光进入人眼
数字图像的任务
| 输入/输出 | 图像 | 知识 |
| 图像 | 数字图像处理 | 计算机视觉 |
| 知识 | 计算图形学 | 人工智能 |
2.图像处理,机器视觉,人工智能关系
图像处理的输出还是图像
机器视觉包括图像处理,目标是理解图像
人工智能 实现机器视觉理解图像的目标
3.opencv c实现提供python接口的计算机视觉工具包
4.图像属性
图像格式
bmp,tiff原图
gif可静可动
图像尺寸:表征图像的长宽
像素:像素=细胞 每个像素有个强度值(对应能量的强度值)
5.图像直方图
统计不同像素亮度的直方图,左侧为黑的点,右侧为亮的点

6.颜色空间
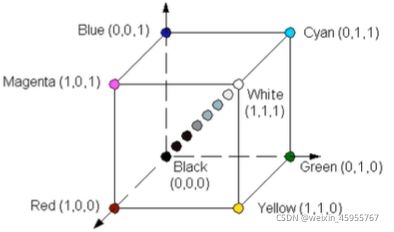
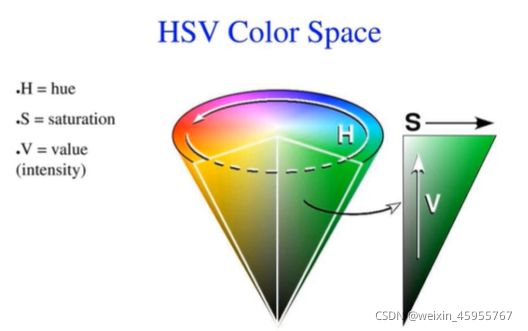
7.opencv画图




8.图像的缩放
下采样:缩小图像
上采样:放大图像
计算机视觉背景知识
模型结构设计:
1.堆积使用小卷积核(3*3卷积)
2.分辨率减半,通道数加倍
3.卷积分解:7*7卷积用3*3卷积代替
非对称卷积 n*n 卷积 = 1*n卷积+n*1卷积 这个在网络后半段效果比较好
4.辅助分类层:
是什么?中间的特征图用于分类的结构
有什么用?可以起正则作用,并不能提升底层的特征提取能力
5.特征图下降策略
因为池化后存在信息瓶颈,所以需要特征图下降策略
inception采用一半卷积一半池化的方式,拼接特征图
怎么做:选择步长为2的卷积核,可以将特征图缩小为原来一半
6.标签平滑
7.低分辨率图像分类
vgg的训练技巧:
1.尺度扰动
2.预训练模型初始化
vgg的测试技巧:
多尺度测试
dense测试
muti-crop测试
多模型融合
背景知识
1.图像描述:将图像描述为一段文字,理解标记间的关系从而生成人类可读的句子
2.多模态学习 用机器学习方法理解多模态信息
3.表征学习 得到好的特征
表征学习的方式
有监督的表示学习
无监督的表示学习

4.纳什均衡
又称为非合作博弈均衡,对于一个策略组合,当其他所有人都不改变策略日没有人会改变自己的策略,则该策略组合就是一个纳什均衡又称为非合作博弈均衡,对于一个策略组合,当其他所有人都不改变策略日没有人会改变自己的策略,则该策略组合就是一个纳什均衡
5.半监督学习
在特征空间中位置相近的无标签样本默认和有标签样本一个标签
6.图像翻译
图像与图像之间以不同形式的转换。根据source domain的图像生成target domain中的对应图像,约束生成的图像和source图像的分布在某个维度上尽量一致
7.图像质量评价(image Quality Assessment,IQA)
像素损失 MSE或PSNR 对模糊不够敏感
结构性损失 SSIM 引入像素的关联性 从两张图片分别裁取小块进行比对
锐度损失 GMSD
感知损失 利用网络提取图像特征,然后再计算l1,l2距离
8.域自适应/泛化(Domain Adaptation/Generalization)
domain自适应/泛化是迁移学习的一块重要研究领域
不同形式和来源的数据,其domain各不相同,数据分布存在域差异(Domain Discrepancy
而domain自适应/泛化的目标,就是学习到不同domain间的域不变(Domain Invariant)特征
9.神经自回归网络
通过链式法则把联合概率分布分解为条件概率分布 的乘积
使用神经网络参数化每个p
效率很低
10.VAE-GAN
编码器和判别器
编码器 最小化生成器和输入x的差距
判别器 给真实样本高分 给重建样本和生成样本低分
11.图像生成的评价指标
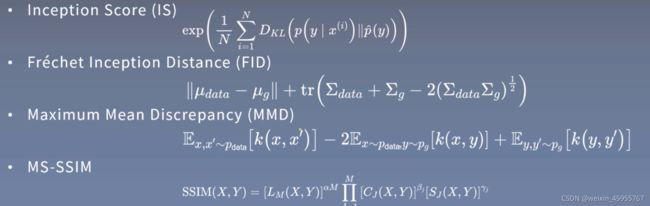
可以评价生成样本的质量可以评价生成样本的多样性,
能发现过拟合、模式缺失、模式崩溃、直接记忆样本的问题有界性,即输出的数值具有明确的上下界
给出的结果应当与人类感知一致
计算评价指标不应需要过多的样本
计算复杂度尽量低
12.谱归一化(spectral normalization)

13.参数初始化
什么用? 使得输入输出方差一样
应用的例子 Xavier初始化,kaiming初始化,单位初始化,正交矩阵初始化
进入正题
gan可以做什么?
生成图像和文本
gan的提出 lan Goodfellow
gan的摘要
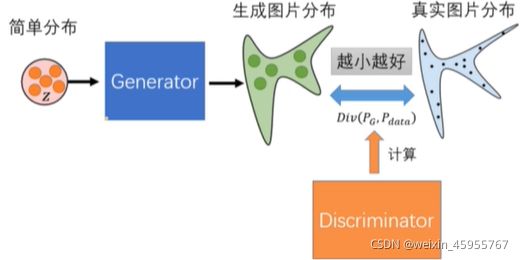
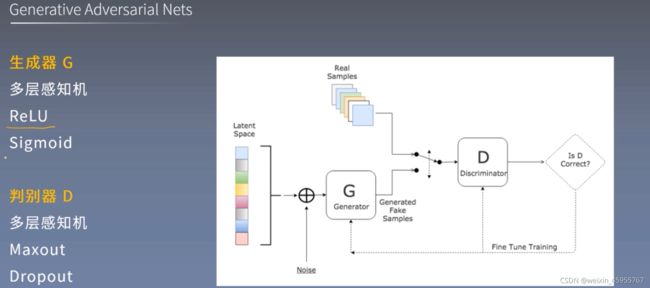
1,提出了一个基于对抗的新生成式模型,它由一个生成器和一个判别器组成
2,生成器的目标是学习到样本的数据分布,从而能生成样本欺骗判别器;判别器的目标是判断输入样本是生成/真实的概率
3.GAN模型等同于博弈论中的二人零和博弈
4,对于任意的生成器和判别器,都存在一个独特的全局最优解
5,在本文中,生成器和判别器都由多层感知机实现,整个网络可以用反向传播算法来训练
6,通过实验的定性与定量分析显示,GAN具备很大的潜力
We propose a new framework for estimating generative models via an adversarial process, in which we simultaneously train two models: agenerative model G that captures the data distribution, and a discriminative mode That esumates the probability that a sample came from the training data rather than G. The training procedure for G is to maximize the probability of D making a mistake. This framework corresponds to a minimax two-player game, In the space of arbitrary functions G and D, a unique solution exists, with G recovering the training data distribution and D equal to everywhere. In the case where G and D are defined by multilayer perceptrons, the entire system can be trained with backpropagation.
There is no need for any Markov chains or unrolled approximate inference networks during either training or generation of samples. Experiments demonstrate the potential of the framework through qualitative and quantitative evaluation of the generated samples.
cgan的提出 Mehdi Mirza, Simon Osindero
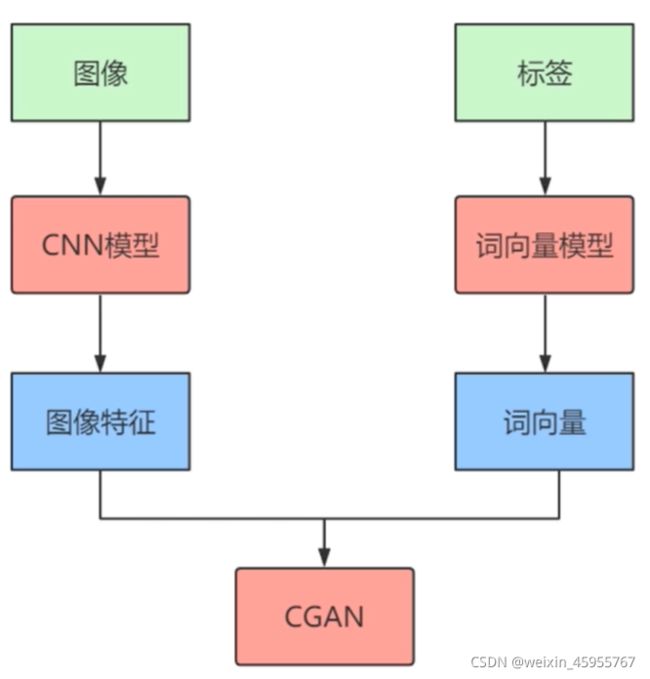
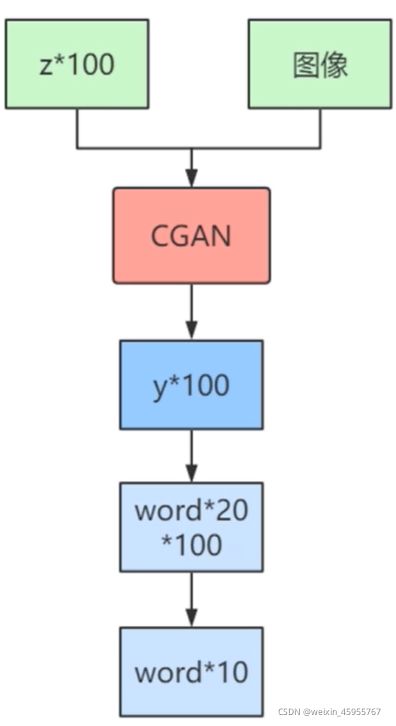
cgan在哪用? gan在多模态学习的应用

cgan的摘要
1,提出了一个基于生成对抗网络的条件生成式模型
2,在原模型基础上,输入额外的数据作为条件
3,在原模型基础上,对生成器和判别器都进行了修改
4,在MNIST数据集上,新模型可以生成以数字类别标签为条件的手写数字图像
5,新模型还可以用来做多模态学习,可以生成输入图像相关的描述标签
Generative Adversarial Nets [8] were recently introduced as a novel way to train generative models. In this work we introduce the conditional version of generative adversarial nets, which can be constructed by simply feeding the data, y, we wish to condition on to both the generator and discriminator. We show that this model can generate MNIST digits conditioned on class labels. We also illustrate how this model could be used to learn a multi-modal model, and provide preliminary examples of an application to image tagging in which we demonstrate how this approach can generate descriptive tags which are not part of training labels.
dcgan的提出 Representation Learning with Deep Convolutional Generative Adversarial Networks>Alec Radford, Luke Metz, Soumith Chintala
dcgan在哪用? gan在表征学习的应用 DCGAN使GAN在图像生成任务上的效果大大提升
dcgan的摘要
1,希望能让CNN在无监督学习上,达到与监督学习一样的成功
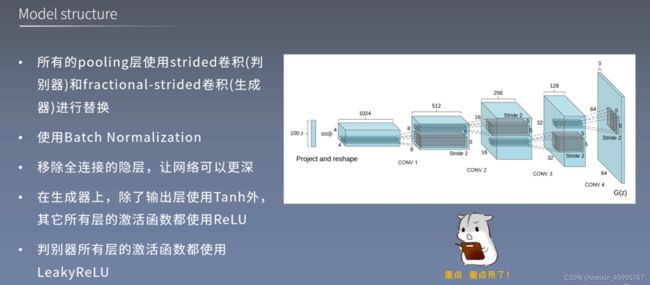
2,通过架构约束,构建了深度卷积生成对抗网络(DCGAN)
3,证明了DCGAN是目前先进的无监督学习网络
4,证明了DCGAN的生成器和判别器学习到了从物体细节到整体场景的多 次表征
5,证明了DCGAN判别器提取的图像特征具有很好的泛化性
In recent years, supetvised learning with convolutional networks (CNNs) has seen huge adoption in computer vision applications. Comparatively, unsupervised learning with CNNs has received less attention. In this work we hope to help bridge the gap between the success of CNNs for supervised learning and unsupervised learning. We introduce a class of CNNs called deep convolutional generative adversarial networks (DCGANs), that have certain architectural constraints. and demonstrate that they are a strong candidate for unsupervised learning. Training on various image datasets, we show convincing evidence that our deep convolutional adversarial pair learns a hierarchy of representations from object parts to scenes in both the generator and discriminator. Additionally, we use the learned features for novel tasks -demonstrating their applicability as general image representations.
DCGAN是具有语义信息的

ITgan的提出 Tim Salimans, lan Goodfellow, et al.
ITgan的摘要
1,提出了一系列新的GAN结构和训练方式
2,进行了半监督学习和图像生成相关实验
3,新的技术框架在MNIST、CIFAR-10和SVHN的半监督分类中取得了良好效果
4,通过视觉图灵测试证明,生成的图像同真实图像已难以区分
5,在ImageNet上训练,模型学习到了原图的显著特征
We present a variety of new architectural features and training procedures that we apply to the generative adversarial networks (GANs) framework. We focus on two applications of GANs: semi-supervised learning, and the generation of images that humans find visually realistic. Unlike most work on generative models, our primary goal is not to train a model that assigns high likelihood to test data, nor do we require the model to be able to learn well without using any labels. Using our new techniques, we achieve state-of-the-art results in semi-supervised classification on MNÍST, CIFAR-10 and SVHN. The generated images are of high quality as confirmed by a (visual Turing test: our model generates MNIST samples that humans cannot distinguish from real data, and CIFAR-10 samples that yield a human error rate of 21.3%. We also present ImageNet samples with unprecedented resolution and show that our methods enable the model to learn recognizable features of ImageNet classes.
用于图像翻译的条件生成式对抗网络pix to pix
pix to pix的提出 Phillip lsola, Jun-Yan Zhu, Tinghui Zhou, Alexei A. Efros
pix2pix的摘要
1,研究条件生成式对抗网络在图像翻译任务中的通用解决方案
2,网络不仅学习从输入图像到输出图像的映射,还学习了用于训练该映射的损失函数
条件gan不同于loss是可以学习的,以及理论上可以惩罚输入和输出的任何结构上的不同
The conditional GAN is different in that the loss is learned,and can,in theory,penalize any possible structure that differs between output and target.
3,证明了这种方法可以有效应用在图像合成、图像上色等多种图像翻译任务中
4,使用作者发布的pix2pix软件,大量用户已经成功进行了自己的实验,进一步证明了此方法的泛化性
5,这项工作表明可以在不手工设计损失函数的情况下,也能获得理想的结果
We investigate conditional adversarial networks as a general-purpose solution to image-to-image translation problems. These nerworks not only learn the mapping from input image to ouput image, but also learn a loss function to train this mapping. This makes it possible to apply the same generic approach to problems thar traditionally would require very different loss formulations. We demonstrate that this approach is effective at synthesizing photos from label maps, reconstructing objects from edge maps, and colorizing images, among other tasks. Indeed, since the release of the pix2pix sofiware associated with this paper, a large number of internet users (many of them artists)have posted their own experiments with our system, further demonstrating is wide applicabiliry and ease of adoption without the need for parameter rweaking. As a community, we no longer hand-engineer our mapping functions, and this work suggests we can achieve reasonable results without hand-engineering our loss functions either
用于非配对图像翻译的循环一致性对抗网络Cyclegan
Cyclegan的提出Jun-Yan Zhu, Taesung Park, Phillip Isola, Alexei A. Efros
Cyclegan的摘要
1,图像翻译任务需要对齐的图像对,但很多场景下无法获得这样的训练数据
2,提出了一个基于非配对数据的方法,仍然可以学习到不同domain图像问的映射
3.CycleGAN是在GAN loss的基础上加入循环一致性损失,使得F(G(X))尽量接近x(反之亦然)
4,在训练集没有配对图像的情况下,对CycleGAN在风格迁移、物体变形、季节转换、图像增强等多个图像翻译任务中的生成结果做了定性展示
5,与此前一些方法的定量比较,进一步显示了CycleGAN的优势
提升生成质量、稳定性和多样性的渐进式增长生成讨抗网络(ProGAN)
ProGAN的提出Tero Karras, Timo Aila, Samuli Laine, Jaakko Lehtinen
ProGAN的摘要
1,使用渐进的方式来训练生成器和判别器:先从生成低分辨率图像开始,然后不断增加模型层数来是升生成图像的细节
2,这个方法能加速模型训练并大幅提升训练稳定性,生成前所未有的的高质量图像(1024*1024)
3,提出了一种简单的方法来增加生成图像的多样性
4,介绍了几种限制生成器和判别器之间不健康竞争的技巧
5,提出了一种评价GAN生成效果的新方法,包括对生成质量和多样性的衡量
6,构建了一个CELEBA数据集的高清版本
We describe a new training methodology for generative adversarial networks. The key idea is to grow both the generator and discriminator progressively: startingfrom a low resolution, we add new layers that model increasingly fine details as training progresses. This both speeds the training up and greatly stabilizes it, allowing us to produce images of unprecedented quality, e.g., CELEBA images at 1024^2. We also propose a simple way to increase the variation in generated images, and achieve a record inception score of 8.80 in unsupervised CIFAR10, Additionally we describe several implementation details that are important for discouraging unhealthy competition between the generator and discriminator. Finally, we suggest a new metric for evaluating GAN results, both in terms of image quality and variation. As an additional contribution, we construct a higher-quality version of the CELEBA dataset.
使用堆叠的生成式对抗网络进行文本到照片级图像的合成(StackGAN)
StackGAN的提出 Han Zhang, Tao Xu, Hongsheng Li, Shaoting Zhang, et.
StackGAN的摘要
1,现有文本到图像方法生成的样本,可以大致表达出给定的文本含义,但是图像细节和质量不佳
2.StackGAN能基于文本描述,生成256"256分辨率的照片级图像
3,把问题进行了分解,采用草图绘制-精细绘制两阶段过程
4·阶段1的GAN根据给定的文本描述,来绘制对象的原始形状和颜色;阶段2的GAN使用文本描述和阶段1的输出来作为输入,通过纠正草图中的缺陷和细节生成,来最终得到更高分辨率的图像
5,还提出了一种条件增强方法,能够增强潜在条件流形的平滑性
6,大量实验表明,以上方法在以文本描述为条件的照片级图像生成上取得了显著进步
Synthesizing high-qualiry images from text descriptions is a challenging problem in computer vision and has many practical applications. Samples generated by existing text-to-image approaches can roughly reflect the meaning of the given descriptions, but they fail to contäin necessary details and vivid object Paris. In this paper, we propose Stacked Generative Adversarial Networks (StackGAN) to generate 256x256 photo-realistic images conditioned on text descriptions. We decompose the hard problem into more manageable sub-problems through a sketch-refinement process.
The Stage-l GAN sketches the primitive shape and colors of the object based on the given text description, yield. ing Stage-l low-resolution images. The Stage-ll GAN takes Stage-I results and text descriptions as inputs and generates high-resolution images with photo-realistic details. In is able to rectify defects in Stage-l results and add comp33elling details with the refinement process. To improve the diversity of the synthesized images and stabilize the training of the conditional-GAN, we introduce a novel Conditioning Augmentation technique that encourages smoothness in the latent conditioning manifold. Extensive experiments and comparisons with state-of-the-art on benchmark datasets demonstrate that the proposed method achieves significant
训练大规模生成式对抗网络用于高保真自然图像合成(big gan)
big gan的提出 Andrew Brock, Jeff Donahue & Karen Simonyan
biggan的摘要
1,基于复杂数据集(如lmageNet)生成高分辨率的多类别图像仍旧是一个非常困难的目标
2,为此,我们训练了现有最大规模的GAN,并研究了这种规模下GAN训练的不稳定性
3.在生成器上应用正交正则化使得它能够进行隐空间的截断,从而可以调节生成器输入的方差,实现了对生成图像保真度和多样性之间平衡的良好控制
4.BigGAN成为了目前类别条件图像生成领域的新SOA模型
5,使用ImageNet进行128× 128分辨率的训练时,BigGAN的1S得分为166.5,FID得分为7.4
Despite recent progress in generative image modeling, successfully generating high-resolution, diverse samples from complex datasets such as ImageNet remains an elusive goal. To this end, we train Generative Adversarial Networks at the largest scale yet attempted, and study the instabilities specific to such scale. We find that applying orthogonal regularization to the generator renders it amenableto a simple "truncation trick.,"allowing fine control over the trade-off between sample fidelity and variety by reducing the variance of the Generator's input. Our modifications lead to models which set the new state of the art in class-conditional image synthesis. When trained on ImageNet at 128 x 128 resolution, our models(BigGANs) achieve an Inception Score (IS) of 166.5 and Fréchet Inception Distance (FID) of 7.4, improving over the previous best IS of 52.52 and FID of 18.65.
生成对抗网络中一种基于样式的生成器架构(StyleGAN)
StyleGAN的提出: Generative Adversarial Networks>Tero Karras, Samuli Laine, Timo Aila
stylegan的摘要:
1,从风格迁移的研究中进行借鉴,提出了GAN的新生成器架构
2,可以自动对图像的高级属性(姿态)和随机变化的图像细节(头发)进行无监督的分离
3,可以直观的、按照特定的尺度来控制生成效果
4,在SOA的基础上提升了生成质量,并拥有更好的插值性能,还对隐变量进行了更好的解耦
5,提出了两种新方法来对插值质量和隐变量解耦程度进行定量评价
6,提出了一个新的高多样性高分辨率人脸图像数据集
We propose an alternative generator architecture for generative adversarial nervorks, borrowing from style transfer literature. The new anhitecture leads to an an tomatically learned, unsupervised separation of high-level atributes (e.g. pose and identiry when trained on huuman faces) and stochastic variation in the generated images
(e.g. freckles, hair), and it enables intuitive, scale-specific control of the synthesis. The new generator improves the state-of-the-ar in terns of traditional distribution qualiry metrics, leads to demonstrably better interpolation properties, and also better disentangles the laten factors of variation. To quantify interpolation qualiry and disentanglement, we propose rwo new; automated methods that are applicable to any generator architecture. Finally, we introduce anew; higly varied and high-qualiry dataset of human faces.
网络结构的设计:
1.把隐向量通过卷积神经网络映射到高维向量输入主干网络生成可编辑的图像,每层都加入了随机噪声
图表解读

对输入噪声进行线性变换,输出也会发生改变,用于图像融合
模型的问题
gan的模式崩溃:每次生成器生成一样的样本
gan没有显示表示的Pg(x)
模型的应用
gan的应用
图像生成,图像转换,图像编辑
模型的发展
gan来自于自编码器
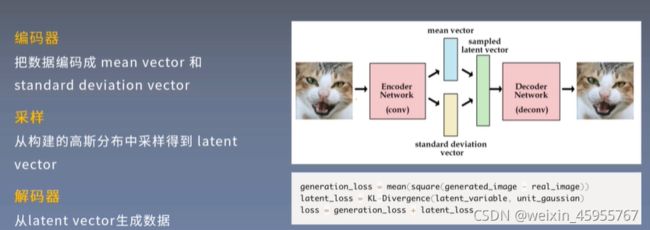
latent vector是包含图像表征的向量



涉及的公式
generation_loss 就是生成图像和实际图像的均方误差
latent_loss是生成数据和实际数据分布的KL散度
gan和cgan价值函数对比

pix2pix的目标函数

L1 loss的求法: |ground truth-生成的图像|求期望
模型结构
CGAN
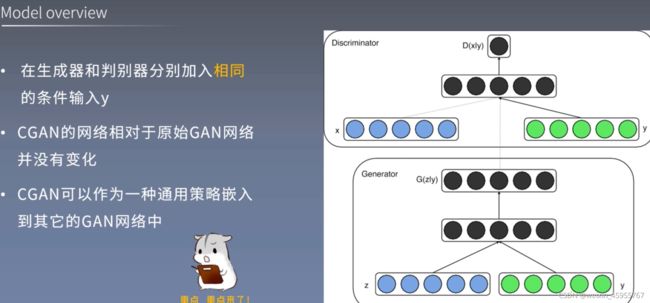
在生成器和判别器分别加入相同的条件输入y
y是什么?条件输入,可以是标签,也可以是来自于其他模块的数据
这种设计有什么用? cgan可以作为模块插入任意网络
y怎么用? 将y作为额外的输入同时输入生成器和判别器
y could be any kind of auxiliary information,such as class labels or data from other modalities.We can perform the conditioniing by feeding y into the both the discriminator and generator as additional input layer.
CGAN的网络相对于原始GAN网络并没有变化
CGAN可以作为一种通用策略嵌入到其它的GAN网络中
模型训练技巧
gan的训练技巧

pix2pix的训练技巧

gan的改进

模型评价方法
1.在相同数据集上训练一个自编码器,然后利用自编码器提取的语义哈希值评价dcgan的生成效果,假如dcgan的生成的语义哈希值和自编码器提取的一样,则视为重复
method 合集
pix2pix推断保留dropout
For our final models,we provide noise only in the form of dropout,applied on several layers of our generator at both training and test time.
有什么用:保证生成图像的随机性
因为初始层的随机噪声z在训练过程中会被忽略,导致网络的条件输入只对应固 定的输出
一些经验与发现
1.previous approaches have found it beneficial to mix GAN objective with a more traditional loss,such as L2 distance 一些前人研究已经发现GAN loss和L2 loss结合可以达到一些好的效果
We also explore ths option,using L1 distance rather than L2 as L1 encourages less blurring
我们也探索了这一选项,使用L1 loss比 L2 loss更有利于减少图像的模糊
2.像素级的l1 loss可以很好的捕捉到图像的低频信息,gan的判别器只需要关注高频信息
一些假设与条件近似
如何把图像建模成马尔可夫随机场?
假设在大于一定距离时,像素之间是相互独立的
应用实例:patchgan把图像切成n*n的patch,当像素处于不同的patch的时候,可以假设像素之间是相互独立的
一些模型设计的思路
patch的思想
做法:将N*N的图片分成若干个patch
缺陷:丢失图片的语义信息
应用:pix2pix;patchgan
优势:解除了输入图像大小的限制
一些图像质量评价方式(IQA)
Amazon Mechanical Turk(AMT)
任务:地图生成,航拍照片生成,图像上色
限制观看时间,每张图像停留一秒钟,答题时间不限每次评测只针对一个算法,包含50张图像前10张图像为练习题,答题后提供反馈,后40张为正式标注每批评测数据由50个标注者标注,每个评测者只能参与一次评测评测不包含测验环节
FCN-score
判断图像的类别是否能被模型识别出来,Inception Score
使用应用于语义分割任务的流行网络结构FCN-8s,并在cityscapes数据集上进行
根据网络分类的精度,来对图像的质量进,由于图像翻译不太关注生成图像的多样性不需要像Inception Score一样关注总体像的分布
recent works have tried using pre-trained semantic classifiers to measure the discriminability of the generated stimuli as a pseudo-metric
我们使用FCN 8s 观察图像的分类精度来评价图像的生成质量
we adopt the popilar FCN-8s architecture for semantiic segmentation,and train it on the cityscapes dataset.We then score synthesized photos by the classification accuracy against
the labels these photos werre synthesized from.
研究成果及意义
涉及的数据集
LSUN(Large-scale Scene Understanding)
加州大学伯克利分校发布,包含10个场景类别和20个对象类别,主要包含了卧室、客厅、教室等场景图像,共计约100万张标记图像
http://lsun.cs.princeton.edu/2017/
SVHN(Street View House Numbers)
街景门牌号码数据集,与MNIST数据集类似,但具有更多标签数据(超过600,000个图像)
从谷歌街景中收集得到
http://ufldl.stanford.edu/housenumbers/
CMP Facade Database由捷克理工大学的机器感知中心(CMP)发布,包含606张建筑正面的校正图像,来自世界各地的不同城市,包含12类语义分割标注
http://cmp.felk.cvut.cz/-tylecr1/facade/
Paris StreetView Dataset由牛津大学发布,包含6412张从Flickr上下载的包含巴黎标志性建筑的街景图像http://wwww.robots.ox.ac.uk/-vgg/data/parisbuildings/
Cityscapes Dataset由德国三个研究机构联合发布的城市景观数据集,拥有5000张带语义理解标注的城市街景图像httos://www.citvyscapes-dataset.com/
FACES数据集
从DBpedia上获取人名,并保证他们都是当代人用这些人名在网络上搜索,收集其中包含人脸的图像,得到了来自1万人的300万张图像使用OpenCV的人脸检测算法,截取筛选出较高分辨率的人脸,最终得到了大约35万张人脸图像